
YOLO(You Only Look Once)
- Unified, Real-Time Object Detection
- Unified: 통합
1. Abstart
- 기존 object dection의 방식이 아닌 regressions 문제로 접근한다
- 이미지 전체에 대해 하나의 신경망이 한 번의 계산으로 bounding box와 class probability를 예측한다
- 전체 detection pipeline이 단일 네크워크인 end-to-end 방식이다
- 매우 빠르다
- 초당 45 frame의 실시간 이미지를 처리할 수 있다 (45FPS)
- fast YOLO의 경우 다른 real time detector들보다 2배의 mPA 성능을 보인다
- )
- FPS (Frame Per Second) : 1초당 몇 이미지 Frame이 보여지는지
- 인간은 보통 25 FPS를 보면 영상이 끊기지 않는다고 판단(실시간성이 있다고 판단한다
- mPA (mean Average Precision) :
- 정확도
2. Introduction
- 현재(논문시점) object detection은 분류기(classifier)를 목적에 맞게 바꾸며 detection을 수행한다
- 객체를 감지하기 위해 분류기(classifier)를 사용하는데 분류를 진행한 후 객체를 탐지하는 복잡한 파이프라인을 거치기 때문에 속도가 느리고 최적화에 어려움이 있다
- DPM , R-CNN
- YOLO는 Object detection을 하나의 regression문제로 정의한다
- single Conv net이 여러 bounding box와 클래스 확률을 동시에 계산한다
- YOLO의 장점
- 빠르다
- 회귀 문제로 정의하면서 pipeline이 간단해졌다
- 25 milliseconds 미만의 지연 시간으로 실시간 스트리밍 비디오를 처리할 수 있다
- 이미지 전체를 사용한다
- YOLO는 전체 이미지를 보기 때문에 클래스에 대한 문맥적 정보와 외형을 인코딩할 수 있다
- background가 object라고 판단하는 background error를 줄일 수 있다
- 일반적인 부분을 학습한다
- 자연 이미지로 학습하고 art work(예술 작품)을 테스트할 때 월등히 뛰어났다
