BI 기말 최종 정리
텍스트 마이닝(9주차)
텍스트로부터 숨어있는 지식들을 발굴해 내는 기술
*비정형 데이터로부터 정형데이터를 만들어 유의미하게 이용
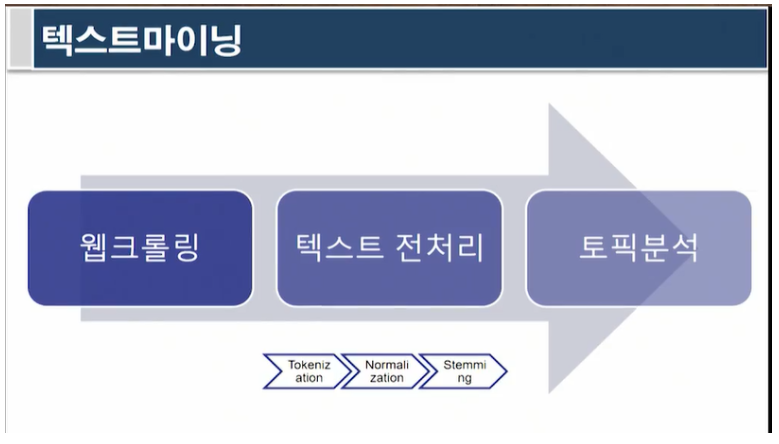
전체적 프로세스
웹크롤링(데이터 수집): 웹사이트, 이메일 등 비구조적 원시데이터
텍스트 전처리(데이터 전처리): 구조적 유형으로 변환
토픽 분석(데이터 분석): 군집화, 분류 등의 모든 설명적, 예측적 기법을 사용
텍스트 전처리
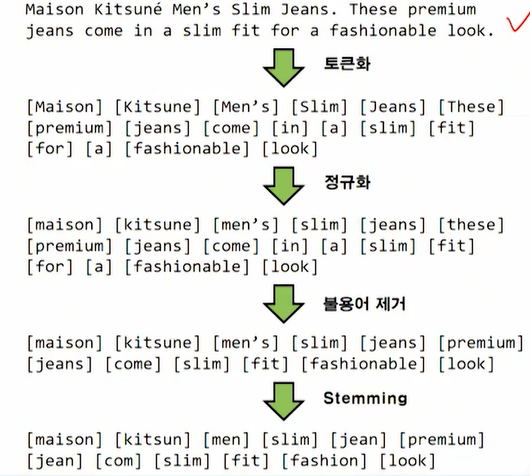
토큰화: 뛰어쓰기 단위로 잘라냄
정규화: 모두 소문자로 변환
불용어 제거: "a", "the", "!"등 특별한 의미가 없는 단어 제거(불용어 사전을 이용함)
문서화 / Term Document Matrix
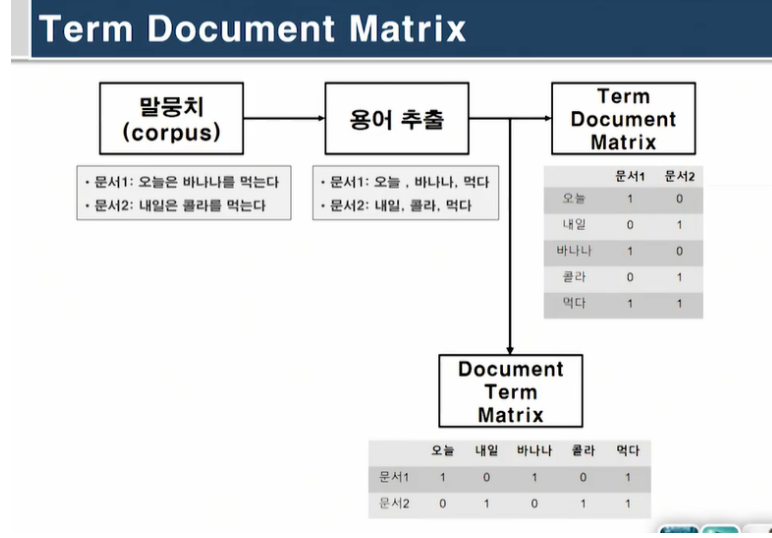
문서(문장)을 텍스트 전처리 과정을 통해 매트릭스 형태로 나타낸다
문장 유사도 계산
코사인 유사도를 이용한다.
ex)
Document 1: dark blue jeans blue denim fabric
Document 2: skinny jeans in bright blue
Query: dark jeans
| dark | blue | jeans | denim | fabric | skinny | in | bright | (크기) | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | ||
| 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | ||
| 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
문장 유사도 계산 결과
TF IDF
특정 단어가 문서에서 얼마나 중요한지 계산할 때 사용
TF
TF: term frequency, 특정 단어가 특정 문서에서 사용된 횟수 (비율)
IDF
DF: document frequency, 특정 단어가 사용된 문서의 수
일반적으로 많은 문서에서 동시 출현하는 빈도가 높을수록 중요도가 떨어지기에 역수값을 취한 IDF를 사용한다.
TF-IDF
흔하지 않은 단어인데 특정 텍스트에서 자주 사용될수록 큰 값을 가짐
계산 예
| S.No. | Sentences |
|---|---|
| 1. | inflation increased unemployment |
| 2. | company increased sales |
| 3. | fear increased pulse |
TF
| Words | inflation increased unemployment | company increased sales | fear increased pulse |
|---|---|---|---|
| inflation | 1/3 | 0/3 | 0/3 |
| company | 0/3 | 1/3 | 0/3 |
| increased | 1/3 | 1/3 | 1/3 |
| sales | 0/3 | 1/3 | 0/3 |
| fear | 0/3 | 0/3 | 1/3 |
| pulse | 0/3 | 0/3 | 1/3 |
| unemployment | 1/3 | 0/3 | 0/3 |
IDF
| Words | Inverse Document Frequency (IDF) |
|---|---|
| inflation | |
| company | |
| increased | |
| sales | |
| fear | |
| pulse | |
| unemployment |
TF-IDF
| inflation | company | increased | sales | fear | pulse | unemployment | |
|---|---|---|---|---|---|---|---|
| inflation increased unemployment | |||||||
| company increased sales | |||||||
| fear increased pulse |
TF-IDF, BOW 장단점
장점: 비교적 단순하며, 문서의 특징을 효울적으로 포착
단점: 단어의 순서를 고려하지 않기 떄문에 문맥적인 의미가 무시됨. 희소 행렬 발생
해소 방안
최근 사용되는 Bert, GPT등의 딥러닝 계열 텍스트 마이닝은 워드 임베딩 기반의 구조화된 기법을 사용.
