
알고리즘
오늘 다룰 크루스칼, 프림, 타익스트라 알고리즘은 대표적인 그리디(greedy)문제입니다.
그래프에서의 최소 비용 문제
- 모든 정점을 연결하는 간선들의 가중치의 합이 최소가 되는 트리 찾기
- 두 정점 사이의 최소 비용의 경로 찾기
최소 스패닝 트리(MST)
최소 스패닝 트리는 그래프에서 만날 수 있는 최소 비용 문제 중 모든 정점을 연결하는 간선들의 가중치의 합이 최소가 되는 트리를 의미합니다.
그렇다면 스패닝 트리는 무엇일까요??
스패닝 트리
n개의 정점으로 이루어진 무향 그래프에서 n개의 정점과 n-1개의 간선으로 이루어진 트리를 신장트리라 합니다. 다른 말로, 원래 그래프의 정점 전부와 간선의 부분 집합으로 구성된 부분 그래프 입니다. 이 때, 스패닝 트리에 포함된 간선들은 정점들을 트리 형태로 전부 연결해야 합니다.
이런 특징들로부터 우리는 스패닝 트리가 유일하지 않고 여러개가 존재합니다.
가중치 그래프의 여러 개의 스패닝 트리 중 가중치의 합이 가장 작은 트리를 찾는 문제입니다.
크루스칼
크루스칼의 알고리즘은 상호 배타적 집합 자료 구조를 사용하는 좋은 예입니다.
크루스칼 알고리즘을 접근하기 전에 다음 질문의 답을 생각해보겠습니다.
가중치가 가장 작은 간선과 가중치가 가장 큰 간선 중 어느 쪽이 최소 스패닝 트리에 포함될 가능성이 높을까?
대부분 가중치가 가장 작은 간선일 것입니다. 크루스칼의 알고리즘은 여기서 출발합니다.
그래프의 모든 간선을 가중치의 오름차순으로 정렬합니다. 그 후, 스패닝트리에 하나씩 추가합니다. 이때 주의할 점은, 간선들이 사이클을 이루지 않게 해야하는 것입니다. 그렇기 때문에, 가중치가 작다고 무조건 간선을 트리에 더하는 것이 아닌, 결과적으로 사이클이 생기는 간선을 제외한 간선 중 가중치가 가장 작은 간선들을 트리에 추가합니다.
이처럼 크루스칼 알고리즘은 모든 간선을 한 번씩 감사한 뒤 종료합니다.
다음은 크루스칼 알고리즘이 최소 스패닝 트리를 만드는 과정을 표현한 그림입니다.
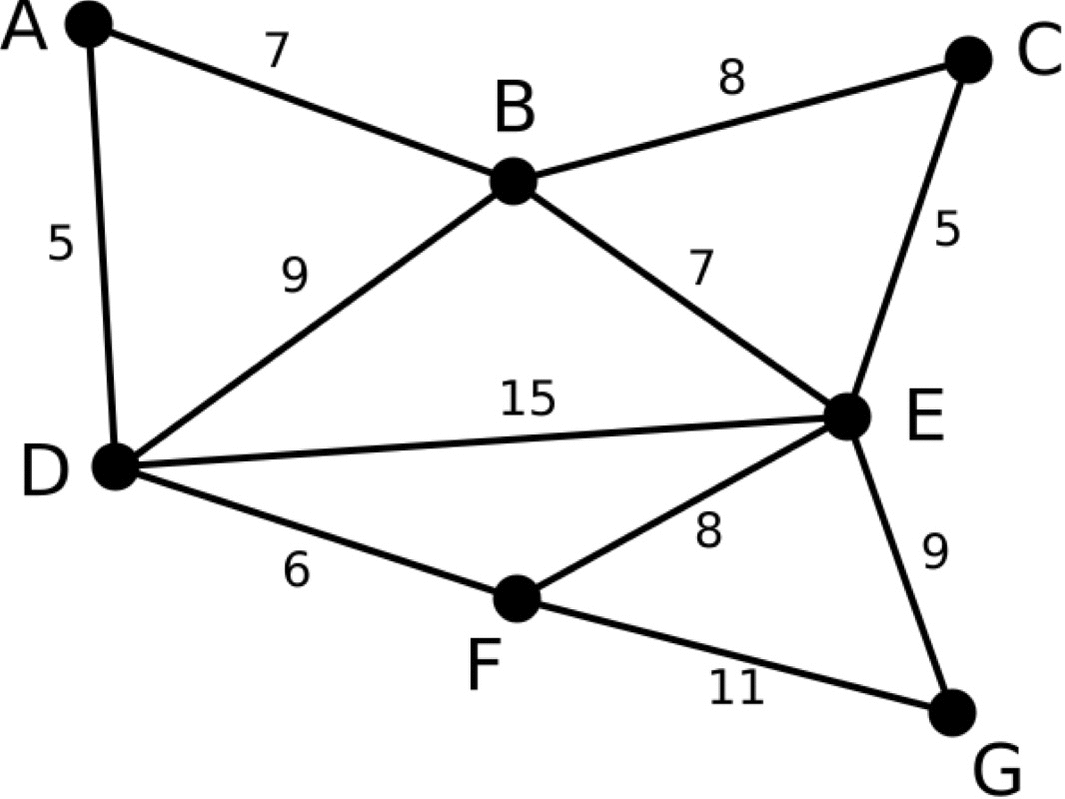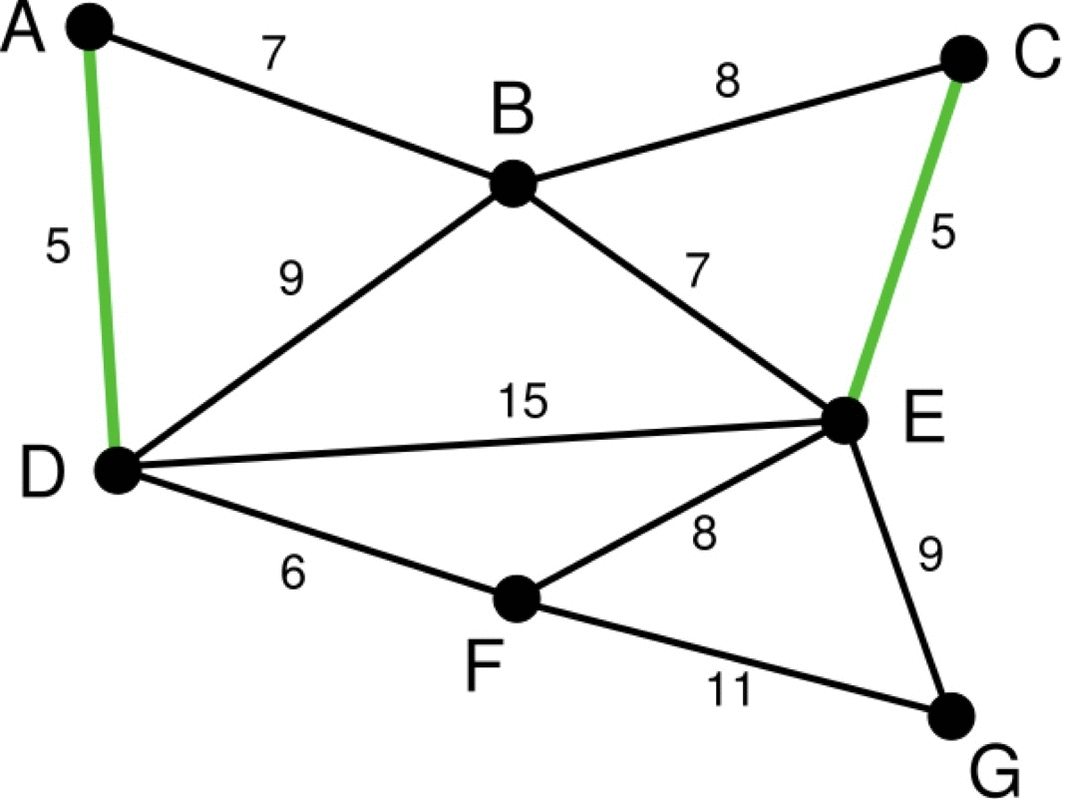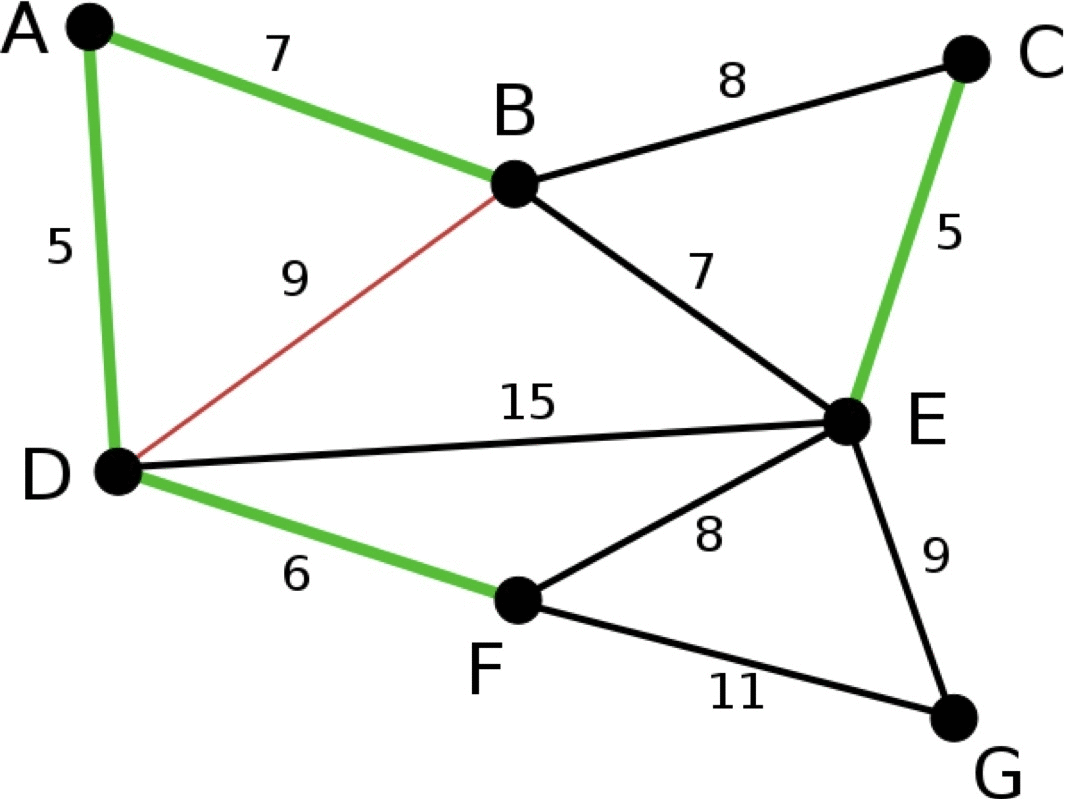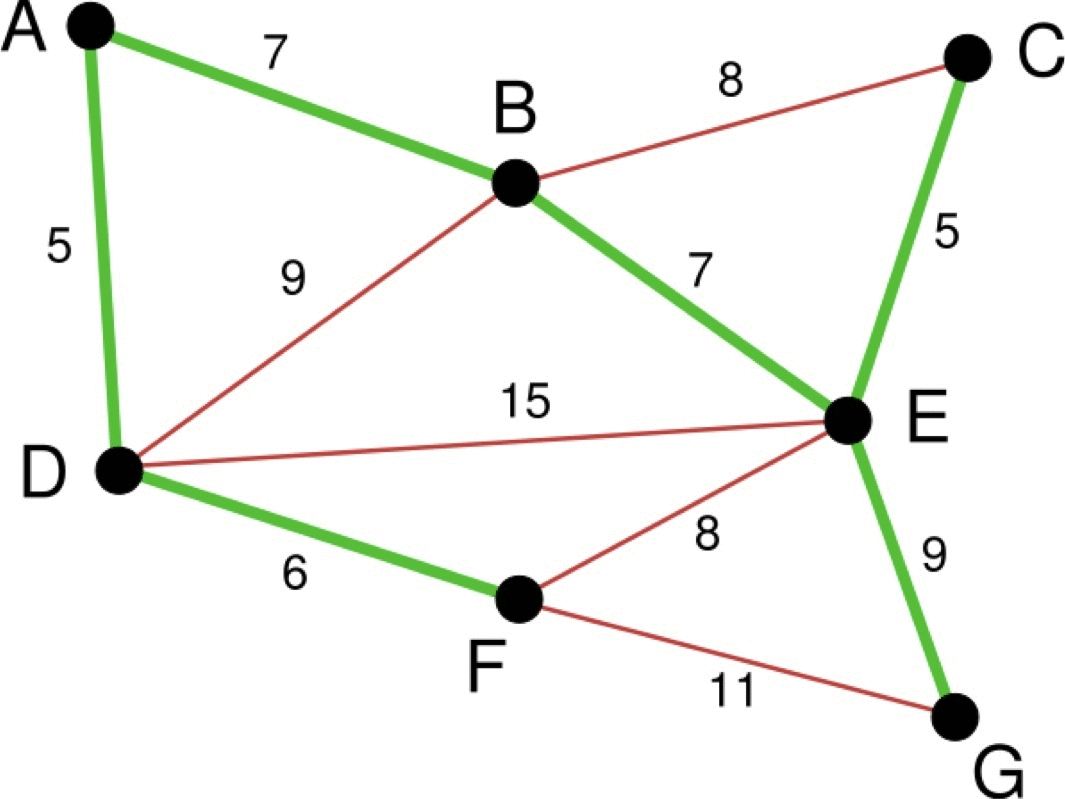
