
오늘은 RNN 배우는 날~
Preview
- RNN 개요
RNN 개요
지금까지는 딥러닝에서 크게 FC와 Conv를 배웠음.
그런데 우리가 왜 이미지, NLP 학습할 때 Conv를 통과 시키고 FC에 입력했는데,
왜 먼저 Conv를 먼저 통과 시킨거임?
이미지에서는 위치적인 특징(예: 경계, 패턴, 형태 등)을 뽑기 위함이었음.
NLP에서는 문맥 간의 상관관계(예: 단어의 의미, 문장 내 패턴 등)를 뽑기 위함이었음.
즉, Conv는 데이터에서 공간적 특징을 추출하는 과정이었던거임.
그럼 RNN은 뭐냐 하면,
데이터에서 어떤 시간적인 특징을 뽑기 위한 모델인거임.
예를 들어 음성, 주식 데이터, 자연어 문장 등은 시간적 순서(sequence) 가 중요함.
즉, RNN은 이전 상태(hidden state)를 기억하면서, 시퀀스 데이터의 흐름을 학습하는 모델인거임.
그래서 NLP, 음성 인식, 주가 예측 등 시간적 패턴이 중요한 데이터에서 사용되는거임.
철수는 영희를 좋아해~
NLP에서 RNN을 사용하는 이유를 "철수는 영희를 좋아해"라는 문장으로 예시를 들어 볼거임.
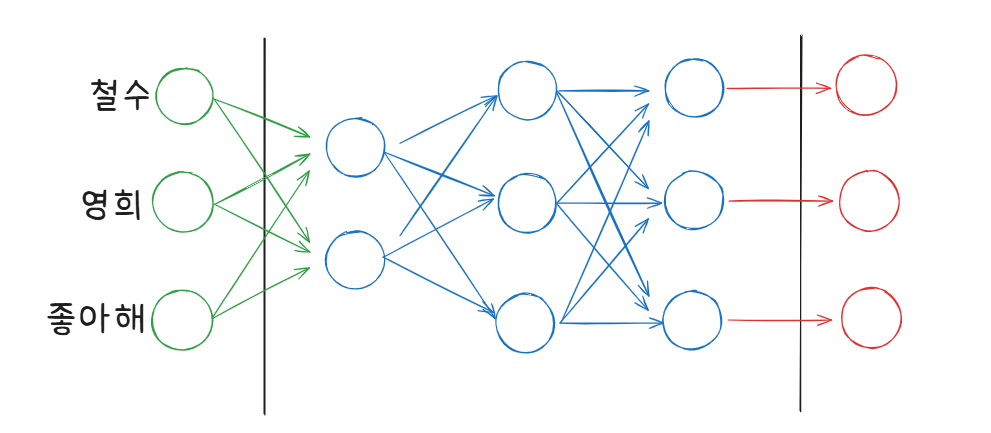
위 FC모델은 학습하는데 순서가 없음.
그냥 한 번에 학습이 진행됨.
이 상태에서는 철수가 영희를 좋아하는지, 영희가 철수를 좋아하는지 학습할 수 없는거임.
위 RNN모델은 학습하는데 순서가 있음.
"철수" -> "영희" -> "좋아해" 순으로 학습이 진행됨.
따라서 "영희는 철수를 좋아해"가 아닌, "철수는 영희를 좋아해" 같은 순서로 학습할 수 있는거임.
