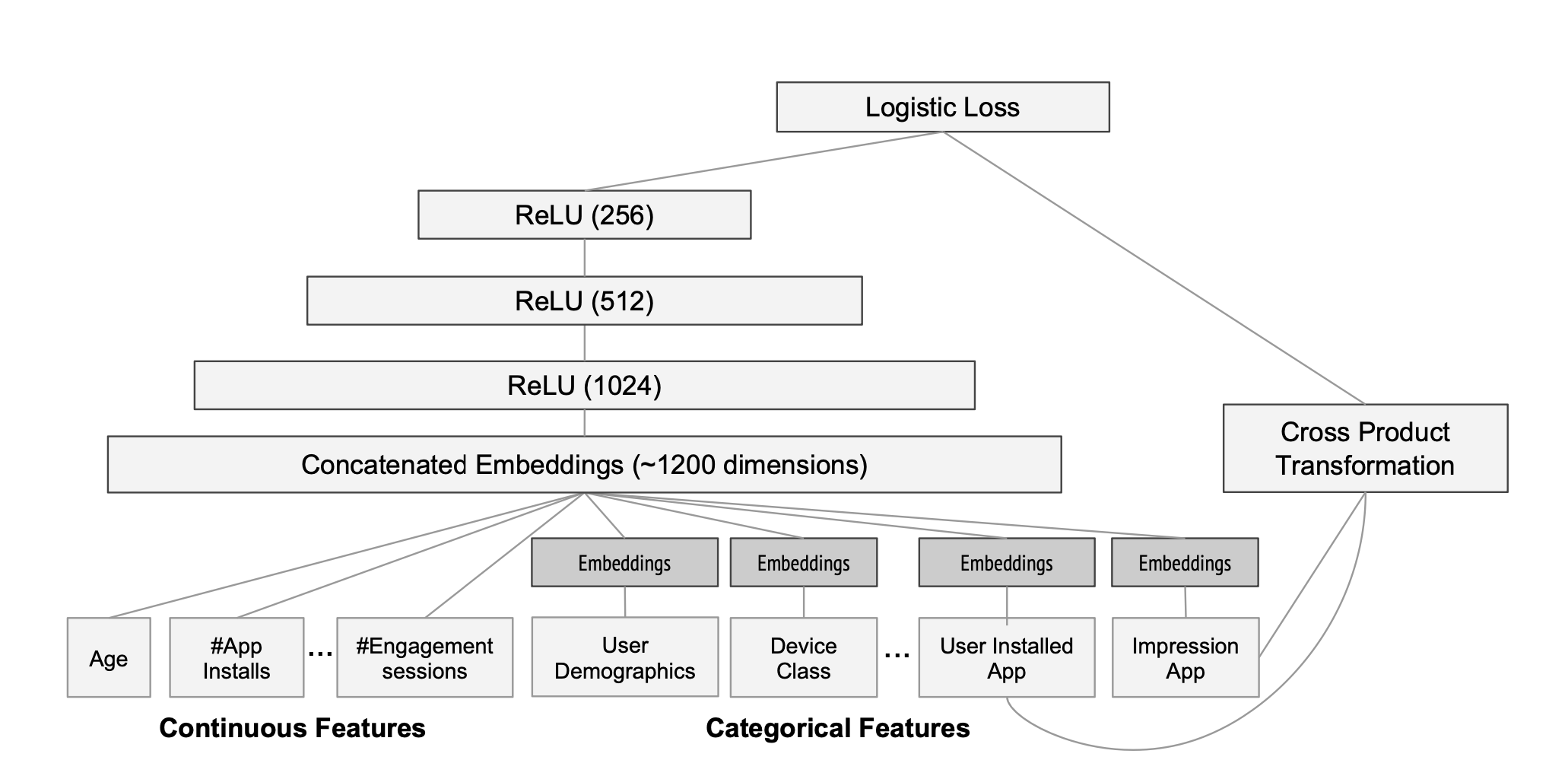
- wide & deep 논문을 읽고, 간략하게 모델 구현
- 논문에 언급되었던 wide model에 input으로 주기 위한 cross-product과정은 다음을 참고하였습니다
https://github.com/jrzaurin/pytorch-widedeep - keras를 이용한 deep model의 구현과 최종 wide deep model의 구현에 있어서는 다음을 참고하였습니다
https://lsjsj92.tistory.com/597 - wide 와 deep model을 concat하여 sigmoid function에 통과시켜 최종적인 확률 값을 얻고자 하였습니다
데이터 로드
- 데이터는 kmrd 데이터 셋을 사용하였습니다.