- 빠르다
- YOLO의 단점
- 최신 SOTA 객체 검출 모델에 비해 정확도가 약간 떨어진다
- 빠르게 객체를 식별할 수는 있지만, 작은 객체의 정확한 위치를 추론하는데는 어려움을 겪는다
- 최신 SOTA 객체 검출 모델에 비해 정확도가 약간 떨어진다
2-1. Unified Detection
-
YOLO는 객체 검출의 개별 요소를 단일 신경망(single neural network)로 통합한 모델이다
-
입력 이미지를 S x S grid로 나눈다
-
만약 어떤 객체의 중심이 특정 grid cell 안에 위치한다면 해당 grid cell이 객체를 검출해야한다
-
각 grid cell은 B개의 bounding box와 그에 대한 confidence score를 예측한다
-
confidence score : 객체를 포함하고 있다고 확신하는 정도와
예측한 bounding box가 얼마나 정확한지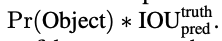
-
IOU
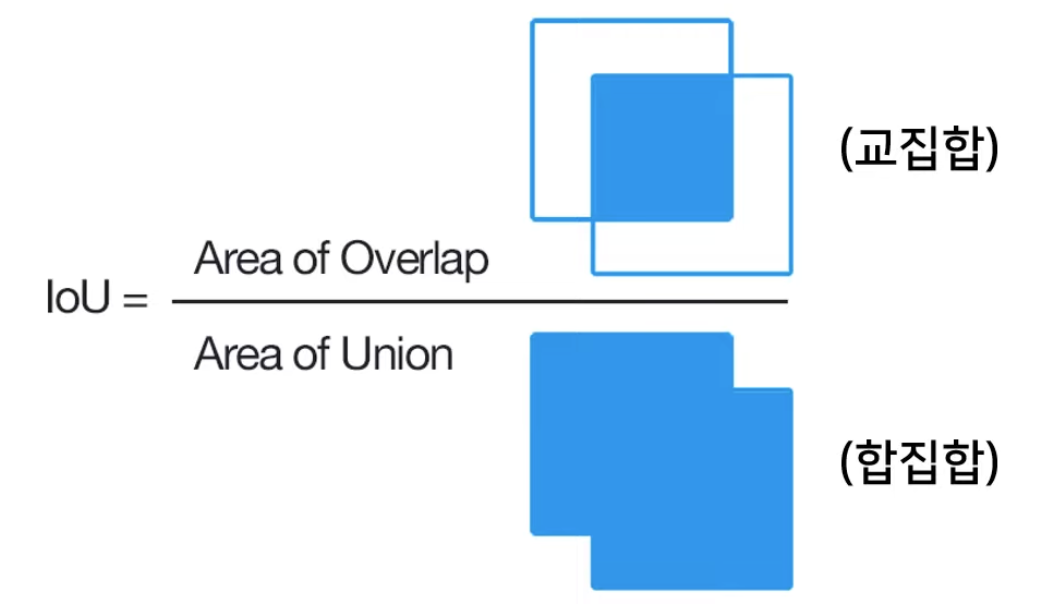
-
mAP@0.5 = 정답과 예측의 IOU가 50%이상일 때 정답으로 판정하겠다는 의미
-
Pr(object) = 0 : grid cell에 아무 객체가 없다, 어떤 객체가 확실히 있다고 예측했을 때 = 1
-
각각의 bounding box는 5개의 예측치로 구성된다
- x,y : bounding box 중심의 gird cell 내 상대위치 (0 ~ 1 사이 값)

- w, h : bounding box의 상대 너비와 상대 높이 ⇒ 전체 이미지 대비 w, h (0~1 사이 값)
- Q) 왜 상대적인 값을 사용했을까?
- confidence score
- x,y : bounding box 중심의 gird cell 내 상대위치 (0 ~ 1 사이 값)
-
각각의 grid cell은 conditional class probabilities(C) 를 예측한다
- cell안에 객체가 있다는 조건 하에 어떤 class 인지를 나타내는 조건부 확률
- Q) 애초에 아무것도 없음이라는 class가 없고, 하나의 class를 무조건 예측하도록 만들었을까?