크루스칼 알고리즘의 구현
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.Comparator;
import java.util.StringTokenizer;
public class KuruskalTest {
static class Edge implements Comparable<Edge> {
int start, end, weight;
public Edge(int start,int end, int weight){
this.start = start;
this.end = end;
this.weight = weight;
}
@Override
public int compareTo(Edge o){
return Integer.compare(this.weight,o.weight);
}
}
static int V;
static int E;
static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
static StringTokenizer st;
static Edge[] edgeList;
public static void main(String[] args) throws IOException {
st = new StringTokenizer(br.readLine()," ");
V = Integer.parseInt(st.nextToken());
E = Integer.parseInt(st.nextToken());
edgeList = new Edge[E];
for(int i = 0;i<E;i++){
st = new StringTokenizer(br.readLine()," ");
int start = Integer.parseInt(st.nextToken());
int end = Integer.parseInt(st.nextToken());
int weight = Integer.parseInt(st.nextToken());
edgeList[i] = new Edge(start,end,weight);
}
Arrays.sort(edgeList);//오름차순
make();// 모든 정점을 각각 집합으로 만들고 출발한다.
//간선 하나씩 시도하며 트리를 만든다.
int cnt = 0,result = 0;
for(Edge edge : edgeList){
if(merge(edge.start,edge.end)){
result += edge.weight;
if(++cnt == V-1) break;// 신장트리 완성.
}
}
System.out.println(result);
}
static int[] parents;
static void make(){
parents = new int[V];
for(int i = 0;i<V;i++){
parents[i] = i;
}
}
//u가 속한 트리의 루트 번호를 반환한다.
static int find(int u){
if(u == parents[u]) return u;
//return find(parent[u]); --- 기울어진 트리의 경우 비효율적
//최적화(Path Compression)
return parents[u] = find(parents[u]);
}
//u가 속한 트리와 v가 속한 트리를 합친다..
static boolean merge(int u, int v){
u = find(u);
v = find(v);
//u와 v가 이미 같은 트리에 속하는 경우는 걸러낸다.
if(u ==v) return false;
parents[u] = v;
return true;
}
}
정당성 증명
- 크루스칼 알고리즘이 선택하는 간선 중 그래프의 최소 스패닝 트리 T에 포함되지않는 간선이 있다고 가정
- 이 중 첫번째로 선택되는 간선을 (u,v)라 하자. T는 이 간선을 포함하지않기 때문에, u와 v는 T에서 다른 경로로 연결되어 있을 것이다.
- 이 경로를 이루는 간선 중 하나는 반드시 (u,v)와 가중치가 크거나 같아야한다.(그 이유는 모두 (u,v)보다 가중치가 작다면 크루스칼 알고리즘이 이미 이 간선들을 모두 선택해서 u와 v를 연결했을 것이기 때문에 (u,v)가 선택됐을리 없다.
- 따라서 이 경로 상에서 (u,v) 이상의 가중치를 갖는 간선을 하나 골라서 T에서 지워버리고 (u,v)를 추가해도 스패닝 트리는 유지되면서 가중치의 총합은 줄거나 같을 것입니다.