(movies, castings, countries, genres)
movies_df = pd.read_csv('../data/kmrd/kmr_dataset/datafile/kmrd-small/movies.txt', sep='\t', encoding='utf-8')
movies_df = movies_df.set_index('movie')
castings_df = pd.read_csv('../data/kmrd/kmr_dataset/datafile/kmrd-small/castings.csv', encoding='utf-8')
countries_df = pd.read_csv('../data/kmrd/kmr_dataset/datafile/kmrd-small/countries.csv', encoding='utf-8')
genres_df = pd.read_csv('../data/kmrd/kmr_dataset/datafile/kmrd-small/genres.csv', encoding='utf-8')
# Get genre information
genres = [(list(set(x['movie'].values))[0], '/'.join(x['genre'].values)) for index, x in genres_df.groupby('movie')]
combined_genres_df = pd.DataFrame(data=genres, columns=['movie', 'genres'])
combined_genres_df = combined_genres_df.set_index('movie')
# Get castings information
castings = [(list(set(x['movie'].values))[0], x['people'].values) for index, x in castings_df.groupby('movie')]
combined_castings_df = pd.DataFrame(data=castings, columns=['movie','people'])
combined_castings_df = combined_castings_df.set_index('movie')
# Get countries for movie information
countries = [(list(set(x['movie'].values))[0], '/'.join(x['country'].values)) for index, x in countries_df.groupby('movie')]
combined_countries_df = pd.DataFrame(data=countries, columns=['movie', 'country'])
combined_countries_df = combined_countries_df.set_index('movie')- 각각의 dataframe을 이용하여 영화 정보에 대한 dataframe을 우선 생성하였습니다
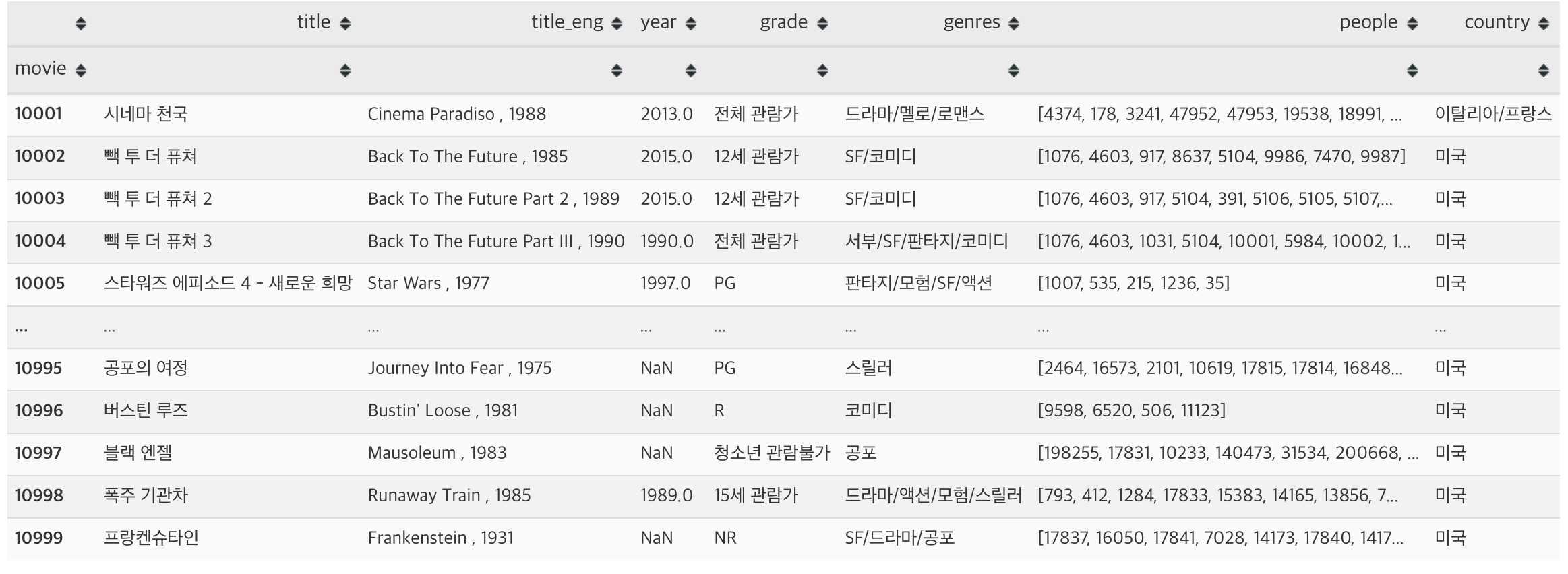
- 결측치를 가지고 있는 row를 drop하여 최종적으로 999개 영화중에 583개의 영화 데이터를 사용하였습니다
- 유저가 어떤 영화를 좋아할지를 예측해야하므로, 유저의 rates 정보에 영화 데이터를 붙여주는 방식으로 train dataframe을 준비하였습다
train_df['genres'] = train_df.apply(lambda x: movies_df.loc[x['movie']]['genres'], axis=1)
val_df['genres'] = val_df.apply(lambda x: movies_df.loc[x['movie']]['genres'], axis=1)
train_df['country'] = train_df.apply(lambda x: movies_df.loc[x['movie']]['country'], axis=1)
