알고리즘
서로소 집합
서로소 또는 상호배타 집합은 서로 중복 포함된 원소가 없는 집합들입니다. 즉, 교집합이 없는 집합들을 의미합니다.
이런 서로소 집합들은 해당 집합에 속한 하나의 특정 멤버를 통해서 각 집합들을 구분합니다. 그때, 특정 멤버를 대표자(representative)라고합니다.
서로소 집합의 표현
서로소 집합은 링크드 리스트와 트리로 표현할 수 있습니다.
- 링크드 리스트
같은 집합의 원소들은 하나의 링크드 리스트로 관리합니다. 이때 해당 집합의 대표 원소는 링크드 리스트의 가장 맨 앞의 원소입니다. 링크드 리스트의 각 원소들은 링크드 리스트를 위한 링크 이외에도 해당 집합의 대표 원소를 가리키는 링크를 갖습니다.
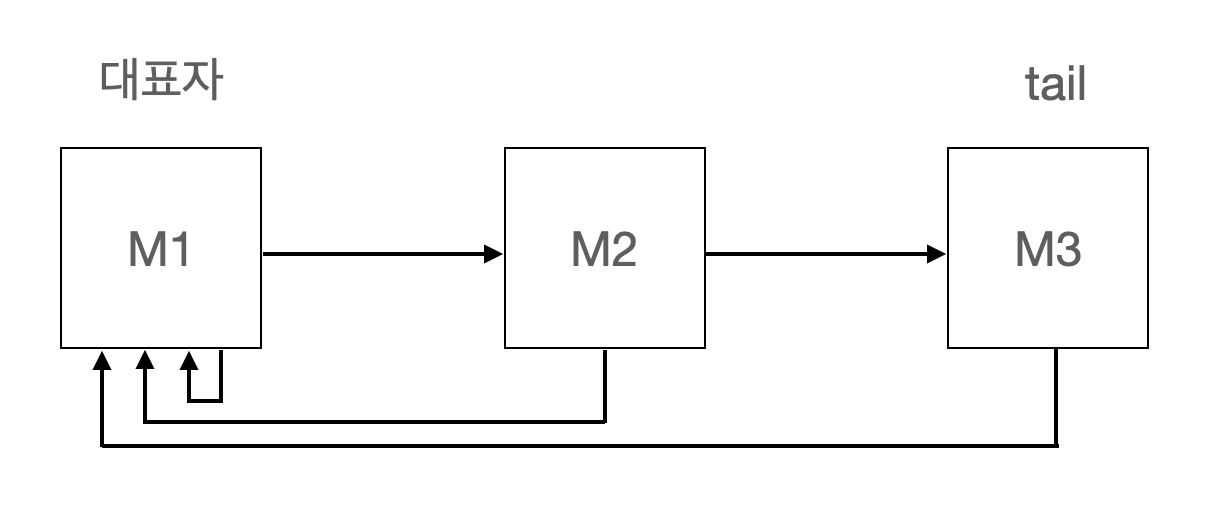
- 트리
트리는 하나의 트리로 표현합니다. 자식 노드가 부모 노드를 가리키며 루트 노드가 대표자가 됩니다.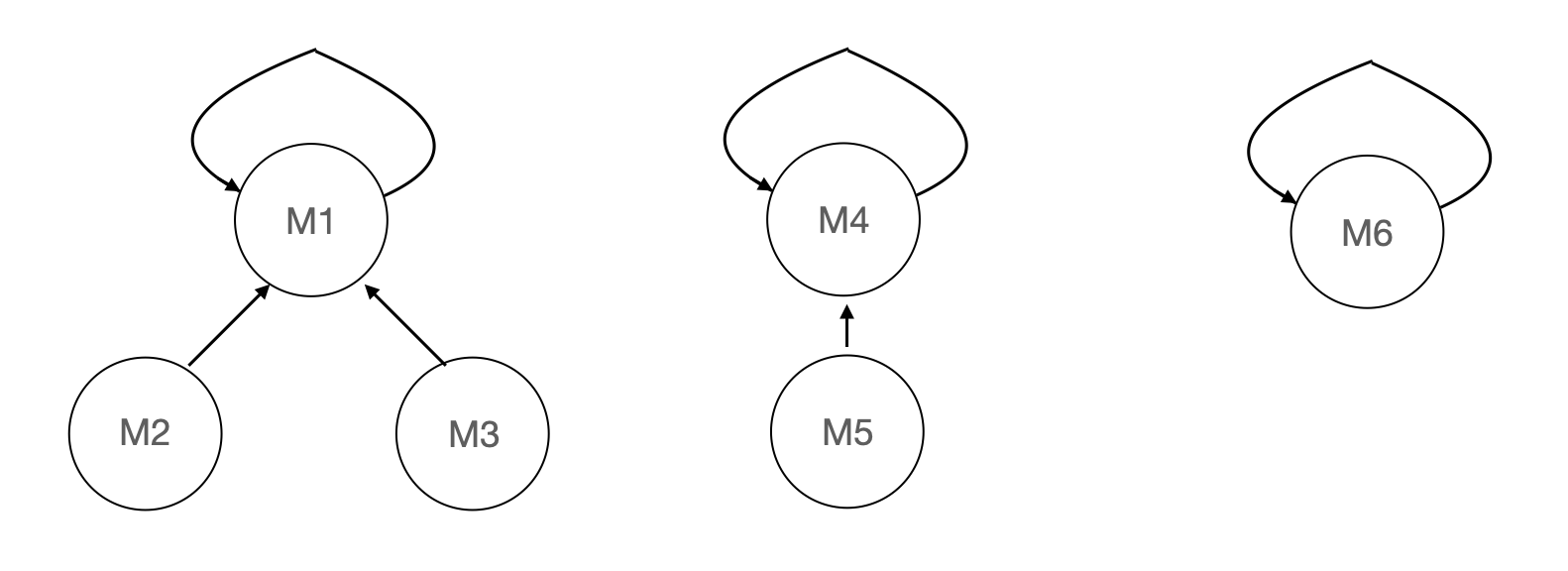
서로소 집합의 연산
- Make-Set(x)
유일한 멤버 X를 포함하는 새로운 집합을 생성하는 연산입니다. - Find-Set(x)
x를 포함하는 집합을 찾는 연산입니다. - Union(x,y)
x와 y를 호팜하는 두 집합을 통합하는 연산입니다. 링크드 리스트인 경우는 아래와 같이 표현됩니다.
