☁️ AWS Personalize로 추천 시스템 구축: 행동 데이터 추가로 성능 2배 향상시키기(feat: Airflow)
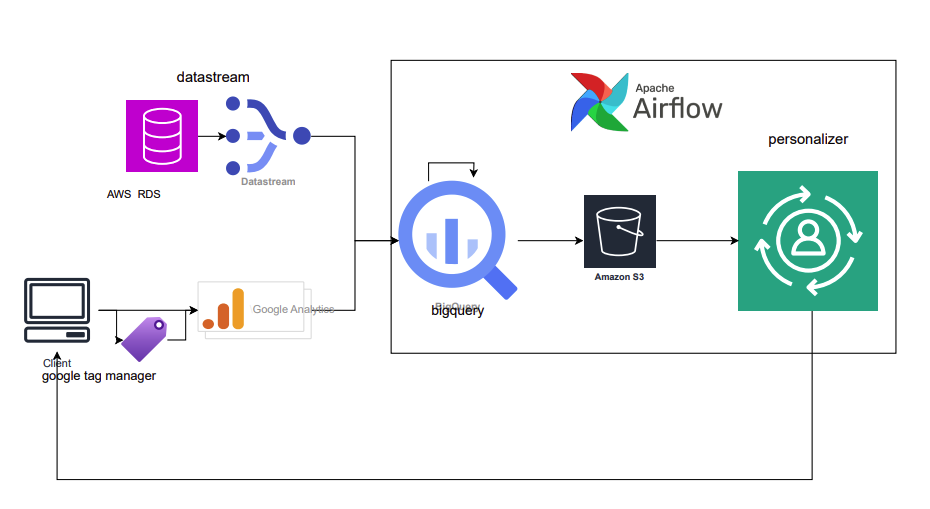
클라우드 서비스를 이용한 추천 시스템 구축과 성능 개선을 위한 데이터 파이프라인 구축 및 재학습 파이프라인 구축 과정을 공유하고자 합니다
🧑💻 상황: 문서도 없고, 데이터도 낯선 상태
빠르게 추천 시스템을 구축해야 하는 상황이었습니다. 하지만 팀에는 데이터 히스토리를 잘 아는 멤버도, 문서도 없는 상태였습니다. 다른 팀원들이 외국에서 원격 근무 중이라 실시간 협업도 쉽지 않았습니다.
우선 데이터베이스를 살펴보니 상품 정보와 구매 데이터는 있었지만, 사용자 정보와 행동 데이터가 부족해 학습에 쓸 feature가 충분하지 않다는 생각이 들었습니다.
💡 이런 환경에서 직접 모델을 만들기보다 기존 모델에 데이터를 넣어 학습시키는 방식이 현실적이라는 판단을 했습니다.
팀은 AWS를 메인 클라우드 서비스로 사용하고 있었고, 리서치 끝에 Bedrock, SageMaker, Personalize를 검토했습니다. 이 중 적은 feature로도 빠르게 개인화 추천을 제공할 수 있는 Personalize를 최종 선택했습니다.
AWS Personalize를 이용한 추천 시스템 구현 ver 1.
Amazon Personalize는 내부적으로 Amazon의 추천 시스템을 기반으로 하고 있으며, 사용자 데이터를 학습해 API 형태로 추천 결과를 제공합니다. 다만 내부 모델이 어떻게 동작하는지는 블랙박스입니다.
📌 장점
-
최소한의 데이터 스키마만 만족하면 빠르게 학습 가능
-
API 연결로 서비스에 빠른 적용 가능
🗄️ 데이터셋 구성 예시
- Interaction Dataset
| user_id | item_id | event_type | timestamp |
|---|
- Item Dataset
| item_id | price | category_L1 | category_L2 | is_available |
|---|
- User Dataset
| user_id | created_at |
|---|
데이터베이스에서 데이터를 추출해 변환한 뒤 S3에 적재하고, Dataset → Solution(Model) → Campaign을 생성하면 API 호출로 추천을 받을 수 있습니다.