val_df['country'] = val_df.apply(lambda x: movies_df.loc[x['movie']]['country'], axis=1)
train_df['grade'] = train_df.apply(lambda x: movies_df.loc[x['movie']]['grade'], axis=1)
val_df['grade'] = val_df.apply(lambda x: movies_df.loc[x['movie']]['grade'], axis=1)
train_df['year'] = train_df.apply(lambda x: movies_df.loc[x['movie']]['year'], axis=1)
val_df['year'] = val_df.apply(lambda x: movies_df.loc[x['movie']]['year'], axis=1)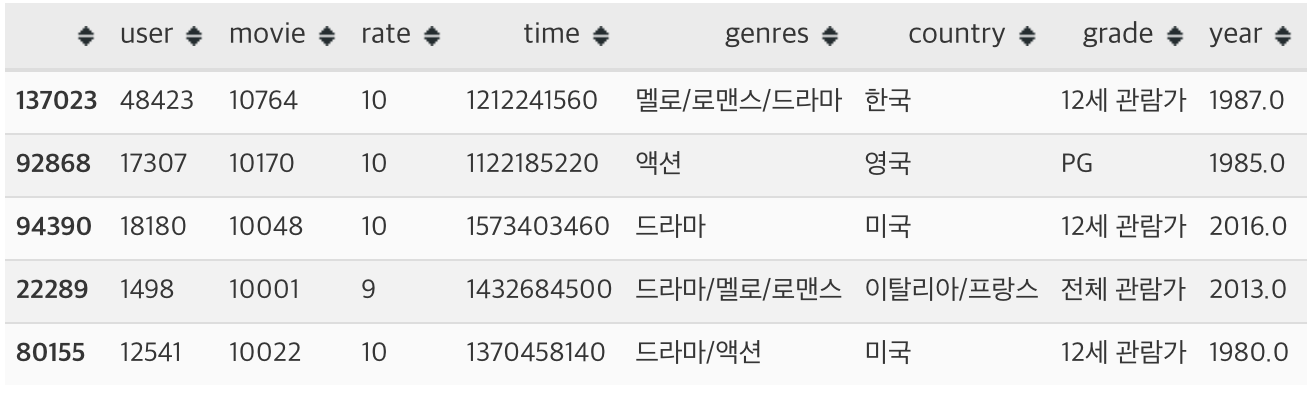
- label값은 평점이 8점 이상인지 아닌지를 기준으로 생성하였습니다
Wide Preprocessor
- wide 모델에 넣기전 cross-product를 진행하게 됩니다
- https://github.com/jrzaurin/pytorch-widedeep의 wide preprocessor를 이용하였습니다
from typing import List, Tuple
import numpy as np
import pandas as pd
class WidePreprocessor():
def __init__(self, wide_cols: List[str], crossed_cols: List[Tuple[str, str]] = None):
self.wide_cols = wide_cols
self.crossed_cols = crossed_cols
def fit(self, df: pd.DataFrame) -> "WidePreprocessor":
df_wide = self._prepare_wide(df)
self.wide_crossed_cols = df_wide.columns.tolist()
glob_feature_list = self._make_global_feature_list(
df_wide[self.wide_crossed_cols]
)
# leave 0 for padding/"unseen" categories
self.encoding_dict = {v: i + 1 for i, v in enumerate(glob_feature_list)}
self.wide_dim = len(self.encoding_dict)
self.inverse_encoding_dict = {k: v for v, k in self.encoding_dict.items()}
self.inverse_encoding_dict[0] = "unseen"
return self
def transform(self, df: pd.DataFrame) -> np.ndarray:
df_wide = self._prepare_wide(df)
encoded = np.zeros([len(df_wide), len(self.wide_crossed_cols)])
for col_i, col in enumerate(self.wide_crossed_cols):
encoded[:, col_i] = df_wide[col].apply(
lambda x: self.encoding_dict[col + "_" + str(x)]
if col + "_" + str(x) in self.encoding_dict
else 0
)
return encoded.astype("int64")
def inverse_transform(self, encoded: np.ndarray) -> pd.DataFrame:
decoded = pd.DataFrame(encoded, columns=self.wide_crossed_cols)
decoded = decoded.applymap(lambda x: self.inverse_encoding_dict[x])
