Wide & Deep Learning for Recommender System
0. Abstract
- Wide : Memorization
- cross-product feature transformations 을 통해 feature간 interaction을 고려할 수 있다
- more feature engineering effort
- Deep : Generalization
- generalize better to unseen feature combinations
- less feature engineering
- user-item inter- actions are sparse할 때, over-generalize and recommend less relevant items
- Wide & Deep
- wide linear models 과 deep neural networks을 모두 사용하여 각각의 장점을 가져간다
1. Introduction.
-
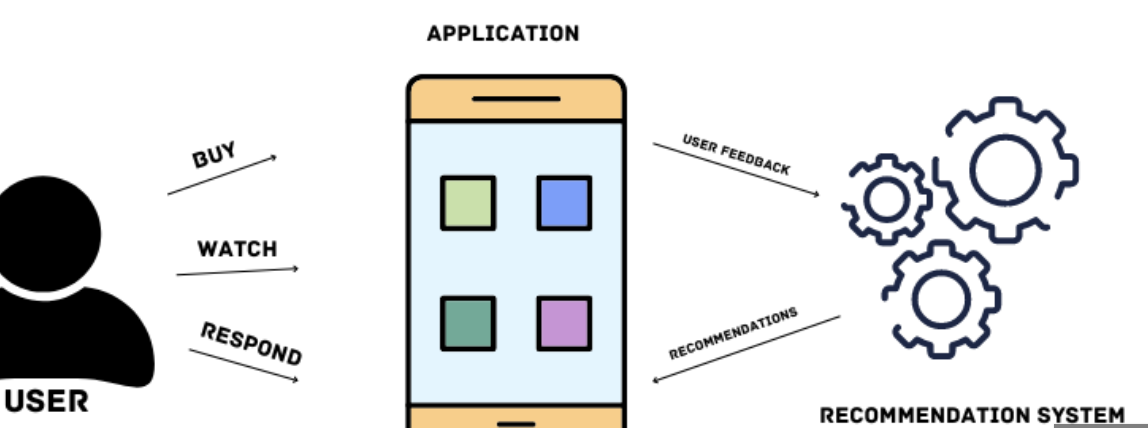
추천 시스템은 유저 정보와 문맥 정보(contextual information)이 주워졌을 때 database에서 관련있는 item들을 찾고, 클릭이나 구매와 같은 특정 목표에 따라 순위를 매기는 search ranking system으로 간주될 수 있다
