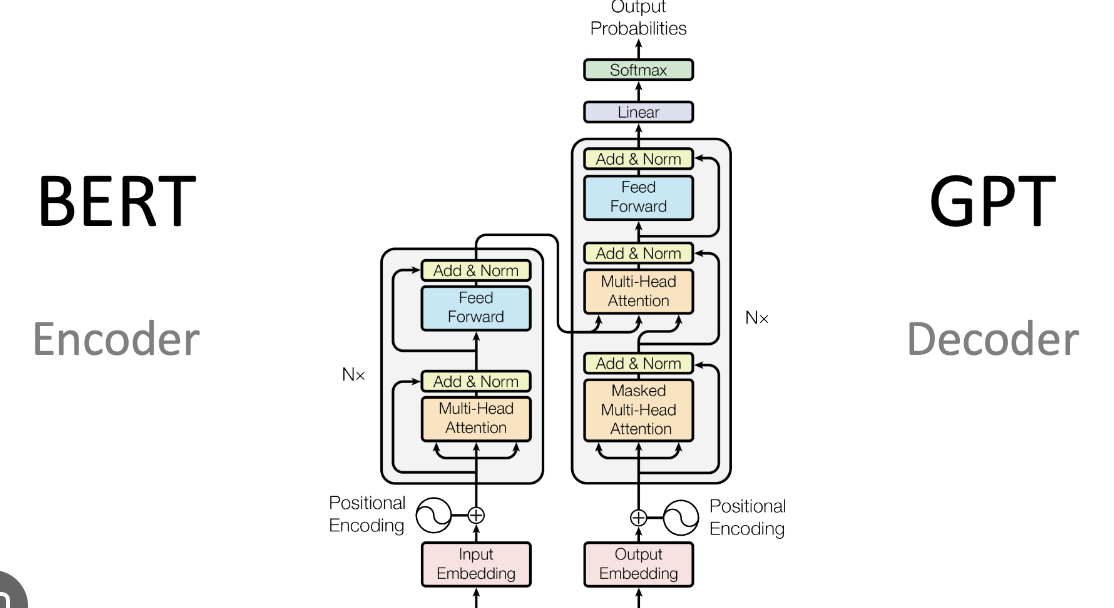
Attention Is All you Need (Transformer)
- 2018, Google Researcher
소개
- 입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력
- seq2seq[https://arxiv.org/pdf/1409.3215.pdf], 2014
→ attention[https://arxiv.org/abs/1409.0473], 2014
→ transformer
→ BERT나 GPT 모두 트랜스포머를 기반으로 한 분류/생성 모델
seq2seq?
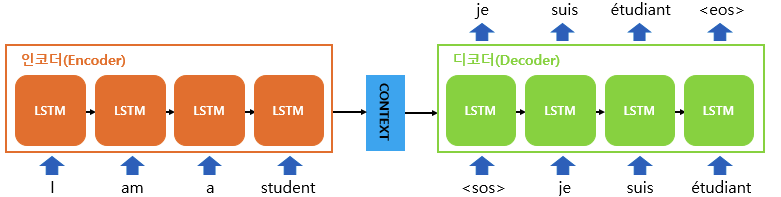
- context vector = RNN 셀의 마지막 시점의 은닉 상태
- 문제점
- 입력 시퀀스의 내용을 하나의 벡터에 모두 담으려다 보니 정보 손실이 발생한다 (long-term dependencies problem)
- RNN의 고질적인 그레디언트 소실 이슈
attention?