for col in decoded.columns:
rm_str = "".join([col, "_"])
decoded[col] = decoded[col].apply(lambda x: x.replace(rm_str, ""))
return decoded
def fit_transform(self, df: pd.DataFrame) -> np.ndarray:
return self.fit(df).transform(df)
def _make_global_feature_list(self, df: pd.DataFrame) -> List:
glob_feature_list = []
for column in df.columns:
glob_feature_list += self._make_column_feature_list(df[column])
return glob_feature_list
def _make_column_feature_list(self, s: pd.Series) -> List:
return [s.name + "_" + str(x) for x in s.unique()]
def _cross_cols(self, df: pd.DataFrame):
df_cc = df.copy()
crossed_colnames = []
for cols in self.crossed_cols:
for c in cols:
df_cc[c] = df_cc[c].astype("str")
colname = "_".join(cols)
df_cc[colname] = df_cc[list(cols)].apply(lambda x: "-".join(x), axis=1)
crossed_colnames.append(colname)
return df_cc[crossed_colnames]
def _prepare_wide(self, df: pd.DataFrame):
if self.crossed_cols is not None:
df_cc = self._cross_cols(df)
return pd.concat([df[self.wide_cols], df_cc], axis=1)
else:
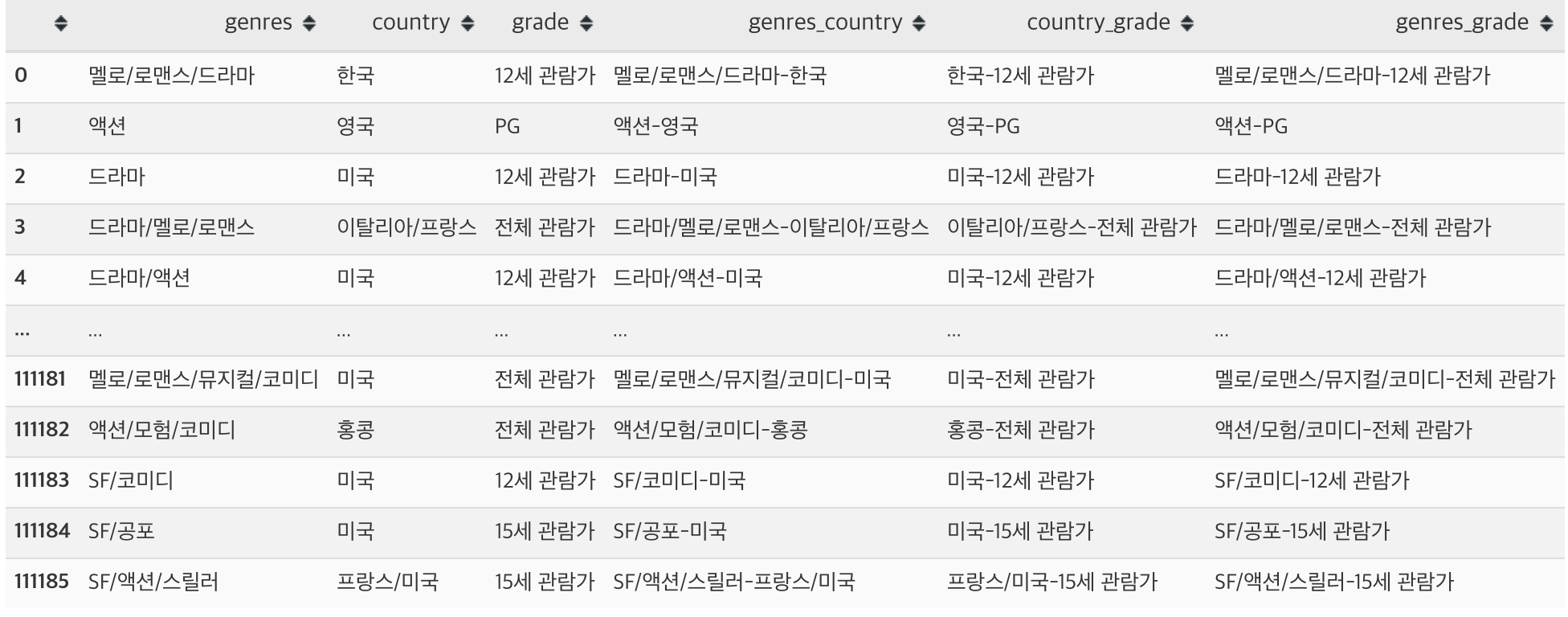
return df.copy()[self.wide_cols]- 각각의 값들에 대한 look up table을 만드는 방식으로 진행됩니다
- 결과적으로 X_wide라는 array가 생성되며 이는 look up table에 매칭된 정수값으로 치환된 값들로 채워집니다
- wide col과 cross col을 입력으로 받습니다
- wide col으로는 ["genres","country","grade"]
- corss col으로는 [("genres","country"),("country","grade"),("genres", "grade")]
- look up table의 형태
{'genres_멜로/로맨스/드라마': 1,
'genres_액션': 2,
'genres_드라마': 3,
...
'genres_grade_뮤지컬-15세 관람가': 915,
'genres_grade_전쟁-전체 관람가': 916,
'genres_grade_드라마/가족-전체 관람가': 917}- 해당 결과를 look-up-table을 이용해 inverse하게 복원하면 다음과 같은 형태입니다
- 사용은 다음과 같습니다. X_wide는 결론적으로 wide모델의 input값 입니다
wide_preprocessor = WidePreprocessor(wide_cols=wide_cols, crossed_cols=crossed_cols)
X_wide = wide_preprocessor.fit_transform(train_df)Deep Preprocessor
class DeepPreprocessor():
def __init__(self, categorical_cols: List[str], continuous_cols: List[str]=None):
