Numpy Structured Array
이전 포스팅에서 numpy array의 빠른 이점에 대해서 알게 되었다.
하지만 실제 프로젝트에서는 여러형태의 data type으로 구성된 list를 다룰 경우가 더 많았다. 이럴 때는 어떻게 numpy array를 사용하여 그 이점을 활용할 수 있을까?
Numpy Structured Array
만약 여러 data type을 가진 리스트를 numpy array로 만들면 어떤 결과가 나올까?
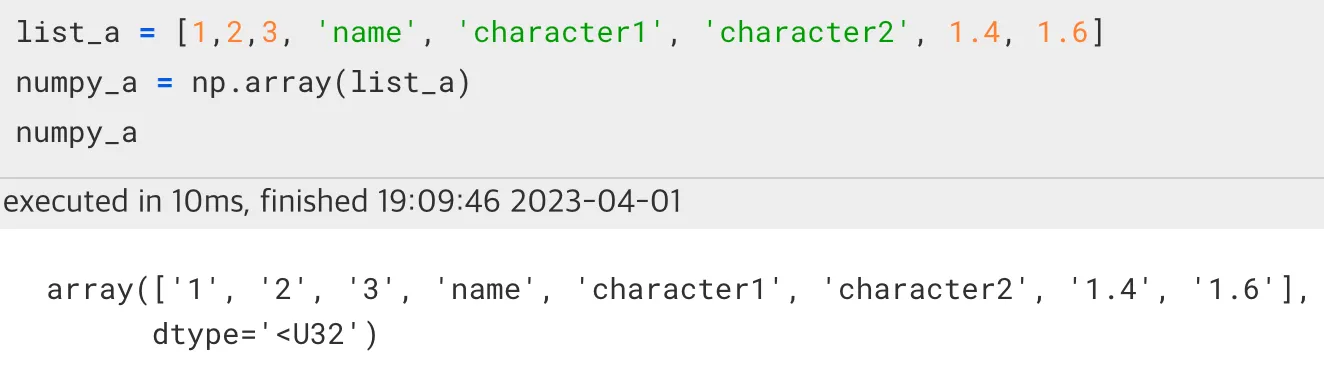
결과적으로, 모두 문자열의 형태로 바뀌는 것을 알 수 있다.


numpy 공식 문서를 살펴 보면 structured array는 c에서의 구조체(struct)를 모방하여 만들었다는 것을 수 있다. 따라서 여러 데이터를 가진 구조체의 배열 형태로 이해할 수 있다.

다음과 같은 형태로, 구조체 안에 리스트가 있을 때는 그 크기를 명시적으로 적어주어야 한다(메모리 상에 크기를 미리 지정하기 위함으로 생각한다)
dtype = object와는 무엇이 다른 것일까?

이렇게 numpy array를 생성하고자 하면 결과에서 dtype을 object로 명시해줘야 한다는 warning을 볼 수 있다.
dtype = object로 지정하면 어떤 일이 발생하는지 궁금하여 찾아보던 중 다음과 같은 답변을 찾을 수 있었다

결국에 dtype object를 이용하면 기존의 파이썬이 list를 관리하는 것과 크게 다를 것이 없다는 것이다. 이렇게 되면 결국 Pyobject를 가지게 되는 것으로 numpy의 이점을 사용할 수 없다고 생각한다.