- 입력 시퀀스가 길어지면 출력 시퀀스의 정확도가 떨어지는 것을 보정하기 위해 등장
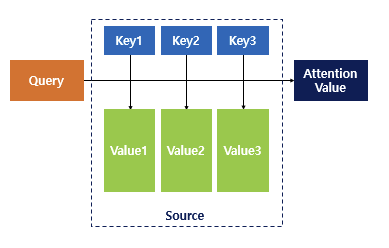
- Query에 대해서 모든 Key와의 유사도를 구하고, 이를 키에 맵핑되어있는 Value에 반영하고 이를 모두 더하여 Attention Value를 구함
- Dot Product Attention
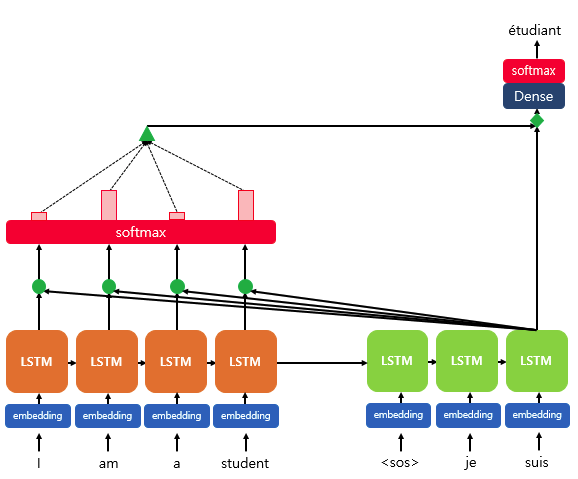
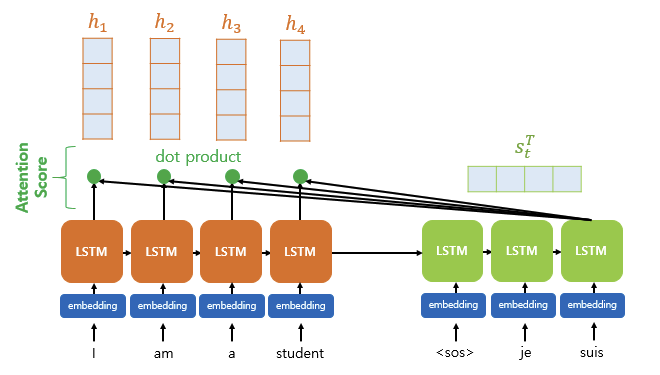
- Q = Query : t 시점의 디코더 셀에서의 은닉 상태
K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
V = Values : 모든 시점의 인코더 셀의 은닉 상태들
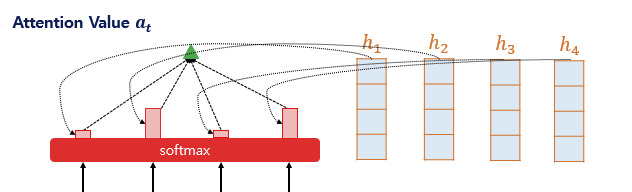
- Q*K 을 softmax에 통과시켜 모든 값을 합하면 1이 되는 확률 분포를 얻음 - 어텐션 분포
- decoder t시점의 출력에 얼만큼 영향을 미칠지
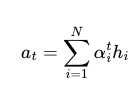
- 해당 값들을 각 시점의 인코더 은닉상태에 곱하여 합하면 attention value
- 예측하고자 하는 시점에 은닉 상태를 이용해 입력 시퀀스에 어떤 단어와 연관이 가장 높은지
- 여전히 RNN을 사용해서 문제가 완전히 해결된 것은 아님
- 병렬 처리 제약 → 하드웨어 리소스를 효과적으로 사용하지 못함
0. Abstarct
- 주류인 시퀀스 모델들은 RNN, CNN으로 구성되어있고 우수한 모델들은 encoder와 decoder를 attention mechanism을 통해 연결
- RNN, CNN을 완전히 제거하고 Attention만을 이용하여 새롭고 간단한 아키텍처인 Transformer를 제안
- 실험결과 더 우수한 성능을 보이면서 병렬화가 가능하고 학습에 더 적은 시간이 소요
1. Introduction
- RNN은 LSTM과 GRNN을 포함하여 고도화되고, 이 후 인코더와 디코더 아키텍처의 한계를 넓히기 위해 노력
- 하지만 RNN은 그 이전 상태(ht-1)과 t 시점의 입력을 통해 t시점의 은닉상태(ht)를 생성하기 때문에 병렬처리가 불가