-
search ranking system에서는 Memorization과 Generalization을 모두 달성하는 것이 Challenge이다
-
Memorization
- item또는 feature들의 빈번한 동시발생(frequent co-occurrence)을 학습
- 과거 데이터에서 item또는 feature 사이의 상관관계를 활용
- 일반적으로 사용자가 이미 user가 특정 행동을 수행한 item과 직접적으로 관련이 있는 주제에 더 많은 추천을 제공
-
Generalization
- 과거에 거의 또는 전혀 발생하지 않은 새로운 특징 조합을 탐색
- 추천의 다양성을 개선
- 사용자의 다양한 관심사와 취향을 고려하여 사용자가 아직 알지 못한 새로운 항목을 추천
-
Google Play Store의 app-recommendation실험을 했지만 일반적인 추천에도 사용할 수 있다
-
기존 모델의 한계
- Generalized Linear Model
- 다양한 feature를 만들어야 하기 때문에 feature engineering에 들어가는 리소스가 크다
- 주어진 데이터에 대한 기억에 특화(일반화에 취약 - 새로운 또는 관측되지 않은 데이터에 취약하다)
- 오버피팅이 발생
- Embedding based Model
- 새로운 또는 관측되지 않은 데이터에 잘 대응할 수 있다
- Generalization에 특화
- 섬세한 추천이 불가하다
- Generalized Linear Model
2. Recommender System Overview
-
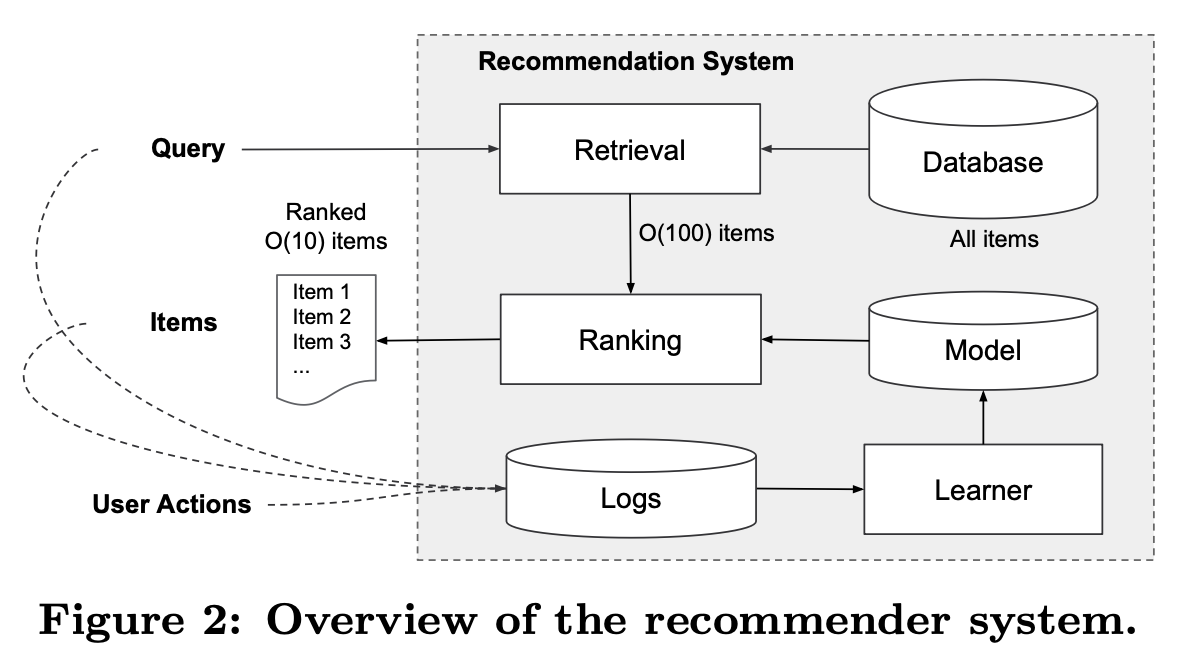
Query(어떤 기기, 언제 접속 했는지, 어떤 앱을 원하고 있는지 etc..) 앱을 접속할 때 발생
-
조회 후 랭키화하여 10개의 상품을 추천
-
10개의 추천에 대해 유저의 action이 발생
-
Query, Items, User Action이 새로운 학습을 위한 데이터가 됨(Logs)
-
이를 Learner를 통해 학습하여 Model의 성능이 점점 좋아지게 된다
-
백만 개 이상의 앱이 있기 때문에, 서빙 지연 시간 요구 사항 (일반적으로 O(10) 밀리초) 내에서 모든 쿼리에 대해 모든 앱을 완전하게 점수화하는 것은 비실용적
-