- 하지만 T가 이미 최소 스패닝 트리라고 가정했기 때문에, (u,v)를 포함하면서 최소 스패닝 트리가 되어야합니다.
- 따라서 (u,v)를 선택한다고 하더라도 남은 간선들을 잘 선택하면 항상 최소 스패닝 트리를 얻을 수 있습니다.
1~6의 성질은 마지막 간선을 추가해 스패닝 트리가 완성될 때까지 성립하기 때문에, 마지막에 얻은 트리는 항상 최소 스패닝 트리가 됩니다.
시간복잡도
DisJointSet에대한 연산은 실질적으로 상수기간이기 때문에,실제 트리를 만드는 for문의 시간복잡도 O(|E|)입니다. 따라서 크루스칼 알고리즘의 전체 시간복잡도는 간선 목록의 정렬에 걸리는 시간 O(|E|log|E|)가 됩니다. 간선 목록의 정렬하는 시간이 알고리즘 전체 시간 중에 지배적으로 크기 때문에, 간선의 수가 많아지면 크루스칼 알고리즘은 효율이 떨어집니다.
프림
프림의 알고리즘은 다익스트라 알고리즘과 거의 같은 형태를 띠고 있습니다.
크루스칼 알고리즘이 여기저기서 산발적으로 만들어진 트리의 조각들을 합쳐서 스패닝 트리를 만든다면, 프림 알고리즘은 하나의 시작점으로 구성된 트리에 간선을 하나씩 추가하는 방식으로 진행됩니다. 그렇기 때문에, 항상 선택된 간선들은 중간 과정에서도 연결된 트리를 만듭니다.
프림 알고리즘은 선택할 수 있는 간선들 중 가중치가 가장 작은 간선을 선택하는 과정을 반복합니다.
아래는 프림 알고리즘을 이용해서 최소 스패닝 트리를 만드는 과정을 표현한 그림입니다.
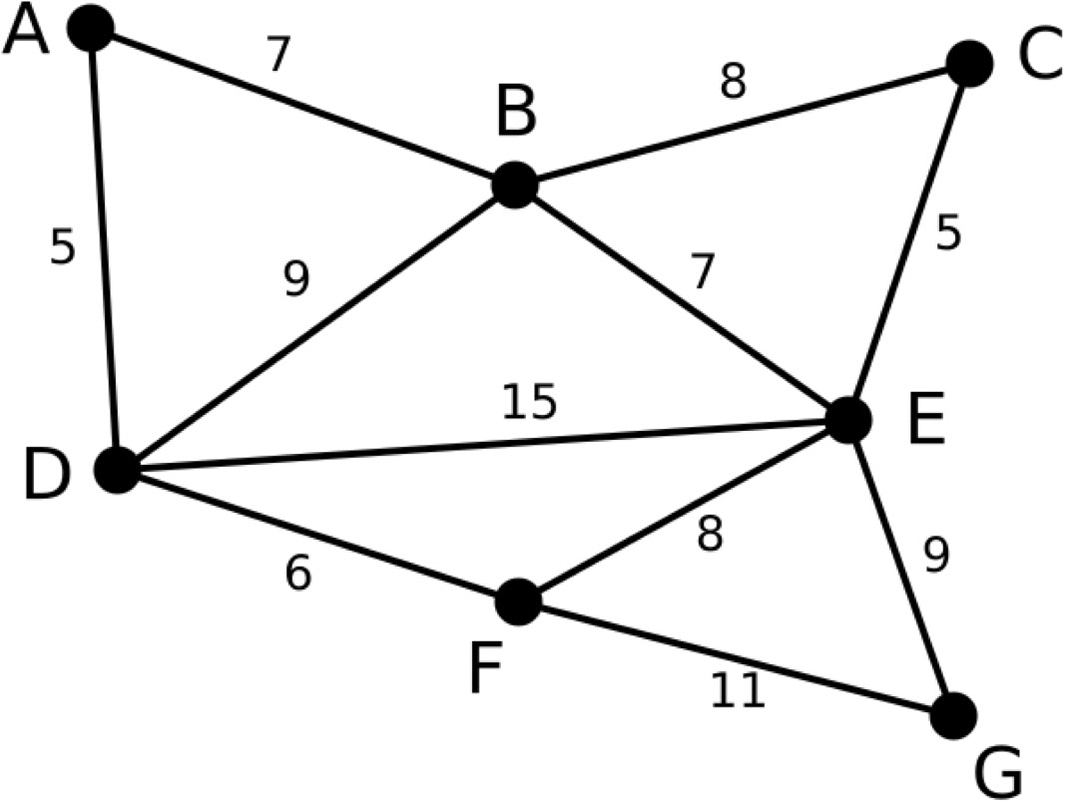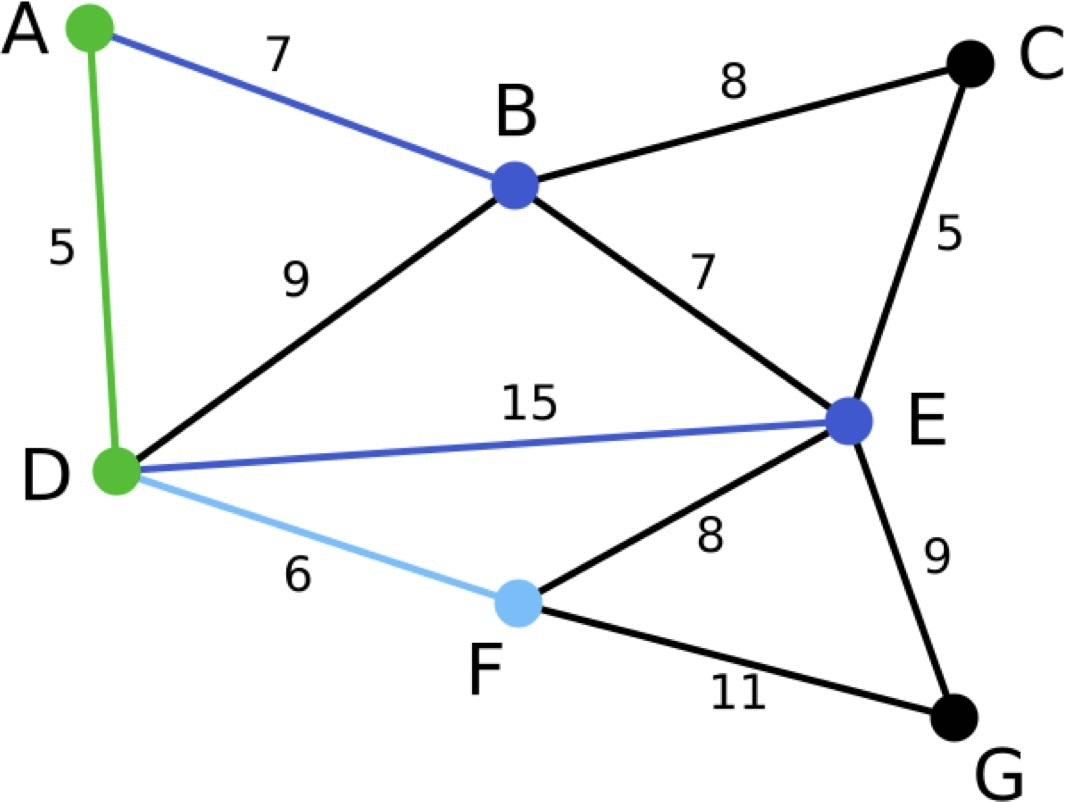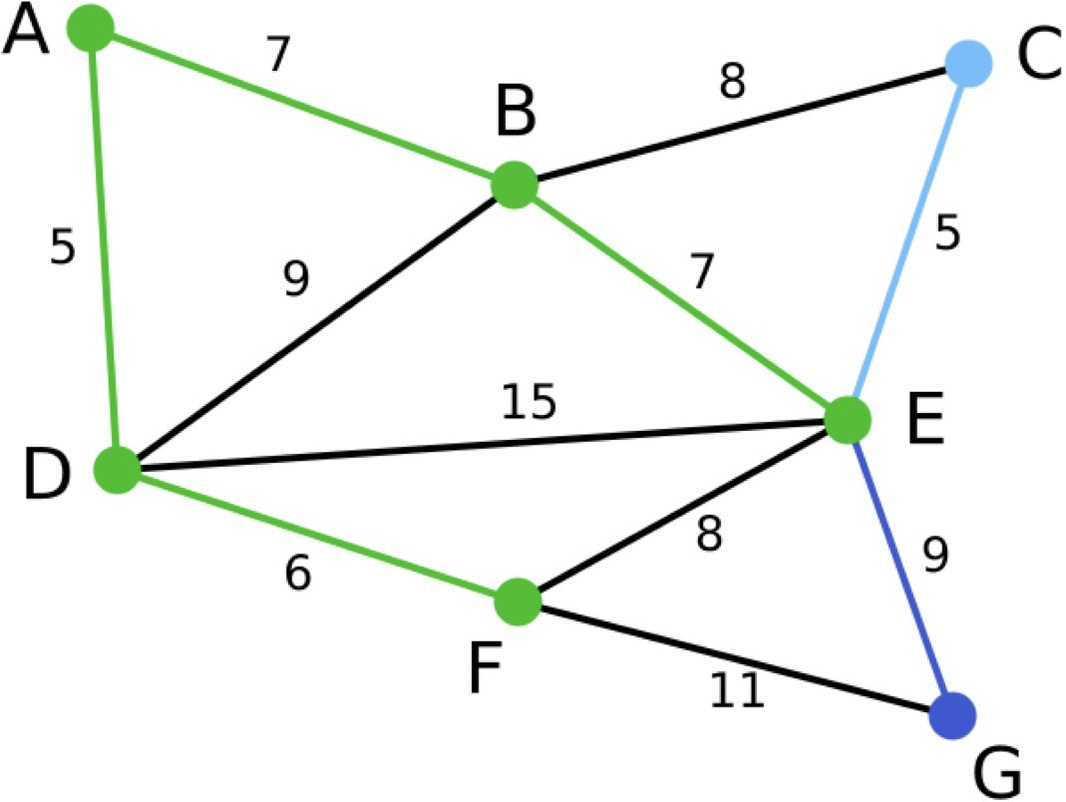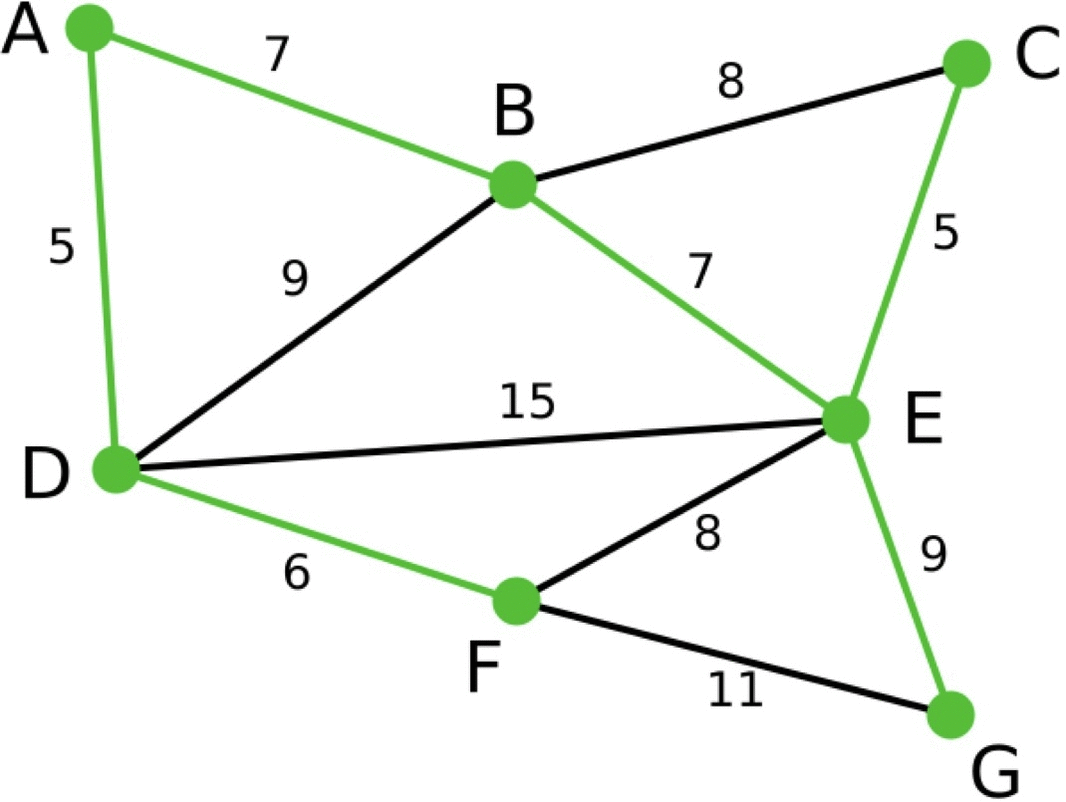
