논문: AN IMAGE IS WORTH 16X16 WORDS:
TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
참고 영상: ViT: Model and Data Scaling는 Transformer로 가능하다! | ICLR 2021 | 이인규
ViT=> Vision Transformer에 준말이다.
원래는 NLP에서 사용하던 개념인 Transformer를 Vision Recognition에도 적용한 논문이다.
먼저 모델의 Architecture 부터 살펴보면,
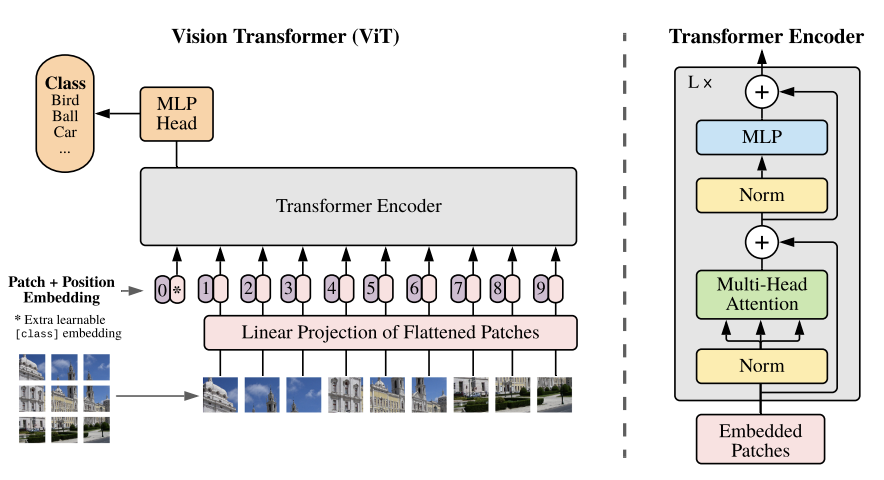
이다.
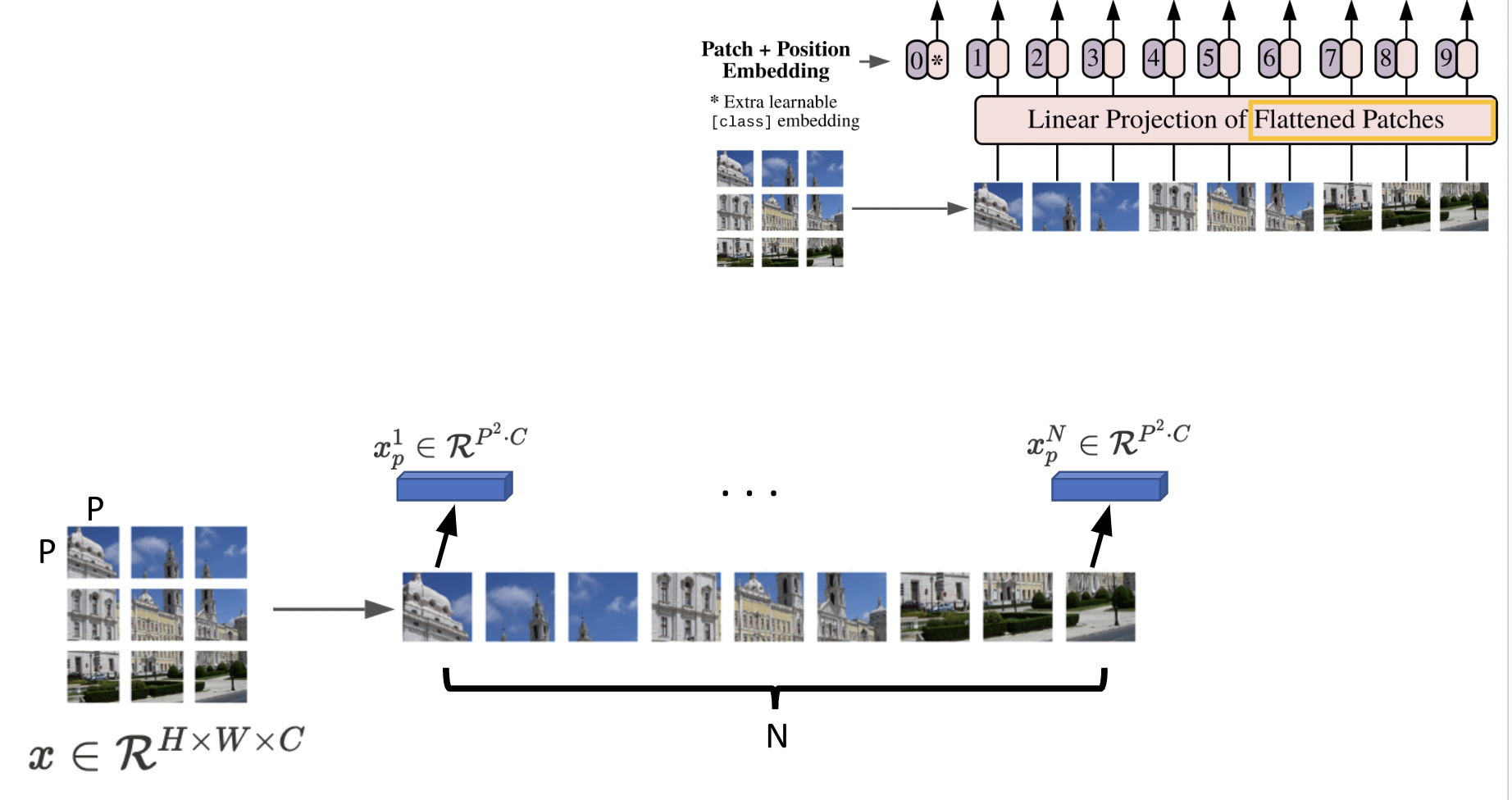
먼저 필자는 이미지()를 1차원 token의 sequence()로 flatten 시켜준다.
