
목표 : 데이터 과학, 빅데이터, 크롤링을 익히기 위해 짧은 시간안에 가장 필요한 파이썬 핵심 문법을 정리하고, 실전 크롤링 프로그래밍을 통해 파이썬과 크롤링에 익숙해지기
원리를 파악하고 나서, 서서히 녋혀가며 이해하기!
외우고 나서, 이해하기 시작은 X
내가 퍼블리싱을 잘하게 된 이유
과하지 않았다. 매일 커리큘럼이 있었고 진도가 나가졌다.
거기서 내가 더 알라고 하지 않았고 배운 부분을 더 깊게 익힐라고 했어서 잘하게 된 것 같다. 결국 나중에 이것들이 모여 실력이 쌓인듯하다.
데이터 과학과 IT영역

보면 내가 웹을 한다면 JavaScript와 Python에 집중을 하면 될 것 같다.

데이터를 잘 수집해서 어딘가에 저장을 하고 필요하는 데이터를 추출해야하고 분석해야하고 분석된 데이터는 그래프로 그려주지 않으면 사람들이 잘몰라서 시각화해도 좋고 시각화를 하고서 정보를 제공하기 위해서 웹/앱 서비스를 제공해야 한다.
크롤링은 데이터 수집
파이썬 기본
- 데이터 타입과 변수, 그리고 출력
- 문자열 다루기 기본과 리스트 데이터 구조
- 조건문
- 반복문
- 함수
- 다양한 데이터 구조 : 튜플, 딕셔너리, 집합
프로그래밍은 데이터를 기반으로 컴퓨터에 명령을 내리는 것
데이터 : 문자 또는 숫자
a = int(input()) //그냥 input이면 str
b = int(input()) // int를 넣으면 num
print(a + b)데이터타입
data = '720'
print(type(data)) // class="str"
**변경**
print(int(data))
print(type(data)) // class="int"문자열 다루기
문자열 여러 줄은 """ """ 로 사용한다
article =""" python 시각 시각 """
article.count("시각") //2 특정 단어가 몇번 나왔는가
print (len(article)) // 문자열이 몇개인가
print (article.find("sa")) // 해당 문자열이 몇번째에 맨 처음에 나왔는가
print (article.replace("sa","aa")) // 특정 문자열을 다른 문자열로 바꾼다
print (article[2:4]) // th (slicing)
슬라이싱 // 특정 문자열부터 특정 문자열을 추출하고 싶을 때
some_string = ",,,computer..."
print(some_string) //,,,computer...
print(some_string.strip(",")) //computer... (,가 사라진다.)출력 포멧과 입력
다양한 출력
//지금까지 문자는 변수에 넣었는데 format이라는 함수를 사용했다.
print("I have a {}, I have an {}.".format("pen","apple"))
//I haver a pen. i haver an apple
print("I have a {1}, I haver an {0}.".format("pen","apple"))
//I haver a apple, I haver an pen
interest = 0.087
print (format(interest, ".2f"))
//0.08문자열 출력(참고)
print("I haver a %s, I have an %s." %("pen","apple"))
%s = string
%c = character
%d = int
%f = float 문자열과 문자열은 +가 되는데
print("This is function without return form " + str(a) + "times")
문자열과 숫자열은 +가 되지 않는다.
이 부분 오답노트
두 개의 숫자를 입력받은 후 나눈 값을 출력해라. 단 나눈 값은 소수점 두번째 자리까지만 출력
a = int(input())
b = int(input())
print(a ,"/", b ,"=", format(a/b , ".4f") )데이터구조 - 리스트(list)
데이터를 다루는 방법
location = ['서울시', '인천시', '경기도']
print (location) // ['서울시', '인천시', '경기도']
# 아 부산시를 안넣었네.. 이럴때
location.append('부산시')
print (location) // ['서울시', '인천시', '경기도', '부산시']
location[1:3] // ['경기도', '인천시']1. 리스트 선언
- 리스트변수 = []
- 리스트변수 = list()
- 리스트변수 = 데이터1, 데이터2, ...]