이는 각 단어들을 벡터로 표현한 후, 순서대로 입력값으로 사용함
텍스트 마이닝 실습
개요
영화 리뷰의 감성 분석
데이터: 영화 리뷰데이터로 긍정/부정 극성을 포함
목적: 상품평을 TF-IDF의 구조호된 형태로 변환
TF-IDF를 활용하여 의사결정나무로 긍정/부정을 분류하는 감성 분석
프로세스 화면
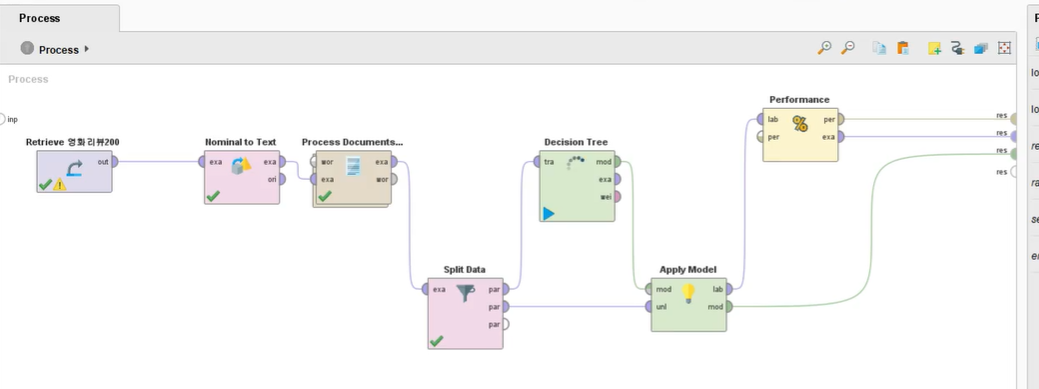
프로세스 도큐먼트 서브 프로세스
토픽 모델링(10주차)
개념
- 텍스트를 분석해 문서 속의 주제들을 찾아내기 위한 통계추론에 기바한한 분석 기법
- 개별 문서는 여러 주제들로 구성되어있다고 가정. 즉 각 문서는 토피들의 확률적 혼합체로 간주함
ex)
문서1: 온난화(0.2), 탄소배출(0.5), 전기차(0.3)
문서2: 온난화(0.3), 빙하기(0.4), 생태계(0.3) - 토픽분석의 시초는 LSA(Latent Semantic Analysis)이며, 가장 많이 사용되는 모델은 LDA(Latent Dirichlet Allocation)임
LDA(잠재디리클레할당)모델
- 디리클레(Dirichlet): 확률분포의 명칭
- 전체 문서들의 주제(토픽) 추출, 각 주제들를 구성하는 단어들, 각 문서별 주제들의 비율을 파악
- 토픽들이 도출되지만, 각 토픽의 이름은 여구자가 직접 붙여줘야함
토픽 모델링의 활용
- 대량의 문서들을 직접 읽어보지 않고도 주제를 파악
- 문서들을 주제별로 분류할 수 있음
- 토픽을 구성하는 주요 단어를 통한 키워드 파악이 가능함
- 그외, 시기별 토픽 모델링을 수행하여 issue tracking을 수행하는 등 활용성이 높음. 예를 들어 SNS글들을 년도별로 토픽모델링하면, 매해 주요 관심 이슈의 변화를 파악할 수 있음.
토픽모델링 실습
개요
워드클라우드&토픽모델링 실습
데이터 수집: 네이버 뉴스에서 수집한 외국인 노동자 관련기사 1,025건
데이터 전처리 파일: 외국인 노동자(명사).txt[전처리완료된 데이터]
토픽모델링(LDA) 프로세스

워드클라우드 프로세스

데이터시각화1 (11주차)
개요
같은 데이터셋(평균, 분산, 상관계수, 회귀식이 동일)을 이용해 그래프를 그려도 차이가 발생할 수 있음.
즉 데이터를 분석 전에 그래프로 확인해 볼 필요가 있음
시각화의 기능
- 효과적으로 데이터를 보여주기
- 공유와 설득을 용이하게
- 데이터에서 가장 중요한 부분을 강조하여
- 시각화를 활용한 분석 -> 데이터의 패턴 파악에 효과적
좋은 디자인에 대한 고민: 단순화
- 단순한 색상 구성
- 주요 트랜드에 집중
- 일관된 스타일과 형태
- 텍스트 단순화
좋은 디자인에 대한 고민: 선택적 레이블링
좋은 디자인에 대한 고민: Multiples
태블루 사용법
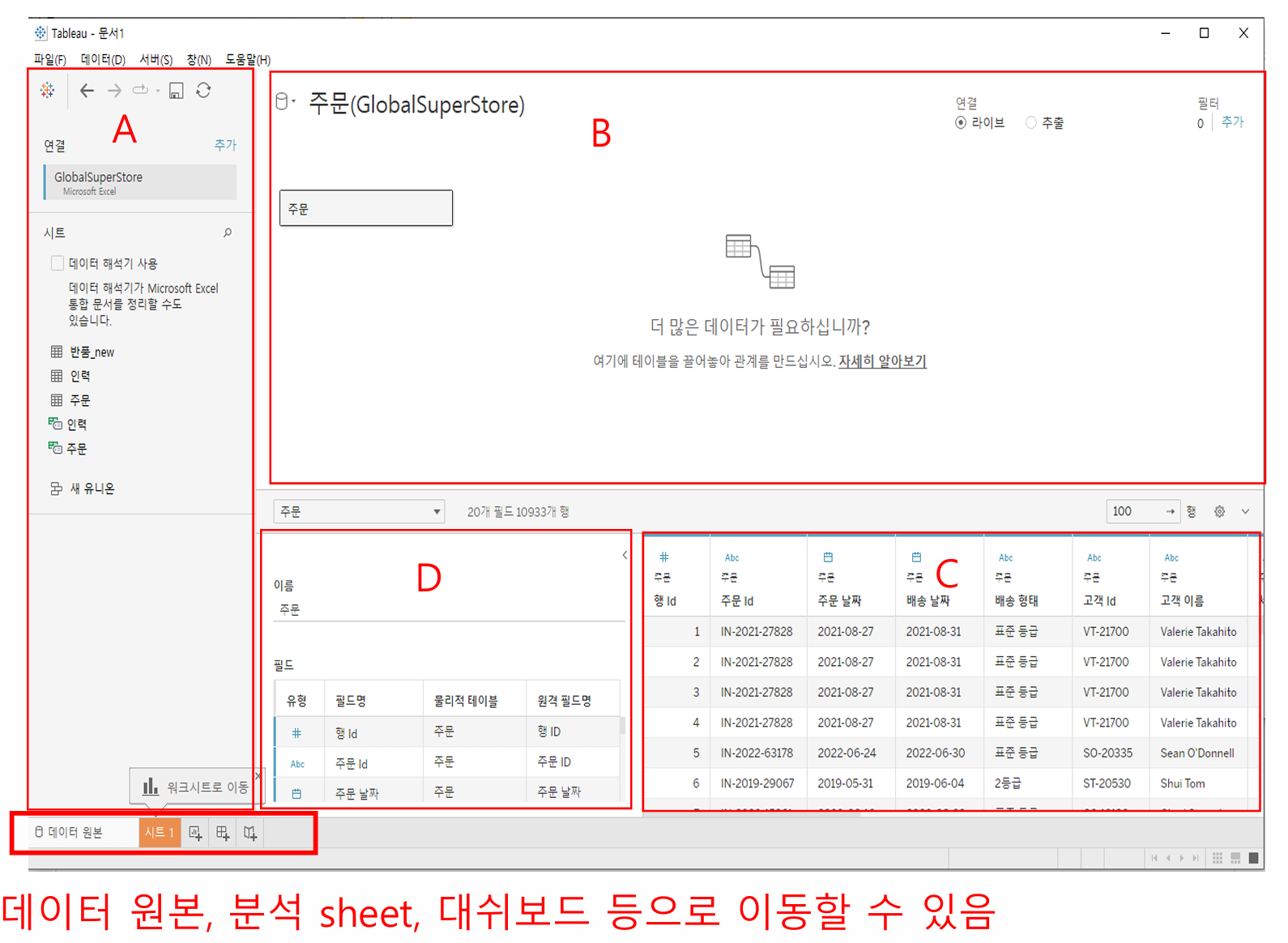
A. 왼쪽 패널 - 연결된 데이터 원본과 데이터에 대한 기타 세부 정보 표시
B. 캔버스 - 데이터 원본 설정 방법과 데이터 결합 옵션에 대한 정보를 표시
C. 데이터 그리드 - Tableau 데이터 원본에 포함된 데이터의 첫 1,000개 행을 표시
D. 메타데이터 그리드 - 데이터 원본의 필드 정보 표시(변수 타입 변경 까지)
병합(Join)
inner(내부조인)
두 테이블 모두에 일치 항목이 있는 값으로 구성된 테이블
Left(왼쪽 조인)
왼쪽 테이블의 모든 값과 오른쪽 텡블에서 해당하는 일치 항목으로 구성
Right(오른쪽 조인)
상동
Full outer join(완전외부)
두 테이블의 모든 값 포함
조인 예시
테이블1
| ID | 이름 | 성 | 출판사 유형 |