self.categorical_cols = categorical_cols
self.continuous_cols = continuous_cols
def fit_transform(self, df: pd.DataFrame):
copy_df = df.copy()
for c in self.categorical_cols:
le = LabelEncoder()
copy_df[c] = le.fit_transform(copy_df[c])
X_train_category = np.array(copy_df[self.categorical_cols])
scaler = StandardScaler()
X_train_continue = scaler.fit_transform(np.array(copy_df[self.continuous_cols]))
return X_train_category, X_train_continue- category 데이터는 LabelEncoder를 사용하여 숫자로 바꿔주며, continuous한 데이터는 StandardScaler를 사용하여 정규화를 하였습니다
- X_train_category, X_train_continue는 deep model의 input으로 사용됩니다
Wide model
class Wide:
def __init__(self):
self.wide_model = None
def make_wide_model(self, X_wide: np.array) -> "WideModel":
input_wide = Input(shape=(X_wide.shape[1],))
emb_wide = Embedding(len(np.unique(X_wide))+1, 1, input_length=X_wide.shape[1])(input_wide)
wide_model = Flatten()(emb_wide)
self.wide_model = wide_model
return self- pytorch로 구현된 패키지의 다음 부분을 참고하여 임베딩을 진행하였습니다

Deep model
class Deep:
def __init__(self, categorical_cols: List[str], continuous_cols: List[str]=None, embed_dim_ratio: float=0.5):
self.category_inputs = []
self.continue_inputs = []
self.categorical_cols = categorical_cols
self.continuous_cols = continuous_cols
self.deep_model = None
self.embed_dim_ratio= embed_dim_ratio
def make_deep_model(self, df: pd.DataFrame):
copy_df = df.copy()
category_embeds = []
for i in range(len(self.categorical_cols)):
input_i = Input(shape=(1,), dtype='int32')
dim = len(np.unique(copy_df[self.categorical_cols[i]]))
embed_dim = int(np.ceil(dim**self.embed_dim_ratio))
embed_i = Embedding(dim, embed_dim, input_length=1)(input_i)
flatten_i = Flatten()(embed_i)
self.category_inputs.append(input_i)
category_embeds.append(flatten_i)
self.continue_inputs = Input(shape=(len(self.continuous_cols),))
continue_dense = Dense(128, use_bias=False)(self.continue_inputs)