파란색으로 표현된 선은 이번 단계에서 고려할 간선이고, 그 중 선택된 간선을 하늘색으로 표현했습니다. 초록색 선은 이미 선택된 간선들을 의미합니다.
프림 알고리즘의 구현
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class PrimTest {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.parseInt(br.readLine());
int[][] adjMatrix = new int[N][N];
boolean[] visited = new boolean[N];
int[] minEdge = new int[N];
StringTokenizer st = null;
for(int i = 0;i<N;i++){
st = new StringTokenizer(br.readLine()," ");
for(int j = 0;j<N;j++){
adjMatrix[i][j] = Integer.parseInt(st.nextToken());
}
minEdge[i] = Integer.MAX_VALUE;
}
int result = 0;//최소 신장 트리 비용
minEdge[0] = 0;//임의의 시작점 0의 간선 비용을 0으로 세팅 index는 아무거나 상관없다.
for(int i = 0;i<N;i++){
// 1. 신장 트리에 포함되지않은 정점 중 최소간선비용의 정점 찾기
int min = Integer.MAX_VALUE;
int minVertex = -1;//최소간선비용의 정점번호
for(int j = 0;j<N;j++){
if(!visited[j] && min>minEdge[j]){
min = minEdge[j];
minVertex = j;
}
}
visited[minVertex] = true;//신장트리에 포함시킴.
result += min;//간선비용 누적.
//2. 선택된 정점 기준으로 신장트리에 연결되지않은 타 정점과의 간선 비용 최소로 업데이트