|---|---|---|---|
| 20034 | Adam | Davis | Independent |
| 20165 | Ashley | Garcia | Big |
| 20233 | Susan | Nguyen | Small/medium |
테이블 2
| 제목 | 가격 | 로열티 | ID |
|---|---|---|---|
| Weather in the Alps | 19.99 | 5,000 | 20165 |
| My Physics | 8.99 | 3,500 | 20800 |
| The Magic Shoe Lace | 15.99 | 7,000 | 20034 |
이너조인
| ID | 이름 | 성 | 출판사 유형 | 제목 | 가격 | 로열티 | ID |
|---|---|---|---|---|---|---|---|
| 20034 | Adam | Davis | Independent | The Magic Shoe Lace | 15.99 | 7,000 | 20034 |
| 20165 | Ashley | Garcia | Big | Weather in the Alps | 19.99 | 5,000 | 20165 |
아우터조인
| ID | 이름 | 성 | 출판사 유형 | 제목 | 가격 | 로열티 | ID |
|---|---|---|---|---|---|---|---|
| 20034 | Adam | Davis | Independent | The Magic Shoe Lace | 15.99 | 7,000 | 20034 |
| 20165 | Ashley | Garcia | Big | Weather in the Alps | 19.99 | 5,000 | 20165 |
| 20233 | Susan | Nguyen | Small/medium | ||||
| 20800 | My Physics | 8.99 | 3,500 |
left조인
| ID | 이름 | 성 | 출판사 유형 | 제목 | 가격 | 로열티 | ID |
|---|---|---|---|---|---|---|---|
| 20034 | Adam | Davis | Independent | The Magic Shoe Lace | 15.99 | 7,000 | 20034 |
| 20165 | Ashley | Garcia | Big | Weather in the Alps | 19.99 | 5,000 | 20165 |
| 20233 | Susan | Nguyen | Small/medium |
right 조인
| ID | 이름 | 성 | 출판사 유형 | 제목 | 가격 | 로열티 | ID |
|---|---|---|---|---|---|---|---|
| 20034 | Adam | Davis | Independent | The Magic Shoe Lace | 15.99 | 7,000 | 20034 |
| 20165 | Ashley | Garcia | Big | Weather in the Alps | 19.99 | 5,000 | 20165 |
| 20800 | My Physics | 8.99 | 3,500 |
화면 소개
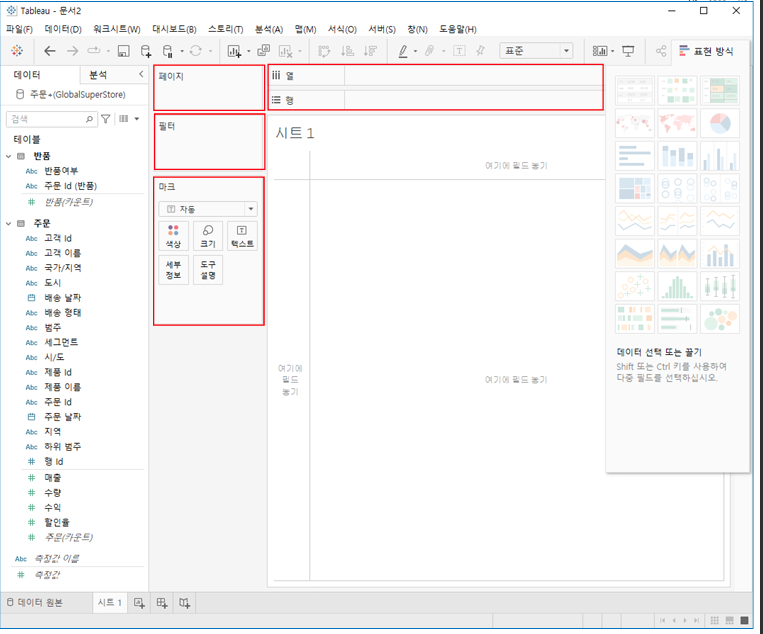
-
열 및 행 선반
- 행 또는 열 선반에 차원을 배치하면 해당 차원 멤버의 머리글이 만들어짐. 복수 개 가능
-
마크 카드
- 마크 카드는 Tableau의 시각적 분석을 위한 핵심 요소로, 마크유형, 색상, 크기, 모양, 텍스트 및 세부정보등을 설정. 마크 카드의 여러 속성에 필드를 끌어 놓으면 뷰의 마크에 컨텍스트 및 세부 정보가 추가됨.