- cell 에 몇개의 bounding box가 있는지와 무관하게 하나의 cell은 하나의 class에 대한 확률만 갖는다
- cell안에 객체가 있다는 조건 하에 어떤 class 인지를 나타내는 조건부 확률
-
테스트 단계에서는 grid cell의 C와 개별 bounding box에 confidence값을 곱한 class-specific confidence socre를 사용한다
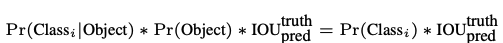
- bounding box에 특정 클래스 객체가 나타날 확률과 예측된 bounding box가 그 class 객체에얼마나 fit하게 맞았는지
-
논문에서 최종 예측 텐서의 차원은 (S x S x (B5 + C)) = 7 7 * 20
-
2-2. Network Design
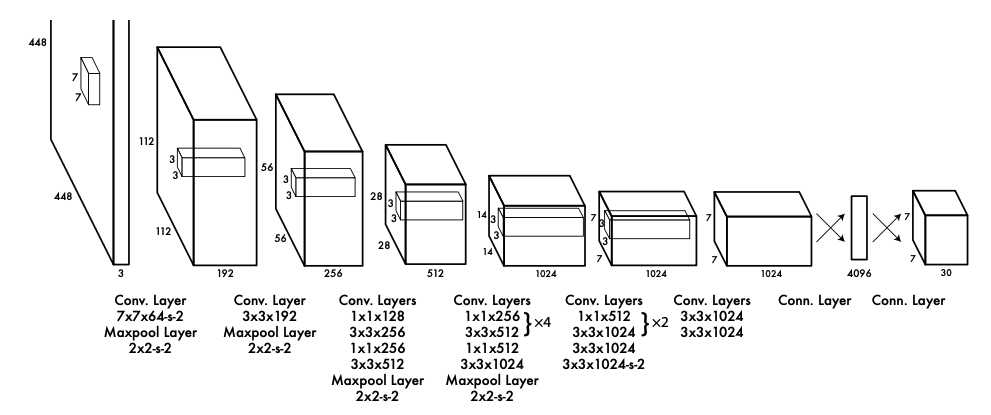
- 전체 구조는 24개의 Conv계층과 2개의 FC 계층으로 구성된다, 1*1 layer는 이전 feature space를 줄여준다
- Conv 계층은 이미지로부터 특징을 추출
- FC 계층은 클래스 확률과 bounding box의 좌표를 예측
- 신경망의 구조는 GoogLeNet 구조에 영감을 받아 설계
- GoogLeNet의 inception 구조대신 11 축소 계측과 33 컨볼루션 계층을 결합하여 사용
2-3. Training
-
ImageNet dataset으로 앞 단의 20개의 Conv계층을 사전 훈련시킨다
-
사전 훈련된 20개의 Conv계층 뒤에 4개의 Conv계층과 2개의 전결합 계층을 추가한다
-
마지막 계층에는 Linear activation funtion을 적용하고, 나머지 모든 계층에는 leaky ReLu를 적용
- leaky ReLu
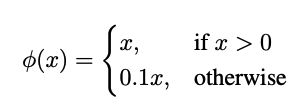
- leaky ReLu
-
YOLO의 loss는 SSE(sum-squared error)를 기반으로 한다
-
SSE를 최적화하는 것이 YOLO의 최종 목적인 mPA를 높히는 것과 완전히 일치하지는 않는다
- YOLO의 loss는 localization lossd(bounding box위치 예측 정도)와 classification loss