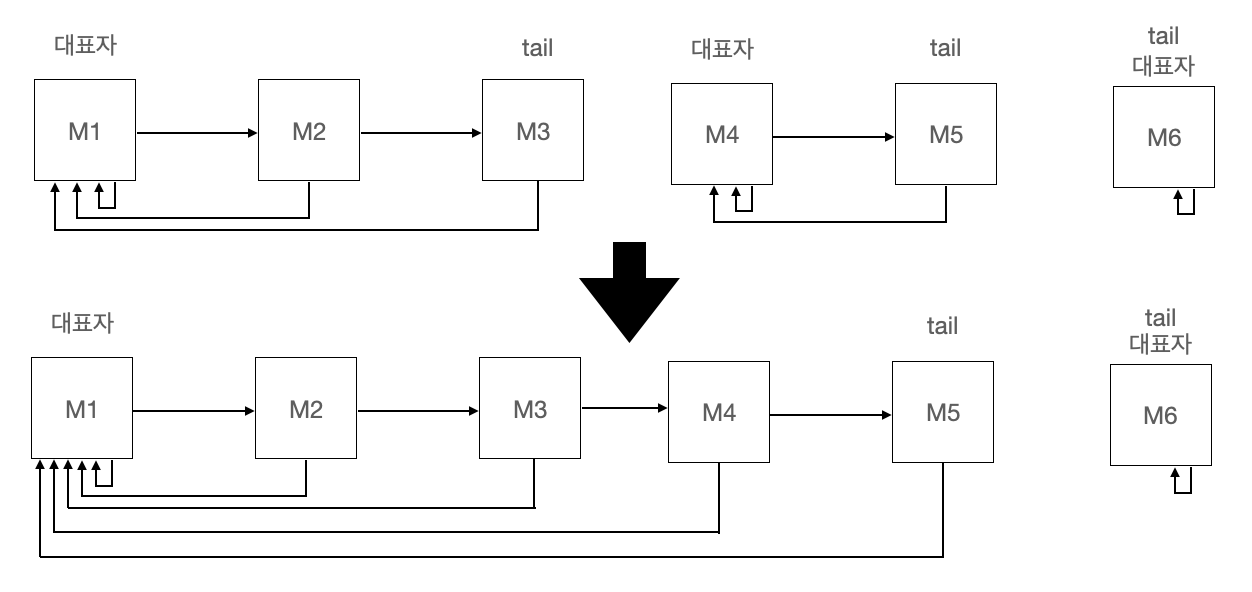
서로소 집합의 구현
public class NaiveDisjointSet{
int[] parent;
NaiveDisjointSet(int n){
parent = new int[n];
for(int i = 0;i<n;i++){
parent[i] = i;
}
}
//u가 속한 트리의 루트 번호를 반환한다.
int find(int u){
if(u == parent[u]) return u;
//return find(parent[u]); --- 기울어진 트리의 경우 비효율적
//최적화(Path Compression)
return parents[a] = find(parents[a]);
}
//u가 속한 트리와 v가 속한 트리를 합친다..
void merge(int u, int v){
u = find(u);
v = find(v);
//u와 v가 이미 같은 트리에 속하는 경우는 걸러낸다.
if(u ==v) return ;
parent[u] = v;
}
}서로소 집합의 단점
트리를 사용하면 Union 연산을 하는 경우에는 효율적입니다. 하지만, 연산 순서에 따라 한쪽으로 기울어진 트리가 만들어질 수 있습니다.
트리로 표현한 경우에 트리가 한쪽으로 기울어진 트리면 Find-Set(x)를 하는 경우 x의 level이 높은 경우 루트 노드를 찾아갈 때까지 연산이 많다는 단점이 있습니다.