concat_embeds = concatenate([continue_dense] + category_embeds)
concat_embeds = Activation('relu')(concat_embeds)
bn_concat = BatchNormalization()(concat_embeds)
fc1 = Dense(512, use_bias=False)(bn_concat)
relu1 = ReLU()(fc1)
bn1 = BatchNormalization()(relu1)
fc2 = Dense(256, use_bias=False)(bn1)
relu2 = ReLU()(fc2)
bn2 = BatchNormalization()(relu2)
fc3 = Dense(128)(bn2)
relu3 = ReLU()(fc3)
self.deep_model = relu3
return self- category 데이터에 대해서 임베딩을 진행할 때, emb_dim차원은 default로 0.5로 진행하였습니다
-
pytorch로 구현된 패키지에서는 다음과 같이 사용하고 있습니다
if embedding_rule == "google": return int(round(n_cat**0.25)) elif embedding_rule == "fastai_old": return int(min(50, (n_cat // 2) + 1)) else: return int(min(600, round(1.6 * n_cat**0.56)))
-
- continue_dense, category_embeds을 concat한 뒷 fully connected layer를 통과하는 과정을 진행합니다
Wide and Deep
class WideDeep:
def __init__(self, wide: Wide, deep: Deep, activation_func: str = "sigmoid"):
self.wide_instance = wide
self.deep_instance = deep
self.activation_func = activation_func
def make_wide_deep_model(self):
out_layer = concatenate([self.deep_instance.deep_model, self.wide_instance.wide_model])
inputs = [self.deep_instance.continue_inputs] + self.deep_instance.category_inputs + [self.wide_instance.wide_model]
output = Dense(1, activation=self.activation_func)(out_layer)
model = Model(inputs=inputs, outputs=output)
return model- Wide와 Deep 객체를 input으로 받아 최종 wide_deep model을 구성합니다
- 최종적으로 sigmoid함수를 통과시키는 Dense를 통해 해당 아이템을 좋아할 확률값을 예측하게 됩니다
wide = Wide().make_wide_model(X_wide)
deep = Deep(categorical_cols, continuous_cols).make_deep_model(train_df)
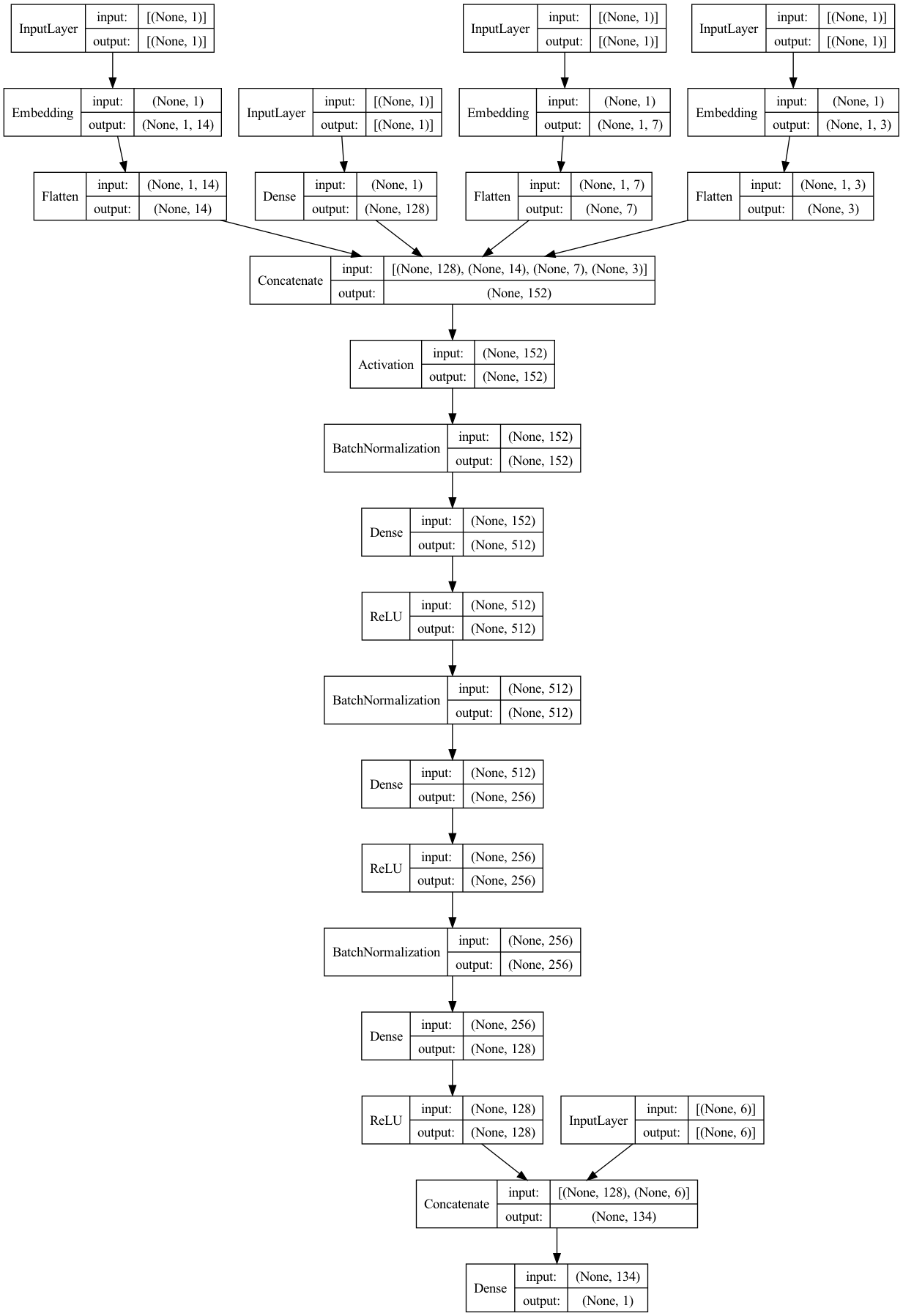
model = WideDeep(wide, deep).make_wide_deep_model()Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_2 (InputLayer) [(None, 1)] 0 []
input_3 (InputLayer) [(None, 1)] 0 []
input_4 (InputLayer) [(None, 1)] 0 []
input_5 (InputLayer) [(None, 1)] 0 []
