관련 기술
- 통계학(Statistics)
- 기계학습(Machine learning)
- 데이터베이스(Database)
- 데이터 웨어하우징(Data Warehousing)
- On-line Analytical Processing(OLAP)
비지니스 데이터 분석 과업
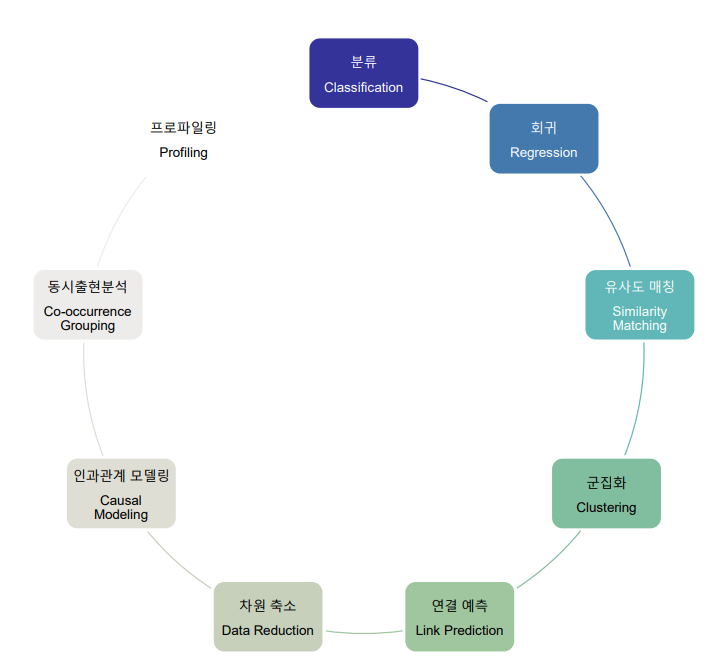
분류(Classfication)
정의 : 범주화 된 데이터를 예측하는 문제
예 : 신용 양호/불량, 성적 예측
회귀(Regression)
- 정의 : 연속형의 수치형 데이터를 예측하는 문제
- 예 : 내일의 주식 종가 예측, 혈압 예측
- 방법론 : 회귀 분석
군집화(Clustering)
- 정의 : 데이터 속성의 유사성을 가지고 그룹핑하고 군집 간 상이성 분석
연결 예측(Link Prediction)
- 예 : SNS 친구 추천
차원 축소
- 예 : 유사도 매칭같은 방법을 이용해 속성의 수를 줄이는 경우
인과관계 모델링
- 결과에 해당하는 원인을 찾는 분석
- 예 : 주가 예측 이유
동시출현분석
- 하나의 사건이 일어날 때 다른 사건이 일어날 확률 분석
- 장바구니 분석 등
프로파일링
- 데이터의 대표적인 특성을 기술하는 방법
데이터 분석 프로세스(SEMMA)
- 표본 추출(Sampling)
- 데이터 탐색(Exploration)
- 데이터 변환(Modification) 및 변수선정
- 데이터 모델링(Modeling)
- 모형 평가(Assessment)
표본추출
- 모집단(Population)으로 부터 표본(Sample)을 반드는 과정
- 데이터 셋의 규모가 커질 수록 계산 비용 및 학습시간 증가
- 이를 줄이기 위해 샘플링 수행
- 샘플의 최소치 : Delmaster and Hancock의 연구의 따르면 최소 6 클래수 수 속성수
ex)클래스 수 2, 속성 10개일 경우 최소 120개의 샘플 데이터 필요 - 통계의 Sampling이 모집단의 분포와 유사한 것을 추구하는 것과 달리, 머신러닝은 모델 수립에 최적화된 Sampling 수행 필요(분류 문제에서 불균형 데이터 셋일 경우 샘플링 주의)
- 학습 데이터 : 평가데이터 비율은 7:3, 6:4 가 일반적
모형 구축용 표본
- 학습데이터 표본
모형 평가용 표본
- 평가 데이터 표본
- 검증 데이터 표본
불균형 데이터셋 해소 방안
- 데이터 모델을 구축하는데 특정 클래스 데이터가 극히 적은 경우, 이러한 데이터를 사용하여 분류 모델을 구축 시, 그 모델은 편향 적일 수있고, 극히 적은 클래스는 예측을 하지 못함
ex) 카드 사기의 데이터는 극히 적으므로, 사기 예측을 잘 못할 수 있음.
높은 빈도의 클래스는 낮은 비중으로 샘플링(Under-sampling)
낮은 빈도의 클래스는 높은 비중으로 샘플링(Over-sampling/Up-Sampling)
데이터 탐색
박스플롯, 히스토그램 등을 이용
데이터 변환
속성별로 최댓값, 최솟값 차이가 클때(스케일링)이 예측/분류에 큰 영향을 미칠 수 있으므로 표준화(정규화)를 적용
데이터 모델링
학습용 데이터에서 유의미한 데이터 추출(Data mining)과정을 거쳐 모형을 만든다. 이후 평가 데이터를 이용함
모형 평가
분류 정확도 평가
- 분류 결과의 정확성을 평가해 최적의 분류 모형을 선택하는 방법
| 구분 | 모형 예측 0 | 모형 예측 1 |
|---|---|---|
| 실제 0 | A | B |
| 실제 1 | C | D |
| 용어 | 정의 |
|---|---|
| 정분류율(Accuracy) | [(실제0,예측0)의빈도+(실제1.예측1)의빈도] /전체빈도=(A+D)/(A+B+C+D) |
| 오분류율(Error Rate) | [(실제0,예측1)의빈도+(실제1.예측0)의빈도] /전체빈도=(B+C)/(A+B+C+D) |
| 민감도(Sensitivity) | (실제1,예측1)인관찰치의빈도/실제1인관찰치의빈도=P(예측1 |
| 특이도(Specificity) | (실제0,예측0)인관찰치의빈도/실제0인관찰치의빈도=P(예측0 |

공학자

덕분에 3분만에 비즈니스 인텔리전스를 마스터했어요. 홍준표님 친절한 설명 아주 감사드립니다. 매일매일 글 올려주세요. 안그럼 쫓아갈겁니다.