이 게시글은 윤성우 선생님의 자료구조 강의를 수강 후 나름대로의 내용 정리를 한 것임을 미리 밝힙니다.
스스로의 복습을 위해 작성한 글이므로 심층있는 학습을 위해서는 책의 구매 및 강의수강을 권장합니다.
1. 자료구조란 무엇인가?
프로그램이란 데이터를 표현하고 그렇게 표현된 데이터를 처리하는 것이다.
이 때 데이터를 표현하는 것은 데이터를 저장하는 것을 포함하는 개념인데
(ex. int x = 1; 은 x = 1이라는 정수형 변수를 표현하는 것뿐 아니라 저장하는 것 역시 의미)
이 데이터의 표현에 자료구조가 포함된다.
(자료구조는 데이터 표현이 60퍼센트 정도라고 생각하면 된다.)
자료구조의 분류
- 선형구조 - 리스트, 스택, 큐
- 비선형구조 - 트리, 그래프
- 단순구조 - 정수, 실수, 문자, 문자열
(4. 파일구조 - 순차파일, 색인파일, 직접파일)
알고리즘은 자료구조에 의존적이므로 자료구조를 공부하며 일부 알고리즘은 자연스럽게 학습하게 될 것이다.
2. 알고리즘의 성능분석방법
시간복잡도 : 얼마나 빠른가?
공간복잡도 : 얼마나 메모리를 쓰는가?
일반적으로 메모리의 사용량보다 실행속도에 초점을 둔다.
그리고 가장 중요한 것은 데이터의 수가 많아짐에 따른 연산횟수의 증가 정도에 있다.
특정 데이터 수일 때 수행속도만으로 알고리즘의 좋고 나쁨을 평가하는데는 무리가 있기 때문이다.
3.시간복잡도 분석의 핵심요소
어떠한 알고리즘이든 최선의 경우는 대부분 만족할만한 결과를 보이므로 최선의 경우는 관심의 대상이 아니다.
평균은 구할 수만 있으면 매우 좋은 비교대상이나 이는 구하기가 쉽지 않고 구하더라도 이가 평균이라고 납득하기가 매우 어렵다.
그래서 대부분 최악의 경우로 알고리즘의 성능을 평가한다.
4. Big - theta
두 개의 함수 f,g가 주어졌을 때, 모든 n >= K 에 대하여 Bg <= f <= Cg를 만족하는 세 상수 B,C,K가 존재하면 f의 Big theta는 Θ(g)이다.
이 때 Θ(g)는 f의 시간에 따른 증가율을 표현해주므로 2.의 알고리즘 성능분석법에 중요한 척도의 내용에 따라 매우 의미있는 값이다.
ex. T(n) = 2*n^2 + 3을 보자.
g(n) = n^2이라 하면 위의 식을 성립하므로 (B = 1, C = 5라 생각하고 n = 1부터 생각하면 쉬울 것이다.) T(n)의 빅세타는 n^2이다.
5.이진탐색 알고리즘과 분석
<간략한 알고리즘>
찾고자 하는 값을 target이라 하자.
1.n개의 자료를 arr[n]에 오름차순으로 저장.
(내림차순이라도 상관없지만 오름차순일 때 어떻게 할지를 알면 내림차순에서도 응용하여 적용할 수 있다.)
2.first = 0, last = n, mid = (first + last)/2 라 하자.
3.
arr[mid]가 target과 같으면 mid출력.
arr[mid]가 target보다 작으면 mid 전은 탐색할 필요가 없기에
first = mid + 1이라 한다.
arr[mid]가 target보다 크면 mid 이후는 탐색할 필요가 없기에 las = mid - 1이라 한다.
이후 mid = (first + last) / 2라 두고 다시 3. 실행
4.
