참고 영상: [딥러닝 기계 번역] Transformer: Attention Is All You Need (꼼꼼한 딥러닝 논문 리뷰와 코드 실습). by 동빈 나
Transformer
Transformer란 무엇일까? 간단하게 생각했을 때, 데이터가 들어왔을 때, 그 데이터를 인공지능이 이해할 수 있도록 벡터로 바꿔주는 역할을 하는 기술이라고 생각한다.
Transformer에 대해서 공부하기 전에 우리는 encoder, decoder, attention mechanism에 대해서 알아야한다. 말만 들으면 벌써 어질어질 하지만 하나씩 살펴보자.
Back Ground
Encdoer, Decoder
-
Encoder: 특정 형식의 정보를 다른 형식으로 변환하는 장치, 회로, 소프트웨어, 알고리즘 등 을 말한다.
=> 인공지능 분야에서 간단하게 생각하면, 고차원 데이터(이미지, 자연어 문장 등)을 인공지능 즉, 컴퓨터가 이해할 수 있는 저차원 데이터(벡터 값, 실수 값 등)으로 축소시켜주는 역할을 하는 부분이다. -
Decoder: Encoder에 의해 처리된 정보를 받아 원하는 형태의 출력을 생성하는 역할을 한다.
=> 한 마디로, encoder에서 축소한 저차원의 데이터를 다시 우리가 원하는 형식의 출력으로 변경해주는 역할을 하는 것이다.
Ex) 영어 -> encoder -> vector -> decoder -> 한국어
이런 식으로 동작한다고 보면 된다.
여기에서 학습은 Encoder는 입력의 중요한 정보는 보존하면서 불필요한 정보는 제거하는 법을 학습하고, Decoder는 encoder가 뽑아준 latent vector를 기반으로 출력하는데 여기서 나오는 출력과 실제 출력의 차이를 줄이는 방향으로 학습한다.
Attention Mechanism
이 Mechanism도 어떻게 보면 이름에 나와있듯이 내가 어디를 중점적으로 볼 것이냐를 택하는 mechanism이다.
이전에 seq2seq의 방식을 설명해보면, encoder를 지나서 문장 전체를 고정된 크기의 context vector로 출력한다. 하지만, 이 과정에서 당연하게도 고차원의 데이터를 저차원으로 축소했기에 Bottleneck현상이 발생하고, 정보 손실이 일어난다. 이러한 정보 손실을 막고자 encoder부분에서 나오는 모든 출력들을 다시 보겠다는 취지에서 나온 mechanism이다.
그냥 전체를 다 보겠다는 것도 아니고, 중요한 부분에 더 가중치를 둬서 보겠다는 것이다.
Encoder와 Decoder의 출력으로 가중치를 구하는데,
Decoder의 입력과 Encoder의 전체 출력을 내적하여 각각의 가중치를 구하고 그 가중치를 곱해서 Decoder의 다음 출력의 입력값으로 넣어준다.
수식적으로는, 
-Energy: 매번 디코더가 출력 단어를 만들 때마다 모든 인코더의 출력을 고려해 어떤 h(인코더 출력)값과 많은 연관성을 가지는 지를 값으로 구할 수 있음.
-Weight: energy 값에 softmax를 취해서 상대적인 확률로 나타냄.
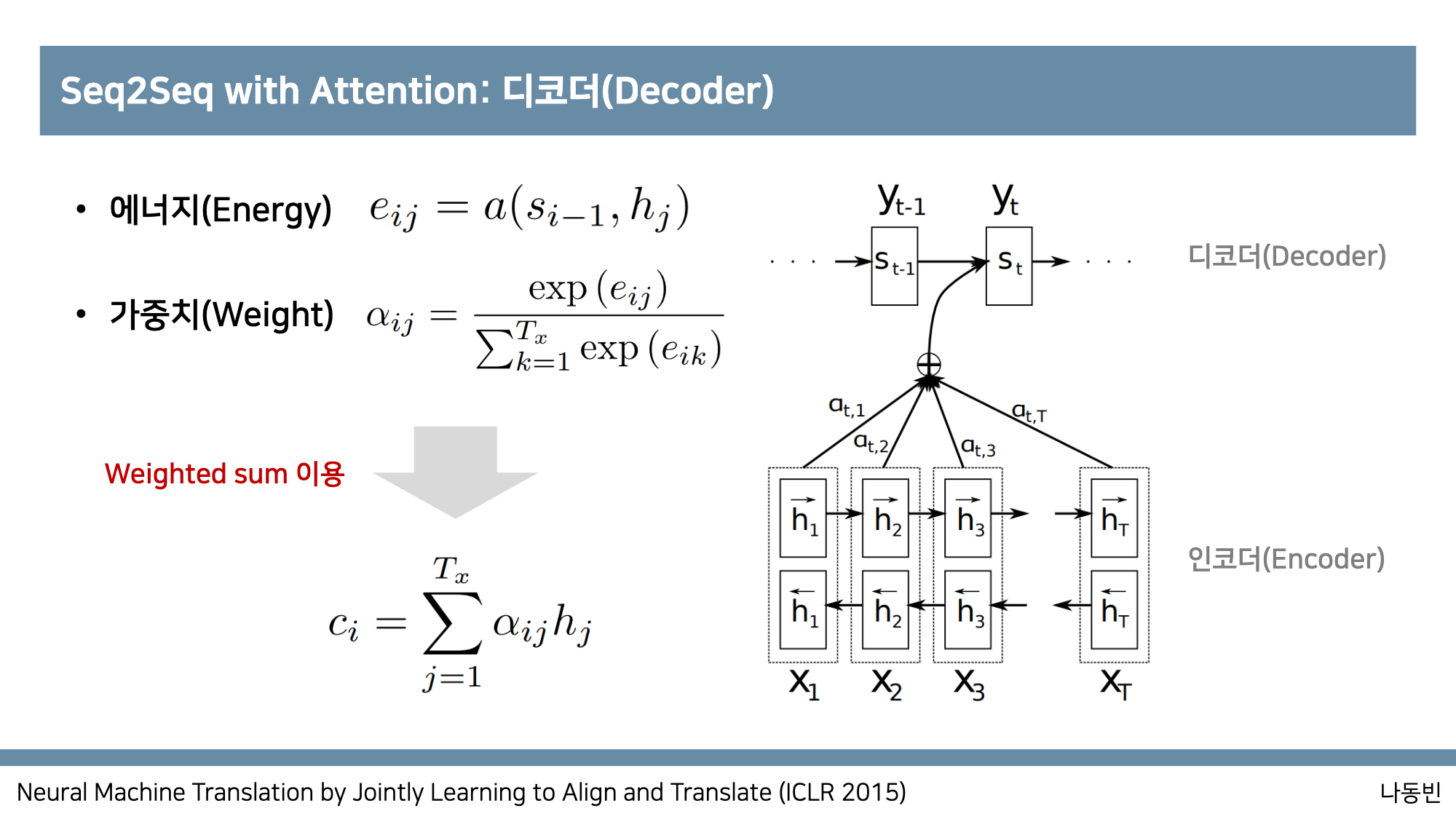
이렇게 softmax를 사용하여 어떤 값이 (이전의 decoder의 출력값)과 가장 연관성이 있는 지 가중치를 구하고 encoder 모든 출력에 가중치값을 곱하고 과 같이 디코더의 입력으로 들어간다고 한다.