따라서 쿼리를 수신하면 검색 시스템은 다양한 신호를 사용하여 쿼리와 가장 일치하는 항목의 짧은 목록을 반환
-
후보 풀을 줄인 후, 랭킹 시스템은 모든 항목을 점수별로 순위를 매긴다. 이 논문에서는 Wide & Deep 프레임워크를 사용한 랭킹 모델에 초점을 맞춘다
3. Wide & Deep Learning
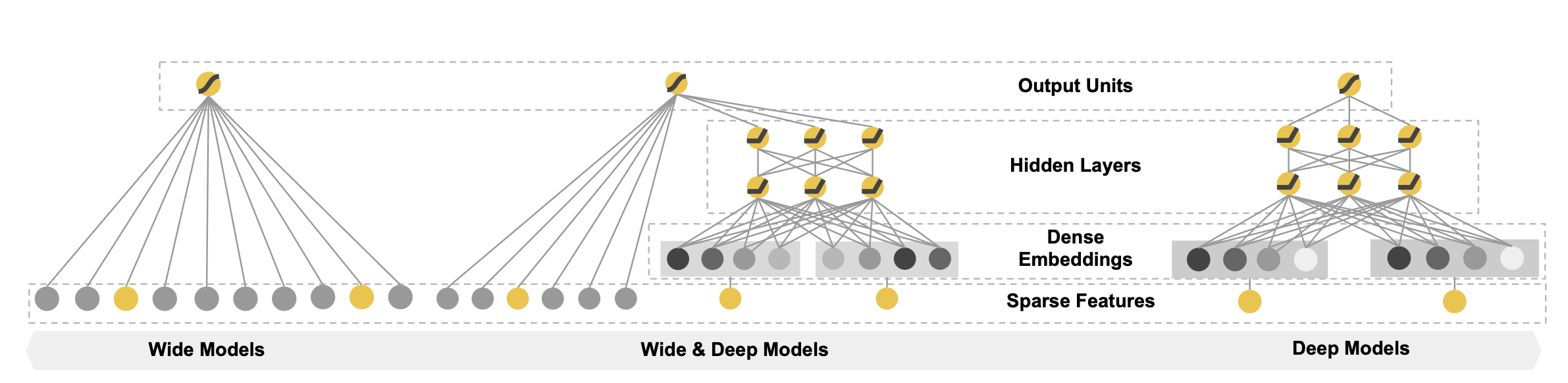
3-1. The Wide Component
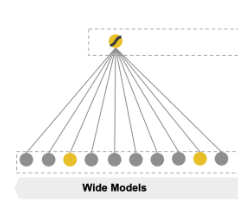
-
y = wT x + b (Linear Model)
-
x → Raw input features & cross-product feature
-
One of the most important transformations is the cross-product transformation
-
선형대수의 cross-product와는 다른 개념
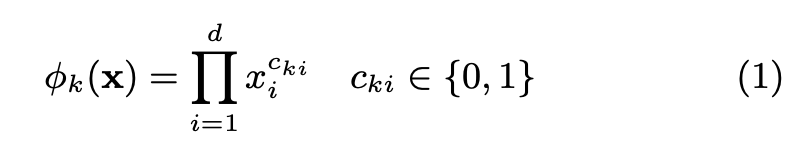
-
사용자 = [남성, 20대]
-
영화 = [액션, 브래드 피트]
-
Cross Product = [남성 x 액션, 남성 x 브래드 피트, 20대 x 액션, 20대 x 브래드 피트]