- 가중치를 동일하게 두고 학습하는 것은 좋은 방법이 아니지만 SSE를 최적화하는 방식은 두 loss의 가중치를 동일하게 취급
-
배경 영역이 더 크기 때문에 대부분의 grid cell에 confidence score=0이 되어 모델의 불균형이 생긴다
- 이는 YOLO가 모든 cell에 대해서 confidence=0으로 예측하도록 학습되게 할 수 있다
-
이를 개선하기 위해 객체가 존재하는 bounding box 좌표에 대한 loss의 가중치를 증가 시키고, 객체가 존재하지 않는 box에 대해서는 감소시킨다
- 이는 localization loss의 가중치를 증가시키고, 객체가 존재하는 cell의 confidence loss의 가중치를 증가시킨다
- λ_coord=5, λ_noobj=0.5로 가중치를 부여
- λ_coord : 객체를 포함하는 grid cell에 곱해주는 가중치
- λ_noobj : 객체를 포함하지 않는 grid cell에 곱해주는 가중치
-
SSE는 큰 bounding box와 작은 bounding box를 모두 동일한 가중치로 loss를 계산한다
- 작은 bounding box는 작은 위치 변화에도 객체를 벗어날 수 있다
- 너비와 높이에 square root를 취해 높이와 너비가 큰 값에 대해서 가중치를 감소시킨다
-
YOLO는 하나의 grid cell이 여러 개의 bounding box를 예측하는데, 결국엔 객체 하나당 하나의 bounding box가 선택되어야 한다
- 이를 위해 여러 bounding box중에서 실제 객체를 감싸는 box(ground-truth boudning box)와 IOU가 가장 큰 것을 선택한다
-
훈련 단계에서 사용하는 loss function

- S^2 = 모든 cell의 수, B = cell당 bounding box의 수
- 1_i^obj : cell 안에 객체가 존재하는지 여부
- 1_ij^obj : cell 의 i의 j번째 bounding box 가 사용되는지 여부
- 1 ) Object가 존재하는 i번 째 cell에 대해 사용하는 j번 째 box에 대해 x ,y loss