- 최근 연구를 통해 긴 시퀀스 길이에서 발생하는 문제는 해결했지만 순차적인 계산 문제를 해결하지 못함
- Attention을 통해 입력 또는 출력의 길이 문제는 해결했지만, 여전히 병렬처리는 불가(RNN사용)
- 본 논문에서는 RNN을 배제하고 입력과 출력 간의 dependency를 어텐션만을 사용, 병렬화를 가능하게 함
2. Background
- sequential computation을 줄이는 것은 CNN을 이용한 Extended Neural GPU, ByteNet, ConvS2S에서도 다뤄졌으나, 이 모델들에서는 입력과 출력을 연과시키는데 필요한 연산 수가 많다
- Transformer에서는 Multi-Head Attention를 이용하여 연산을 줄였다
- Self-attention은 시퀀스의 서로 다른 위치를 관련시켜 시퀀스의 표현을 계산하기 위한 메커니즘
- Transformer는 RNN이나 convolution을 사용하지 않고 온전히 self-attention에 의존한 최초의 변역 모델
3. Model Architecture
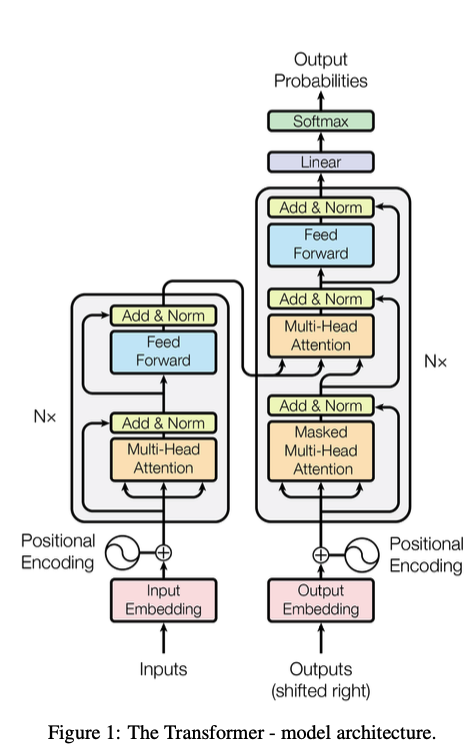
- 주류인 시퀀스 변환 모델들은 대부분 인코더 - 디코더 구조를 따르고, Transformer도 이를 따른다
- Transformer는 self-attenstion과 fully connected layer를 이용하여 인코더와 디코더를 구성한다
3-1. Encoder and Decoder Stacks
- encoder
- 논문에서는 Encoder는 6개 층으로 stack
- 각 layer는 두 개의 sub-layer가 있음
- 첫 번째 sub-layer는 multi-head self-attention mechanism
- 두 번째 sub-layer는 간단한 position-wise fully connected feed-forward network
- two sub-layers 마다 residual connectio 후에 layer normalization 적용
- 즉 각 sub-layer의 결과는 LayerNorm(x+Sublayer(x)) 임