-
필터 선반
- 포함하거나 제외할 데이터를 지정
-
페이지 선반
- 특정 필드가 뷰의 나머지 데이터에 미치는 영향을 쉽게 분석할 수 있도록 분석. 우측에 페이지 컨트롤이 추가되며, 이를 활용하여 페이지 탐색
데이터 계층
주소, 제품 등 많은경우, 데이터가상하위로구성됨
• Ex. 국가-시도-군구 /제품군-하위범주-제품명
계층구성후일괄관리가능
실습
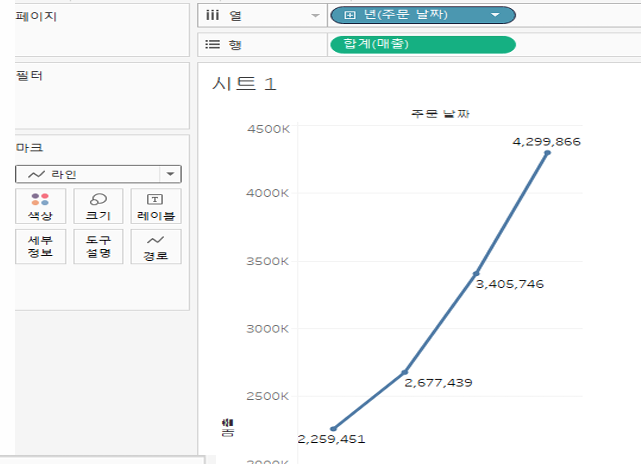
실습1
연도별 총 매출액을 분석하시오
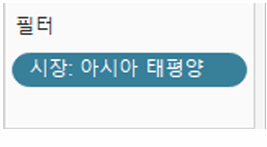
실습2
아시아 태평양 시장에서 반품 정보만 확인하고자할 떄
- "시장"을 드래그하여 필터에 위치 - 아시아 태평양 선택
실습3
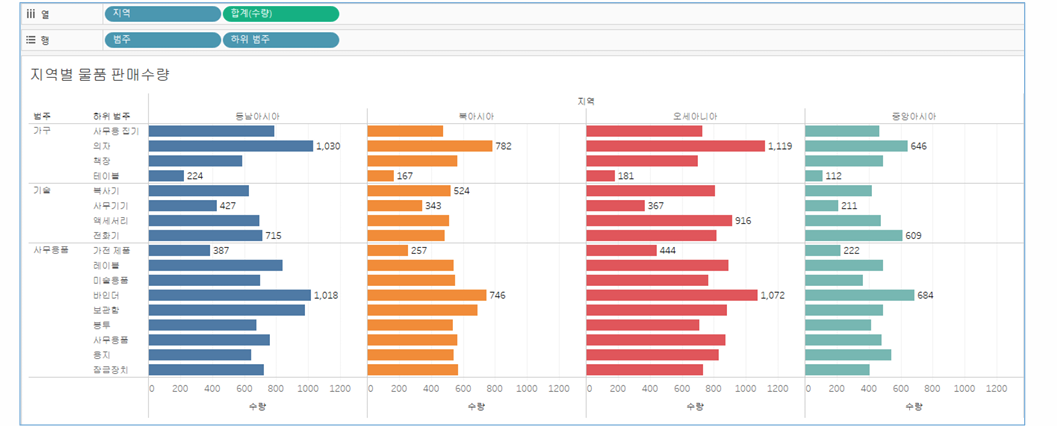
- 전세계“지역”별로어떤“범주”의어떤“하위범주”(segment)제품들이몇개(quantity)팔렸는지그래프로작성하시오.
- “시장” 별로색상을다르게표시하시오.
•행: Category(범주), Segment(하위범주) /열: Market(지역), 합계(수량)설정
•지역을Color로드래그 - 2022년자료만표시하시오
시각화2 (12주차)
워드클라우드
특정 차원(dimension)필드를 지정된 측장값(measure) 기준에 따른 크기로 나타내기
- 워드클라우드로나타내고자하는차원(dimension)을 마크카드의텍스트에드래그해서위치
- 크기로설정하고자하는필드를마크카드의크기에드래그해서위치
- 크기에있는필드는측정값(measure)이어야동작함
- 마크타입을채워진맵, 버블, 텍스트등으로선택가능
- 워드클라으두의마크카드의색상을설정
워드클라우드 실습
동영상 보고 추가할것(미완!!!!!!!!!!!!!!!!!!!!!!)
맵기능
개요
- Tableau의 맵기능은 내부 보유DB로 국가, 주/시/도, 도시 등을 자동으로 인식할 수있음.
- DB에 등록되어있지않은지명은자동인식이안되며, 이경우, 약자, 스펠링오류, 동일한지명
등의문제로인식이안되는것일수있음. - 그외, 회사의지점등, 세부 지역은DB에없기때문에, 위경도를넣어 주어야표기됨. – (ex. 서울과학기술대학교)
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ - 위치는기본적으로마크(Mark)로 표시됨.
- 그러나, 국가(Country), 시/도(State), 우편코드등은 채워진 맵으로 표시가 가능함.