- 각각의 값이 0 또는 1로 각 위치별 값도 0/1이 나온다
-
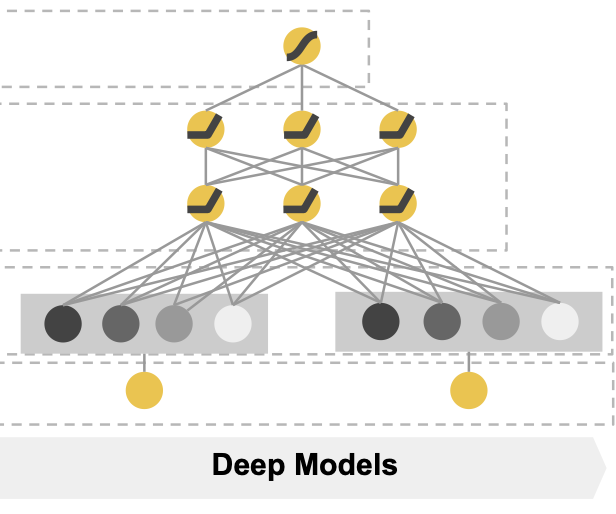
3-2. The Deep Component
-
기본적인 feed forward neural network
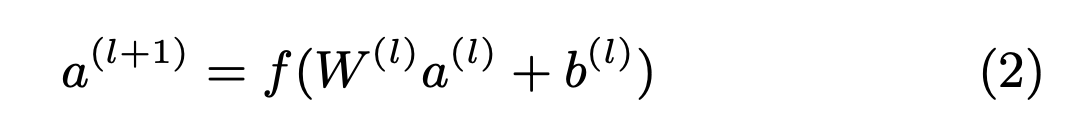
- activation = ReLu
-
faetures를 embedding과 뉴럴넷에 학습
3-3 Joint Training of Wide & Deep Model
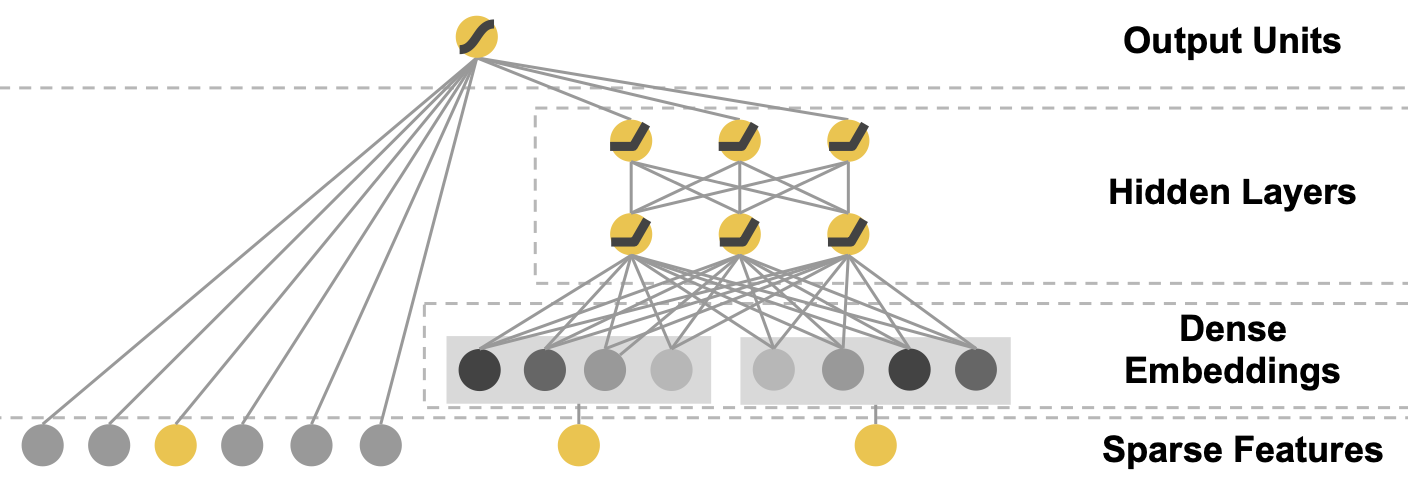
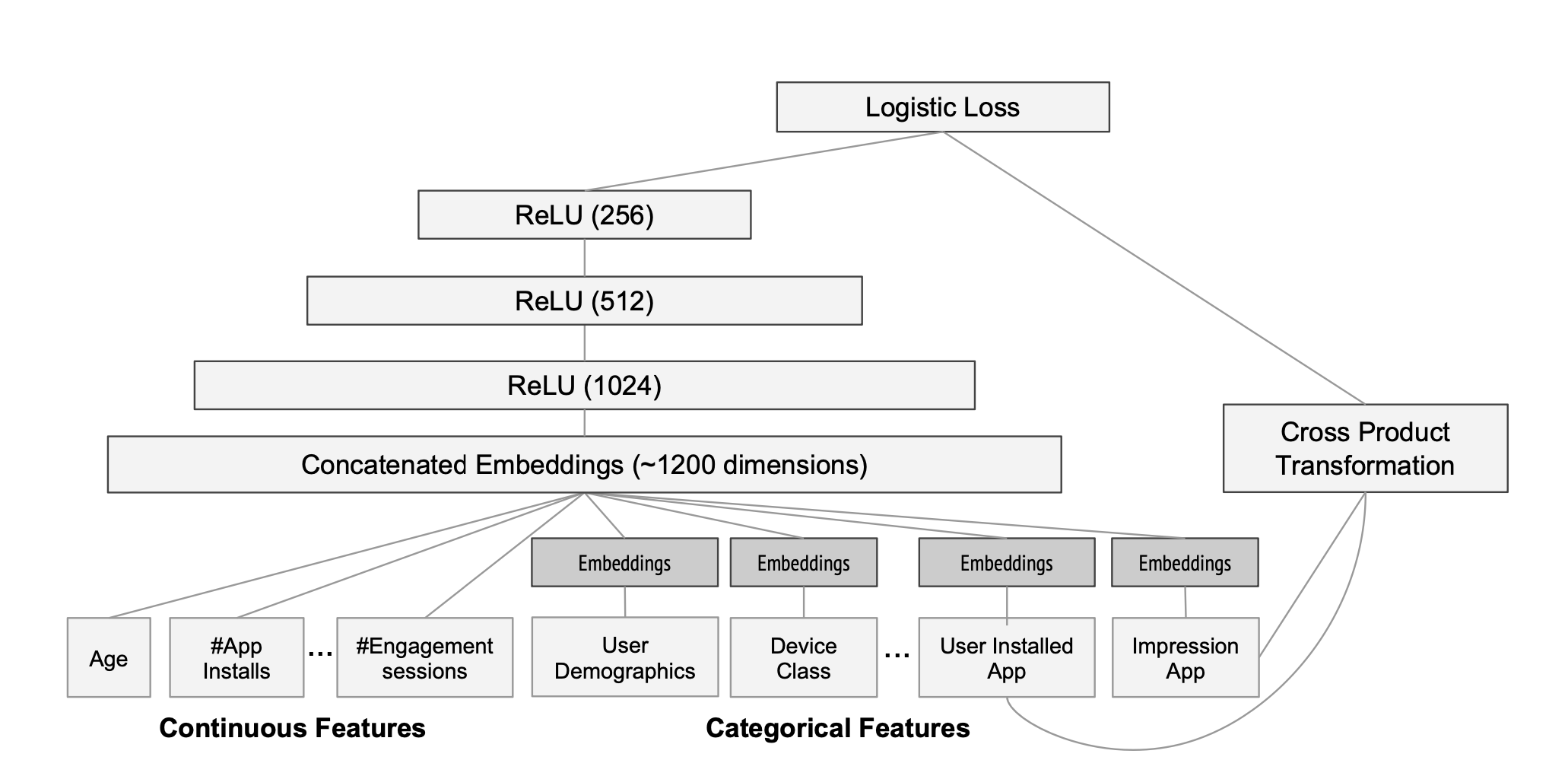
-
joint training은 여러개의 모델을 결합하는 앙상블과 달리, output의 gradient를 wide와 deep모델에 동시에 back propagation하여 학습
- optimizer( Wide : Follow-the-regularized-leader(FTRL), Deep: AdaGrad)
-
Wide
- cross-product의 결과를 input으로 사용하게된다
-
Deep
