Python list and Numpy array
현재 진행중인 프로젝트에서 많은 상품의 정보를 한 번에 받아놓고 후에 특정 feature에 따른 조건 검사를 할 때 numpy를 사용한다. 이 때 numpy array를 사용한 이유는 numpy가 python list보다 빠른 속도와 메모리 효율을 가지며, vectorize가 가능하기 때문이다.
List 와 Array
list와 array 모두 같은 특성을 갖는 데이터가 순서를 가지고 구성되어 있는 선형 구조이지만, 메모리 상에 어떻게 저장되어 있는지에 따른 많은 차이점을 지닌다
list는 메모리 상에서 비연속적으로 저장(연결 리스트)되며, 때문에 메모리 상의 빈 공간을 효율적으로 사용할 수 있다. 연결 리스트이기 때문에 데이터의 크기가 가변적일 수 있다. 하지만 데이터 접근 관점에서 O(N)의 시간이 들어간다.
array는 메모리 상에서 연속적으로 저장되며, 따라서 같은 크기의 데이터로 구성이 되어야 한다(접근을 위해서). 때문에 크기가 정적이다. 하지만 데이터 접근이 O(1)의 복잡도를 갖는다(메모리 시작 주소 + 데이터 크기 * 인덱스)
array의 경우 물리적으로 연속적으로 저장되어 있기 때문에 cache hit rate 또한 높다(Principle of Locality).
Python list
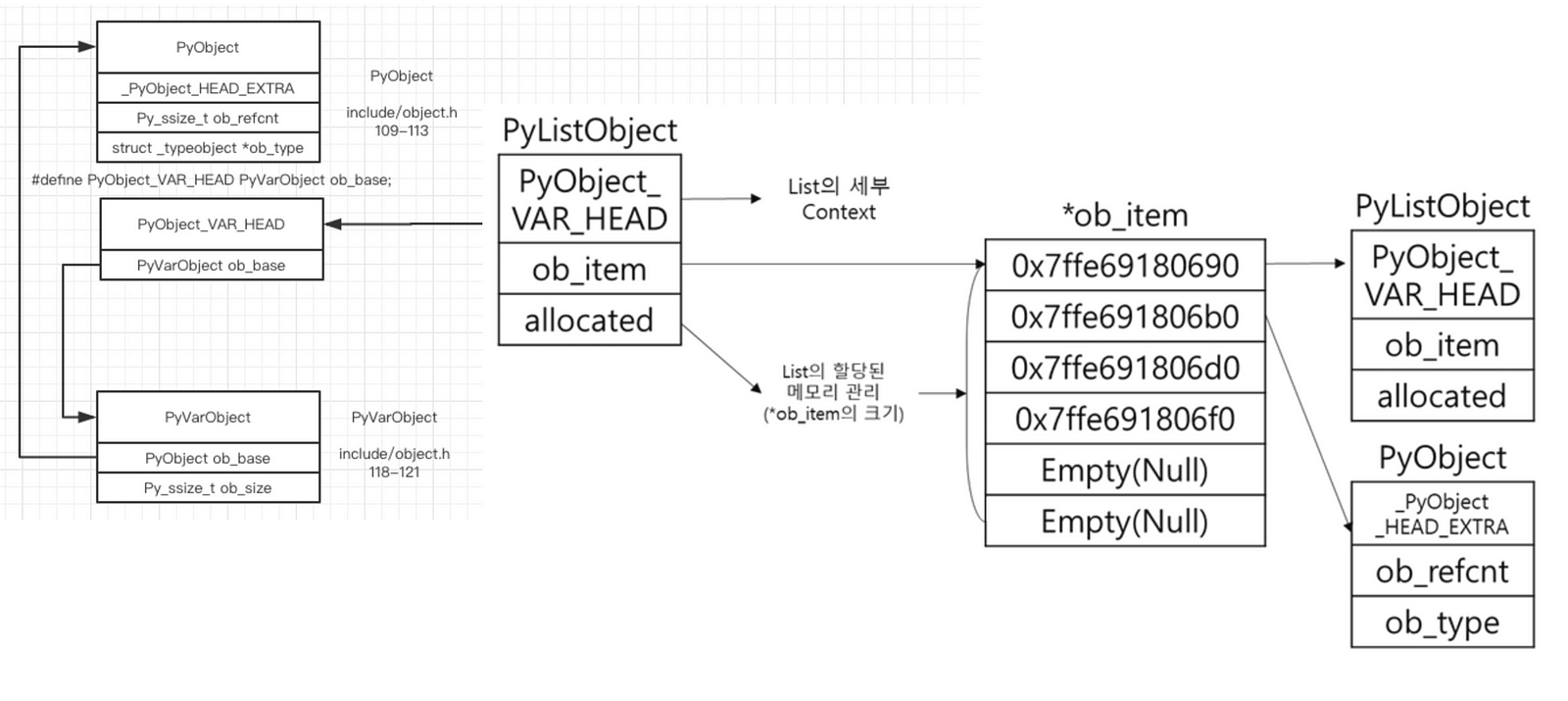
python list를 구조화 하면 다음과 같은 형태이다. python은 object class를 상속받은 객체들로 이뤄져있다
여기서 ob_item을 통해서 python list가 item을 어떻게 관리하는지 볼 수 있다. ob_item은 각각의 item 객체의 주소를 가지고 있고 이 주소를 통해 실제 item 객체에 접근해야하는 2중 포인터 구조를 가지고 있다.