RNN 모델 입력, 출력
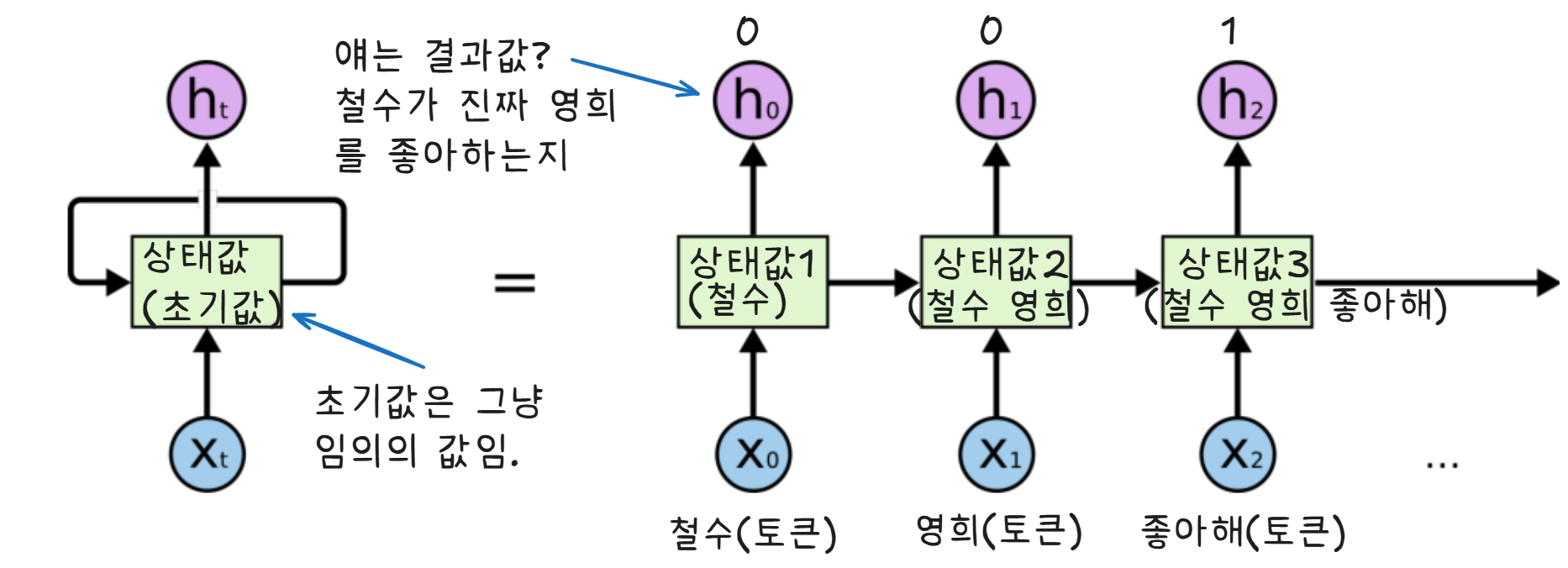
그러면 RNN의 학습 순서를 생각해보면,
각 단계의 처음에 입력이 2개가 있을 거임.
초기값(또는 이전 상태값), 토큰 이렇게 2개 일거임.
그럼 결과로 업데이트된 상태값이 나올거임.
이때 우리는 업데이트된 상태값을 2가지 길에 적용할거임.
첫 번째 길은 어떤 결과값을 만드는 h()라는 액티브 펑션에 업데이트된 상태값을 넣는것이고,
두 번째 길은 다음 상태값을 만드는 f()라는 펑션에 다시 넣는거임.
그러면 각 단계의 마지막 출력이 2개가되는거임.
h()를 통과한 결과값, f()를 통과한 결과값.
그러면 h()를 통과한 결과값과 f()를 통과한 결과값이 무슨 차이가 있냐? 를 물어본다면,
딱히 다를건 없음.
h()의 결과값은 모델이 학습한 결과? 라고 생각하면 되고,
f()의 결과값은 다음 상태값이라고 생각하면 됨.
h() 함수는 모델이 학습한 결과를 만들기위한 함수.
f() 함수는 다음 상태값을 만들기위한 함수.
조금 다른거는 각 단계에서 h()의 결과값이 스칼라값으로 하나씩나옴.
그러면 이 단계가 토큰 수 만큼있으니까 h()의 스칼라값을 모아서 벡터값을 만들 수 있음.
나중에 벡터인 h()의 결과들을 가지고 어떻게어떻게 활용할 수 있다고 함.
f()의 결과값은 계속해서 업데이트 되는거라서? 스칼라 값이라고 함.