for (int j = 0; j < N; j++) {
//인접 안해있으면 인풋이 0이므로 걔가 최소가 되어버림.
if(!visited[j] && adjMatrix[minVertex][j]!=0 && minEdge[j] > adjMatrix[minVertex][j]){
minEdge[j] = adjMatrix[minVertex][j];
}
}
}
System.out.println(result);
}
}다익스트라 알고리즘의 구현과 비슷한 코드입니다.
각 정점에대해서 지금까지 알려진 최단 거리를 저장하는 것이 아닌, 마지막 간선의 가중치를 저장하는 방식으로 구현했습니다.
우선 순위 큐를 이용해서 최소 간선 비용의 정점을 찾으면 코드를 최적화 할 수 있습니다. 이렇게 구현을 하면, 우선순위 큐는 minEdge[ ]가 증가하는 순서로 정렬해서 담고있게 됩니다.
정당성 증명
크루스칼 알고리즘의 증명과 똑같이 증명할 수 있습니다.
크루스칼 vs 프림
크루스칼이 간선 위주였다면 프림은 정점을 위주로 풀어나가는 알고리즘입니다.
둘은 이미 만들어진 트리에 인접한 간선을 고려하는지의 여부를 제외하면 완전히 똑같은 알고리즘입니다.
최단 경로
최단 경로를 구하는 알고리즘은 3가지가 있습니다.
1. 하나의 시작 정점에서 끝 정점까지의 최단 경로 구하기
다익스트라 알고리즘- 음의 가중치를 허용하지않는다.(그래서 그리디 적용가능)
벨만-포드 알고리즘 - 음의 가중치를 허용한다.
2. 모든 정점들에대한 최단 경로
플로이드-워샬 알고리즘
이번 게시글에서는 다익스트라에대한 내용을 다루고 추후에 벨만-포드와 플로이드-워샬 알고리즘에대해서 다루겠습니다.
다익스트라
다익스트라는 그래프의 한 시작 정점이 주어졌을 때, 그 정점에서 다른 정점으로의 최단 경로를 구하는 알고리즘입니다.
다음은 다익스트라 알고리즘의 동작 방식을 표현한 그림입니다.