Dataset을 위해 Product DB에서 추출한 데이터를 변환하여 S3에 적재하는 과정이 필요하며, 적재 후에 Dataset 업데이트, 솔루션 업데이트, 캠패인 업데이트를 각각 트리거하면 됩니다. 각 과정이 끝났는지 폴링을 하며 센싱을 한 뒤에 뒤의 과정을 트리거하는 방식을 채택했습니다.
이 때까지는 구매 데이터만 사용했기 때문에 구매 주기를 분석하여 배치 학습의 주기를 1일로 지정하였습니다.
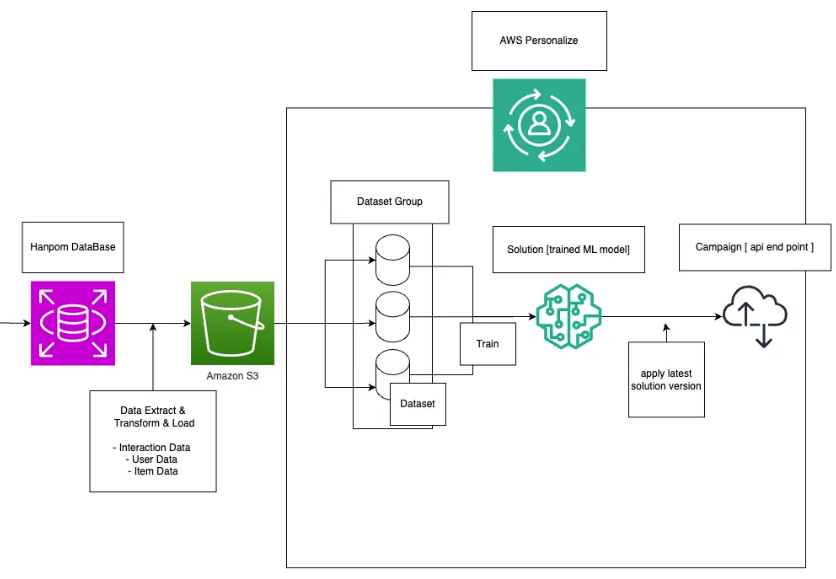
🔄 재학습 파이프라인 (Ver1)
-
데이터 추출/변환 → S3 적재 → Dataset 업데이트 → Solution 업데이트 → Campaign 업데이트
-
각 과정 완료 여부는 폴링 센싱 후 다음 단계 트리거
-
Cron 스케줄러로 재학습 주기: 1일 (구매 데이터 기반)
🛡️ Cross-account 문제 해결
메인 서버와 Personalize 인프라가 서로 다른 계정에 있어 Cross-account pass role is not allowed 오류가 발생.✅ 해결: IAM에 sts:AssumeRole 권한 추가 → assumeRole()로 임시 권한 발급 → 호출 성공
사용자 행동 데이터를 추가한 Ver 2.
- 🕵️♀️ 사용자 행동 데이터 추적하기
구매 데이터를 이용해 학습했을 때, 구매 이력이 있는 유저에 한하여 추천이 가능하고 구매는 sparse한 데이터이기 때문에 구매 외에도 더 다양한 interaction data가 필요했습니다.
프론트 엔지니어분과 이야기를 나누었을 때 과거 GA를 사용했었지만 지금은 관리가 되고 있지 않은 것을 알 수 있었습니다. 과거 심어져 있던 GA 이벤트를 추적하며 해당 GA 이벤트가 exprot되고 있는 bigquery를 발견할 수 있었습니다. (문서화가 되있지 않은 상태로 관리자가 바뀌며 자연히 잊혀진 상태였습니다) 이 과정은 마치 먼지가 잔뜩 쌓인 창고를 발견하는 것과 같았습니다.
Bigquery를 이용해서 현재까지 수집이 문제 없이 되고 있는 데이터와 되지 않는 데이터를 분류하고, front 코드를 기반으로 해당 필드가 Database의 어떤 필드와 연결되는지, 어떤 의미를 갖는지 정리하여 데이터 Taxonomy를 만들었습니다.