위 글 GPT 해석본
RNN의 동작 원리
각 단계에서 입력(input)과 이전 상태(hidden state)가 2개의 입력으로 들어감.
즉, 각 RNN 셀의 입력은 다음과 같음:
- 현재 입력 단어(x_t, 즉 현재 토큰)
- 이전 단계에서 전달된 상태값(h_t-1, hidden state)
이 입력을 바탕으로, 각 단계에서 출력(output)과 다음 상태값(hidden state)이 2개의 출력으로 나옴:
- h_t → 다음 상태(hidden state, 메모리)
- y_t → 최종 출력(output)
💡 여기서 h_t와 y_t는 어떤 함수(f(), h())를 거쳐 계산됨
RNN에서 h()와 f()의 역할
- f() → 다음 상태값을 만드는 함수
- h_t = f(h_t-1, x_t)
- 이전 상태(h_t-1)와 현재 입력(x_t)을 사용하여 다음 상태(h_t)를 생성함
- 일반적으로 tanh 또는 ReLU 같은 활성화 함수를 사용 - h() → 출력값을 만드는 함수
- y_t = h(h_t)
- 현재 hidden state(h_t)를 바탕으로 최종 출력(y_t)을 생성
- NLP에서는 y_t가 단어 예측, 감정 분석 등의 결과가 될 수 있음
- 보통 h()는 softmax나 linear layer를 사용하여 변환함
💡 즉, h_t(hidden state)는 다음 단계로 넘겨주는 "메모리" 역할을 하고, y_t(output)는 우리가 실제로 사용하는 값!
RNN에서 hidden state와 output의 차이점
| 구분 | 역할 | 예시 |
|---|---|---|
h_t (hidden state) | 다음 단계로 넘겨줄 "메모리" | 문맥을 유지하는 정보 |
y_t (output) | 최종 출력 값 | 예측된 단어, 감정 분석 결과 등 |
- h_t는 계속 업데이트되며 전달됨 (메모리 역할)
- y_t는 각 시점마다 나오는 최종 결과값 (출력 역할)
추가 보충: RNN의 출력 방식
각 단계에서 h()의 결과값(y_t)이 나오는데, 이걸 여러 개 모아서 벡터 형태로 만들 수도 있음.
💡 이렇게 모은 y_t를 나중에 어떻게 활용하냐에 따라 모델의 종류가 달라짐.
- 모든 y_t를 모아서 마지막에 한 번만 출력 → "many-to-one" 구조 (예: 감정 분석)
- 각 y_t를 그대로 사용해서 연속된 출력 → "many-to-many" 구조 (예: 번역)
최종 정리
- RNN은 "시간적 순서"를 학습하는 모델!
- 각 단계에서 입력(x_t) + 이전 상태(h_t-1) → 출력(y_t) + 새로운 상태(h_t)가 만들어짐.
- f()는 새로운 상태(hidden state)를 계산하는 함수
- h()는 출력값(output)을 만드는 함수
- h_t는 계속 전달되며 문맥을 유지하는 역할, y_t는 실제 모델이 예측하는 값.