- 잔차연결(residual connection)을 구현하기 위해, embedding layer를 포함한 모든 sub-layer들의 output은 512 차원
- decoder
- 논문에서는 Decoder 또한 6개 층으로 stack
- 인코더와 다르게, 인코더 각 stack의 출력에 대해 multi head attention을 수행하는 층이 추가
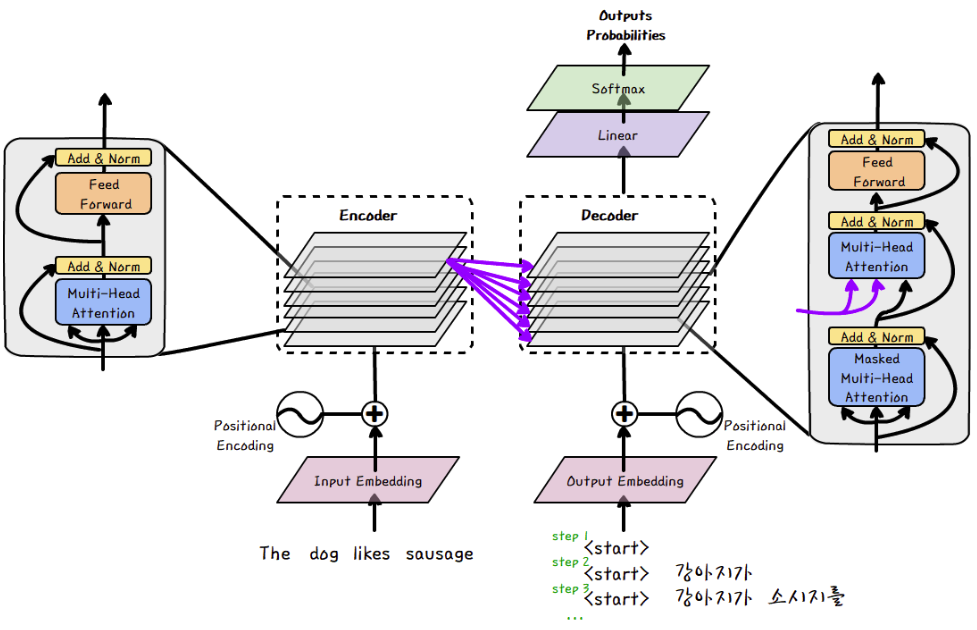
- 인코더와 마찬가지로 sub-layer에 잔차연결(residual connection)과 정규화 연산
- 마스킹을 이용하여 i위치의 예측은 i보다 이전 위치 출력만 사용
3-2. Attention
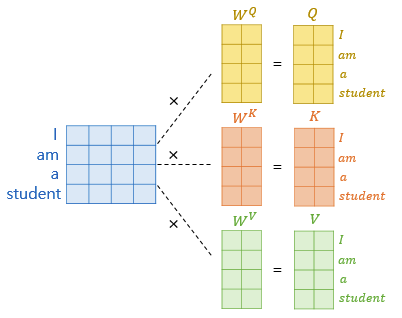
- query(Q), key(K), value(V) 쌍을 입력으로 받아 출력을 생성하는 함수
3-2-1. Scaled Dot-Product Attention
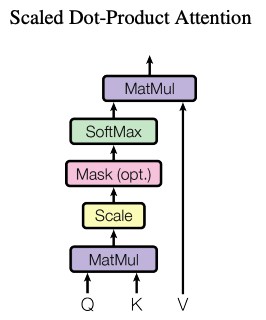
- 모든 쿼리와 key에 대해 dot product를 계산하고, √dk 로 나눠주고, weight을 적용하기 위해 value에softmax함수를 적용
- 내적 어텐션(Dot-Product)의 속도가 훨씬 빠르고 메모리 공간을 효율적으로 사용할 수 있다
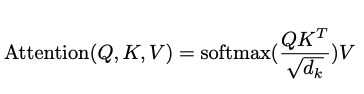
-
SoftMax 함수에서 기울기가 극히 작아질 수 있기 때문에 스케일링을 진행한다
-
1개의 입력 벡터에 대해서 대략 다음과 같은 행렬 연산이 일어나고,
Q벡터가 나오면, 이를 모든 K벡터와 내적한 값을 정규화하여 softmax를 통과시킨다
그 뒤에 V벡터에 곱하여 모두 합하여 Attention Value를 계산하다
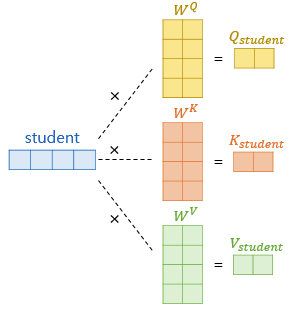
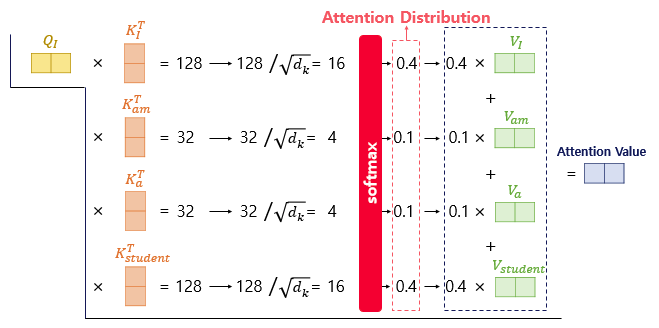
- 위 과정 중 Q,K,V 벡터의 계산을 한 번에 병렬처리하면 대략 다음 이미지와 같다
3-2-2. Multi-Head Attention
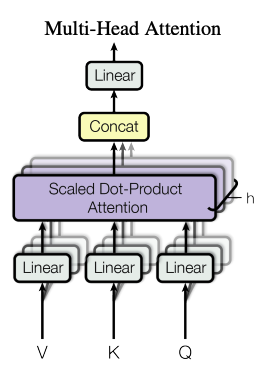
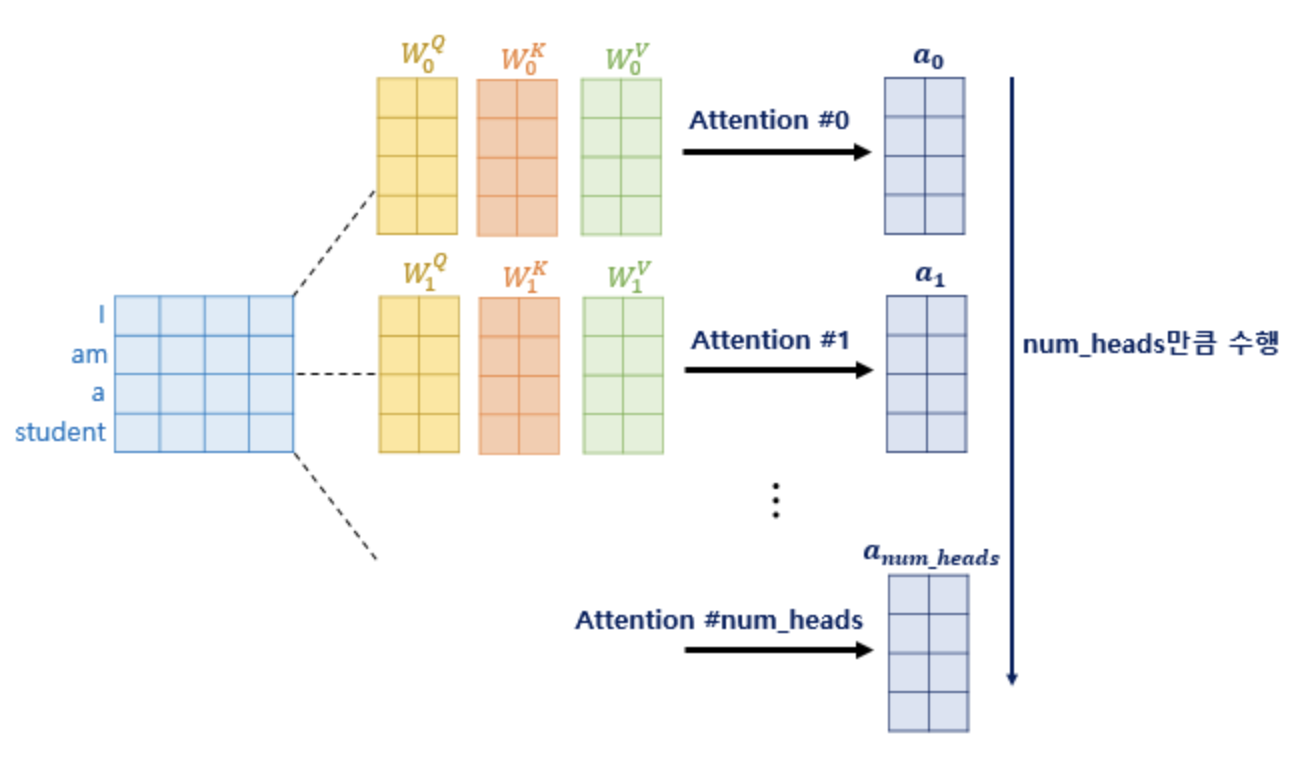