이를 확인해보기 위해서 간단하게 주소값을 찍어보기로 했다
- dtype = object일 때,
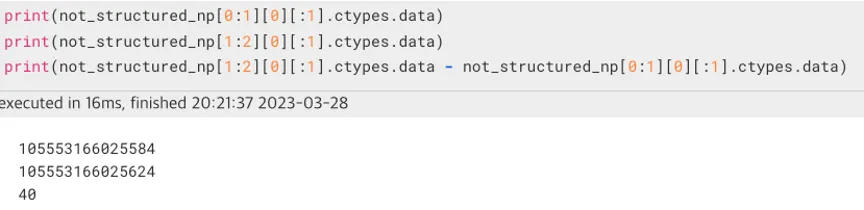
- dtype = user_numpy_dtype (structured numpy array)
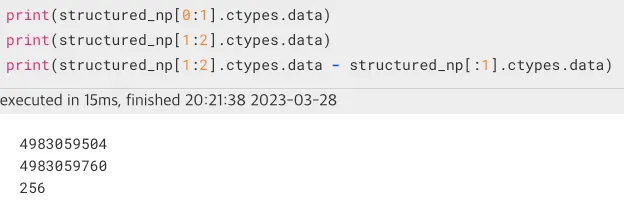
같은 형태의 list를 어떻게 numpy array로 만드는지에 따라 item의 시작 주소값의 차이가 달라졌다.
여기서 다음과 같이 data안에 특정 list에 값을 추가하여 여전히 주소값이 바뀌지 않는지 확이해봤다
바뀌지 않는다면 주소값을 가지고 있는 것이 맞고, 바뀐다면 ctype의 data의 시작 주소를 가리키는 것(단일 포인터)이 맞기 때문이다
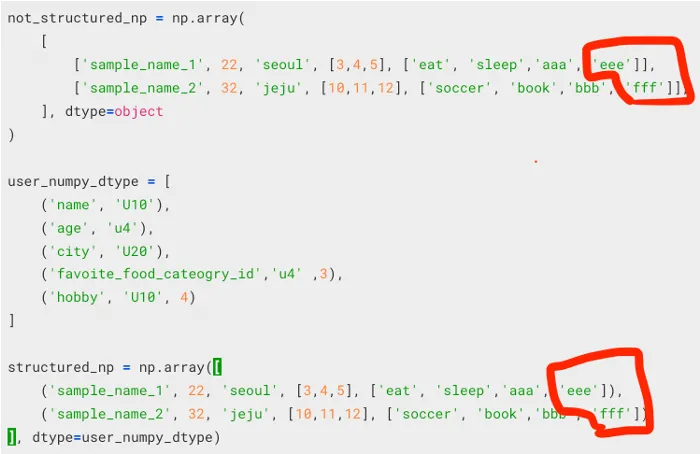
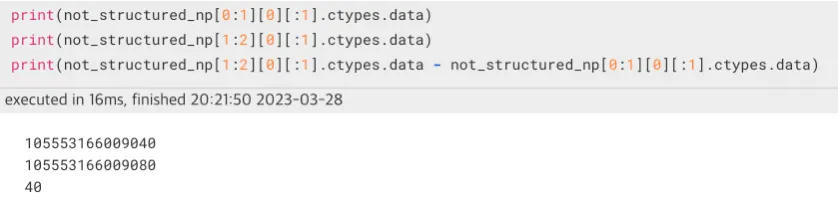
- dtype = object일 때,
- dtype = user_numpy_dtype (structured numpy array)
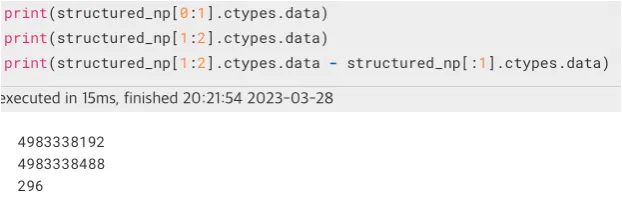
dtpye object의 경우 주소값의 차가 바뀌지 않았지만, structured array의 경우 주소값의 차가 변경되었다. 따라서 structured array로 만들면 cdtype의 data를 가리키는 형태(단일 포인터)임을 알 수 있다.