RNN의 종류 그림
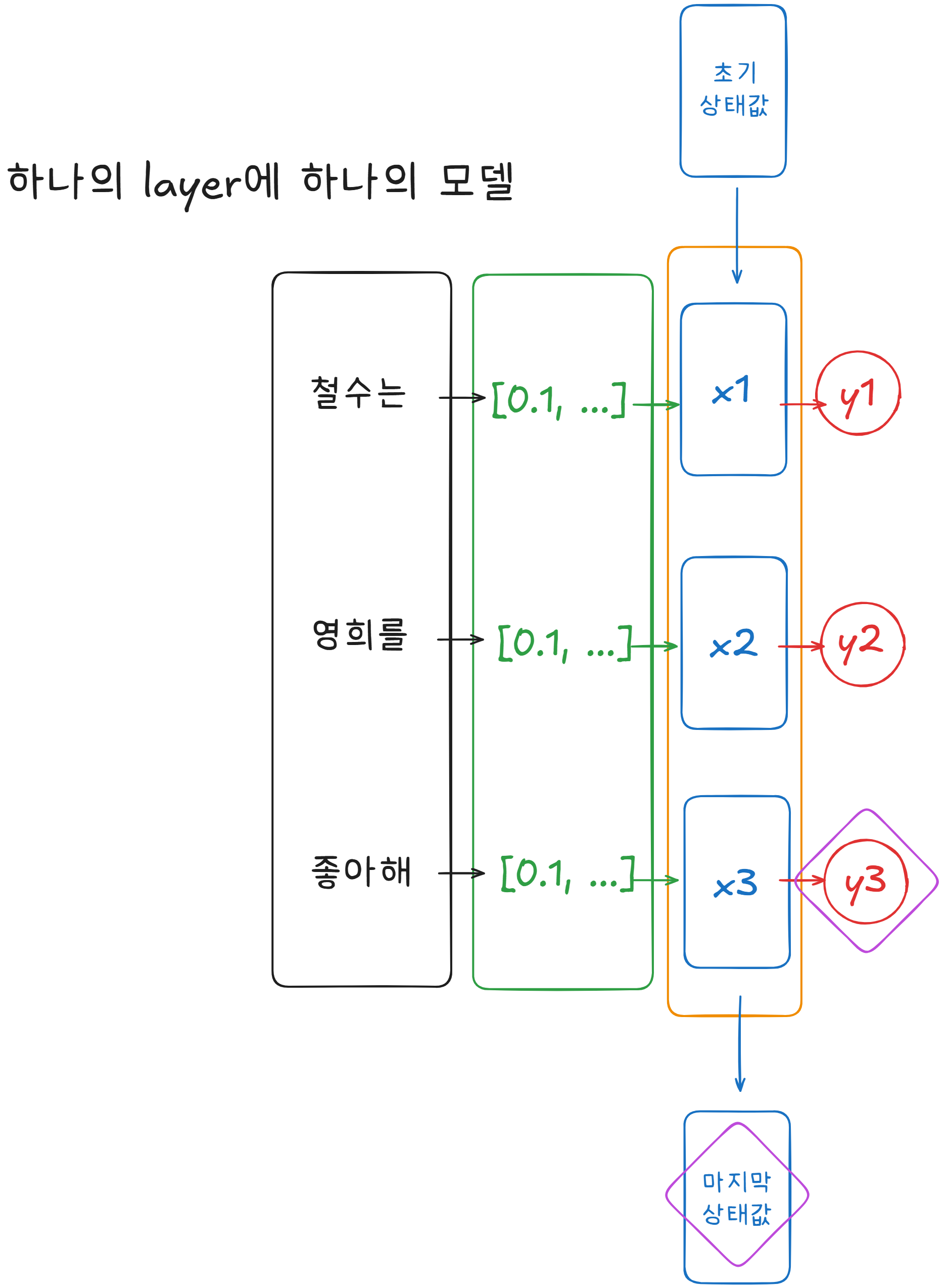
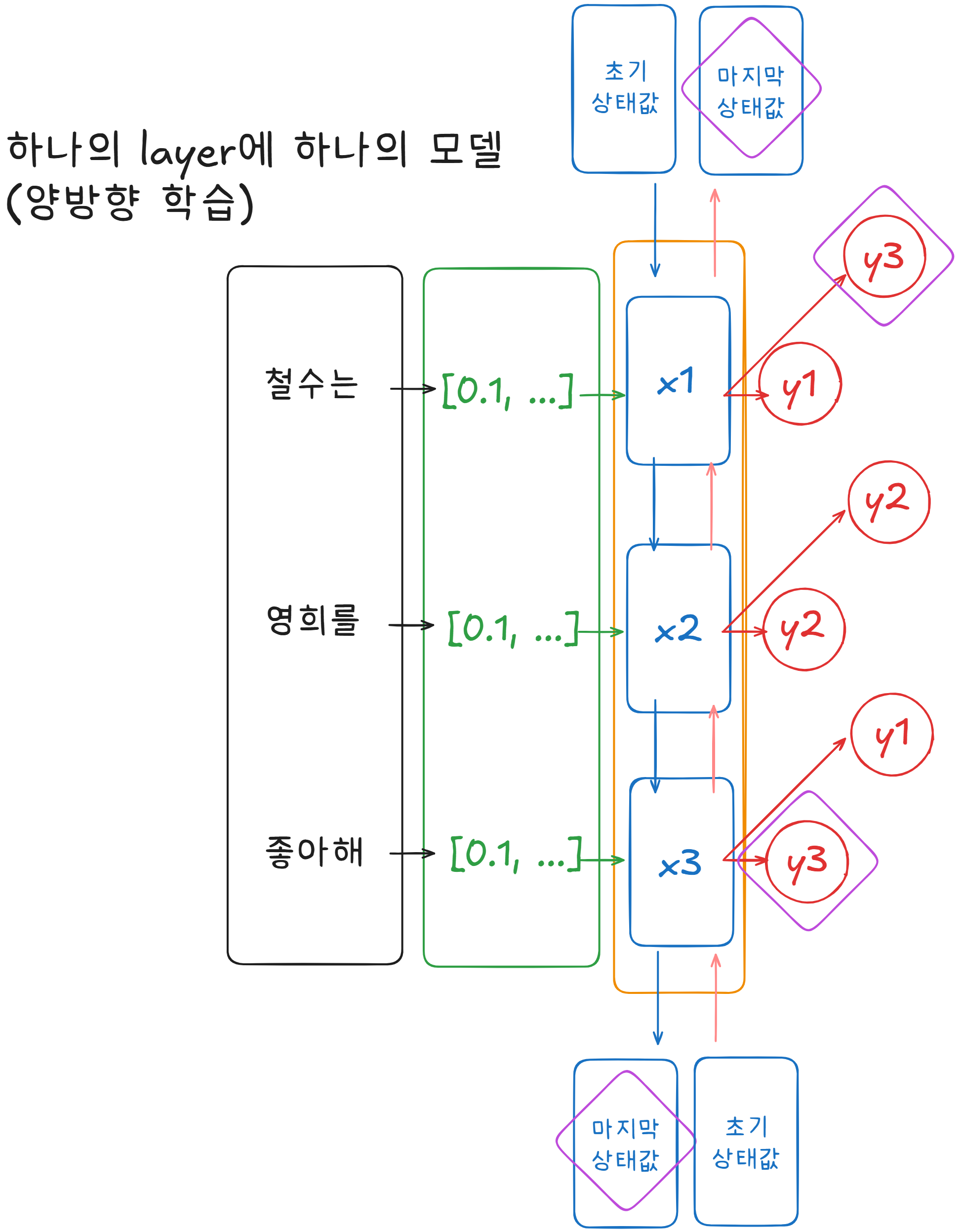
하나의 Layer에 하나의 Model
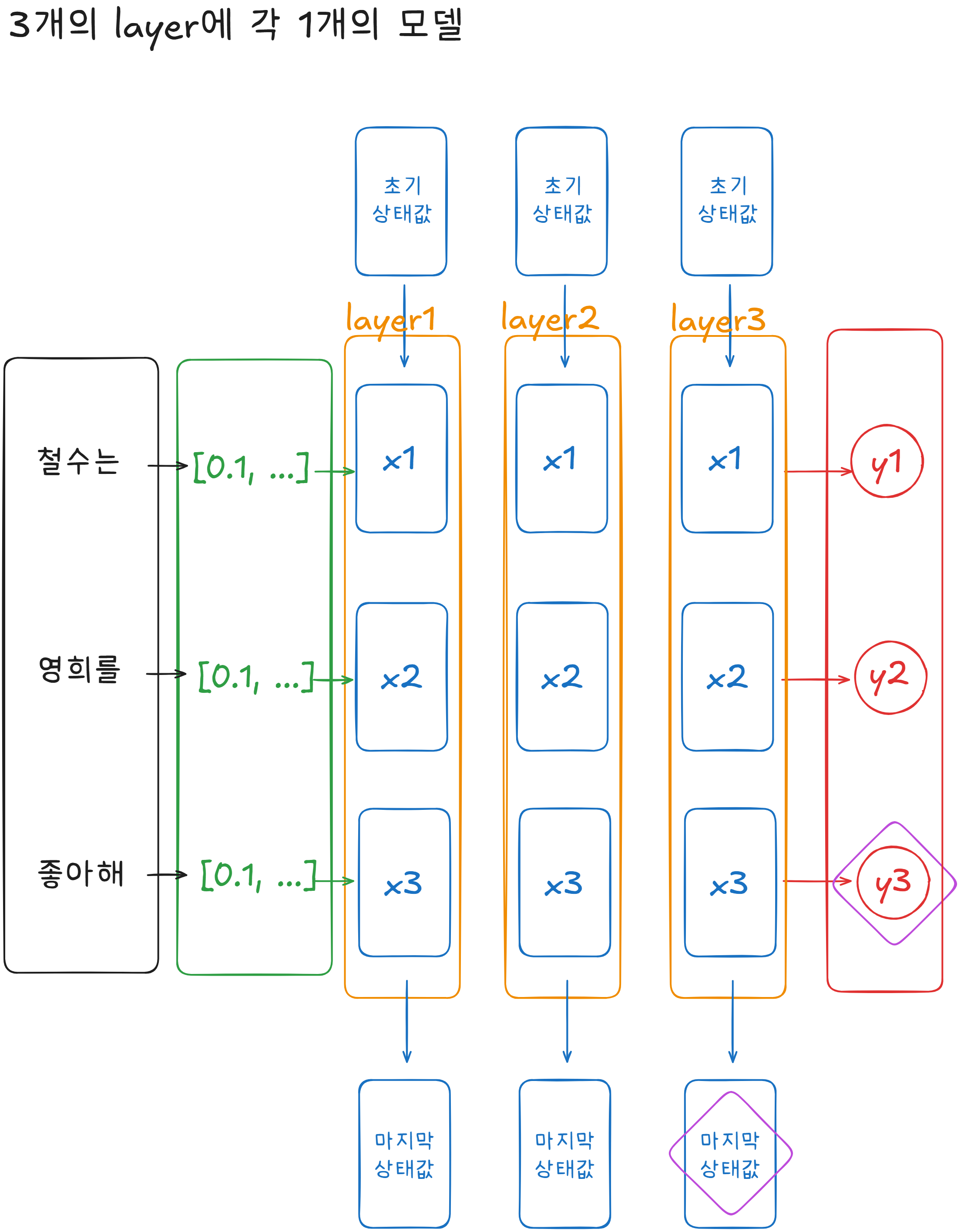
3개의 Layer에 각 1개의 Model