결국, transformer는 이전에 모델들과는 다르게 attention기법만 잘 활용해도 좋은 성능을 낼 수 있다는 것을 보여준다.(RNN과 CNN을 사용하지 않음)
Transformer
- Architecture
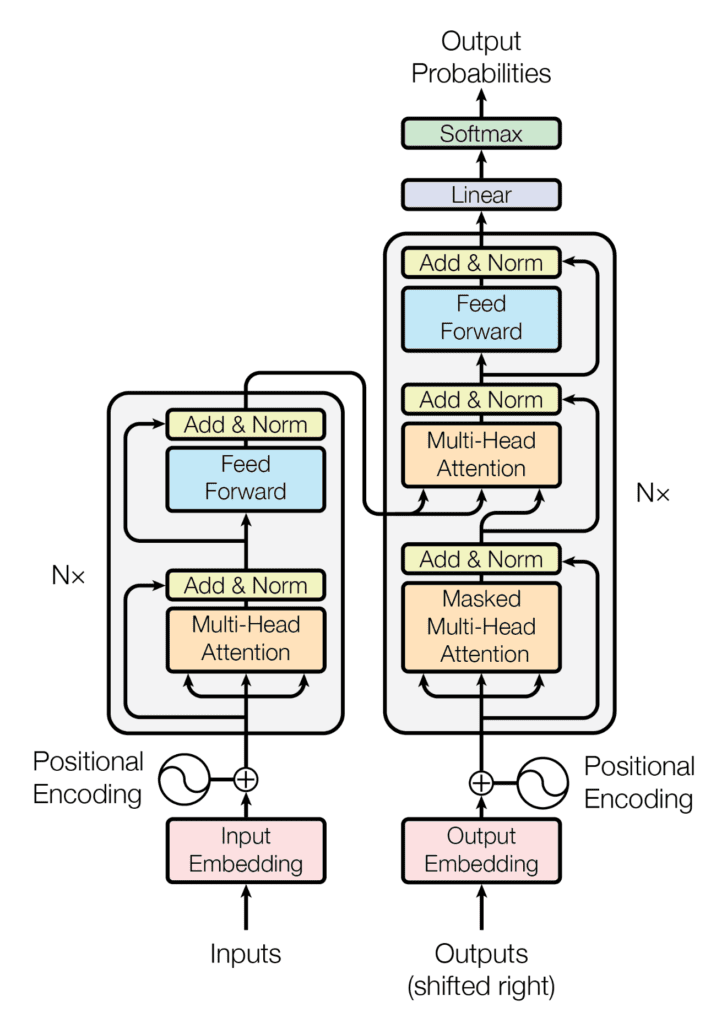
(왼쪽: Encoder, 오른쪽: Decoder)
=> Transformer는 RNN이나 CNN을 사용하지 않기에 데이터의 순서에 대한 정보를 포함하지 않고 있으므로 Positional Encoding을 추가해서 각 데이터들의 순서 정보를 부여한다.(step by step 방식으로 encoding이나 deocding 하지 않아서 인 것 같음.)
=> Attention Layer도 한 번이 아닌 N번 중첩해서 사용함.
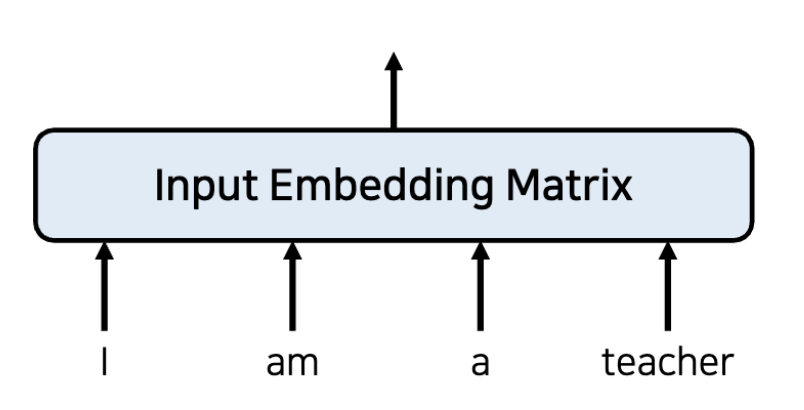
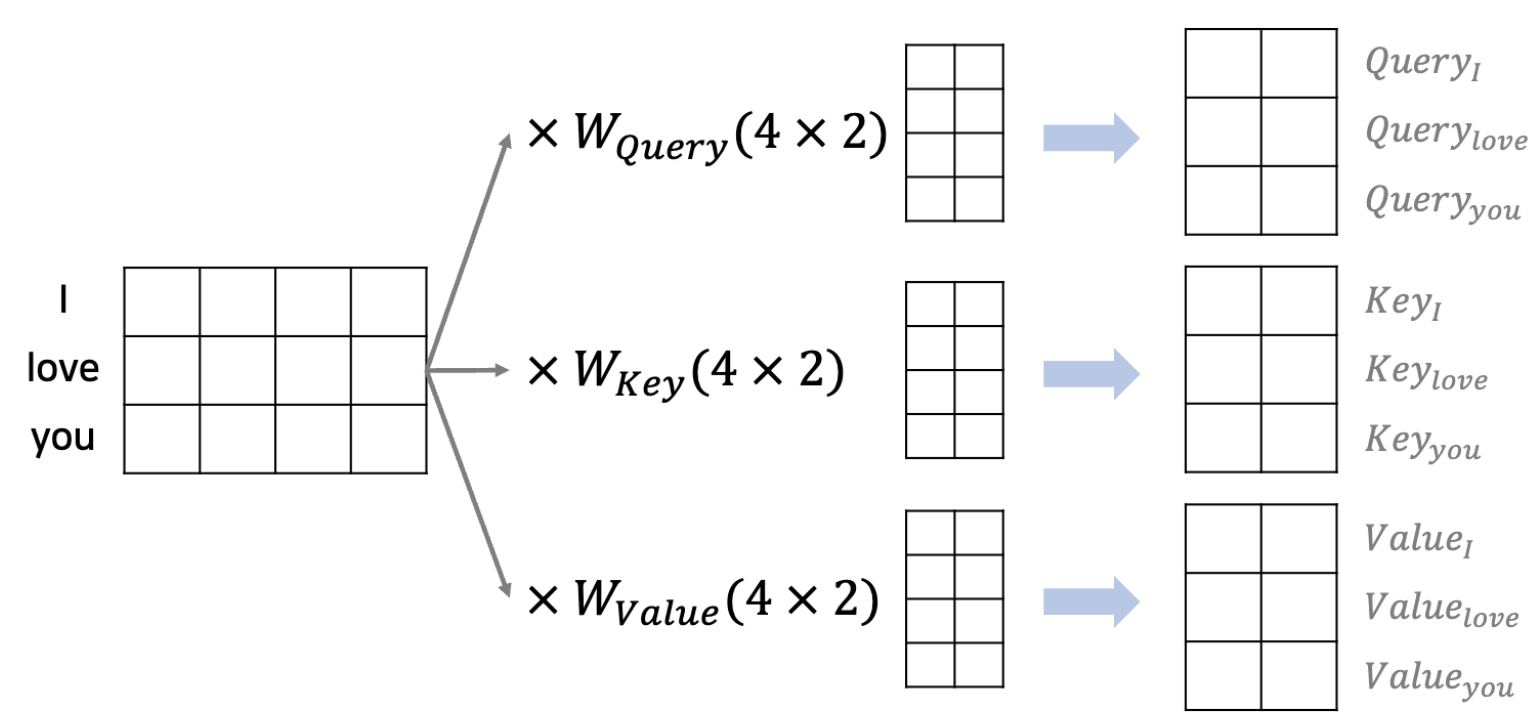
먼저 데이터를 임베딩 Matrix에 집어넣어서 작은 차원에 continuous한 실수 값으로 표현한다.(단어의 경우 one-hot encoding으로 나타냈다면 차원이 엄청 크기 때문에)
여기서 embedding matrix의 행은 단어의 개수, 열은 내가 나타내고 싶은 embedding 차원의 수로 나타낸다. 본 논문에서는 512로 설정한다고 말한다.
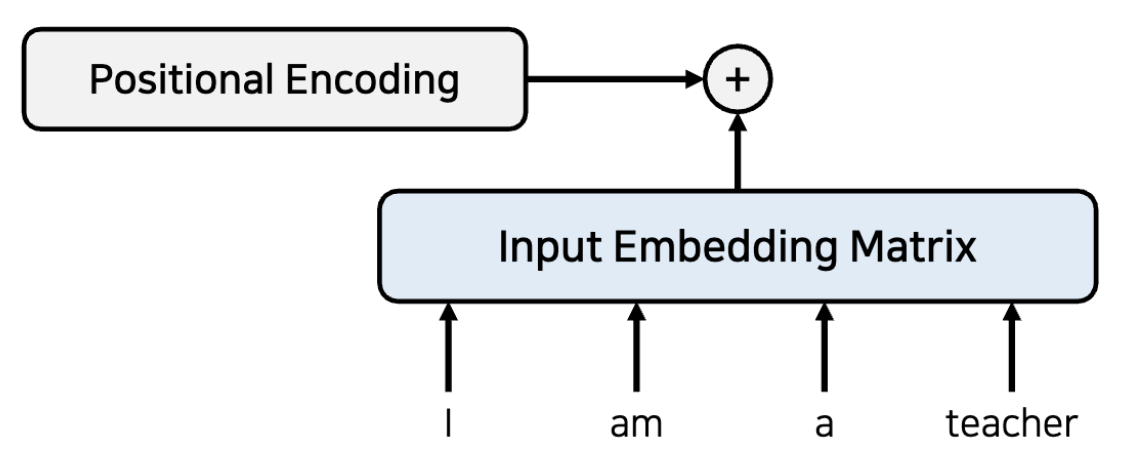
RNN이랑은 다르게 step by step 방식이 아니기 때문에, 위치 정보를 포함하고 있지 않아서 Positional Encoding으로 위치 정보를 따로 부여해준다.(embedding 차원과 같은 encoding값을 element wise 합으로 더해준다.)