단, 도시 또는 군/구(City) level에서는 채워진 맵 사용 안됨. - Mapbox통합: 위도를 추가한 후, 추가한 위도의 우측에서 이중축으로 설정하면 두개의
서로다른맵을합칠수도있음
실습
실습1
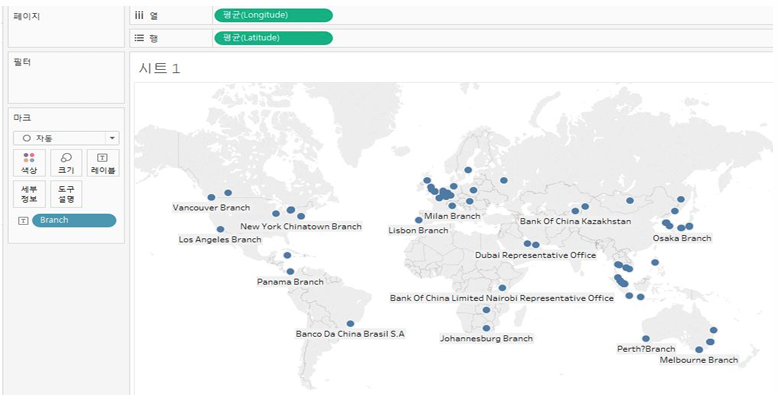
■실습) Bank of China의 글로벌지사를 보려면? (위경도 정보를 활용)
• 파일: Bank of China branches.csv (텍스트로 열기)
• 위도: latitude, 경도: longtitude, 레이블: Branch
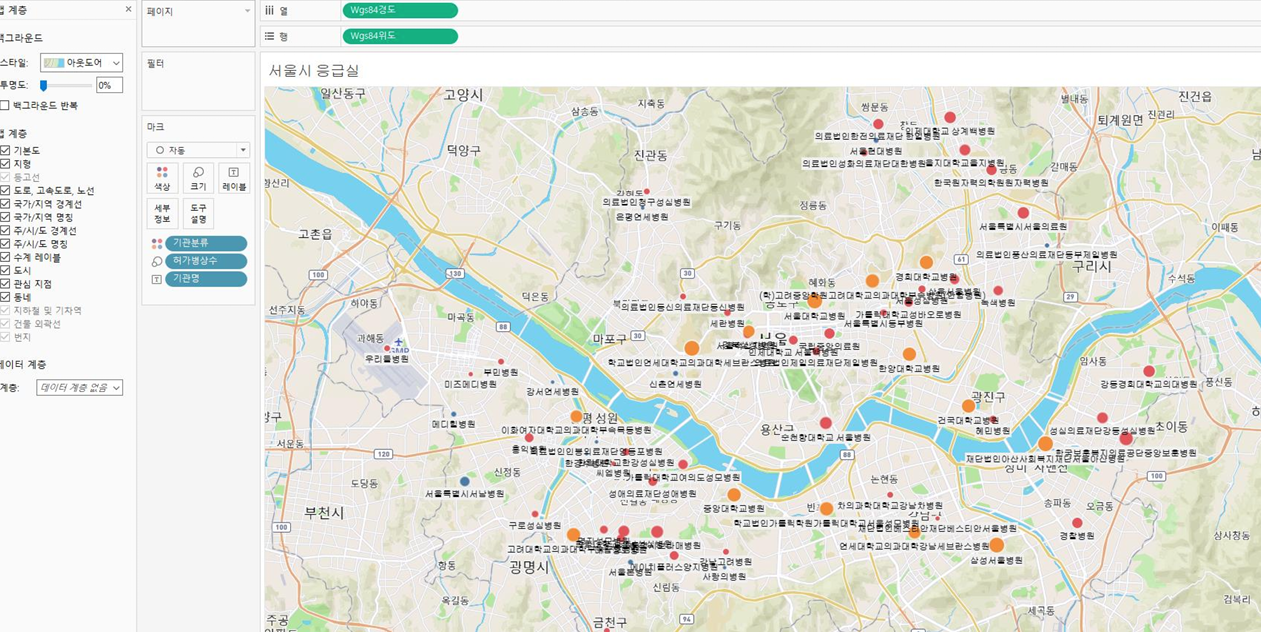
실습2
각구의응급실분포현황을지도로분석하시오.
시각화3 (13주차)
데이터 분석
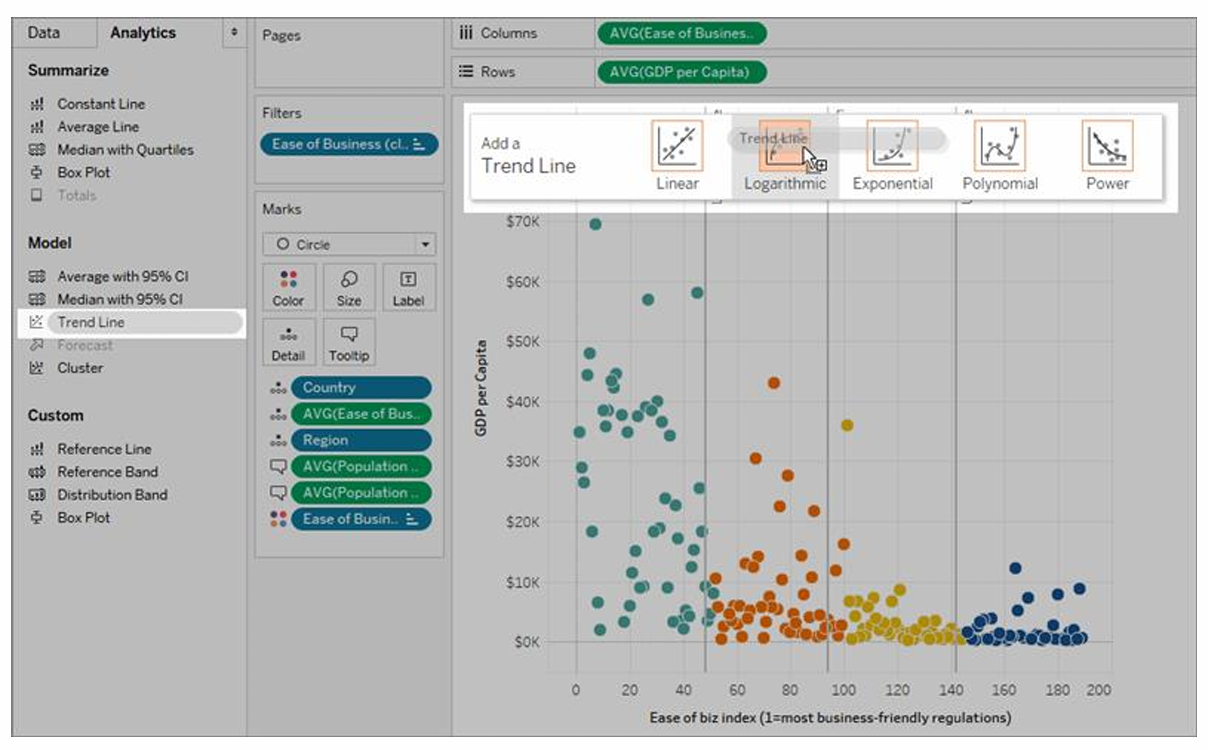
추세선
뷰에 추세선 추가
- 분석 패널에서 추세선을 뷰로 끌어온 다음 선형, 로그, 지수, 다항식 또는 거든제곱 모델 유형 선택