결국 마지막에 가서 존재하는 것이 Pyobject이기 때문에 연산에 대해서도 python 연산을 따른다. Pyobject type의 연산은 중간중간 type check에 따른 다수의 except처리가 존재하여 ctype연산보다 긴 시간이 걸리는 것은 당연하다.
Numpy Array

Numpy array의 구조는 다음과 같다. python list와 가장 다른 점은 데이터가 2중 포인터 형태가 아닌, 단일 포인터로 관리 된다는 것이다. 또한 데이터가 저장되어있는 형태가 Pyobejct가 아닌 메모리에 직접적으로 값이 저장되어 있는 것을 알 수 있다(ctype data가 저장) 따라서 buff의 시작 주소를 알면, 인덱스를 통해서 빠르게 접근할 수 있으며, cache hit rate도 높을 것 같다.
numpy array가 python list 보다 빠를까?
위에 두 자료구조를 비교했을 때, numpy array가 단일 포인터로 접근이 가능하며 메모리 상의 연속적으로 존재하여 cache hit rate가 더 높아 더 빠르다고 생각한다. 또한 메모리에 연속적으로 존재하면 SIMD가 가능해진다(SIMD는 데이터가 정렬된 상태에서 가능하다
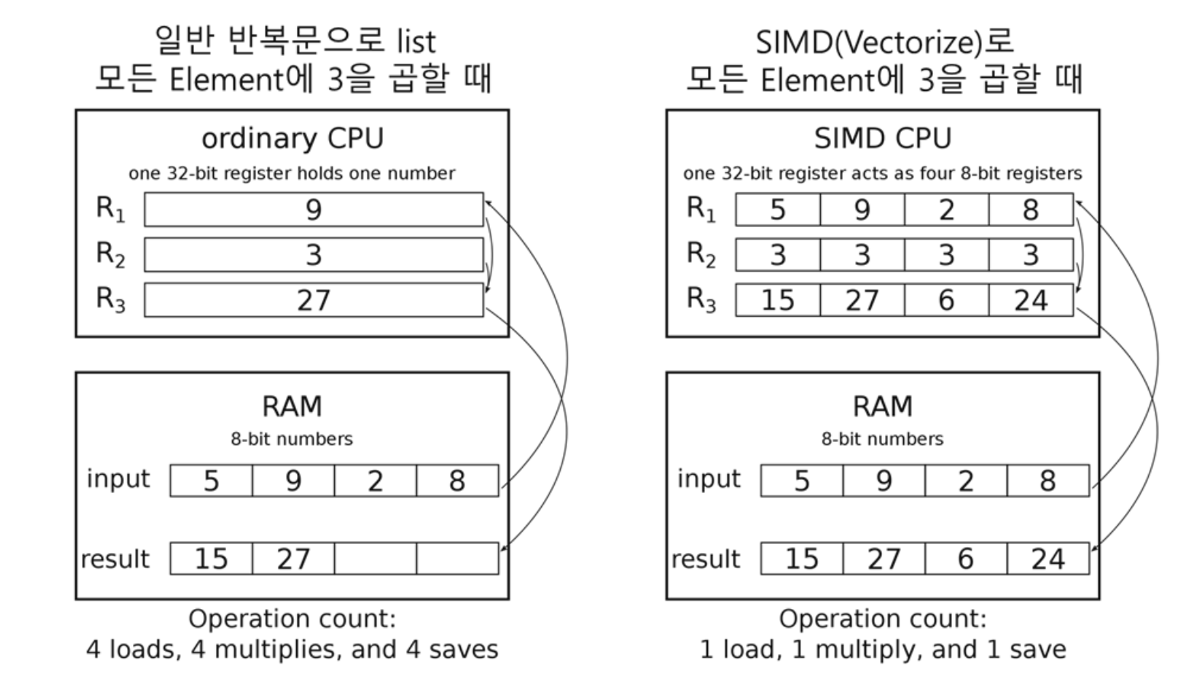
numpy arrary의 vectorize 연산이 이 SIMD를 통해서 이뤄진다.
결과적으로 numpy array가 같은 타입의 데이터로 이뤄져 있기 때문에 메모리에 연속적으로 저장이 되어 접근이 빠르고, cache hit rate가 높으며 결과적으로 SIMD가 가능한다.
그렇다면 다양한 데이터 타입으로 구성되어있는 데이터는 numpy array로 다룰 수 없을까? (다음 포스팅에서..)