- 2) Object가 존재하는 i번 째 cell에 대해 사용하는 j번 째 box에 대해 w, h loss (큰 박스에 대해 작은 가중치를 주기 위해서 square root)
- 3) Object가 존재하는 i번 째 cell의 j번 째 box에 대해서 confidence loss (Ci =1 )
- 4) Object가 존재하지 않는 i번 째 cell의 j번째 box에 대해서 confidence loss (Ci = 0)
- 5) Object가 존재하는 i번 째 cell에 대해 conditional class probability
-
overfitting을 막기 위해 dropout과 dat augmentation(random scaling, random translation)을 적용
2-3. Inference
- 하나의 신경망만 계산하면 되기 때문에 굉장히 빠르다
- 객체의 크기가 크거나, 객체가 cell의 경계에 인접해 있는 경우 객체에 대한 bounding box가 여래 개 생길 수 있다 (multiple detections)
- NMS(non-maximal suppression)를 통해 mPA 2~3% 올릴 수 있었다

2-4. Limitations of YOLO
- 하나의 cell에 하나의 객체만을 검출해야하므로 cell에 두개 이상의 객체가 붙어있다면 잘 검출하지 못함
- 훈련 단계에서 학습하지 못한 종횡비(aspect ration)를 테스트 단계에서 만났을 때 고전한다
- 큰 bounding box와 작은 bounding box에 대해서 동일한 가중치를 준다
3. Comparison to Other Detection Systems
-
DPM (Deformable Parts Models)
- sliding window를 사용

- 특징 추출, 위치 파악, bounding box예측 등을 서로 분리된 파이프 라인으로 구성한다
- 하지만 YOLO는 하나의 파이프라인으로 구성되어있어 DPM보다 빠르다
- sliding window를 사용
-
R-CNN
- sliding window 대신 selective search 방식을 사용
- 여러 bounding box를 생성하고, 컨볼루션 신경망으로 feature를 추출하고, SVM으로 bounding box에 대한 점수를 측정