추세선 또는 추세선 모델의 설명 보기
- 추세선을 추가한 후, 마우스 오버하여 R제곱 및 p 값을 표시
- 또는 뷰에서 추세선을 마우스 오른쪽 단추로 클릭한 다음 추세선 설명을 선택
추시선 시각화 실습
열: 주문날짜 행: 매출 또는 수익
좌측 패널의 분석 - 추세선을 드래그하여 뷰에 놓고 원하는 추세선을 선택
추세선 우클릭 - 추세선 설명 확인
- 주의
다중 회귀 분석 불가
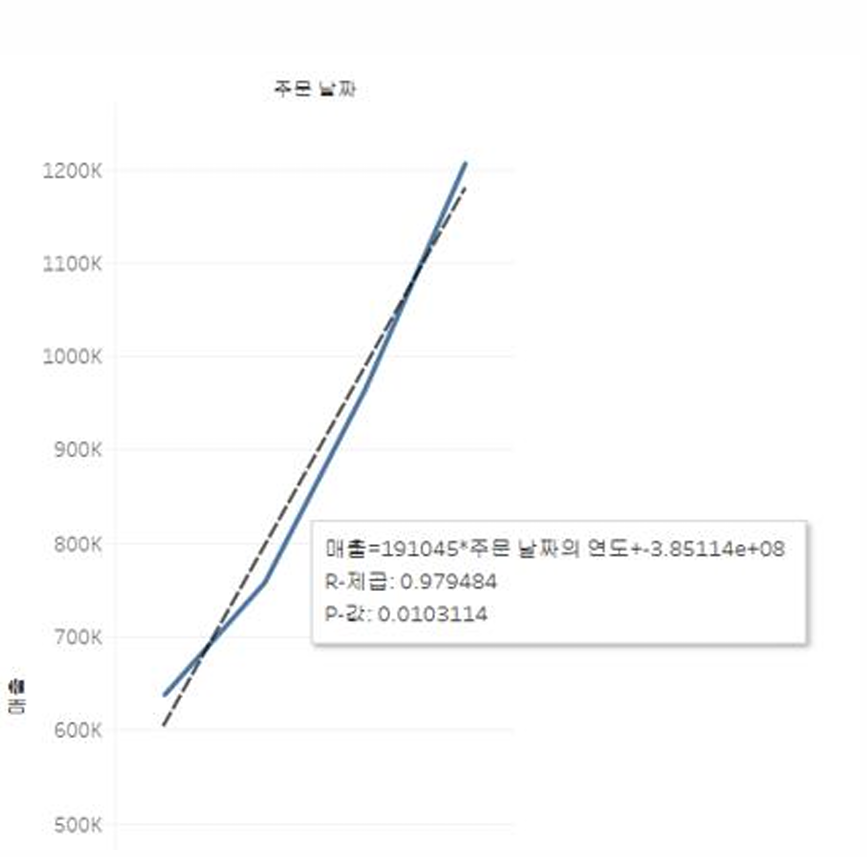
참조선 추가
참조선, 구간, 분포 또는 박스 플롯을 추가하여 Tablue뷰의 연속 축에서 특정 값, 영역 또는 범위를 식별
- 여러 하위 범주의 매출을 분석하는 경우, 평균 매출 마크에 참조선 표시
- 좌측패널 - 분석- 참조선을 끌어서 뷰에 놓고 원하는 참조선 형태를 선택
시계열 자료의 예측
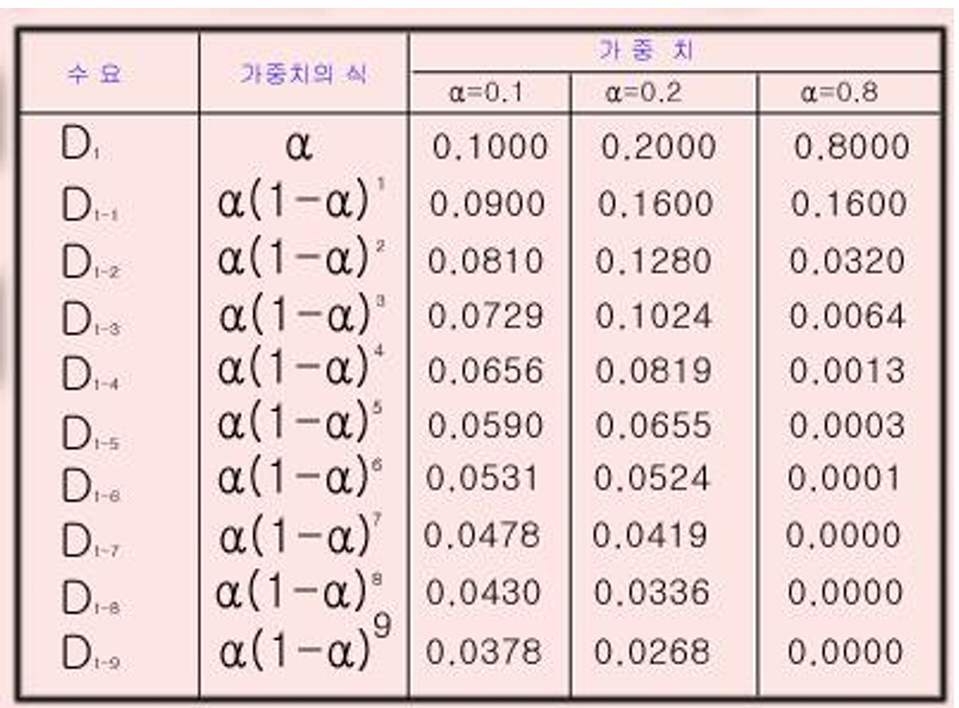