- 한 번의 어텐션보다 여러 번의 어텐션을 병렬적으로 하는 것이 더 효과적
- 논문에서는 8개로 병렬처리
- 논문에서는 dmodel 차원이 512 이고 num head = 8이므로 W 벡터는 (512, 64)
- 64 = 512 / 8
- 나중에 병렬처리한 attention벡터들을 concatenate했을 때 dmodel과 차원이 같음
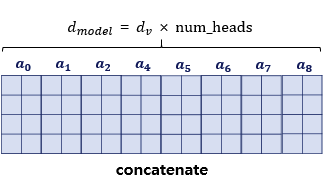
- 입력 차원과 동일하게 맞추는 이유는 인코더/디코더가 여러 층으로 stack되기 때문에 다음 입력으로 넘겨주기 위해서 결과적으로 출력도 입력과 동일한 차원
3-2-3. Applications of Attention in our Model
- self-attention in encoder : 해당 position과 모든 position간의 correlation information
- self-attention in decoder : masking vector를 사용하여 해당 position 이전의 벡터들만을 참조
- encoder-decoder attention: decoder의 sequence vector들이 encoder의 sequence vector들과 어떠한 correlation
3-3. Position-wise Feed-Forward Networks
- fully connected feed-forward network
- ReLu를 포함하여 총 2개의 선형 변함이 포함
- 마찬가지로 출력은 512차원이며, layer마다 서로 다른 매개변수를 사용한다
3-4. Embeddings and Softmax
- 다른 sequence transduction models 처럼, 학습된 임베딩을 사용함
- decoder output을 예측된 다음 토큰의 확률로 변환하기 위해 선형 변환과 softmax를 사용함
3-5. Positional Encoding
- 어떤 recurrene, convolution도 사용하지 않기 때문에, sequence의 순서를 사용하기 위해 sequence의 상대적 또는 절대적인 position에 대한 정보필요
- • 다양한 positional encoding 방법 중 sine, cosine function을 사용하여 위치 정보를 생성
