
LLM 개요
ChatGPT같은 LLM은 만들기 어려움.
GPU하나에 몇 천 만원인데 그게 수십개가 필요함.
따라서 일부 대규모 회사에서만 자체적으로 LLM을 만들 수 있는거임.
그러면 우리는 우리만의 LLM을 어떻게 만들 수 있나? 하면
파인튜닝, RAG, 프롬프트 엔지니어링 등으로 우리가 원하는 대답을 하도록 할 수 있음.
파인튜닝은 기존에 만들어진 LLM모델에 추가적으로 내가원하는 데이터를 학습시키는 거임.
RAG는 기존에 만들어진 LLM모델이 내가 원하는 데이터를 벡터 DB 같은 곳에서 참고할 수 있도록 해주는 거임.
프롬프트 엔지니어링은 기존에 만들어진 LLM모델에게 질문할 때 직접 추가적인 정보를 제공해주는거임.
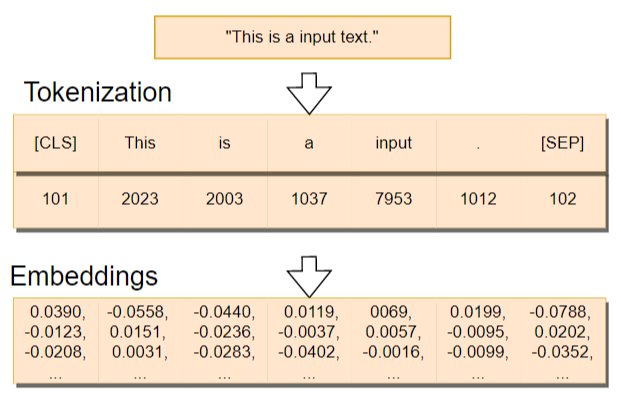
자연어 처리 과정
문장: I am a student!!
1. Cleaning: I am a student
2. Stemming: I be a student
3. Stopword: I be student
4. Tokenize: [I, be, student]
5. Vocabulary: {0: 'I', 1: 'be', 2: 'student'}
6. Embedding: {0: [벡터], 2: [벡터], 3: [벡터]}
LLM 학습
LLM 모델을 학습시킬때 나는 어떤 문자열, 어떻게 보면 스칼라 값을 넣는것 처럼 보이지만,
실제로는 문자열을 토큰화하고 벡터화한 matrix를 넣는 것이다.
matrix는 이렇게 표현될 수 있음.
A_(7, 100) 정도 될 것 같은데 여기서 row는 단어의 개수이고 col은 벡터 차원의 수임.
만약 LLM을 이 matrix로 학습시킨다고 가정했을 때, 문제가 발생할 수 있음.
LLM은 아마 딥러닝?으로 학습을 시킬텐데 딥러닝이 받는 입력 matrix의 모양은 동일해야함.
벡터 길이(100)은 상관없음.
각 단어는 어떤 Tokenizer을 사용하느냐에 따라 벡터 차원의 수가 다르긴하지만 한 단어에 대해 한 모델이 내밷는 벡터는 동일할 거임.
우리가 맞게 설정만 해주면 됨.
그런데 단어 개수(7)은 상관이 있음.
학습되는 단어, 토큰의 수가 데이터 마다 다른데 어떻게 학습할 거임?
예를 들면 어떤 문장들에 대해서 같은 Tokenizer을 사용하면 아래와 같이 될 거임.
ex) (7, 100), (5, 100), (11, 100) ...
이렇게 만들어지면 모양이 달라서 학습할 수가 없음.
이때 우리는 패딩 토큰을 사용함.
우리가 LLM을 학습시킨다면 최대 토큰 수를 정해놓아야함.
스페셜 토큰
패딩 토큰: 벡터를 만들고 나서 남는 공간을 채울 토큰
언노운 토큰: 만약 학습하지 않은 단어가 입력으로 들어왔을 때 언노운 토큰으로 대체함.
잡다
딥러닝, PyTorch 이런거보다 머신러닝을 기초로 깔고 가는것이 좋다.
머신러닝은 원-핫 인코딩, 딥러닝은 Word2Vec을 주로 사용한다.