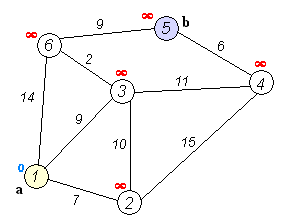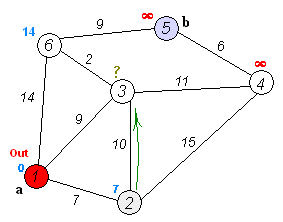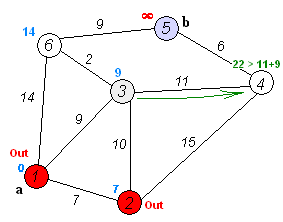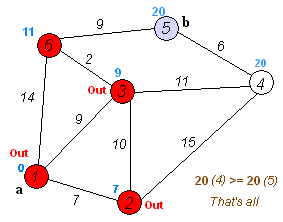
출처
Basic idea
//init
S = {v0}; distance[v0] = 0;
for (w 가 V - S에 속한다면)//V-S는 전체 정점에서 이미 방문한 정점을 뺀 차집합.
if ((v0, w)가 E에 속한다면) distance[w] = cost(v0,w);
else distance[w] = inf;
//algorithm
S = {v0};
while V–S != empty {
//아래의 코드는 지금까지 최단 경로가 구해지지않은 정점 중 가장 가까운 거리를 반복한다는 의미
u = min{distance[w], w 는 V-S의 원소};//---1
S = S U {u};
V–S = (V–S)–{u};
for(vertex w : V–S)
distance[w] = min{distance[w],distance[u]+cost(u,w)}//update distance[w];---2
}위의 코드에서 1로 마킹한 부분에대한 설명을 하겠습니다.
먼저 length[v]는 최단 경로의 길이를 의미하고 distance[w]는 시작점에서부터의 최단 경로의 길이를 의미합니다.
S는 시작점을 포함해서 현재까지 최단 경로를 발견한 점들의 집합을 의미합니다.
정당성 증명
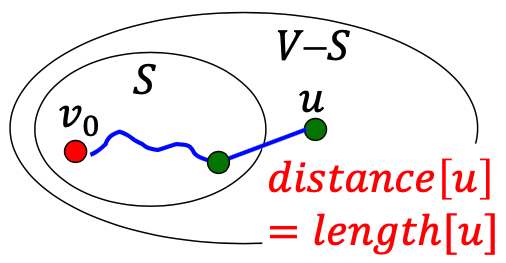
u = min{distance[w], w 는 V-S의 원소}의 의미는 u까지의 최단 거리의 길이는 distance[u] 와 같다는 의미입니다.
둘이 같다는 것은 다음처럼 증명할 수 있습니다.
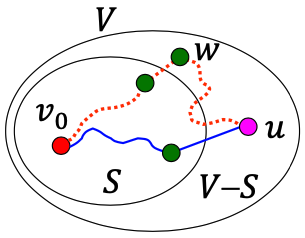
- distance[u] > length[u]라고 가정해보겠습니다.
- P를 시작점부터 u까지의 최단 경로라고 하면
- P의 길이 = length[u]입니다.
- P는 S에 속하지않는 최소 1개의 정점을 가집니다. 그렇지않다면 P의 길이 = distance[u]가 됩니다.
- P의 경로에 속하면서 S에 속하지않는 시작점에서 가장 가까운 점을 w라 하겠습니다.
- 그렇게 된다면 distance[u] > length[u] >= length[w] 가 성립하고, length[w] = distance[w]이기 때문에 이로부터
distance[u] > distance[w]를 유추해낼 수 있습니다. - 이는 다익스트라 알고리즘은 아직 최단경로가 찾아지지않은 정점들만 선택한다는 정의에 어긋납니다.(지금 보는 점보다 가까운 경로가 존재한다면 이전 탐색에서 걸러져서 S에 포함되어있기 때문입니다.)
그렇기 때문에 distance[u] = length[u]입니다.
다음으로는 distance[w]를 업데이트하는 부분입니다.
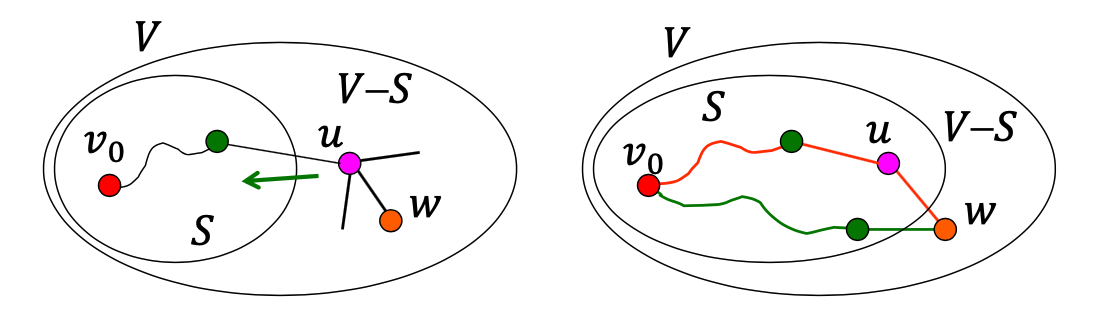
위의 그림에서와 같이 시작점 v0에서 u를 거쳐 w로 가는 경로와 v0에서 w로 가는 경로의 길이 중 가까운 경로를 distance[w]로 설정하고 S와 V-S를 최신화해줍니다.
distance[ ]를 업데이트할 때 각각의 간선들이 2번씩 체크되는데 그 이유는 다음과 같습니다.