4. Why Self-Attention

- layer당 시간 복잡도
- n : sequence length, d : representation dimensionality
- d: 대부분의 경우 기계 번역에서 사용되는 문장 표현 방식인 단어 조각
- sequence의 길이가 전체 단어의 수보다 긴 경우가 드물다 ( n < d 가 대부분)
- n : sequence length, d : representation dimensionality
- Sequential Operation
- self-attention layer는 input의 모든 position 값들을 연결하여 한번에 처리
- 반면 RNN의 경우 t시점에 대해서 알기위해서는 t-1까지 계산을 차례로 거처야함
- self-attention layer는 input의 모든 position 값들을 연결하여 한번에 처리
- Maximum Path Length
- length of paths란 forward와 backward signals간의 길이
- self-attention은 각 token들을 모든 token들과 참조하여 그 correlation information을 구해서 더해주기 때문에(심지어 encoder-decoder끼리도), maximum path length를 O(1)
6. Results
- 기계 번역 (Machine Translation)
- Transformer 모델은 WMT 2014 영어-독일어 및 영어-프랑스어 번역 작업에서 기존의 모델들을 능가하는 우수한 성능, 더 작은 모델 크기로도 경쟁 모델보다 우수한 번역 결과를 달성
- 언어 모델링 (Language Modeling): 데이터셋의 크기와 모델의 크기에 관계없이 일관된 성능 향상
- Transformer 모델은 번역 작업 외에도 음성 인식과 어순 변환 작업에서도 강력한 성능
- 긴 문장 처리에 대한 실험에서도 LSTM 기반 모델보다 더 효과적인 결과
참고
https://www.youtube.com/watch?v=AA621UofTUA
https://wikidocs.net/31379

데이터와 파이썬을 좋아합니다 :) contact : chal405@naver.com