이 때 과정을 반복하다 보면
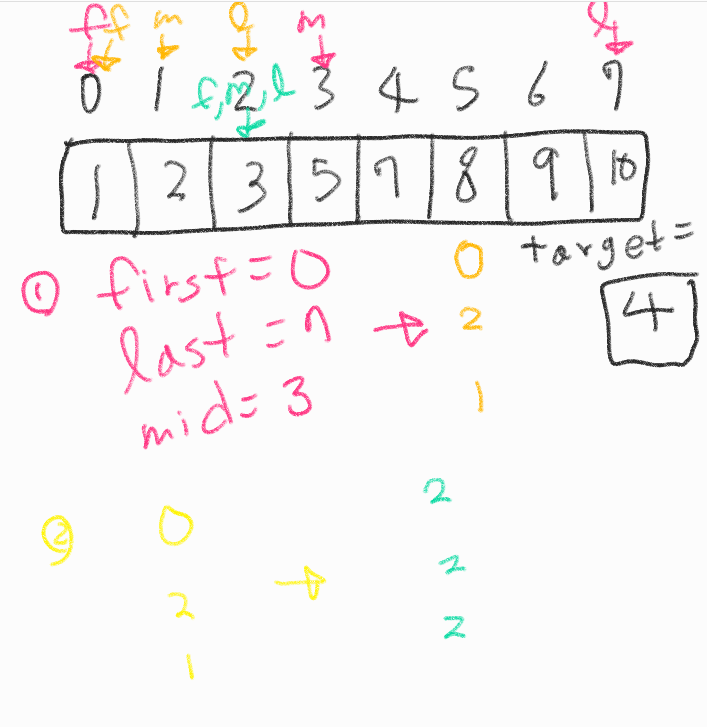
이렇게 first, last, mid가 같아질 때가 오는데 이 때 arr[mid]의 값이 target과 같으면 mid를 출력하면 되나 아닌 경우 둘 중 한가지이다.
(1) target < arr[mid]
mid의 왼쪽에 target이 있을 것으로 판단하는 경우이므로 last가 mid - 1이 되어 last < first 가 된다.
(2) target > arr[mid]
mid의 오른쪽에 target이 있을 것으로 판단하는 경우이므로 first가 mid + 1이 되어 last < first가 된다.
즉, last < first가 되는 순간 탐색하고자 한 배열에 target이 없다고 판단하면 된다.
이 알고리즘은 최악의 경우
탐색해야할 자료의 수가 한번의 target과 arr[mid]의 비교 때마다 절반씩 줄어들고 이후 자료의 수가 1이 되고 한번 더 target과 arr[mid]를 판단하여야하므로
자료의 개수를 n 비교횟수를 k라 할 때
n / (2 ^ t) = 1, t + 1 = k
따라서 t = log_2(n)
k = log_2(n) + 1이고 이진탐색의 big - theta는 log n 이라 할 수 있다.
코드
int Bsearch(int arr[], int len, int target)
{
int first = 0;
int last = len - 1; //배열의 마지막 번호
int mid;
while(first <= last)
{
mid = (first + last) / 2;
if(target == arr[mid]) return mid;
else if(target > mid) first = mid + 1;
else last = mid - 1;
}
return -1;
}응용하여 풀 수 있는 문제
https://www.acmicpc.net/problem/4158
내 코드
#include <stdio.h>
int array[1000000];
int brray[1000000];
int binary(int key, int array[], int left, int right)
{
int mid = (left + right) / 2;
if (left <= right)
{
if (array[mid] > key)
{
right = mid - 1;
mid = (left + right) / 2;
return binary(key, array, left, right);
}
else if (array[mid] < key)
{
left = mid + 1;
mid = (left + right) / 2;
return binary(key, array, left, right);
}
else
{
return mid;
}
}
else
{
return -1;
}
}
int main(void)
{
int M, N;
int i, j;
int n, x;
while (1)
{
n = 0;
scanf("%d %d", &M, &N);
if (M == 0 && N == 0) return 0;
for (i = 0; i < N; i++)
{
scanf("%d", &array[i]);
}
for (i = 0; i < M; i++)
{
scanf("%d", &brray[i]);
}
for (i = 0; i < M; i++)
{
x = binary(array[i], brray, 0, N);
if (x != -1) n++;
}
printf("%d\n", n);
}
return 0;
}