embedding_1 (Embedding) (None, 1, 14) 2492 ['input_2[0][0]']
embedding_2 (Embedding) (None, 1, 7) 343 ['input_3[0][0]']
embedding_3 (Embedding) (None, 1, 3) 27 ['input_4[0][0]']
dense (Dense) (None, 128) 128 ['input_5[0][0]']
flatten_1 (Flatten) (None, 14) 0 ['embedding_1[1][0]']
flatten_2 (Flatten) (None, 7) 0 ['embedding_2[1][0]']
flatten_3 (Flatten) (None, 3) 0 ['embedding_3[1][0]']
concatenate (Concatenate) (None, 152) 0 ['dense[1][0]',
'flatten_1[1][0]',
'flatten_2[1][0]',
'flatten_3[1][0]']
activation (Activation) (None, 152) 0 ['concatenate[1][0]']
batch_normalization (BatchNorm (None, 152) 608 ['activation[1][0]']
alization)
dense_1 (Dense) (None, 512) 77824 ['batch_normalization[1][0]']
re_lu (ReLU) (None, 512) 0 ['dense_1[1][0]']
batch_normalization_1 (BatchNo (None, 512) 2048 ['re_lu[1][0]']
rmalization)
dense_2 (Dense) (None, 256) 131072 ['batch_normalization_1[1][0]']
re_lu_1 (ReLU) (None, 256) 0 ['dense_2[1][0]']
batch_normalization_2 (BatchNo (None, 256) 1024 ['re_lu_1[1][0]']
rmalization)
dense_3 (Dense) (None, 128) 32896 ['batch_normalization_2[1][0]']
re_lu_2 (ReLU) (None, 128) 0 ['dense_3[1][0]']
input_6 (InputLayer) [(None, 6)] 0 []
concatenate_1 (Concatenate) (None, 134) 0 ['re_lu_2[1][0]',
'input_6[0][0]']
dense_4 (Dense) (None, 1) 135 ['concatenate_1[1][0]']
==================================================================================================
Total params: 248,597
Trainable params: 246,757
Non-trainable params: 1,840
__________________________________________________________________________________________________
학습
input_data = [X_train_continue] + [X_train_category[:, i] for i in range(X_train_category.shape[1])] + [X_wide]
epochs = 30
optimizer ='adam'
batch_size = 128
model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
model.fit(input_data, train_target, epochs=epochs, batch_size=batch_size, validation_split=0.15, callbacks=[checkpoint, early_stopping])...
