데이터 유형
- 정형
- 비정형
- 반정형
정형데이터
- 정의: 스키마 혹은 일정한 형태로 정의 되어있음. 일반적으로 관계형 데이터 베이스
- 특징
- 쉽게 퀴리
- 행열 형태로 정제
- ex
- 데이터베이스 테이블
- 열이있는 CSV
- 엑셀 스프레드시트
비정형데이터
- 정의: 일정한 구조 혹은 스키마가 없는 데이터
- 특징:
- 쉽게 쿼리하지 못함(사전 준비를 거쳐야한다)
- 다양한 형식으로 존재
- 예시:
- 일정한 형식이 없는 텍스트데이터
- 비디오, 오디오 파일
- 이미지
- 이메일, 문서
반정형 데이터
- 정의: 일정한 형태로 정제 되어있지 않지만 테그 등 일정한 계층 구조를 가지고 있는 데이터
-특징- 테그 혹은 특징이 구분되어있음
- 예시
- XML, JSON 파일
- 이메일 헤더
- 로그파일
빅데이터 3요소
- Volume
- Velocity
- Variety
데이터웨어하우스 VS 데이터 레이크
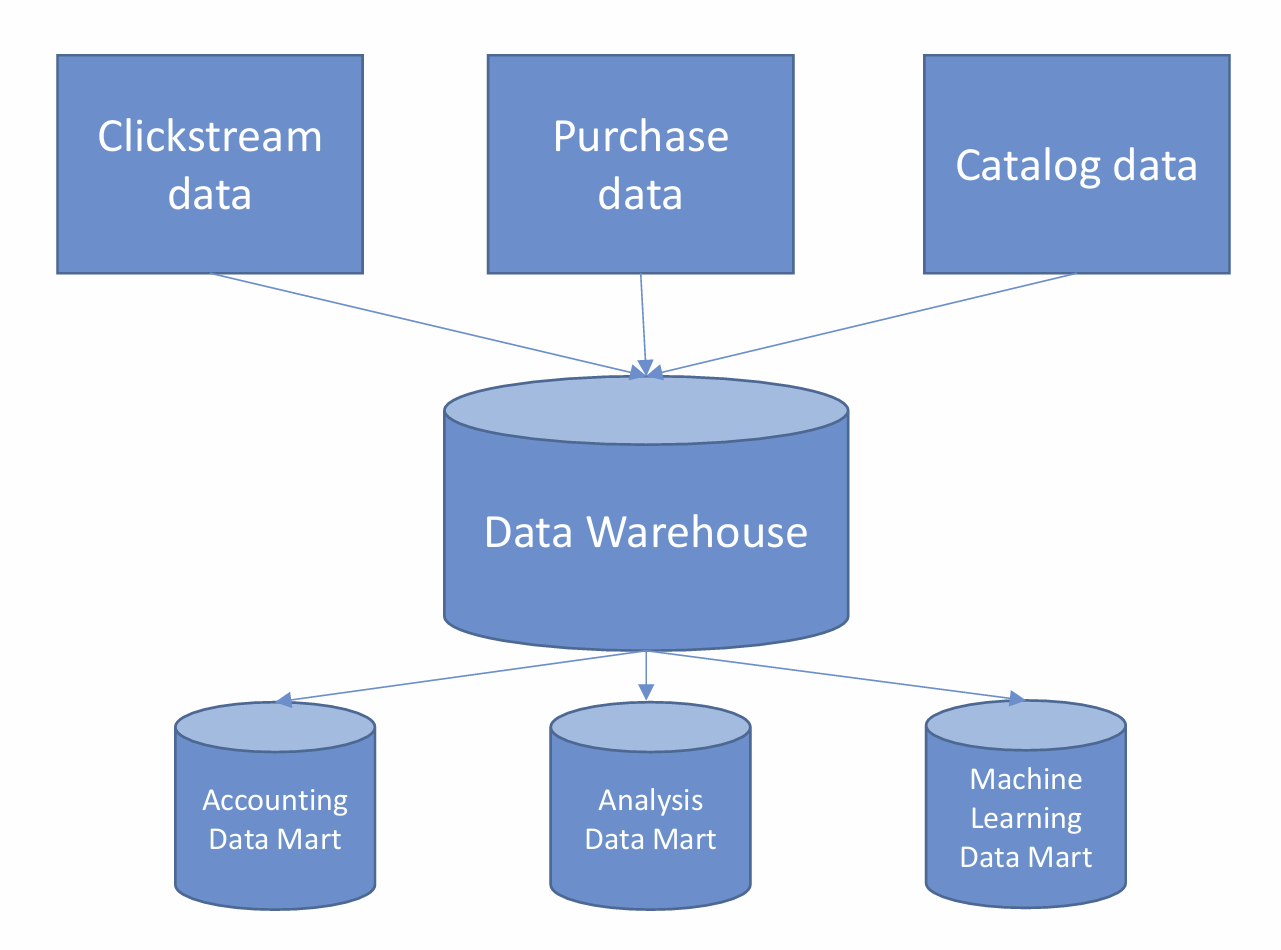
데이터웨어하우스
- 정의 : 정형데이터로 정제된 데이터 분석을 위한 중앙화된 저장소
- 특징:
- 여러 쿼리와 분석을 위함
- 데이터는 정제, 변환, 적제되어야함(ETL)
- 일반적으로 스타스키마, 스노우플레이크 스키마 사용
- 읽기가 많은 작업을 위해 최적화됨
- 예시:
- 아마존 레드쉬프트
- 구글 빅쿼리
- 애져 SQL 데이터웨어 하우스
데이터레이크
- 정의: 여러형태의 방대한 양의 로우데이터 저장소
- 특징
- 사전 정의된 스키마 없이 많은양의 로우데이터 저장 가능
- 사전 준비 필요X
- 배치, 실시간 처리 가능
- 데이터 변환, 탐색을 위해 쿼리 가능
- 예시
- 아마존 S3
- 애져 데이터 레이크 스토리지
- 하둡 분산 파일 시스템
레이크 웨어하우스 비교
- 스키마
- 데이터 웨어 하우스: Schema-on-write(쓰기전 사전 정의된 스키마)
- Extract - TransForm -Load(ETL)
- 데이터 레이크: Schema-on-read(읽을 떄 스키마 정의됨)
- Extract- Load- Transform(ELT)
- 데이터 웨어 하우스: Schema-on-write(쓰기전 사전 정의된 스키마)
- 데이터 형식
- 데이터 웨어하우스: 주로 정형데이터
- 데이터 레이크: 비정형, 정형 데이터 모두
- 속도
- 데이터 웨어하우스: 사전 스키마 떄문에 느림
- 데이터 레이크: 스키마 준비 없이 바로 로우 데이터 적재 덕분에 빠름
- 비용
- 데이터 웨어하우스: 복잡한 쿼리를 위해 최적화 되어 비쌈
- 데이터 레이크: 저장엔 저렴하나 데이터양이 증가함에 따라 비싸짐
웨어하우스 레이크 선택
- 데이터 웨어하우스 사용