- continuous feature와 임베딩 된 categorical feature를 concat하여 Deep의 input으로 사용하게 된다
-
최종적으로 얻을 결과 값은
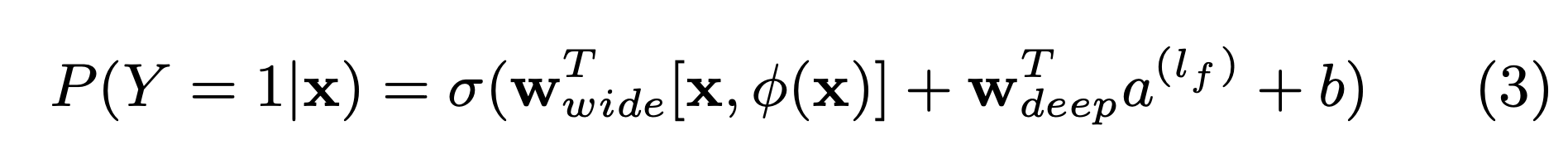
- Y is the binary class label
- σ(·) is the sigmoid function,
- φ(x) are the cross product transformations of the original features x
- a(lf ) is Deep model activation function
- W : weight
- X라는 feature일 때 앱을 다운받을 확률
4. System Implementation
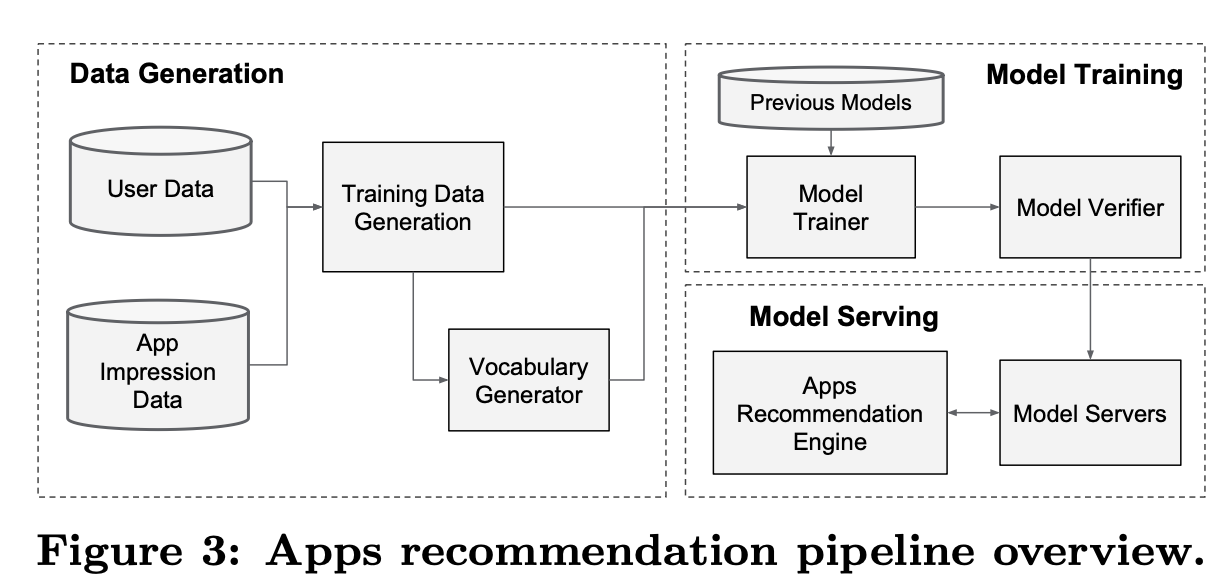
4-1. Data Generation
- 일정 기간 동안의 사용자 및 앱 노출 데이터를 사용하여 학습 데이터 생성
- 레이블은 노출된 앱이 설치 되었으면 1, 설치되지 않았으면 0
- vocabularies : categorical feature들을 정수형 변수로 매핑한 table
- continuous 실수 feature들은 feature x를 누적 분포 함수에 매핑하여 [0,1]로 normalized