- Airflow를 이용한 데이터 ELT, ETL, 재학습 파이프라인 구축
airflow를 선택한 이유는 여러 가지 task들의 성공 실패 여부를 웹 UI를 통해 빠르게 확인 가능하기 때문에 혼자서도 관리하기 수월하기 때문입니다. Bigquery 뿐만 아니라, python Operator 또는 python 함수를 task로 만들어 사용할 수 있는 유연성도 존재하여 이후에 대시보드나 주요 리포트 생성으로도 확장 가능하기 때문에 채택하게 되었습니다.
Airflow는 인프라 엔지니어분과 논의하여 AWS MWAA를 이용해 배포하였고, 위와 마찬가지고 Worker에 대한 Cross-account 문제는 sts:AssumeRole 권한을 추가하고 assumeRole()을 통해 해결해주어야 합니다.
GA 데이터는 exprot를 통해서 bigquery에 적재가 되었고, Product DB의 경우 GCP의 Datastream을 통해 bigquery 테이블에 적재하였습니다.
GA 데이터 병합
GA데이터는 event_date에 따라 별개의 테이블로 적재가 됩니다. 이를 하나의 테이블로 합쳐서 관리하기 위해서 event_date를 partition으로 하는 하나의 raw table을 생성하였습니다.

GA 데이터가 적재되는 시간을 매번 다른데, 해당 파이프라인이 동작할 때 먼저 해당 날짜의 GA 데이터가 적재되었는지 먼저 체크하고 있다면 병합을 진행하도록 했습니다. 이는 나중에 fail이 되었다면 원천 데이터의 누락인 것을 인지하고 확인 후 수동으로 트리거하기 위함이었습니다.
GA 데이터 정제
병합된 raw 테이블에서 각 event를 기준으로 필요한 데이터를 정제하여 별개의 테이블로 관리했습니다.
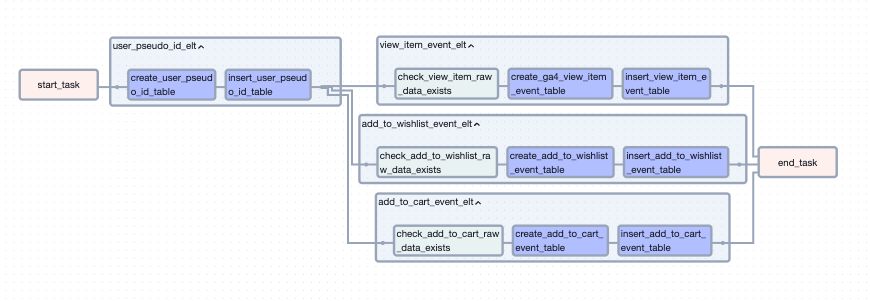
데이터가 존재하는지 확인 -> 테이블이 있는지 확인 후 없으면 생성 -> 데이터 insert 과 정으로 진행되었습니다. {{ ds }} 값을 partition으로 지정하여 관리했습니다. 이를 통해 Product DB에는 없는 유저의 행동 데이터를 사용할 수 있게 되었습니다
Personalize 데이터 ETL
이제 준비된 GA 데이터와 Product DB의 데이터를 학습에 사용될 스키마 형태로 가공하여 S3에 적재하는 ETL 파이프라인을 구축할 수 있게 되었습니다.