- linear 모델로 bounding box를 조정하고, NMS로 중복 검출 제거
- 복잡한 파이프라인을 단계별로 독립적으로 튜닝해야하기 때문에 굉장히 느리다
- 정확성은 높지만 속도가 느려서 실시간 객체 검출로 사용하기엔 한계가 있다
- grid cell이 여러 개의 bounding box를 생성하고, 이에 점수를 계산하는 것이 YOLO와 비슷하다
- 하지만 YOLO는 98개 R-CNN은 2000개로 YOLO가 훨신 적은 bounding box로 진행 가능
- YOLO는 모든 과정이 하나의 파이프라인
- sliding window 대신 selective search 방식을 사용
-
Other Fast Detectors
- Fast R-CNN과 Faster R-CNN은 R-CNN 프레임워크를 개선하지만 실시간 속도에는 아직 부족
- DPM 파이프라인의 속도를 높이는 노력이 있었지만, 실시간으로 동작하는 DPM은 30Hz DPM 뿐이다
- 하나의 파이프라인으로 구성된 YOLO가 더 빠르다
-
그 외 Deep MultiBox, OverFeat, MultiGrasp 와의 비교
4. Experiments
- YOLO를 다른 실시간 객체 검출 모델과 비교
- 파스칼 VOC 2007 dataset 사용
4-1. Comparison to Other Real-Time Systems
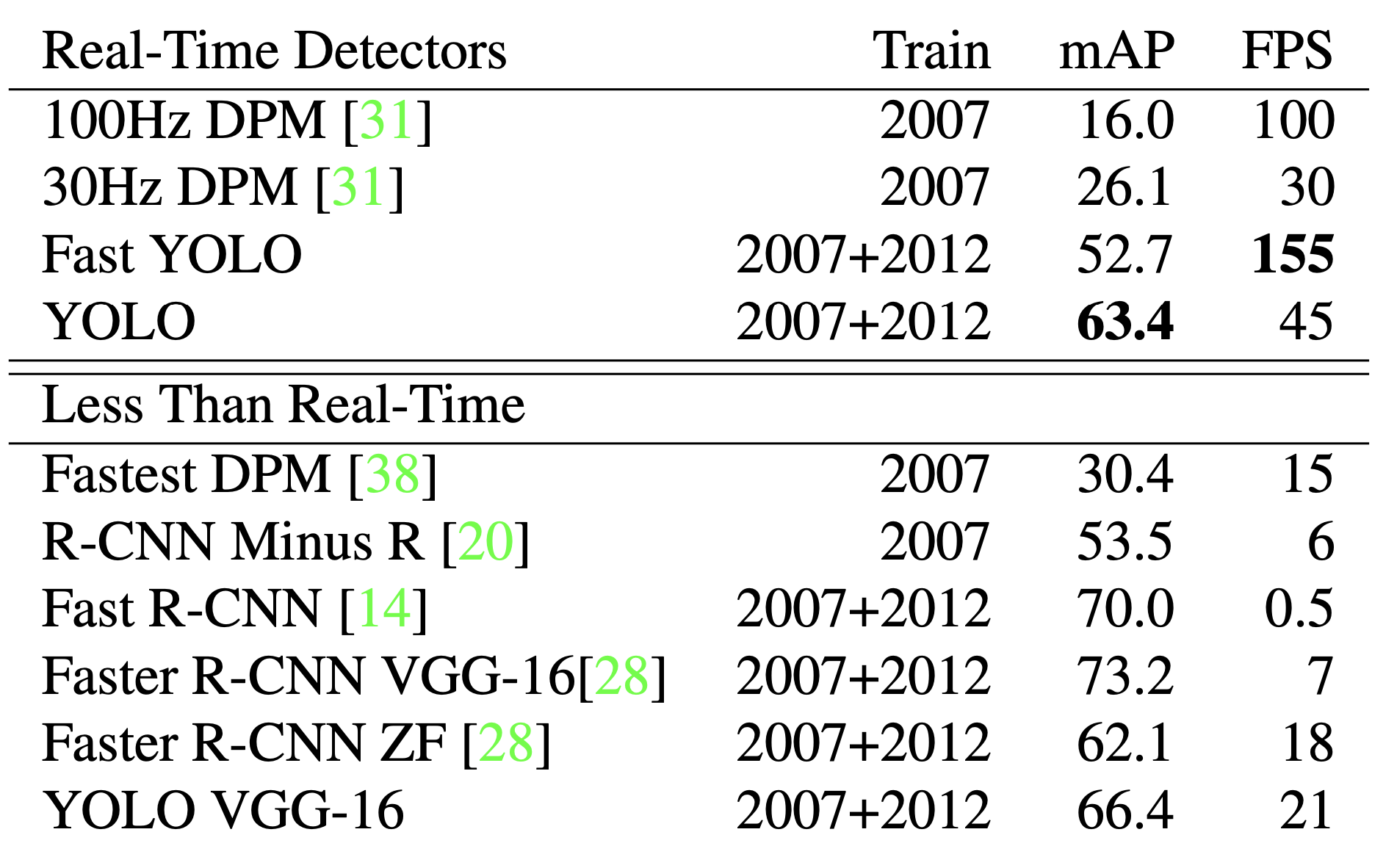
- 객체 검출의 많은 연구들이 표준화된 객체 검출을 빠르게 만드는데 초점을 두고있다
- Real-Time Detectors(FPS 30이상) 중에서 YOLO가 가장 mAP가 높다
- Fast YOLO는 YOLO에 비해 mAP는 조금 떨어지지만(그래도 52.7로 30Hz DPM의 2배 가량의 성능)
VOC dataset에 대해서 가장 빠른 모델이다
- Fast YOLO는 YOLO에 비해 mAP는 조금 떨어지지만(그래도 52.7로 30Hz DPM의 2배 가량의 성능)
- YOLO VGG-16은 mAP는 높아졌지만 FPS가 낮아, 실시간 객체 검출 모델로 사용하기에 느리다