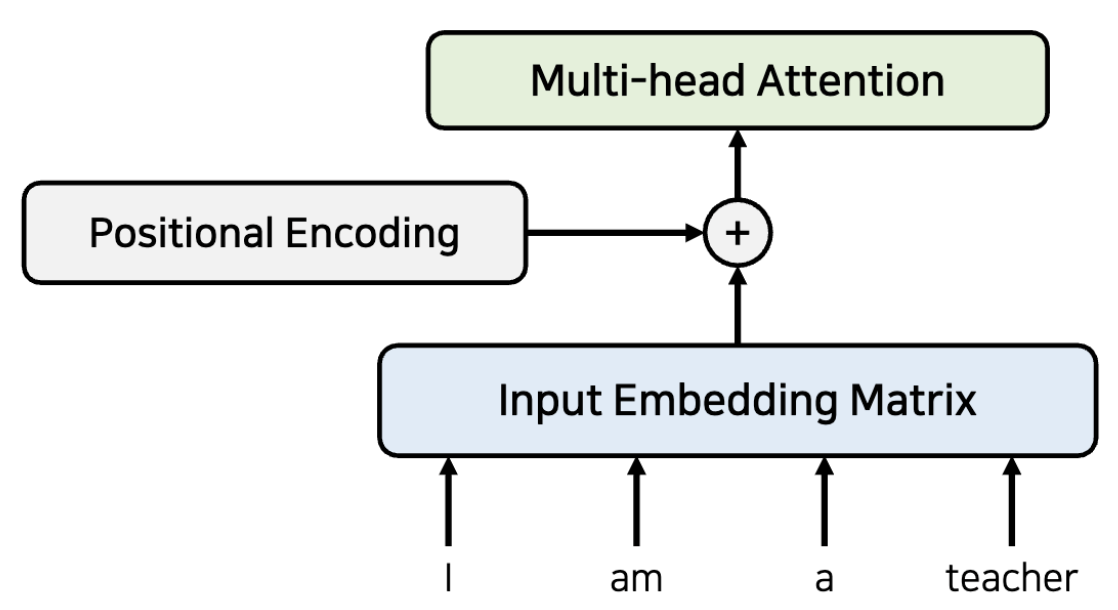
이제 이 값을 Attention에 넣어준다.
Self-Attention
Encoder부분의 attention은 self-attention을 사용하는데, 이해하기 쉽게 말하면, 각각의 단어가 서로에게 어떤 연관성을 가지고 있는 지를 구하기 위해 사용된다.
문장을 구성하는 각각의 단어가 각각 서로에게 attention score을 부여하여 각가의 단어가 어떠한 단어와 높은 연관성을 가지는 지 알 수 있다.
(Ex. "나는 어제 집에 갔다."라는 문장에서 나는-갔다 는 주어와 동작이라는 연관성을 갖고 있다는 것을 알 수 있다.)=> 입력 데이터에 대한 문맥 정보를 잘 학습할 수 있음.

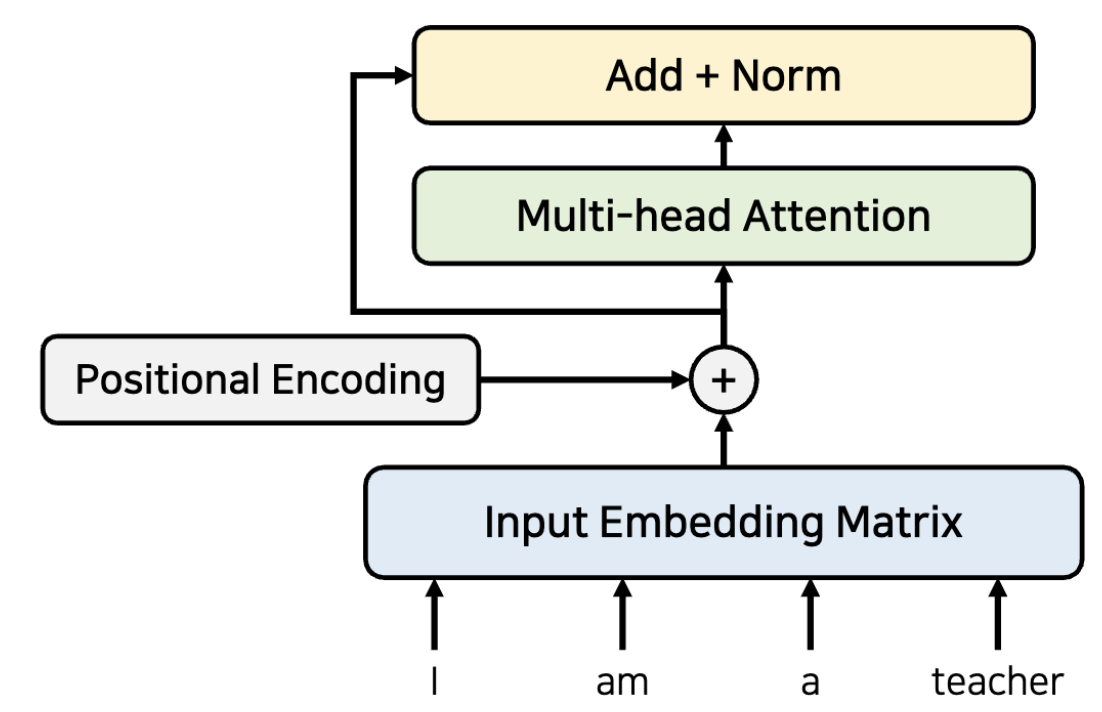
그리고, 성능 향상을 위해 residual 방식으로 잔차 학습 방식을 사용한다.(간단히 설명하면, 입력된 정보에 추가되는 정보만 학습하는 방식이다.)
그래서 attention 수행 후 나온 값과 residual connection으로 더해진 값을 Normalization까지해서 내보낸다.
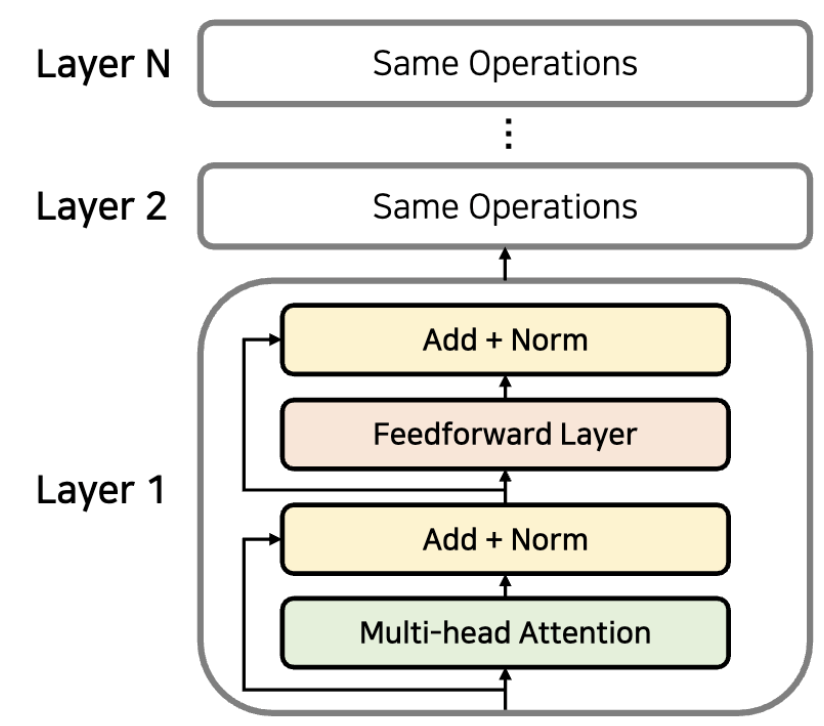
그리하여, 이런 식으로 동작한다.
- Feedforward Layer: Neural network임.
여기서 각 Layer들은 각각 다른 parameter를 갖게 된다.