- 빠르고 복잡한 쿼리문을 사용해야하고, 정형데이터를 가지고 있을떄
- 여러 데이터 원천으로 부터 데이터 통합이 팔요할떄
- 비지니스 분석을 위할떄
- 데이터 레이크 사용
- 여러 형태의 데이터를 가지고 있을떄
- 많은 양의 데이터와 싸게 하기 위해
- 미래 어떻게 데이터를 사용하기 모르기에 일단 저장하기 위함
- 머신러닝, 데이터 탐색, 어려운 분석을 위함
- 조직은 두가지 모두 사용한다. 로데이터는 레이크에 저장, 분석을 할떄 변환해 웨어하우스에 저장
데이터 레이크 하우스
- 정의: 위 두가지 형태가 합쳐저 높은 성능, 안전성, 많은 데이터 저장, 비용효율성을 가짐
- 특징
- 비정형, 정형 모두 데이터 처리
- Schema on write, shema on read 모두 허용
- 고급 분석과 머신러닝 작업을 위한 성능을 가짐
- 클라우드의 맨 위, 분선처리 환경 위에 있음
- 빅데이터에 ACID를 적용함
- 예시
- AWS LAKE Formation
- Delta Lake
- Databricks Lakehouse Platform
- Azure Synapse Analytics
데이터 매쉬 Data Mesh
- 조직, 거버넌스 관점에서 발생
- 각기 팀이 도메인에 해당하는 데이터를 가짐
- 조직 전체의 유즈케이스를 가져다줌
- 도메인 중심의 데이터 관리
- 전체적인 기준만 가지고 각기 팀이 해당하는 데이터 보유
ETL Pipelines
- Extract, Transform, Load
- 다른 원천에서 데이터웨어하우스에 데이터를 옮기는 것
Extract
- 원천 시스템에서 로우 데이터를 가져오는거 데이터베이스, crm, 파일, api를 통해 가져옴
- 데이터 무결성 중요
- 배치처리, 혹은 실시간처리
Transform
- 데이터웨어하우스 적재를 위해 일정한 형태로 변환
- 아래 작업과 연관
- 데이터 클랜징(중복제거, 에러 수정)
- Data enrichment(다른 원천으로부터 데이터 추가)
- 형태 변환(날짜 변환, 문자열 조작)
- 총계처리
- 인코딩 디코딩
- 결측값 처리
Load 적재
- 변환된 데이터를 데이터웨어하우스 혹은 다른 데이터 저장소에 적재
ETL Pipeline 관리
- 신뢰할 수 있게 자동화 되어야함
- AWS Glue
- Orchestration services
- EventBridge
- Amazon Managed Workflows for apache Airflow(MWAA)
- AWS step functions
- Lambda
- Glue Workflows
데이터 원천 Data soruces
- JDBC
- ODBC
- Raw logs
- API
- Streams

공학자