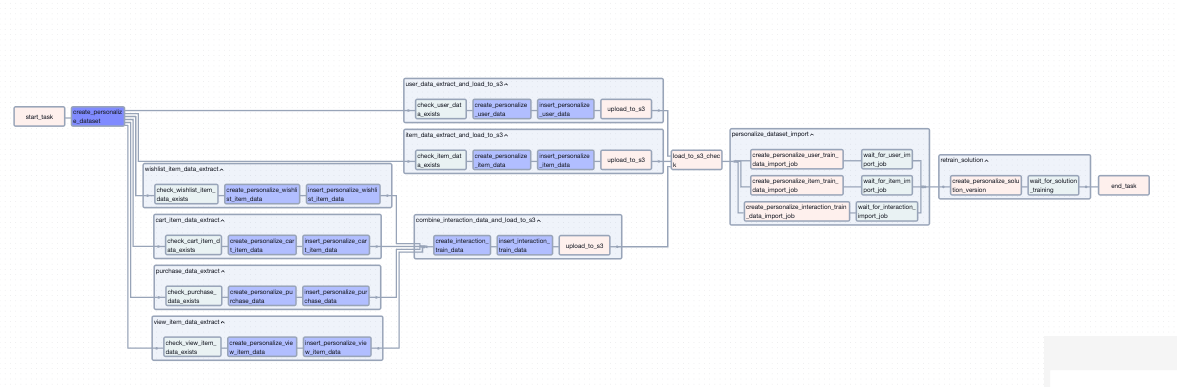
유저의 행동 데이터와 구매 데이터를 병합하여 Interaction 데이터로 만들고, 나머지 User, Item에 대한 추출과 변환도 진행해주었습니다. S3 적재와 Personalize Python 함수를 task로 만들어 진행하였습니다.
이 때 유저에게 지속적으로 새로운 Item set을 노출시켜주는 것이 중요하다고 판단하였기에, GA 데이터의 정제의 성공 실패 여부와 별개로 Personalize Dag는 수행되도록 하였습니다. Personalize는 같은 Dataset이여도 새로운 학습을 진행하면 추천 항목이 달라지기 때문입니다.
행동 데이터 추가 이후 성능 지표 변화
Personalize에서는 Solution 별로 추천 성능 지표를 제공합니다
두 모델 (첫 번째 = Ver1, 두 번째 = Ver2) 의 성능 지표를 비교했을 때 다음과 같은 향상이 있었습니다
| 지표 | 첫 번째 모델 | 두 번째 모델 | 변화 | 의미 |
|---|---|---|---|---|
| NDCG @25 | 0.1973 | 0.3380 | 🔼 +71% | 관련 아이템이 추천 리스트 상위로 더 이동 |
| Precision @5 | 0.0395 | 0.0921 | 🔼 +133% | 추천 아이템 중 실제 관심 아이템 비율 증가 |
| MRR @25 | 0.1216 | 0.2752 | 🔼 +126% | 첫 번째 정답 아이템이 상위권에 더 잘 위치 |
| Coverage | 0.2509 | 0.4299 | 🔼 +71% | 더 많은 아이템이 추천에 포함 (다양성 증가) |
구매라는 데이터가 커머스에서는 다른 이벤트에 비해서 sparse한 데이터인데, 이를 보충할 수 있는 행동 이벤트(장바구니, 좋아요, 조회)를 통해서 유저의 선호 판단이 이전보다 향상 되었다고 생각합니다.
또한 사용중인 레시핀인 Personalize-v2는 Transformer 기반 모델로 구매 뿐만 아니라 조회, 장바구니, 좋아요 등의 행동을 통해서 행동 패턴(맥락)을 파악하여 관심사를 추론하기 때문에 행동 데이터 추가시에 성능의 향상이 일어났다고 생각합니다.
마치며
처음에는 생소한 환경에서, 낯선 데이터들을 보며 어떻게 추천 시스템을 구축할 수 있을지 걱정이 앞섰습니다. 하나씩 해나가자는 마음으로 천천히 데이터 베이스를 뜯어보고, 코드를 보면서 현재 상황을 파악하는 일은 쉽지 않았습니다. 하지만 하나씩 해나가면서 자신감이 조금씩 붙기 시작했습니다. 오래도록 관리되지 않은 먼지 쌓인 GA 데이터와 Bigquery 테이블을 새롭게 단장하고 다시금 동작하도록 기름칠하고 새롭게 파이프라인을 구축했을 때는 청소를 깔끔히 한 뒤의 뿌듯함과도 같았습니다. 또한 Cursor, Claude Code, GPT의 발달로 막막한 부분에 대해 도움을 받을 수 있어 작업 효율이 올라간 것을 체감할 수 있었습니다