2. 리스트 추가
- 리스트변수.append(데이터)
- 리스트변수.insert(인덱스번호 , 데이터)
3. 리스트 삭제
- 리스트변수.remove(데이터)
- del 리스트변수[인덱스번호]
4. 리스트 수정
- 리스트변수[인덱스번호] = 수정할 데이터
5. 리스트 데이터 정렬하기
numbers = [2, 1, 4, 3]
numbers.sort()
print(numbers)6. 리스트 데이터 역순으로 정렬하기
numbers = [2, 1, 4, 3]
numbers.reverse()
print(numbers)
7. 문자열 특수 함수와 리스트
pythons_is_easy = "pythons_is_easy"
pythons_is_easy.split()
['python', 'is', 'easy']5, 6번을 쓰면 해당 변수 값이 바뀌는데 split 함수는 본래의 변수 내용은 바뀌지 않습니다. 그래서 사용하려면 새로운 변수를 추가해야합니다.
조건문
age = input("나이는 몇살인가요?")
int_age = int(age)
if(int_age >= 19):
print("당신은 성인입니다")
else:
print("당신은 성인이 아닙니다.")
and조건이랑 or 조건도, not 조건 사용가능
cash = int(input('현금은?'))
if cash > 100000:
print("레스토랑으로 간다")
else:
print("편의점으로 간다.")문제
나이를 입력받아서, 나이가 19이상이면 성인이라고, 13이상 19이하면 청소년이라고 13이하면 아동이라고 출력하기
정답
age = int(input("당신의 나이는?"))
if age > 19:
print("성인")
elif age >= 13 or age <= 19:
print("청소년")
else:
print("아동")
#파이썬에서는 else if가 아니라 elif로 사용된다.4. 반복문
여러번 실행을 시키고 싶을 때 사용합니다.
for
for i in range(반복횟수):
print (i)
for i in ["python", "java", "golang"]
print(i)
만약에 1 ~ 10까지 더하고 싶으면
for i in range(10):
이 아닌
for i in range(1, 11):
이 됩니다.
while
i = 0
while i <= 3:
print(i)
i = i + 1오답노트 / 여기는 자주 풀어봐야겠당
33번, 38번 = var를 빼야하는데 데이터를 빼려고해서 에러가 났다.
34번 = 슬라이싱을 이용해보자 (꼭 정석은 아니어도 방법이 많다. - 퍼블리싱과 비슷한 느낌)
35번 나눠야 할 대상이 3이 아니라 i이다
37번 문자열인지 숫자열인지 잘 생각하자
39번 리스트 변수는 for in 문으로 출력할 수 있다.
5. 함수
y = f(x)
x = 인자이며 인자를 넣으면 함수(function)이 특정한 동작을 하고 y에 넣어진다.즉, 입력이 있고 출력이 있는 것!
용어
- 인풋(input), 인자(argument, parameter)
함수 만들기
def 함수이름(parameter인자):
...내용
함수이름() #실행
------------------------------------
def func1 (parameter1, parameter2):
print('Hello!", parameter1)
print('Hello!", parameter2)
function("Python", "JAVA")
------------------------------------
def func2 (data1, data2(:
return data1 + data2 #return은 뒤에 값들을 결과 값으로 전달(반환)해주는 것
y = func2(1, 2)
print(y) // 3 
결국 data1 * (data1 + data2) 같은 내용들을 매번 적어서 실행시키지 않아도, 함수로 만들어서 함수만 호출하면 언제든 실행되게 만들 수 있는 것이다. 매우매우 편리하다!
지역변수와 전역변수
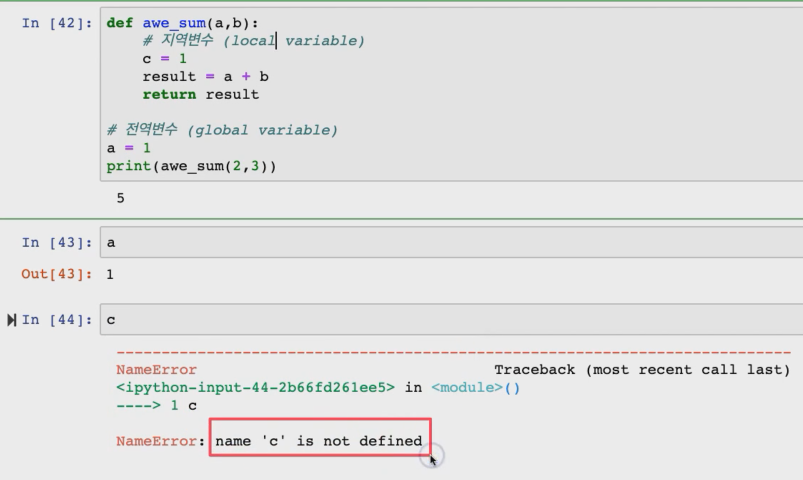
함수 안에 들어가 있으면 지역변수래서 함수가 끝나면 변수가 사라지기 때문에 함수 밖에서 그 함수를 호출하면 에러가 나온다.