그리고 입력되는 값과 출력되는 값의 dimension은 동일하다.(Residual과 Multi-Layer를 쉽게 하기 위해)
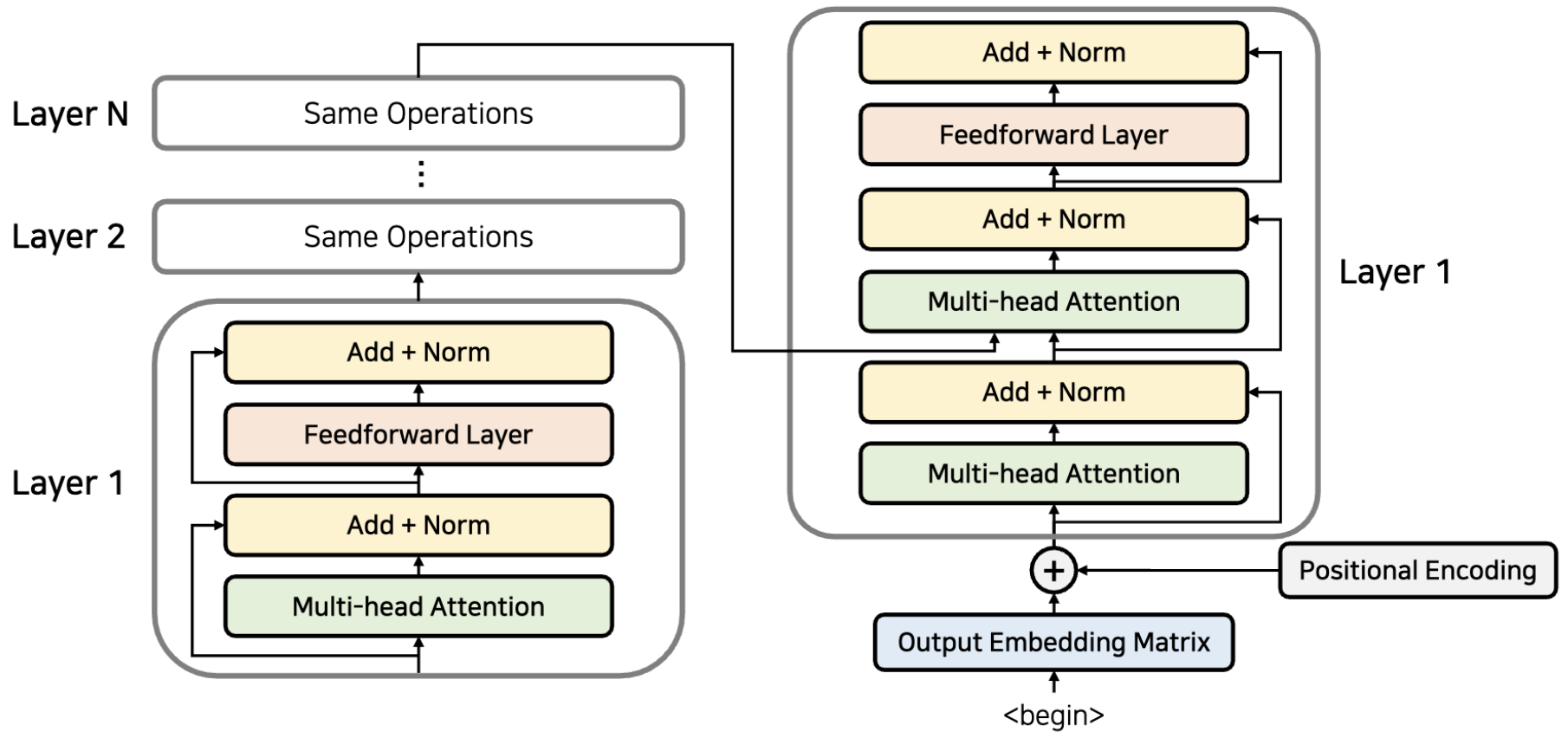
이렇게 Encoder의 마지막 출력 부분을 Decoder attention부분에 넣어서 Decoder 파트에서 매번 출력할 때마다, 입력 source 문장 중에서 어떤 단어에게 가장 많은 초점을 두어야하는 지 알려주기 위함이다.
=> Decoder의 처음 attention 부분은 self-attention으로 각 단어들의 입력된 문장의 단어들 서로 간의 연관성을 파악. 2번째 attention(encoder-decoder attention)에서는 encoder의 출력에 대해 attention할 수 있게 해준다.
디코더 또한 Layer가 여러개 될 수 있고, encoder 마지막 레이어의 출력이 모든 디코더 레이어에 입력된다. 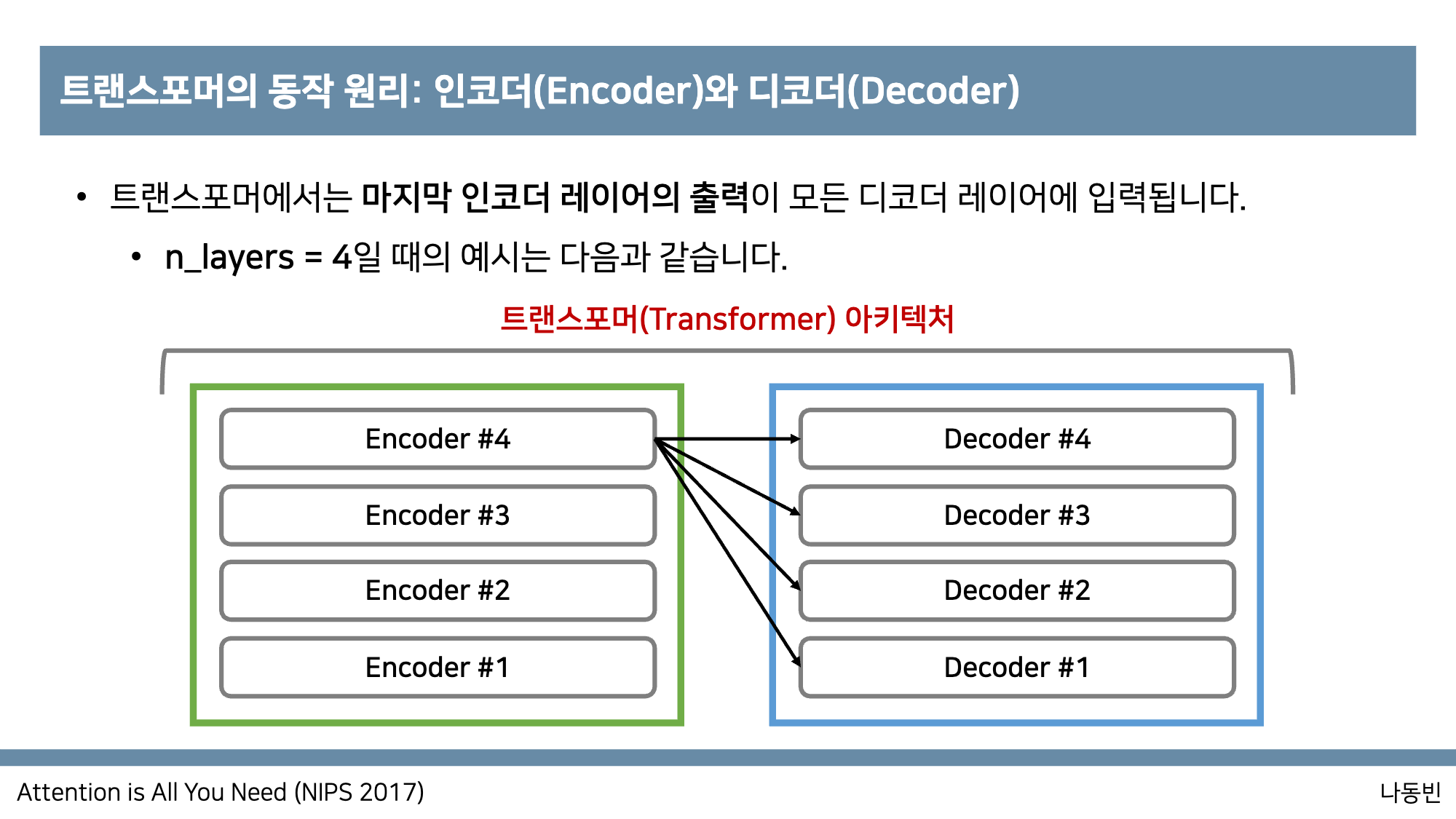
Encoder와 Decoder의 Layer개수는 맞춰준다고 한다.