739/739 [==============================] - 19s 25ms/step - loss: 0.5216 - accuracy: 0.7729 - val_loss: 0.4955 - val_accuracy: 0.7843
Epoch 10/30
739/739 [==============================] - ETA: 0s - loss: 0.5176 - accuracy: 0.7737
Epoch 10: val_loss did not improve from 0.49554
739/739 [==============================] - 18s 25ms/step - loss: 0.5176 - accuracy: 0.7737 - val_loss: 0.5064 - val_accuracy: 0.7768
Epoch 11/30
739/739 [==============================] - ETA: 0s - loss: 0.5178 - accuracy: 0.7742
Epoch 11: val_loss improved from 0.49554 to 0.48547, saving model to ./checkpoint/wide-deep-keras.h5
739/739 [==============================] - 18s 25ms/step - loss: 0.5178 - accuracy: 0.7742 - val_loss: 0.4855 - val_accuracy: 0.7864
...test
wide_preprocessor = WidePreprocessor(wide_cols=wide_cols, crossed_cols=crossed_cols)
X_test_wide = wide_preprocessor.fit_transform(val_df)
deep_preprocessor = DeepPreprocessor(categorical_cols, continuous_cols)
X_test_category, X_test_continue = deep_preprocessor.fit_transform(val_df)
eval_input_data = [X_test_continue] + [X_test_category[:, i] for i in range(X_test_category.shape[1])] + [X_test_wide]
result = model.predict(eval_input_data)
df_val = pd.DataFrame([result.reshape(-1), val_target]).transpose()
df_val = df_val.rename(columns={0: 'predict', 1: 'real'})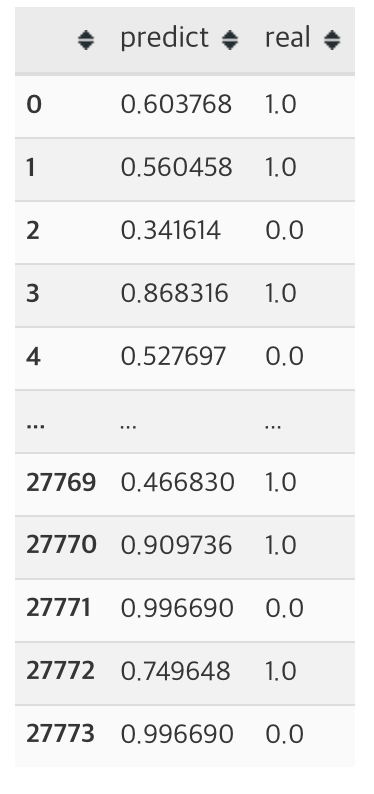
df_val['is_predict_over_half'] = df_val['predict'].apply(lambda x: 1 if x >= 0.5 else 0)- 예측 확률이 0.5 초과인 경우 값을 1로 대응하였습니다
pytorch 패키지에서도 같게 처리한 것을 확인할 수 있었습니다
if self.method == "binary":
preds = np.vstack(preds_l).squeeze(1)
return (preds > 0.5).astype("int")- 이를 통해 실제 1인 값을 얼마나 맞췄는지에 대해서는 다음 값이 나왔습니다
df_val['is_correct'].sum() / df_val.shape[0]
0.6616619860301001loss, acc = model.evaluate(eval_input_data, val_target)
test_loss: 0.7483738660812378 - test_acc: 0.6616619825363159- 구현 자체에 초점을 맞추어 어떤 col을 선택하여 wide와 deep에 넣을지에 대해서는 크게 신경쓰지 않았습니다
- 유저에 대한 정보가 input으로 들어가는 것이 없기 때문에 영화에 대략적인 정보만으로 평정을 예측하게 되었습니다. 따라서 개인 맞춤 추천이라고 보기는 힘들 것 같지만 구현 자체의 의미를 두었습니다
- 추후 유저 개인의 정보까지 포함된 데이터 셋을 이용하여 적용해볼 예정입니다
- 최종 코드는 다음 주소에 있습니다
https://github.com/hongchal/ml_study/blob/master/wide_and_deep_recommender/wide_and_deep_recommender_keras .ipynb

데이터와 파이썬을 좋아합니다 :) contact : chal405@naver.com
가치 있는 정보 공유해주셔서 감사합니다.