자주 사용하는 return 사용방법
def id_check(id):
if id == "admin":
print("invalid id : admin")
return
print("valid id: ", id)6. 다양한 데이터 구조: 튜플, 딕셔너리, 집합
튜블(Tuple)
선언 + 입력 : 괄호를 통해서 선언할 수 있다. 변수명 = (1, 2, 3, 4)
data = (1, 2, 3)
type(data) // tuple읽기 : 변수명[인덱스번호]
data = (1, 2, 3)
data[1] // 2추가 : 삭제나 추가가 불가능합니다.
가능하다면
data1 = (1, 2, 3)
data2 = (4, 5, 6)
data1 + data2 // (1, 2, 3, 4, 5, 6)
data1 * 3 // (1, 2, 3, 1, 2, 3, 1, 2, 3)삭제 : 삭제나 추가가 불가능합니다.
수정 : 삭제나 추가가 불가능합니다.
도대체 언제 사용하는건가요
1. 결과 값을 여러개 넣고 싶을 때
def quot_and_rem(x,y):
quot = x // y
rem = x % y
return quot, rem #결과 값이 여러개다
quot, rem = quot_and_rem(3, 10)-
두 개의 결과 값을 뒤바꾸고 싶을때
x, y = y, x
List <-> tuple
data1 = (1, 2, 3)
type(data1) #tuple
list(data1) # [1, 2, 3] 튜플을 리스트로 바꿈
또는
data1_list = list(data1)
type(data1_list) # list
data11_tuple = tuple(data1_list)
type(data1_tuple) # tuple튜플에서 데이터로 바꾸면 좋은 점 : 리스트로 바꾸면 데이터 수정, 삭제, 추가가 가능
딕셔너리(사전)
선언 + 입력 : 변수명 = {} 또는 dict(), 초기값과 함께 선언, 변수명 = {키:값,키:값}
data_dict = {'한국' : 'KR', '일본':'JP'}읽기 : 변수명[키]
data_dict['한국'] // 'KR'추가 : 변수명[새로운키] = 새로운값
data_dict['마국'] = 'US'삭제 : del 변수명[삭제할키]
del data_dict['일본']수정 : 변수명[수정할키] = 수정할값
data_dict['알본'] = 'JR'키나 값만 쫙 출력하고 싶을 때 (.keys() 중요)
data_dict.keys()
dict_keys(['한국', '중국', '미국']) #리스트
for keys in data_dict.keys():
print(key)
일본
중국
미국
data_dict.values()
dict_values(['KO', 'CN', 'US'])
for keys in data_dict.values():
print(key)
KO
CN
US
.tems()로 하면 전체 key와 values를 튜플 형태로 출력해준다.
가장 많이 쓰이는 것
for key in data_dict.keys():
print(data_dict[key])데이터 구조 (집합 또는 set)
수학 집합 연산을 쉽게 하기 위해 만든 자료형
선언 + 입력 : 변수명 = set(), 변수명 = {데이터1, 데이터2, ...} , 변수명 = set{데이터1}, 변수명 = set({데이터1, 데이터2...})
읽기 :
추가 :
삭제 :
수정 :
data_set = {'apple', 'dell', 'samsung', 'lg'}
type(data_set) #set
'motorola' in data_set # false
if 'apple' in data_set:
print(data_set) # {'apple', 'dell', 'samsung', 'lg'}
집합연산
data1 = {'apple', 'samsung', 'lg'} # 스마트폰 생산 업체
data2 = {'samsung', 'lg', 'xaiomi'} # TV 생산 업체
data1 & data2 #교집합 {'lg', 'samsung'}
data1 | data2 # 합집합 {'apple', 'samsung', 'lg', 'xaiomi'}
data1 - data2 # 차집합(앞에서 뒤를 빼준다) {'apple'}
data1 ^ data2 # {'apple', 'xaiomi'}순서가 없다
중복이 없다
data_list = {'apple', 'dell', 'samsung', 'lg','apple', 'dell','lg'}
set (data_list) #중복이 제거된다 {'apple', 'dell', 'samsung', 'lg'}
data = set(data_list)
data # {'apple', 'dell', 'samsung', 'lg'}
list(data) {'apple', 'dell', 'samsung', 'lg'}빈 데이터 구조
data_list = list() # []
data_tuple = tuple() # ()
data_dict = dict() # {}
data_set = set()