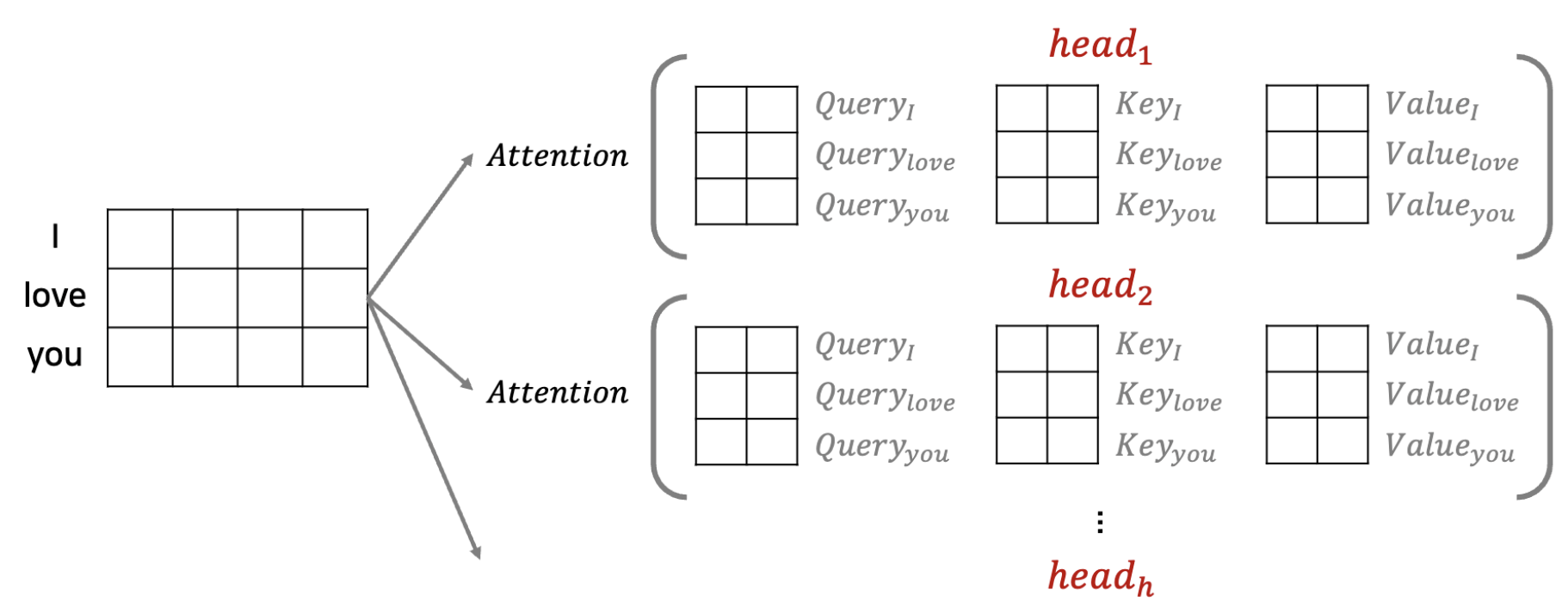
Multi-Head Attention
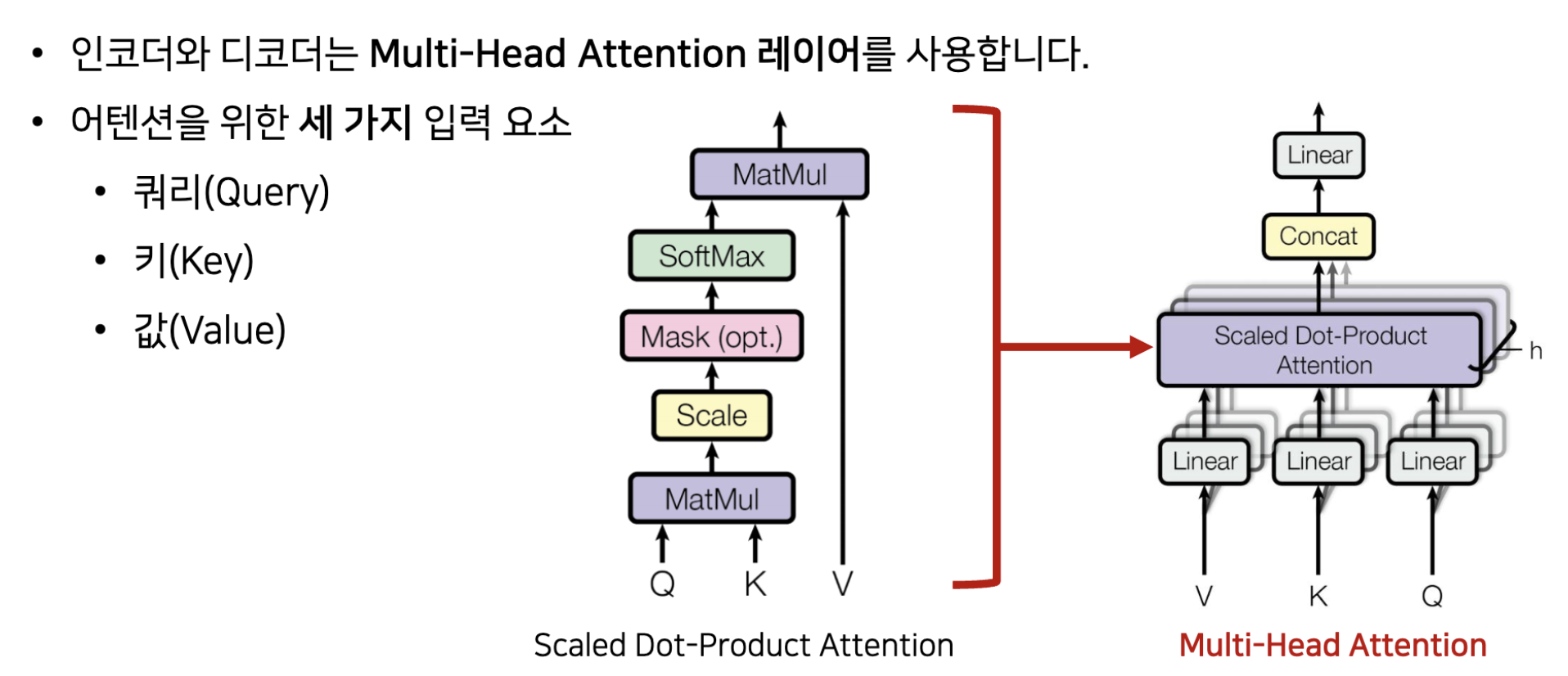
- Query: 무언가를 물어보는 주체(Ex. "I")
- Key: 물어보는 대상(Ex. "I", "am", "a", "teacher")
- Value: Query와 Key를 이용해서 Attention score를 구하고 그걸 다시 Key에 곱해서 Value값을 뽑아낼 수 있다.
이걸 h개만큼 해줘서 h개 만큼의 관점에 대한 정보를 얻을 수 있다.
(Ex. I-teacher의 연관성을 높다고 생각하는 attention이 있고, I-am의 연관성을 더 높다고 생각하는 attention이 있을 수 있다는 거임.)
여기서 Linear()를 거치는 이유는, 일단 입력을 3개(Q, K, V)로 복제하고 각각이 어떤 역할을 할 지를 정해주기 위해서이다.
여기서 각각의 head로 나오게된 attention값등를 마지막에 concat을 하고 Linear Layer을 거쳐서 입력 값과 같은 차원의 출력 값이 나오도록 한다. (Encoder와 Decoder 그리고 Decoder에서의 위치에 따라 Q, K, V가 어떻게 사용될지는 정해짐.)

수식을 보면 이런 식으로 표현할 수 있음.
- softmax: 상대적인 확률을 구해서 뭐가 제일 중요한 지 선정
- : scale, softmax가 너무 날카롭지 않게 해줌. 내적값의 분산이 너무 커지지 않도록 조절해서, softmax가 너무 날카로워지는 걸 방지하기 위해서. 만약 분산이 너무 커지면, 초반에 다른 단어들은 무시되고 중요하다고 생각하는 단어만 고려할 수 있기 때문에.
- : 각 Q, K, V가 h개의 Linear Layer을 거쳐서 각각 어떤 관점으로 이 문장을 볼 지를 정해줌.(위의 설명보단 이게 더 직관적이네)
=> 그래서 나중에 attention score을 시각화 했을 때, h개 만큼 그래프가 나오게 된다.