- Fastest DPM은 mAP를 약간 하락시키며 FPS를 높였지만 여전히 실시간 객체 검출 모델로 사용하기에 느리다
- 정확도도 높고 실시간 처리가 가능한 빠른 모델은 YOLO
4-2. VOC 2007 Error Analysis
- 객체 검출이 정확한지, 틀렸다면 어떤 error인지
- YOLO와 Fast R-CNN 을 비교


- Correct : class가 정확하며 IOU > 0.5 인 경우
- Localization : class가 정확하고, 0.1 < IOU < 0.5 인 경우
- Similar : class가 유사하고 IOU > 0.1 인 경우
- Other : class는 틀렸으나, IOU > 0.1 인 경우
- Background : 어떤 Object라도 IOU < 0.1 인 경우
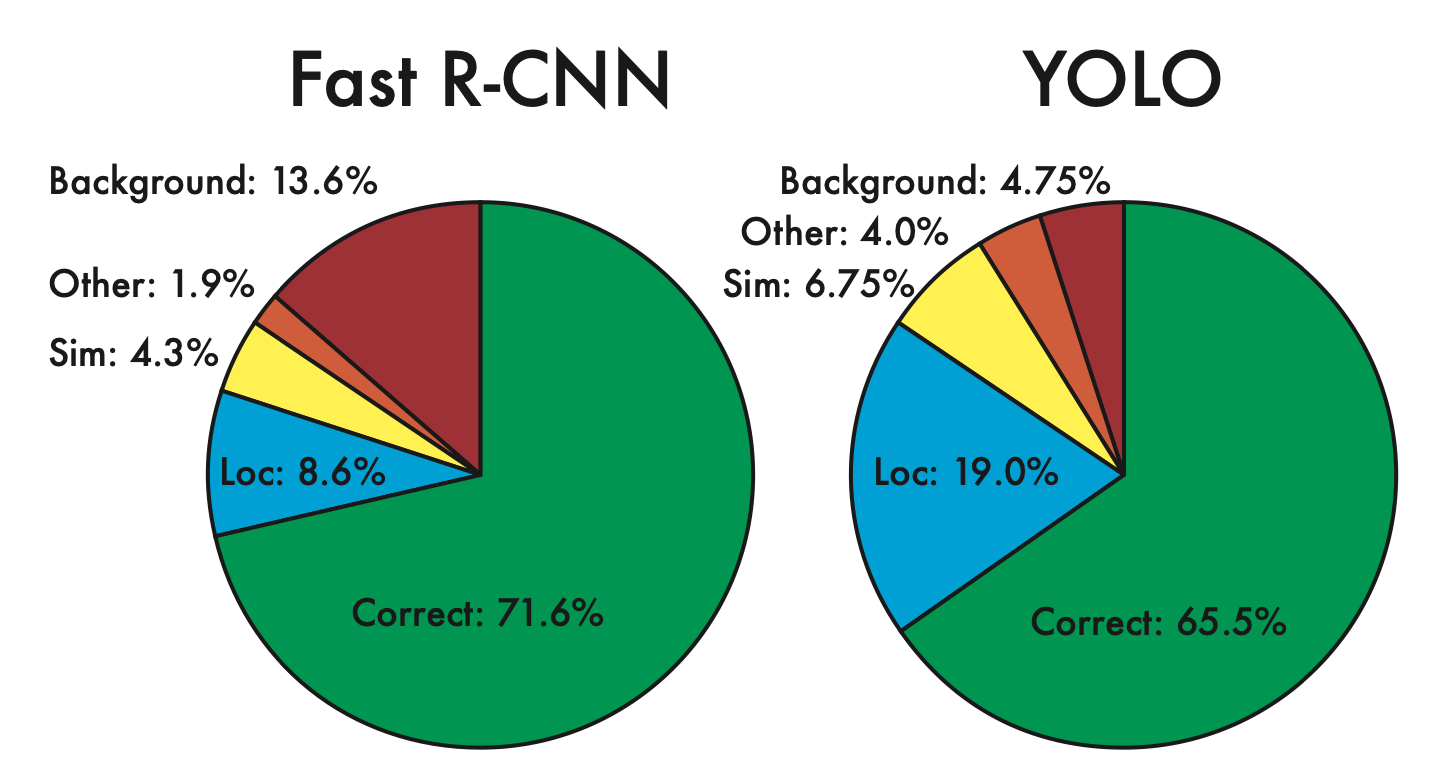
- YOLO는 localization error가 가장 높고, Fast R-CNN에 비해서도 localization error가 높다
- 반면에 R-CNN은 background error가 가장 높고, YOLO에 비해서도 background error가 높다
4-3. Combining Fast R-CNN and YOLO
- 서로의 약점을 보완하는 방식으로 둘 모델을 결합한다면 높은 성능을 낼 수 있을 것
- Fast R-CNN 은 파스칼 VOC 2007 dataset에 대해서 mAP가 가장 높은 71.8 mAP를 기록하였다
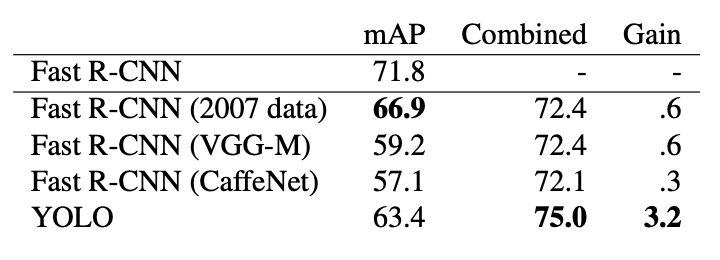
- 다른 모델과의 앙상블보다 YOLO와 앙상블 했을 때 증가율이 3.2로 가장 높았다
- Fast R-CNN 과 YOLO를 독립적으로 실행하여 앙상블하는 방식이기 때문에 YOLO에 비해느리지만,
YOLO가 워낙 빨라 Fast R-CNN을 단독으로 돌리는 것과 거의 비슷한 속도를 낸다
4-4. VOC 2012 Results
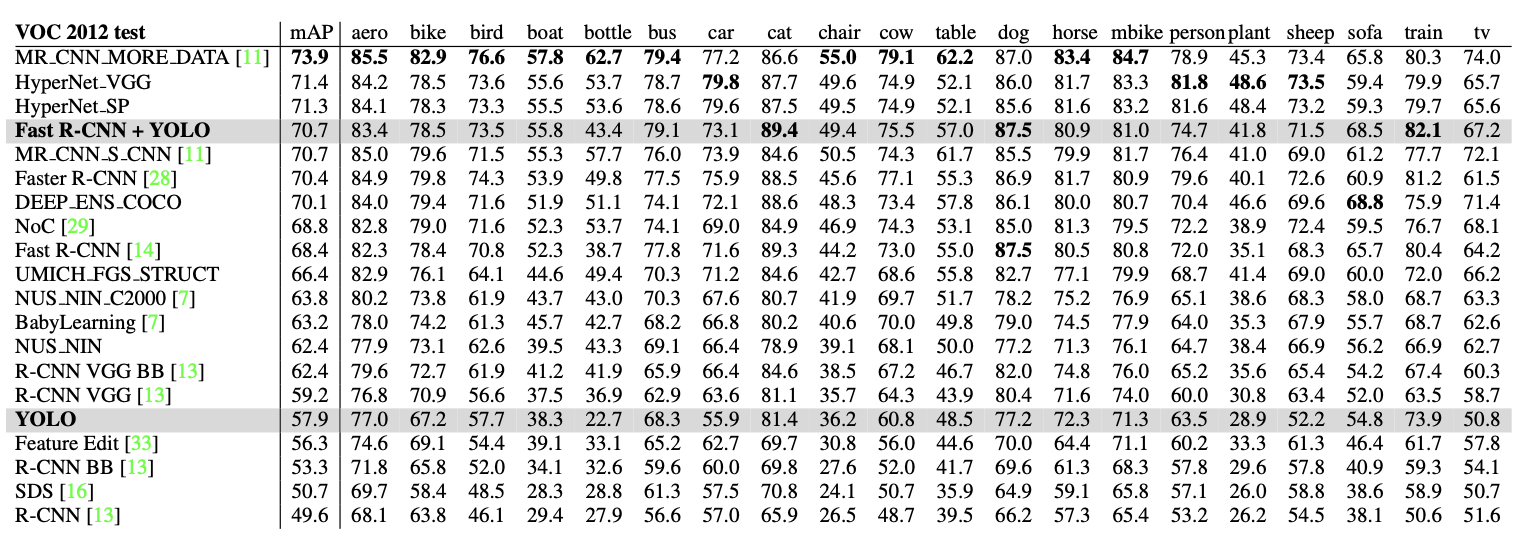
- YOLO 다른 모델보다 작은 객체에 어려움을 겪는다
- 병, 양, TV/모니터와 같은 카테고리에서 YOLO의 점수는 R-CNN이나 Feature Edit보다 8-10% 낮다.