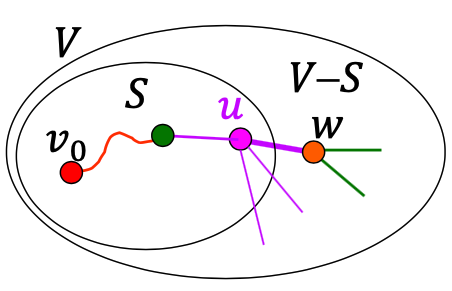
아직 최단 경로를 찾지 못한 정점 중 u에 인접한 정점들의 거리를 업데이트 할 때 u와 w를 연결하는 간선이 체크가 됩니다.
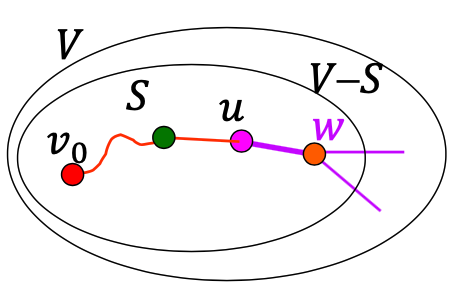
정점 w의 최단 경로가 찾아졌기 때문에, w는 S에 속하게됩니다. 아직 최단 경로를 찾기 못한 정점들에서 w까지의 거리를 업데이트하는 과정에서 u에서 w로의 간선이 다시 한 번 체크됩니다.
이런 방식으로 코드를 작성하면 각 정접들에대해서 u에 인접한 모든 간선을 살펴보는 연산이 추가되기 때문에 최악의 경우 시간복잡도가 O(𝑛^2)가 되버립니다. 이를 개선하는 방법으로는 대표적으로 우선순위 큐를 사용하는 방법(O( 𝑛 + 𝑚 log 𝑛))과 피보나치 힙을 사용하는 방법(O(𝑛 log 𝑛 + 𝑚))이 있습니다.
피보나치 힙에대한 내용은 피보나치 힙 을 확인해주시고, 지금은 우선순위 큐에대한 내용을 다루겠습니다.
다익스트라 알고리즘 로직(우선순위 큐)
-
첫 번째 정점을 기준으로 연결되어있는 정점들을 추가해가면서 최단 거리를 갱신합니다.
첫 정점부터 각 노드 사이의 거리를 저장하는 배열을 만든 후에 첫 정점의 인접 노드 간의 거리부터 먼저 계산하면서, 첫 정점부터 해당 노드 사이의 가장 짧은 거리를 해당 배열에 업데이트 합니다. 이런 로직은 현재의 정점에서 갈 수 있는 정점들부터 처리한다는 점에서 BFS와 비슷합니다.
다양한 다익스트라 알고리즘이 있지만 가장 개선된 형태인 우선순위 큐를 사용하는 방식을 다뤄보겠습니다.
먼저 우선 순위 큐를 간단하게 설명하면 MinHeap 방식을 사용해서 현재 가장 짧은 거리를 가진 노드 정보를 먼저 꺼냅니다.
꺼낸 노드는 다음의 과정을 반복합니다.
- 첫 정점을 기준으로 배열을 선언핸 첫 정점에서 각 정점까지의 거리를 저장합니다.
- 초기에는 첫 정점의 거리를 0, 나머지는 무한대(inf)로 저장합니다.
- 우선순위 큐에 순서쌍 (첫 정점, 거리 0) 만 먼저 넣어줍니다.
- 우선순위 큐에서 노드를 꺼냅니다.
- 처음에는 첫 정점만 저장된 상태이기때문에 첫번째 정점만 꺼내집니다.
- 첫 정점에 인접한 노드들 각각에대해서 첫 정점에서 각 노드로 가는 거리와 현재 배열에 저장되어있는 첫 정점에서 각 정점까지의 거리를 비교합니다.
- 배열에 저장되어 있는 거리보다, 첫 정점에서 해당 노드로 가는 거리가 더 짧은 경우, 배열에 해당 노드의 거리를 업데이트 합니다.
- 배열에 해당 노드의 거리가 업데이트된 경우, 우선순위 큐에 해당 노드를 넣어줍니다.
- 2번의 과정을 우선순위 큐에서 꺼낼 노드가 없을 때까지 반복합니다.
- 첫 정점을 기준으로 배열을 선언핸 첫 정점에서 각 정점까지의 거리를 저장합니다.
-
우선순위 큐를 사용하면 지금까지 발견된 가장 짧은 거리의 노드에대해서 먼저 계산을 해서 더 긴 거리로 계산된 루트에 대해서는 계산을 스킵할 수 있다는 장점이 있습니다.
pseudo 코드는 다음과 같습니다.
found[], distance[]를 초기화
construct min_heap(V-{s});
for(i = 0; i < n-2; i++) { //𝑛−1iterations(=Θ(𝑛))---(1)
distance[u]가 최소인 정점 u를 선택합니다. //Θ(1) found[u] = T;로 바로 배열로 접근 가능
min_heap에서 정점 u를 제거; //O(log𝑛)---(2)
for(every vertex w adjacent to u) //Θ(𝑚)total---(a)
if(found[w] == F && distance[u] + cost(u,w) < distance[w]){
distance[w] = distance[u] + cost(u,w);
adjust heap(w); //𝑂(log𝑛)foreachedgecheck---(b)
} // distance[w]가 수정됐기 때문에 heap을 조정해주는 for문
}시간 복잡도
위의 pseudo code에서 다음 2가지 과정을 거칩니다.
(1),(a) - 각 정점마다 인접한 간선들을 모두 검사하는 과정 -> 𝑂(𝑛)
(2),(b) - 우선순위 큐에 정점/거리 정보를 넣고 삭제하는 과정 -> 𝑂(log𝑛)
따라서 전체 알고리즘은 O((𝑛+𝑚)log𝑛)입니다.