단점의 해결책
이런 단점을 해결하기 위한 방법은 2가지가 있습니다.
1. Rank를 이용한 Union
각 노드는 자신을 루트로 하는 subtree의 높이를 rank라는 이름으로 저장합니다.
각 노드들이 rank를 저장하고 있기 때문에, Union 연산을 할 때, rank가 낮은 집합을 rank가 높은 집합에 붙여줍니다.
이 경우에 트리의 높이는 합쳐진 두 트리의 높이가 같을 대만 증가하기 때문에, Union, Find 연산의 시간복잡도를 O(N)에서 O(logN)까지 줄일 수 있습니다.
2. Path compression
Find 연산을 재귀적으로 실행할 때, 한 번 찾은 부모의 값을 계속 갱신해놓는 방식으로 다음에 같은 노드의 부모를 찾아야하는 경우 바로 찾을 수 있게해줍니다. 찾기 연산이 중복된 계산을 여러 번 하고있기 때문에 가능한 방식입니다.
서로소 집합의 활용
대부분의 경우 서로소 집합 대신 그래프나 다른 자료구조로 활용이 가능합니다. 하지만 서로소 집합의 구현이 매우 간단하고 동작 속도가 아주 빠르기 대문에, 다른 알고리즘의 일부로 사용되는 경우가 많습니다.
그래프의 연결성을 확인하는 문제나, 가장 큰 집합을 찾는 경우에 많이 사용됩니다. 특히, 그래프의 연결성은 크루스칼의 최소 스패닝 트리 알고리즘을 구현할 때, 서로소 집합을 이용하는 것이 대표적입니다.