4-2. Model Training
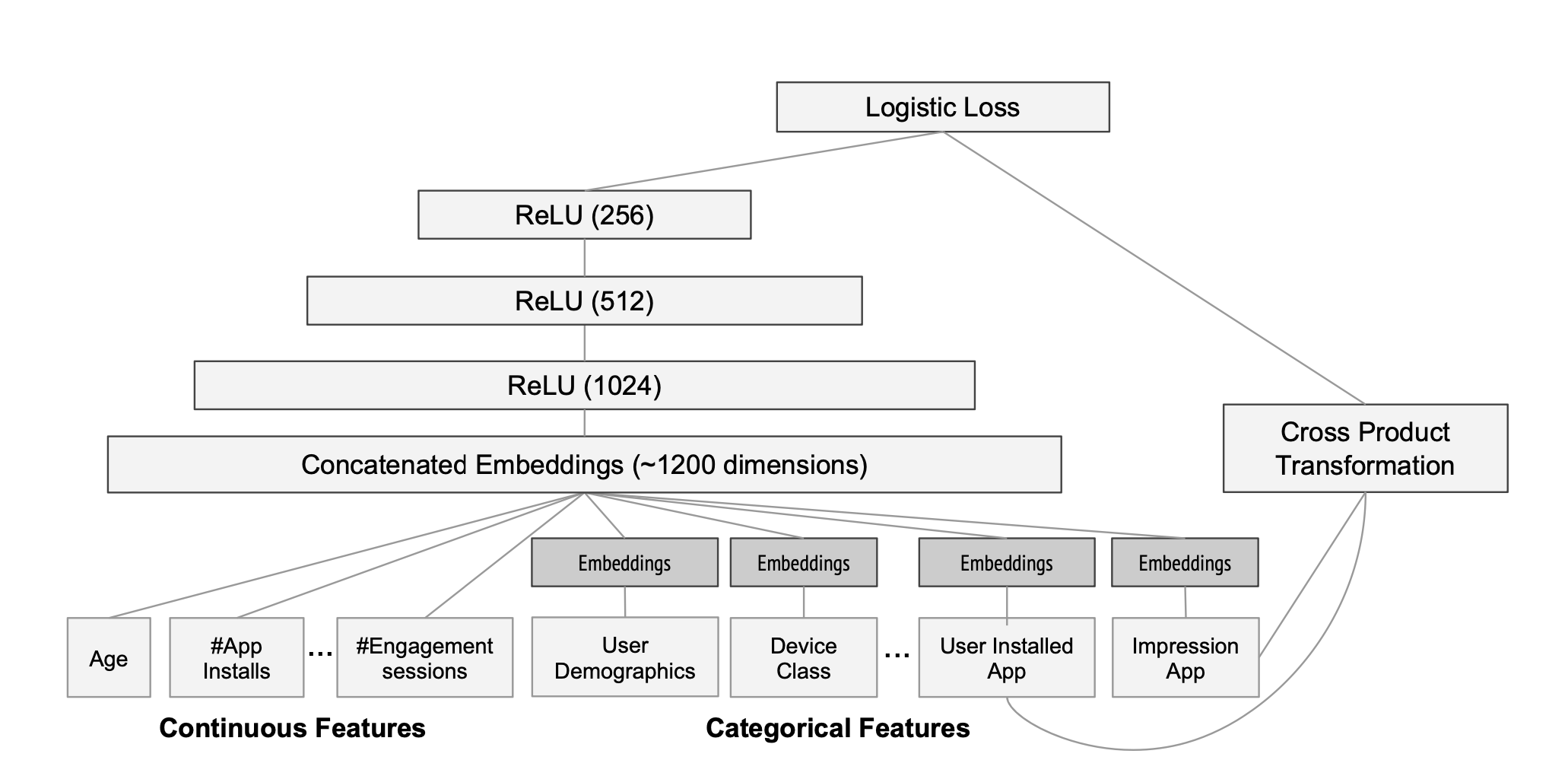
- 각 categorical feature 마다 32 dimension embedding vector를 학습
- 5000억 개 이상의 예제들로 학습
- 새로운 훈련 데이터가 도착할 때 재훈련에 들어가는 비용과 제공 시간 지연을 최소화하기 위해서 warm start 시스템을 구축
- 이전 모델에서 임베딩과 선형 모델 가중치를 가져와 새로운 모델을 초기화
4-3. Model Serving
- 각 요청마다 앱 후보들과 사용자 특징을 받아 각 앱의 점수를 계산
- 점수로 Rank화 하여 사용자에게 노출
- 요청을 10ms(0.01) 정도의 처리 시간으로 처리하기 위해 모든 후보 앱을 한 번에 점수화하는 대신 작은 배치를 병렬로 실행하여 멀티스레딩 병렬성을 사용하여 성능을 최적화
5. Experiment Results
- we ran live experiments and evaluated the system in a couple of aspects: app acqui- sitions and serving performance.