이를 또 알 수 있는 방법이 연산에 대해서 dtype=object는 파이썬의 연산이 동작하고 structured array는 ctype의 연산이 수행됨을 보는 것이다
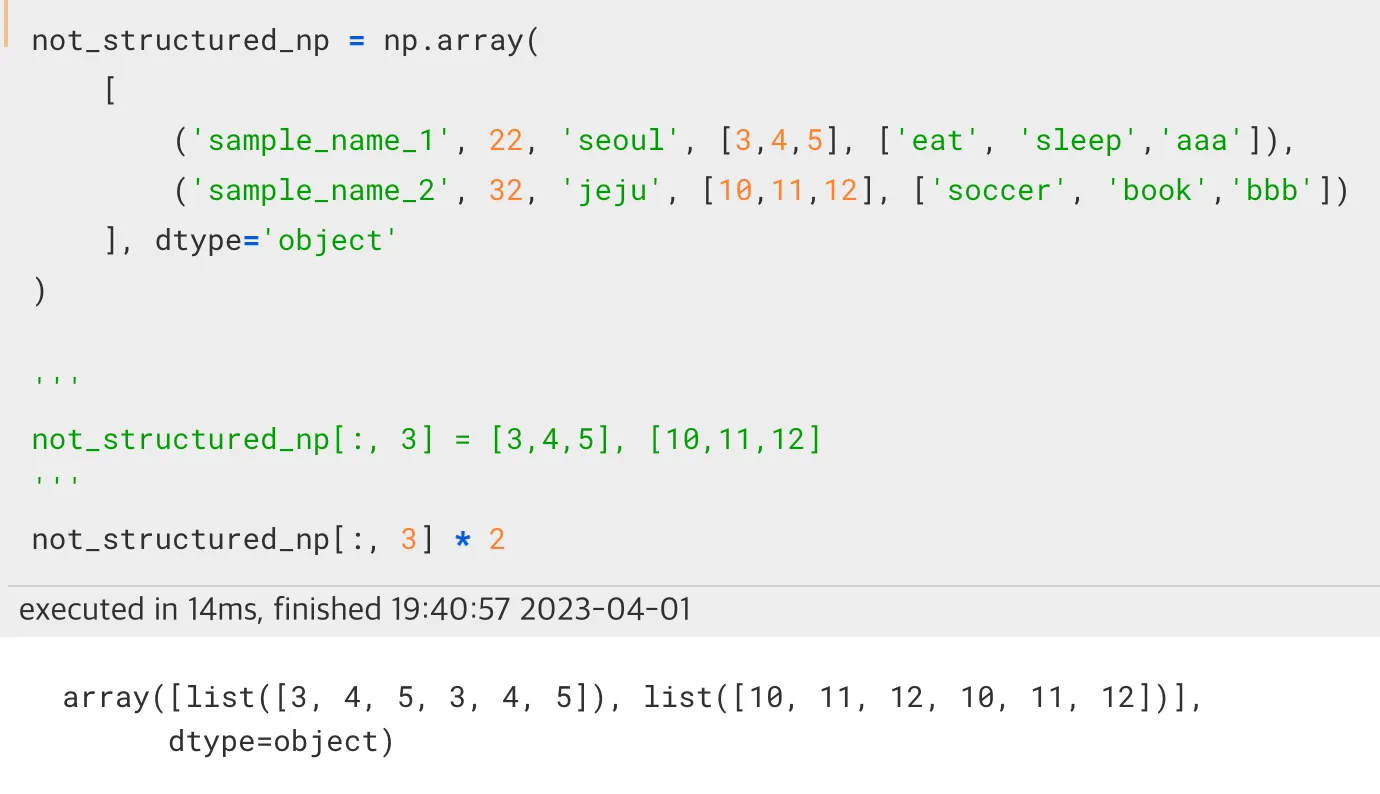
dtype=object에 대해서 * 연산이 반복자 연산으로, python list에 대해서 적용되는 것을 알 수 있다.
반면 structured array의 경우 * 연산이 ctype의 연산이 적용되어 vectorize연산이 이뤄짐을 알 수 있다