동작 원리(단어 하나)
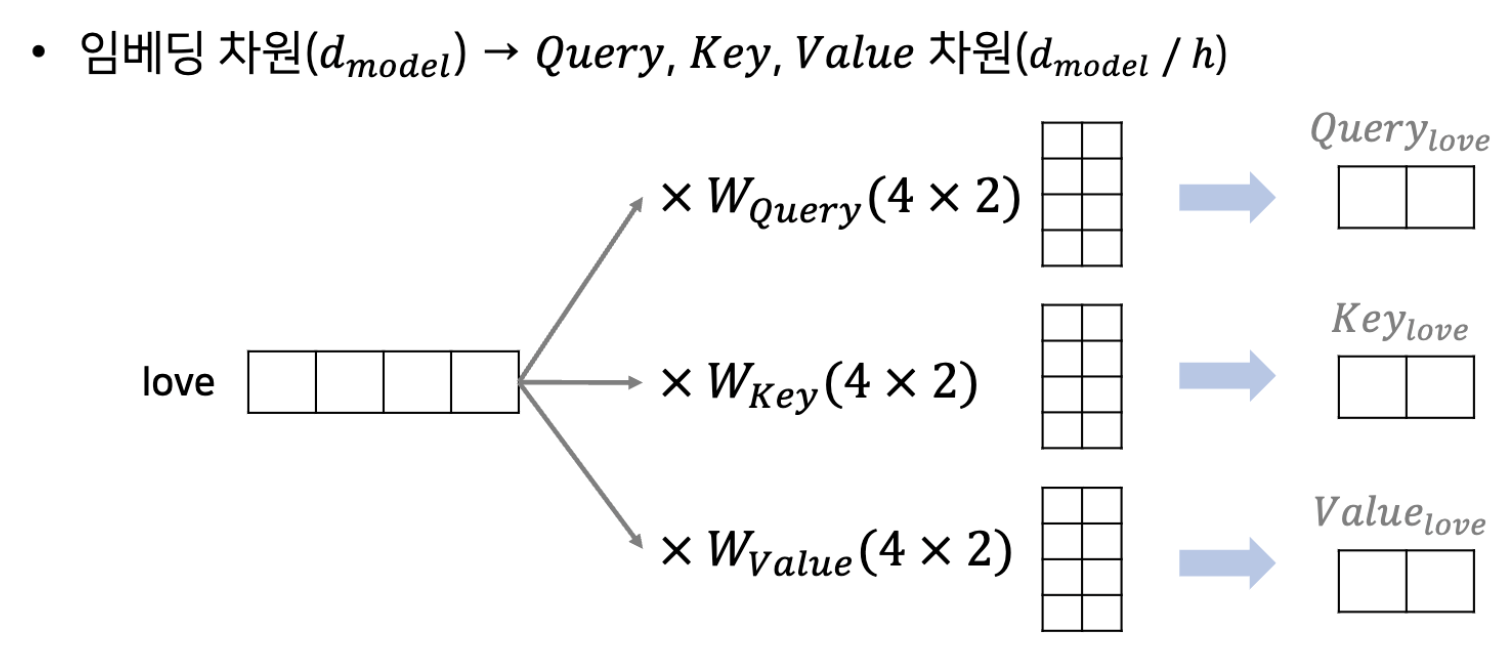
- 임베딩 차원: 4
- heads: 2
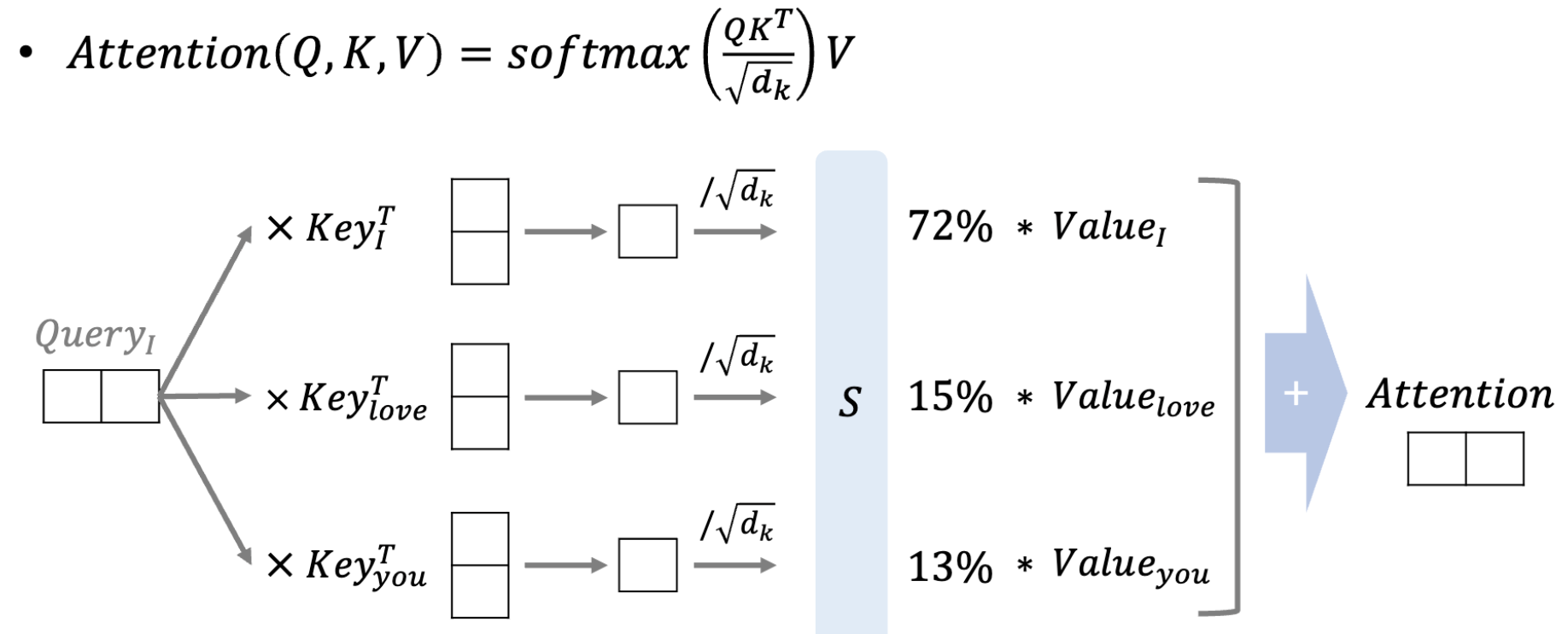
이런 식으로, query와 key를 행렬곱 해주고, scale해준 후, softmax를 통해 attention score를 구한 후 value에 곱하고 각 값들을 더해줘서 attention value값을 뽑아낸다.
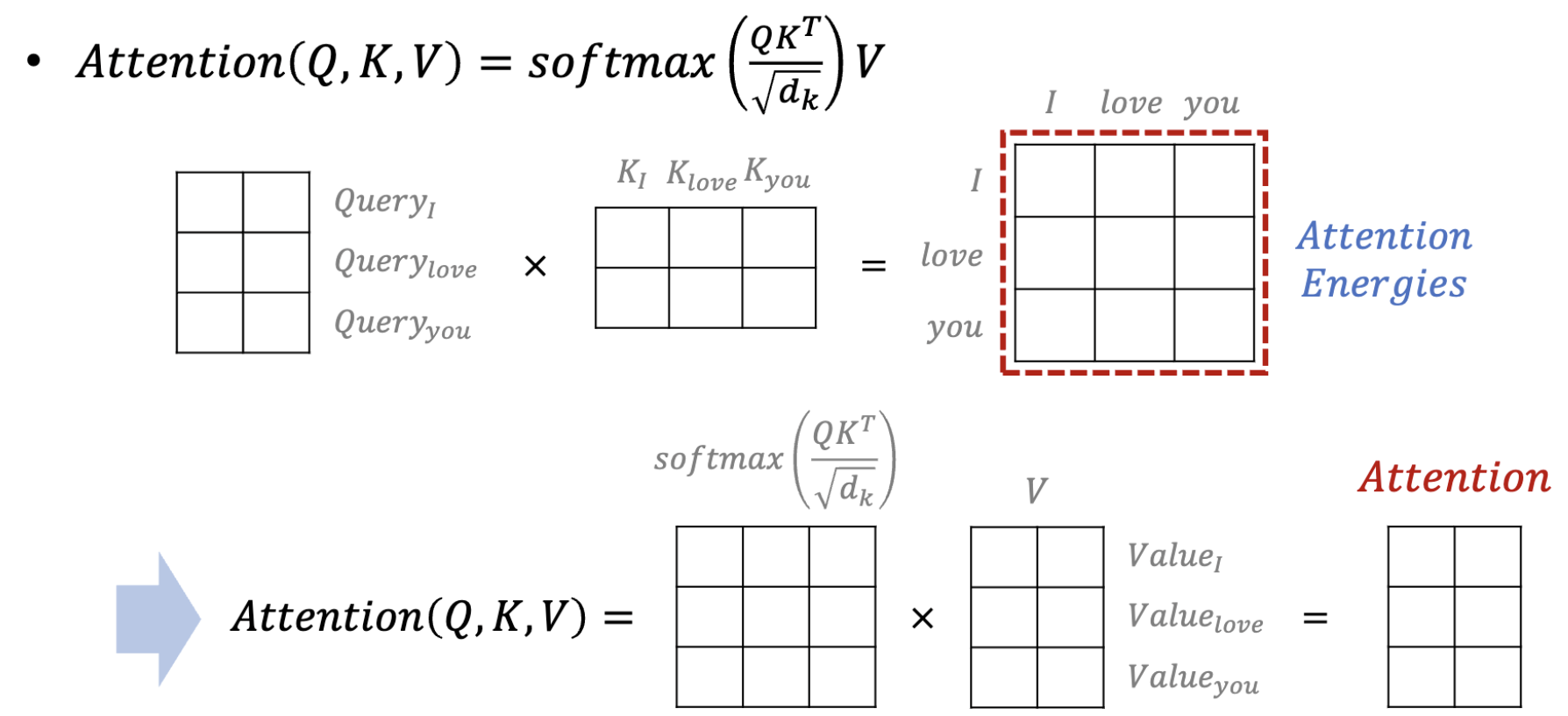
- Attention Energies: 각각의 단어가 각각의 key값에 대해 얼마나 높은 언관성을 표현하는 숫치를 부여했는 지.