5-1. App Acquisitions
- A/B testing framework를 통해 3주동안 실험을 진행
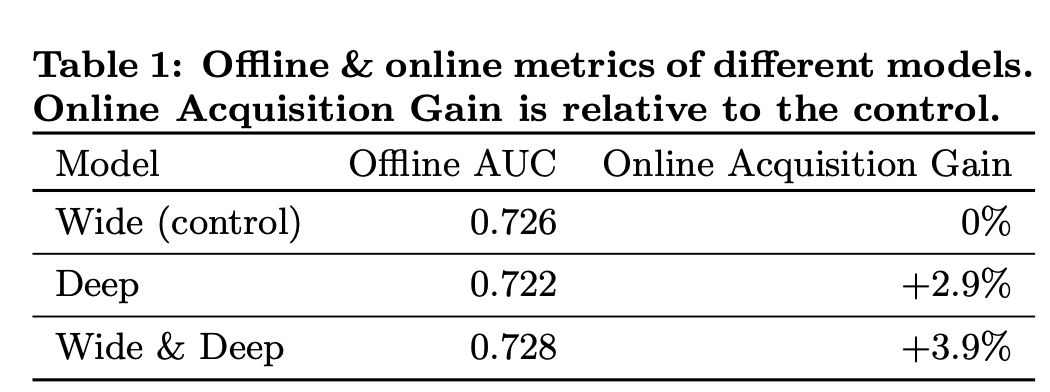
- Offline AUC
- Test Set의 사용자 행동결과로 성능 측정
- AUC는 클수록 좋은 점수 (=ROC 커브의 아래 면적)
- Offline Acquisition Gain
- 실제 사용자들의 action을 추적
- 기존 모델 대비 application 실제 다운로드 수가 증가
5-2. Serving Performance

- 상용 모바일 앱 스토어에서는 높은 수준의 트래픽으로 인해 고 처리량과 낮은 지연 시간으로 서빙하는 것은 challenging(최대 트래픽 시간에는 추천 서버가 초당 1,000만 개 이상의 앱을 점수화)
- 단일 스레딩으로는 하나의 배치에서 모든 후보 앱의 점수화에 31 ms
- 멀티스레딩을 구현 지연 시간은 14 ms로 크게 감소
6. Related Work
- Wide와 Deep model의 결합은 이전 연구인 factorization machines에서 영감을 받았다
- 이 논문에서는 내적(dot product) 대신 신경망을 사용하여 임베딩 간의 비선형 상호 작용을 학습하는 방법을 적용했다
- 본 연구에서는 피드포워드 신경망과 선형 모델을 함께 훈련하여 희소한 입력 데이터를 다루었다
- 협업 필터링(CF) 및 컨텐츠 기반 접근법과 다른 방식으로, Wide & Deep 모델을 사용하여 사용자와 impression data(노출 데이터)를 함께 훈련시키는 앱 추천 시스템에 대한 연구가 진행
7. Conclusions
- Wide & Deep Learning
- Linear model과 embedding-based model의 장점을 잘 조합하였다
- Wide : sparse한 feature interaction 효과적으로 기억
- Deep : 저차원 임베딩을 통해 이전에 볼 수 없었던 feature interaction 생성
- 추천 알고리즘을 실제 서비스 환경에서 작동할 수 있도록 구현함
- open sourse로 tensorflow api를 구현하여 다양하게 활용 가능하게 하였다