- 지수 평활법을 활용해 시계열 자료를 예측
- 구델 브라운이 송급망 수요를 예측을 위해 제안
- 미래의 매출액 등을 예측하기 위해 쓰이는 정량적 예측 방법 중 하나
- 가까운 과거의 종속변수 값을 예측에 더 많이 반영하고, 먼 과거일 수록 더 저게 반영함
- 가중치:
실습
- 날짜와 측정값만 있으면 가능
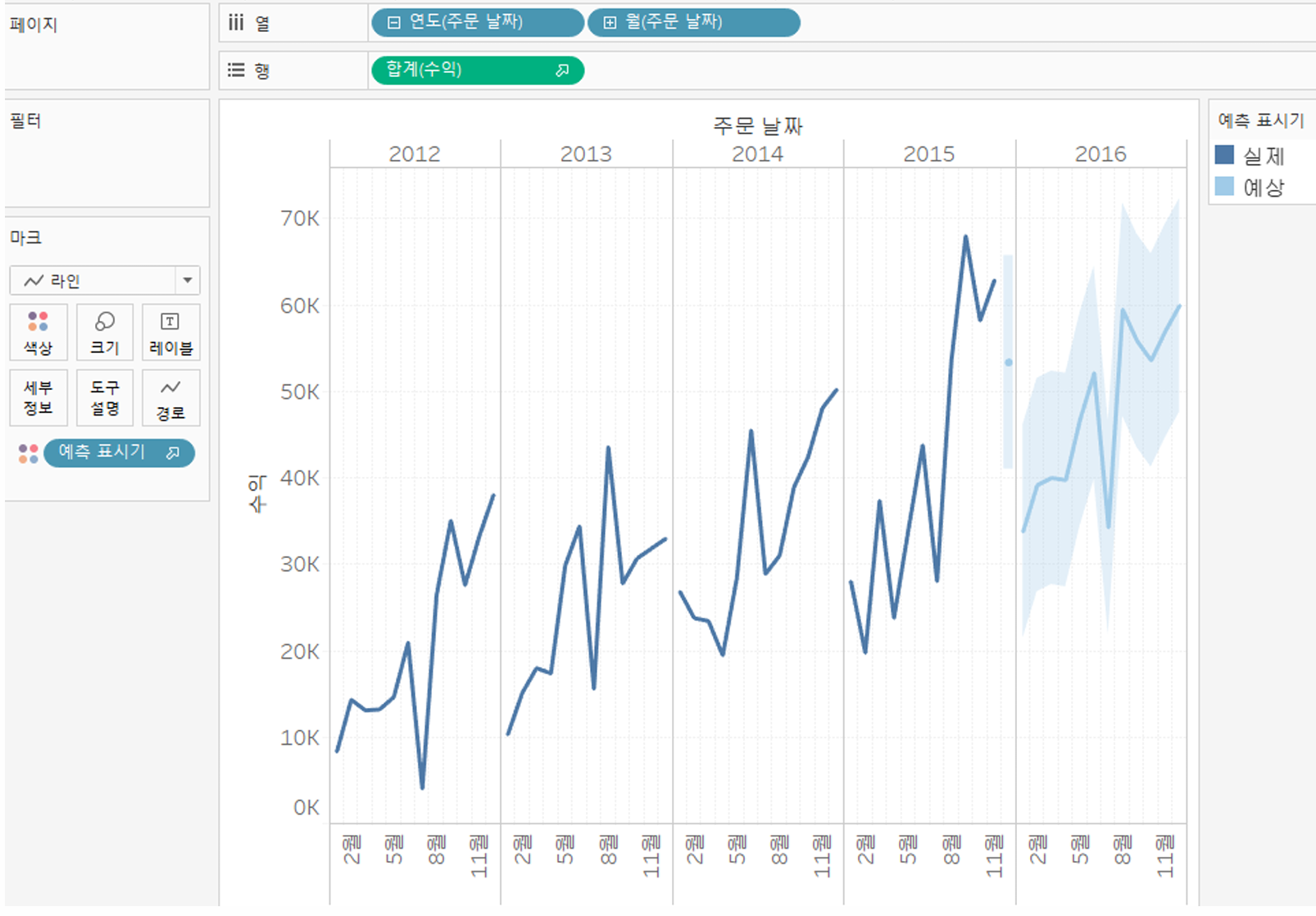
예측 옵션 적용
- 기본값은 자동이나 naive forecasting되면 가장 최근 값으로 예측이 끝날 수있음
- 추세: 시간의 흐름에 따른 수준(관측값의 크기)의 변화
- 계절: 단위 시각내에서 순환 주기의 영향
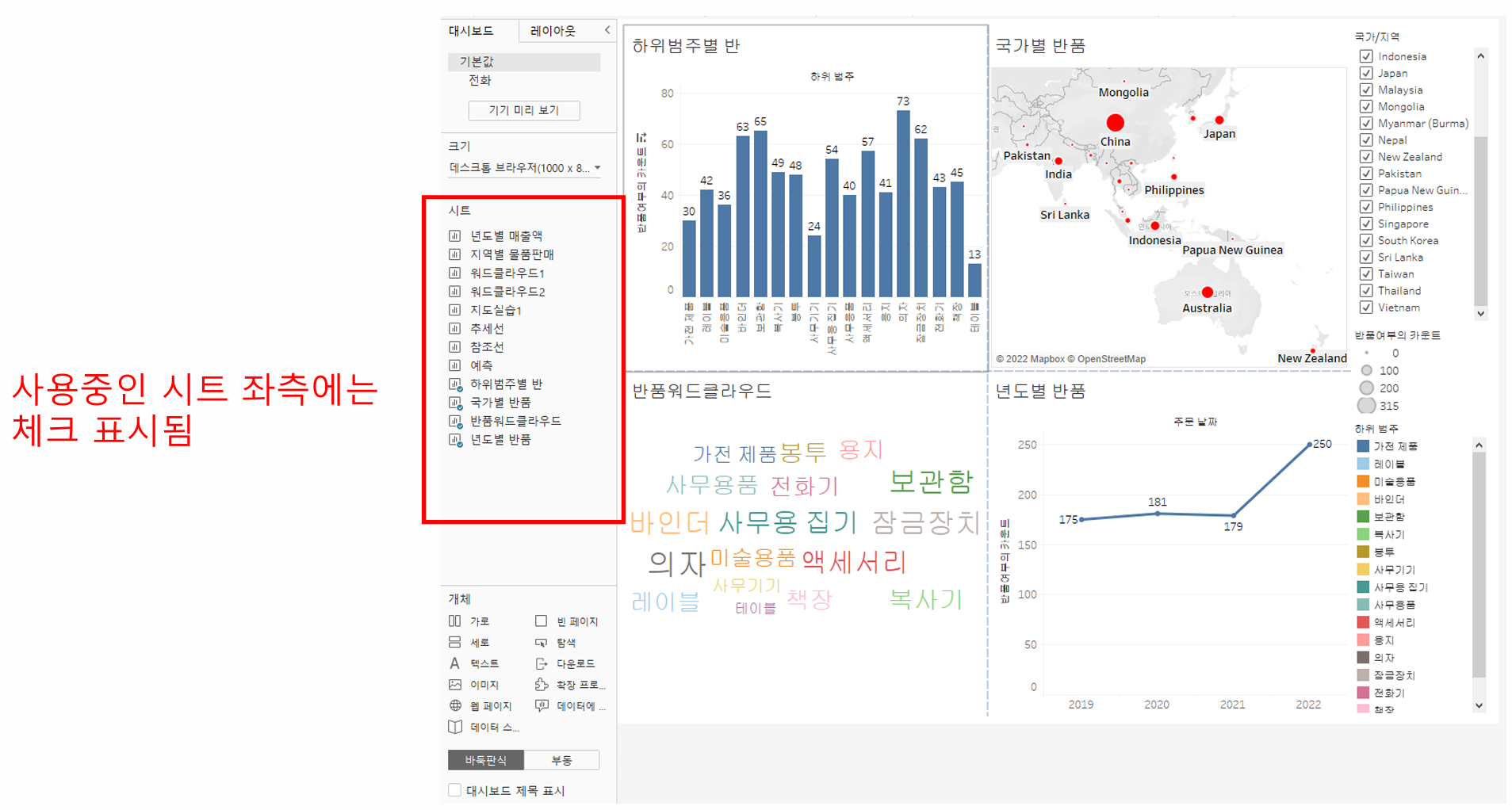
대쉬보드
- 작업한 여러 뷰를 종합적으로 관리하며 분석하고자 할 떄 사용
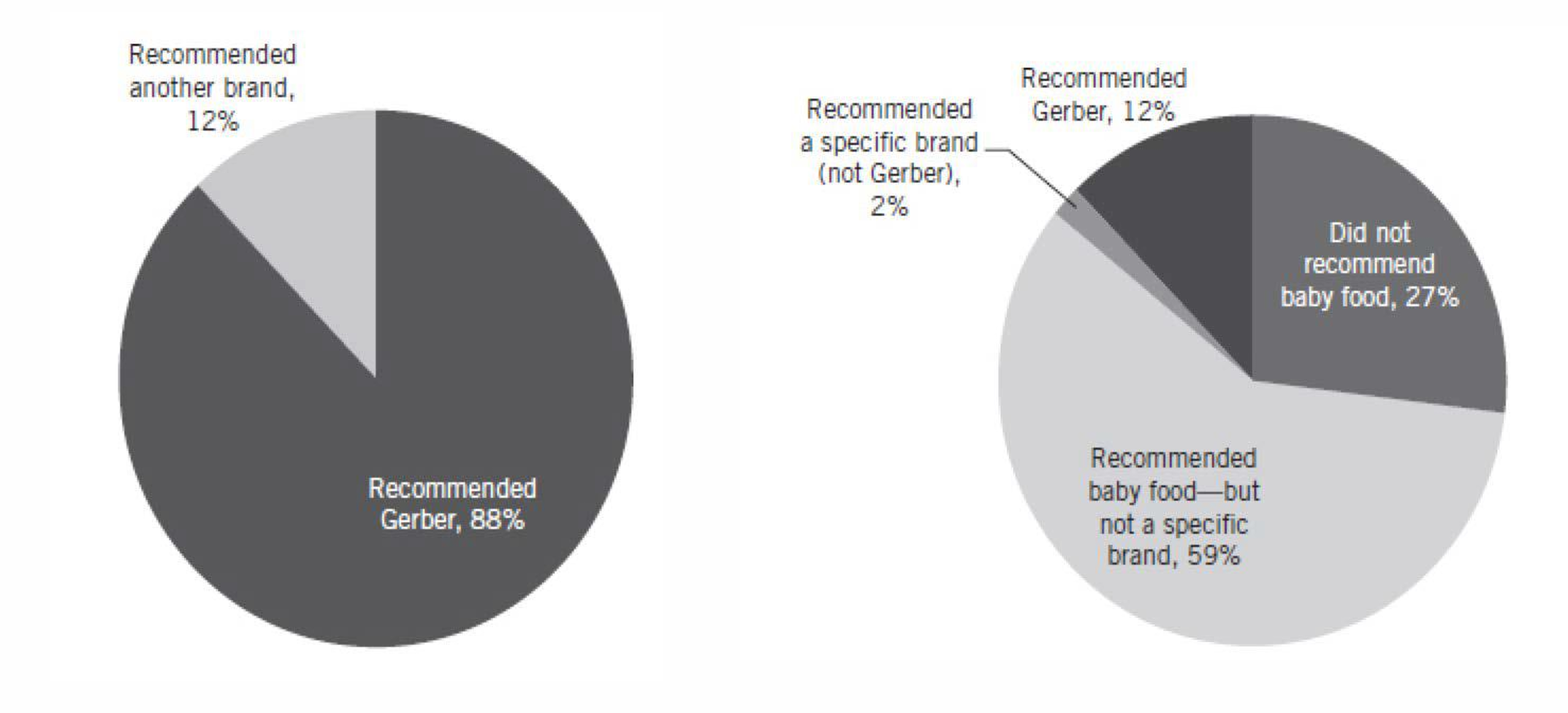
데이터분석의 함정(마지막주)
Gerber의 체리피킹

소아과 의사중 5명중 4명은 Gerber를 추천했어요!
- 불공정 여부 조사
- 562명을 조사. 이중 408명이 이유식을 먹을 것을 추천
- 408명 중 332명이 어떤 특정 브랜드를 명시해 추천하지 않았음
- 76명중 67명이 Gerber를 추천함
결국 562명 중 Gerver를 추천한 사람은 67명
허위 상관관계(Spurious Relationship)
둘 이상의 변수가 통계적으로 상관되어 있지만 인솨관계가 없는 관계
역 인과관계
원인과 결과가 뒤바뀌어, 실제로는 결과가 원인의 원인이 되는 현상
Simson’s Paradox
여러 개의 그룹을 합쳐놓았을 때 각 그룹의 우열관계가 뒤바뀌는 현상


시각화의 함정
시사점
- 시각화수행시간단하고정확하게데이터에대한진실을전달
- 타인의그래프를읽을때에는왜곡이있는지살펴보고데이터와비교를통한검토



글이 안 올라온지 한달이 넘어갑니다 새로운 글 올려주세요