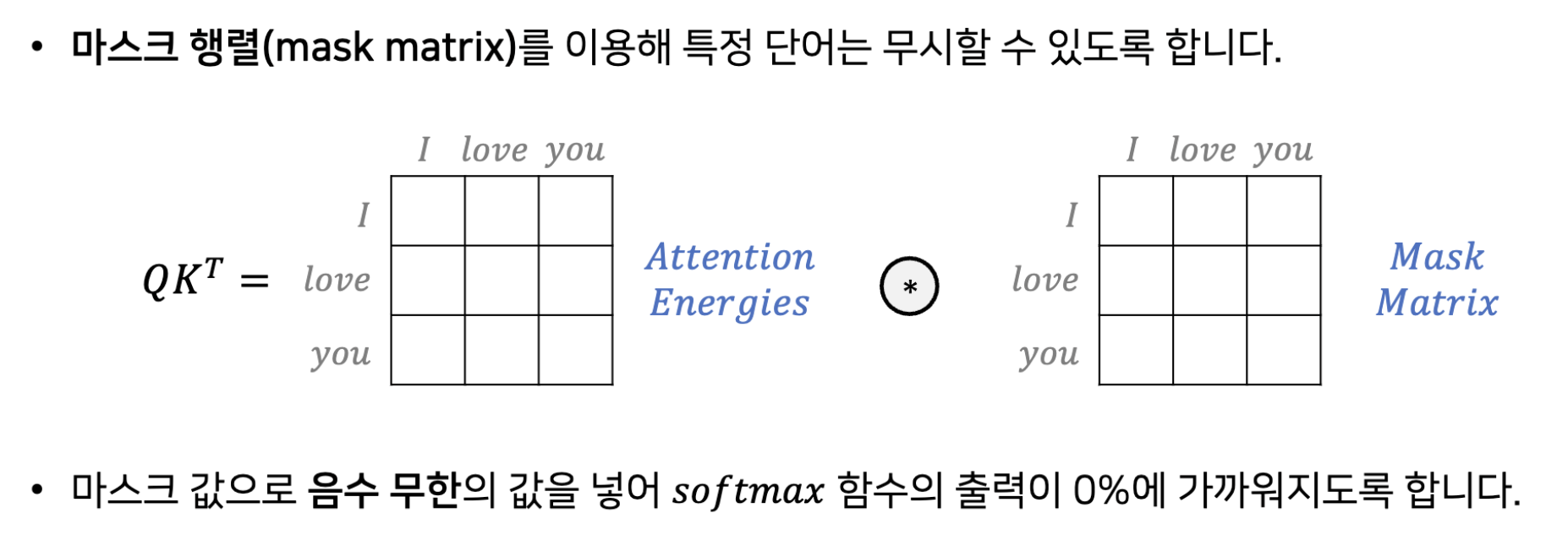
Mask Matrix
특정 단어를 무시하기 위해 사용하는 행렬.
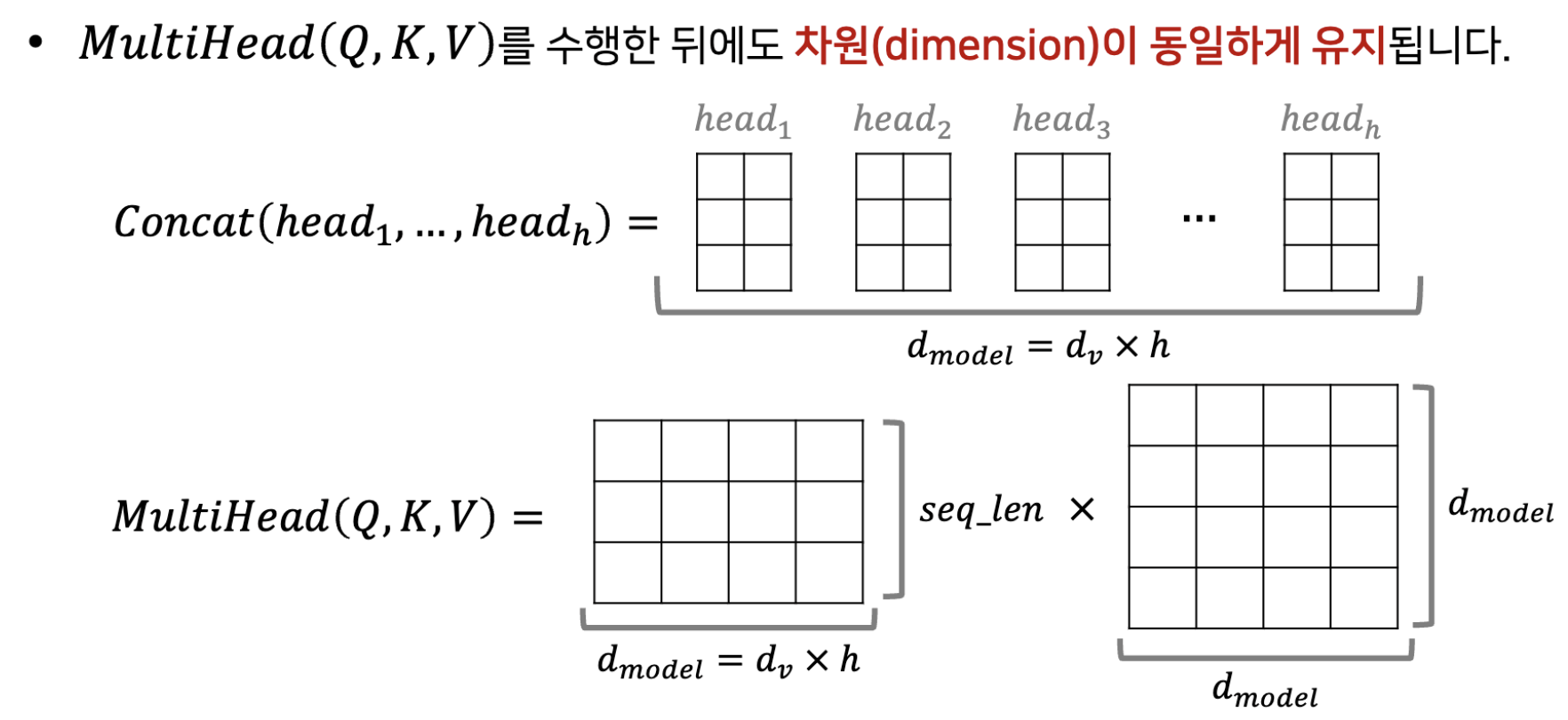
이런 식으로 결국에 마지막에 concat으로 합치기 때문에, 입력의 차원과 동일한 차원이 나오게 되는 것이다. 그리고 마지막에, Linear Layer(X)의 행렬을 곱해서 MultiHead attention의 결과값이 나옴.
(마지막에 Linear Layer을 한번 더 거치는 이유는 여러 head가 학습한 서로 다른 정보들을 잘 융합해서 다음 Layer로 넘겨주려고.)
Attention of Transformer
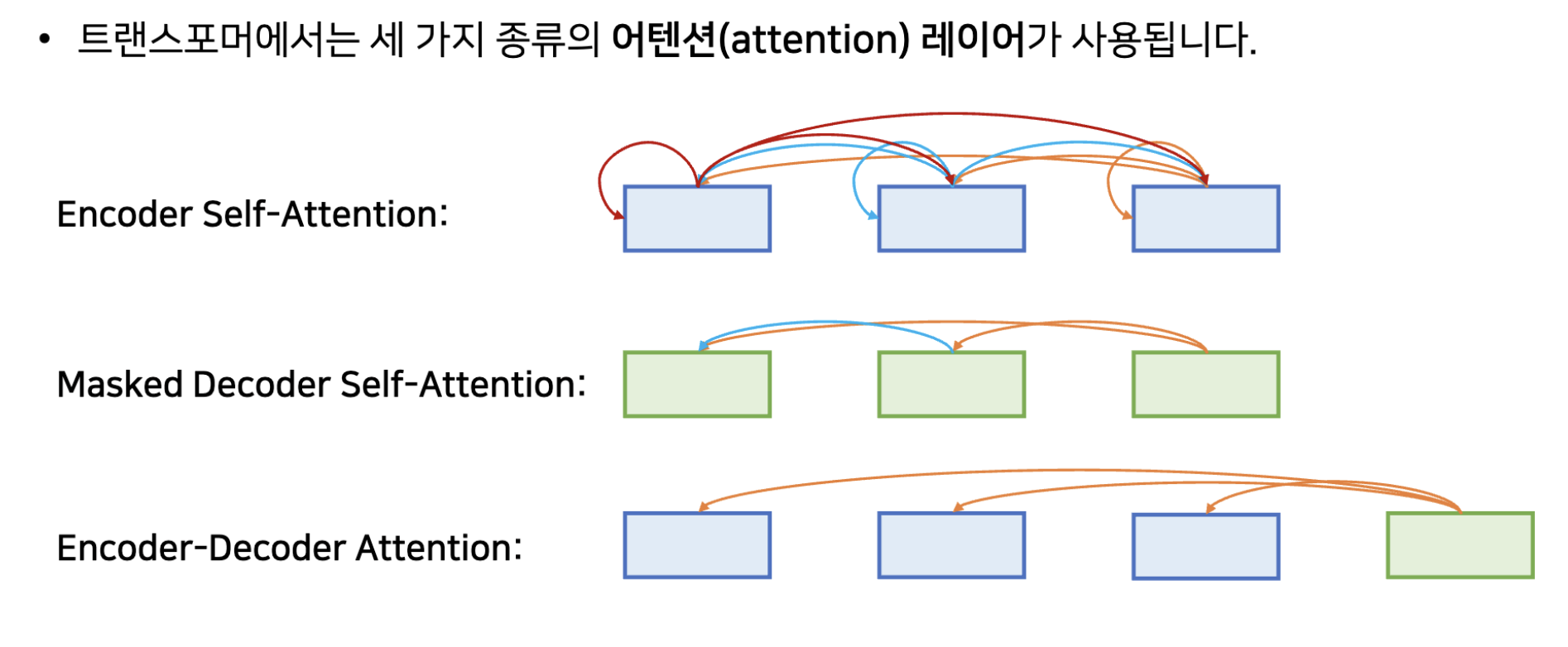
- Encoder Self-Attention: Encoder에서 쓰이는 attention, 각각의 단어가 서로에 대해 어떤 연관성을 지니는 지, 전체 문장에 대한 representation learning 가능.
