AI studio(구 rapid miner)를 통해 데이터 전처리 실습을 해보자
Sampling
AI studio에서 제공하는 주요 샘플링 operator
- Sample, Sample(stratified), Sample(Boot_strapping)
- SMOTE Upsampling
- Sample : 단순임의추출
- absolute : 표분 수 지정
- relative : 비율지정
- probability : 각 데이터 포인트(사례)별로 추출될 확률을 지정
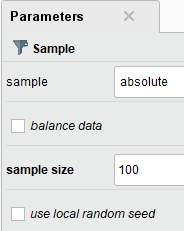
balance data 설정 : 각 클래스별 추출 수 / 비율 설정
- Sample (stratified) : 층화추출
- 층화추출 : 모집단을 동질적인 특성을 가진 여러 개의 '층(strata)'으로 나눈 후, 각 층에서 독립적으로 표본을 추출하는 통계학적 표본 추출 방법
- Sample(Boot-strapping):복원 추출
- SMOTE Upsampling
- 적은 수의 클래스만 Sample(Bootstrapping)해서 클래스 분포
를 균등하게 맞춰 줌
데이터 분할
Split Data operator 사용
partitions
몇개로 분할할지, 각 크기(0 ~ 1) 지정
Sampling type
- Liner sampling: 순서대로 분할
- Shuffled sampling: 임의로 섞어서 분할
- Stratified sampling: 클래스의 분포를 보고,
각 subset에 클래스가 유사한 분포로 구성되도록 분할
데이터 탐색
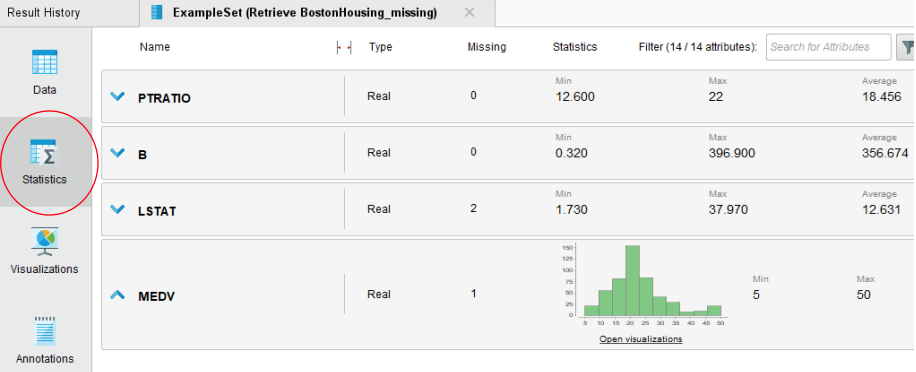
RapidMiner를 활용한 기술통계량
stistics
• 평균, Min(Least)/Max(Most), deviation(numeric일 때) 확인
• 각 속성(attribute)별 Missing 확인
• 속성 click시 chart 보임
• Chart 클릭 – open chart시, “Chart”로 연결됨.
Charts
- 다양한 Chart들로 표시 가능 (Bar chart, Pie chart,
Histogram/Histogram(color), Distribution, Scatter diagram,
Box plot/Box plot(color) - Histogram등 chart종류에 따라서 편집 가능
예) Histogram은 Ctrl키로 여러 attribute를 한꺼번에 그래프로 표현, bin크기
조절 등 가능 - 상관관계 분석을 위해서는 scatter diagram확인
예) 집값 vs 방의 개수, 집값 vs 범죄율 등
Histogram vs Histogram (color)
- 좀 더 깊이 있는 인사이트를 얻기 위해서는 다른 클래스들을 포
함시켜 히스토그램을 수정 - Histogram(color): color – 분류의 문제일 경우 클래스명
산점도(Scatter/Scatter Multiple/Scatter Matrix chart)
- 데이터 포인트들을 데카르트 좌표 공간에 표시하여, 변수들 간
상관관계를 파악하는데 유용하게 사용되는 차트 - 일반적으로 변수들은 연속형
- 산점도로부터 알 수 있는 중요 정보
1. 두 변수들 사이의 상관관계 존재 여부
2. 변수 사이에 상관관계가 있다면 직선에 가깝게 모여 있게 되며, 상관
관계가 없다면 데이터 포인트들은 흩어짐
3. 주 변수를 x축에 표시, y축은 나머지 변수들끼리 공유
데이터 변환(Modification)
결측치 처리, 속성변경, 정규화
결측치(Missing Value) 처리 방법
1. 결측치 제거
- 데이터 셋이 크고, 결측치가 많지 않을 때
- 특정한 행 또는 열에 결측치가 집중적으로 몰려있을 때, 해당 행 또는 열을 제거
2. 결측치 대체 (Replace Missing Values 오퍼레이터)
- 결측치가 다양한 행 또는 열에 흩어져 있어, 제거 시 데이터 셋이 너무
작아질 때 - 데이터 셋 규모가 작아서 최대한 데이터를 보존해야 할 때
- 최소값, 최댓값, 평균, 0, 사용자 지정값 등으로 대체 가능
언제 어떤 방식의 결측치 처리가 좋을까
데이터 셋 크기가 500개이고, attribute7에 260개의 결측치가
집중되어 있을 때
-> attribute7을 제거하는 것이 좋음
데이터 셋 크기가 500개이고, 20개의 attributes에 각 10개씩
의 결측치가 있을 때
-> 수치형일 경우 평균, 명목형일 경우 최빈값 등으로 대체 가능
종속변수에 결측치가 있을 때
-> 종속변수에 결측치가 있는 데이터들을 제거하는 것이 좋음
속성(데이터 타입) 변경
Raw data(원시데이타)에 특정 알고리즘을 적용하기 위해 데이터 type
변환이 필요한 경우가 있음. (예) 회귀분석
명목형을 수치형으로 (One-Hot Encoding)
회귀분석 등 명목형 변수 처리 못하는 머신러닝 기법 위해 더미변수
형태로 변환
ex. 회귀분석, 군집분석 시 필요
수치형에서 이진형으로(numerical to binominal)
기본은 true이고, flase로 처리될 구간의 min값/max값 지정 가능. 연관성
분석 또는 회귀의 문제를 분류의 문제로 변환하고자 할 때 등 사용
ex. 연관성 분석 시 필요
정규화(Normalizing Data)
-속성별 측정방식 또는 단위의 차이로 인해, 속성이 모형에 미치는 영향에
차이가 생길 수 있음. (단위 효과, effect of unit)
ex. 연령, 연봉, 자녀 수
- 단위 효과의 제거가 필요함.
- 일부 머신러닝 모형은 RapidMiner에서 단위효과를 자동으로 고려하여 분
석을 수행하거나, 단위효과에 영향을 받지 않는 머신러닝 기법도 존재.
RapidMiner Operator
Parameter – Method
- Z-transformation: 각 속성들의 평균 0, 표준편차 1이 되도록 변환
- Range transformation: 각 속성들의 데이터 값이 Min~Max 사이가
되도록 변환