- 고양이와 기차와 같은 다른 카테고리에서는 YOLO가 더 높은 성능을 달성
- Fast R-CNN + YOLO가 높은 순위권에 위치
4-5. Generalizability: Person Detection in Artwork
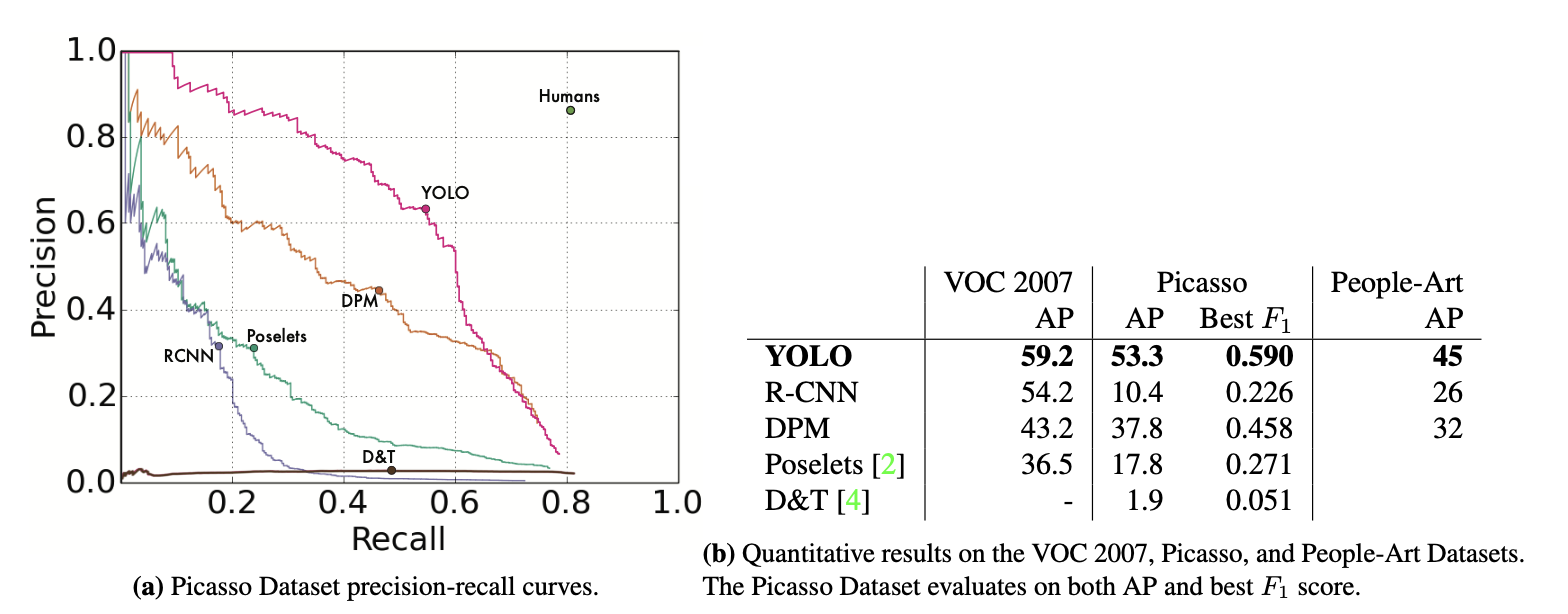
- 훈련 단계(실제 이미지)에서 보지 못했던 피카소 데이터 셋과 일반 예술 작품 데이터 셋을 이용하여 테스트
- R-CNN은 VOC 2007에서는 높은 정확도를 보이지만 예술작품에 대해서는 굉장히 낮은 정확도
- DPM은 예술 작품에 대해서도 정확도가 크게 떨어지지는 않지마 VOC 2007에서의 정확도도 높은 편은 아님
- YOLO는 3개 영역에서 높은 성능을 보임
5. Real-Time Detection In The Wild

6. Conclusion
- YOLO는 단순하면서도 빠르다
- YOLO는 훈련 단계에서 보지 못한 새로운 이미지에 대해서도 객체를 잘 검출한다
- 애플리케이션에서도 충분히 활용할만한 가치가 있다