- Masked Decoder Self-Attention: Decoder에서 self-attention을 수행할 때는, 각각의 단어가 모든 출력 단어에 대한 연관성을 생각하지 않고 앞쪽에 등장했던 단어들만 참고할 수 있도록 한다. (이를 위해 Mask Matrix를 활용)
- Encoder-Decoder Attention: Query는 Decoder에 있고, Key와 Value는 Encoder에 있음.
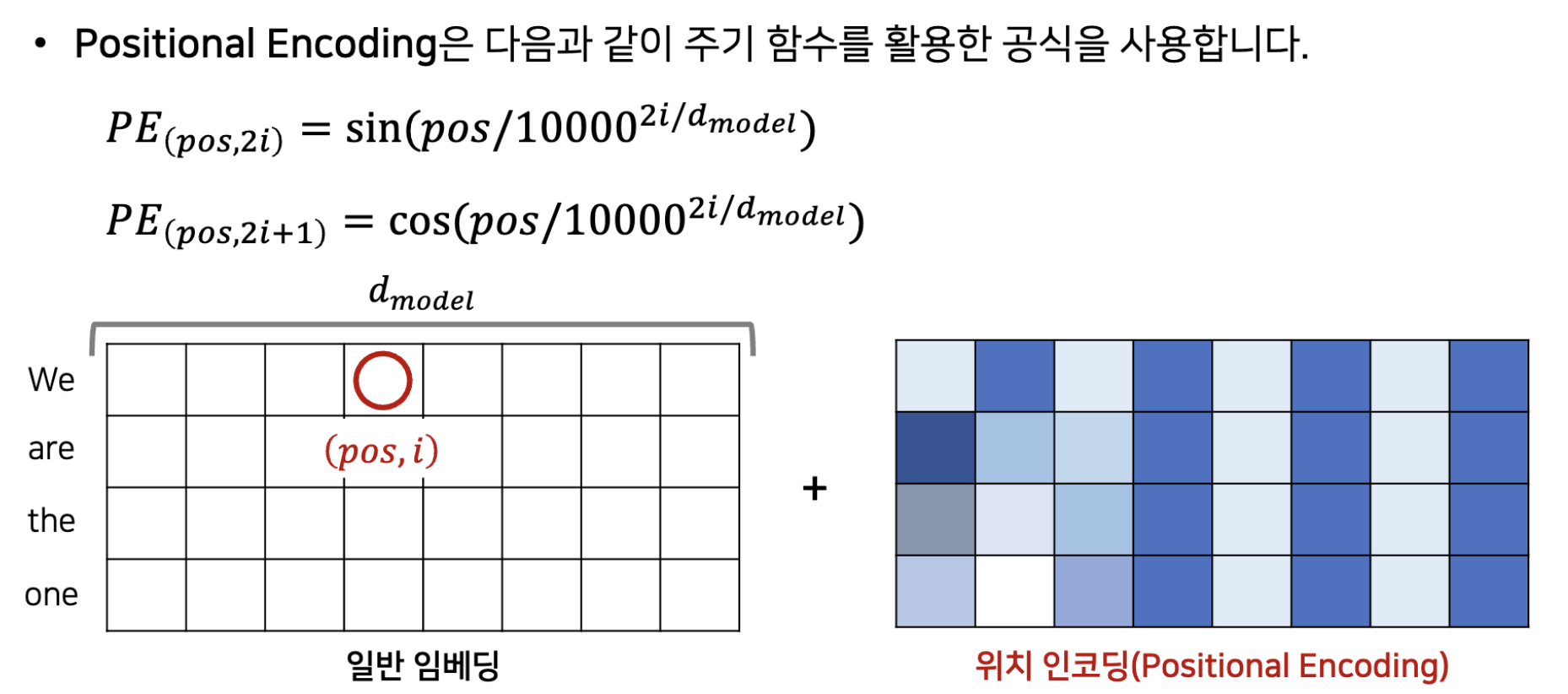
Positional Encoding
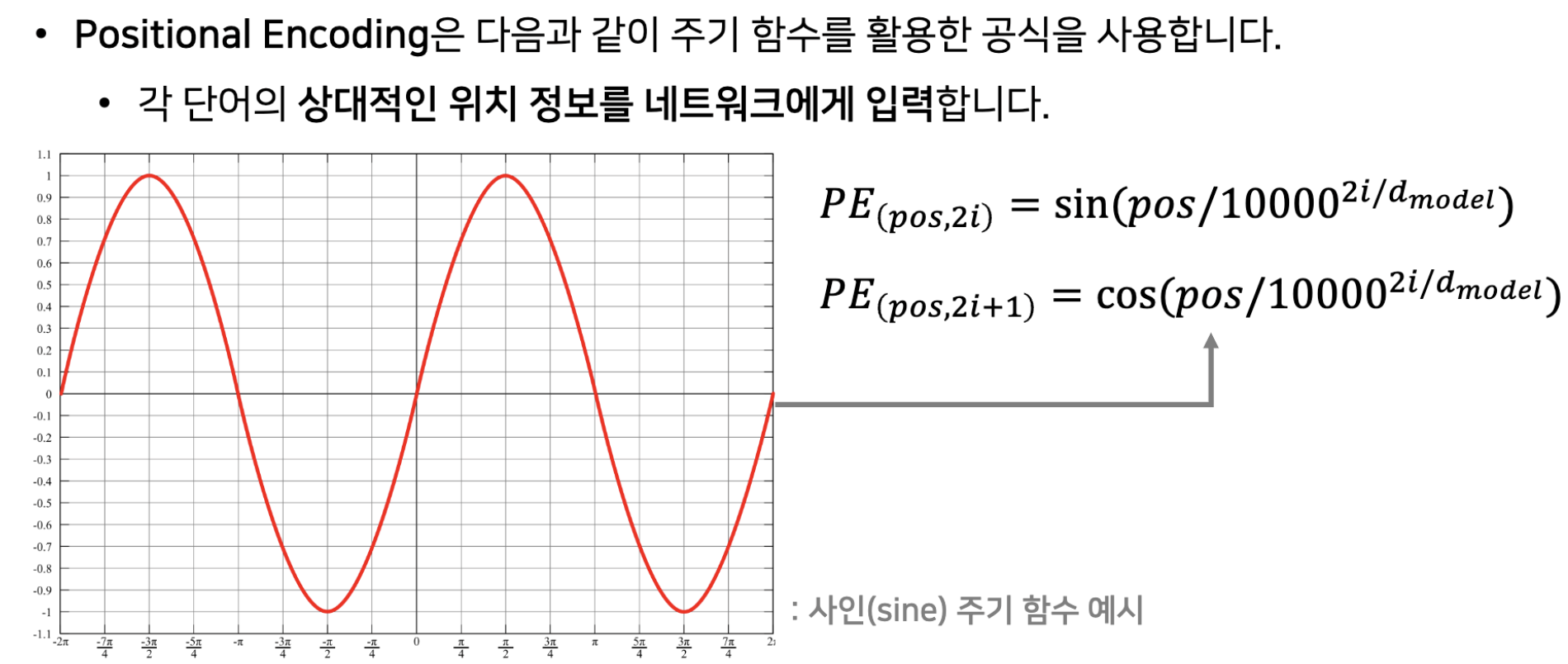
- pos: 단어의 번호
- i: 각각의 단어에 대한 embedding값의 위치
=>sin, cos말고 다른 주기함수도 가능함.