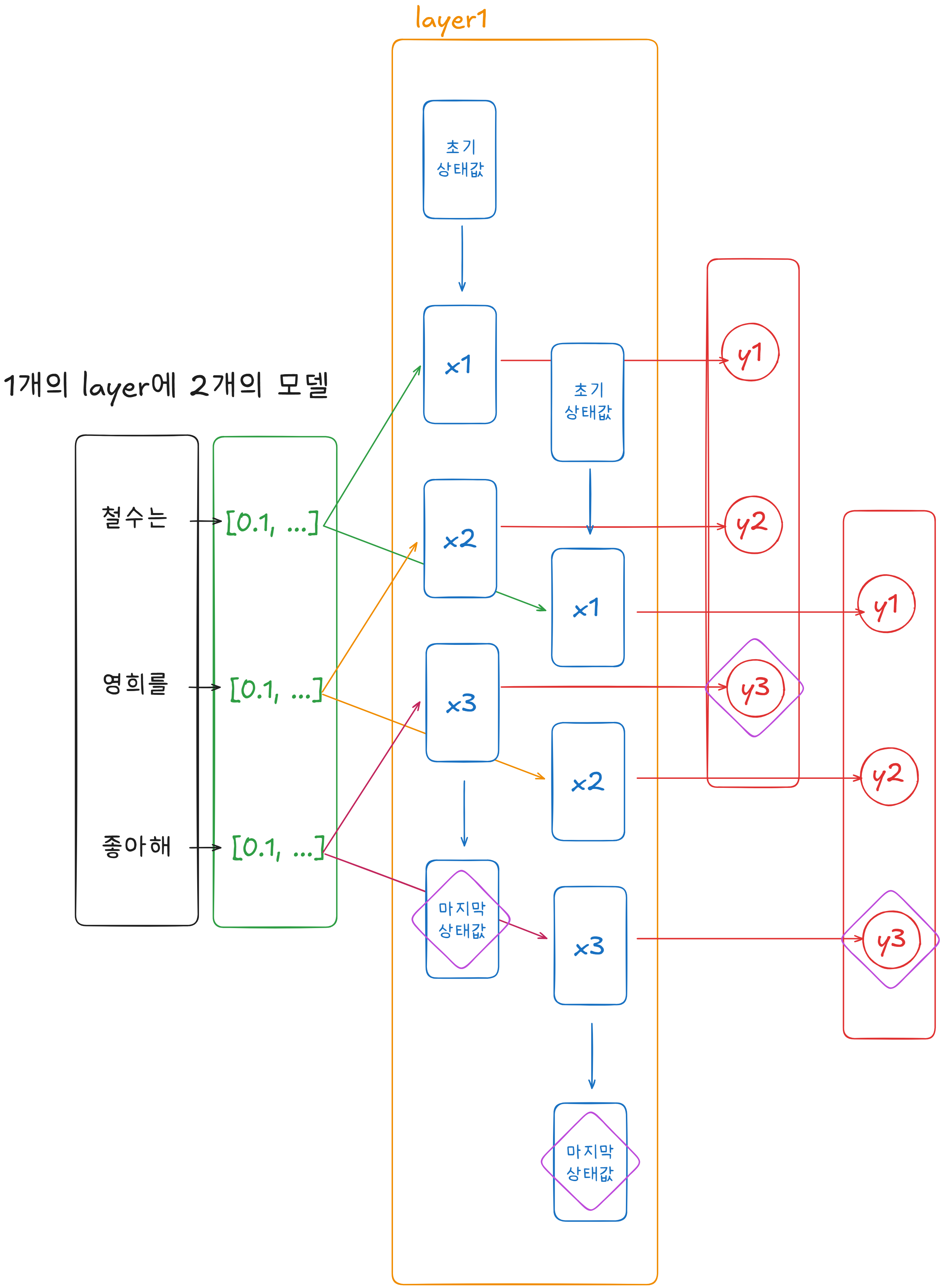
1개의 Layer에 2개의 Model
양방향 학습
"하나의 Layer에 하나의 Model" 그림을 수학적인 표현으로
x1 = f(x0, u1), u1 = "철수는"
x2 = f(x1, u2), u2 = "영희를"
x3 = f(x2, u3), u3 = "좋아해"
만약 f()함수를 그냥 덧셈 함수라고 무식하게 생각해보면
x1 = x0 + u1
-> 비율: u1:50
x2 = (x0 + u1) + u2
-> 비율: u1:25, u2:50
x3 = ((x0 + u1) + u2) + u3
-> 비율: u1:12.5, u2:25, u3:50
어? 점점 처음 학습한 토큰의 비율이 줄어들고 있음.
그러면 이 RNN은 토큰이 많아질수록 처음 학습했던 토큰 데이터를 까먹게되는거임.
이것을 해결하기 위해 반대방향으로 한번 더 학습해주면 됨.
모델이 2개다 라고 생각하면 편함.
첫 번째 모델은 순방향으로 학습,
두 번째 모델은 역방향으로 학습.