- H: height
- W: width
- C: channel
- P: patches
- N: # of patches
그리고 이것을 E라는 matrix를 곱하여 필자가 설정한 D크기의 constant latent vector로 linear projection해준다. => patch embeddings
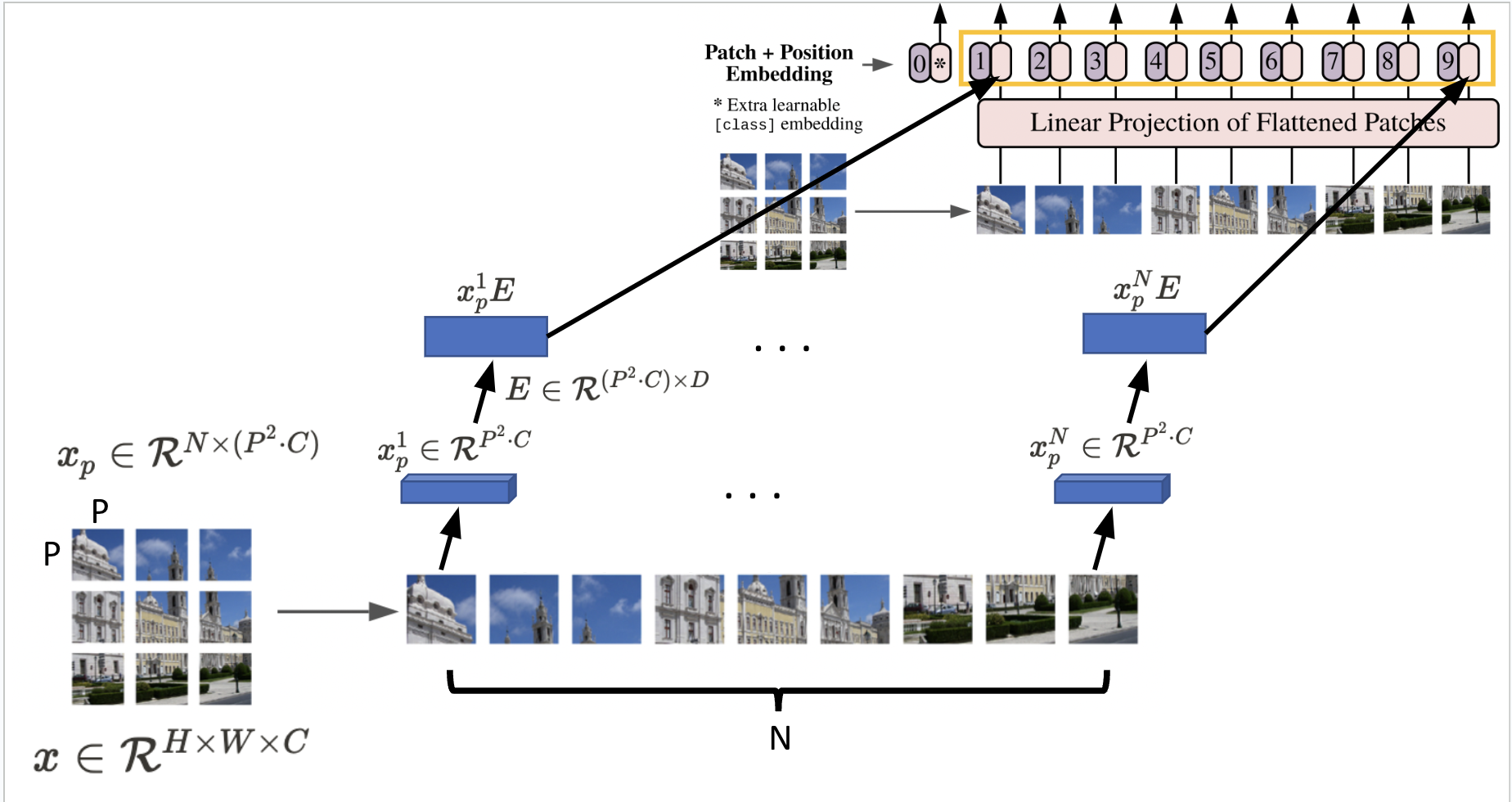
이런 식으로 이렇게 할당 된다. 이게 N개가 있는 형식
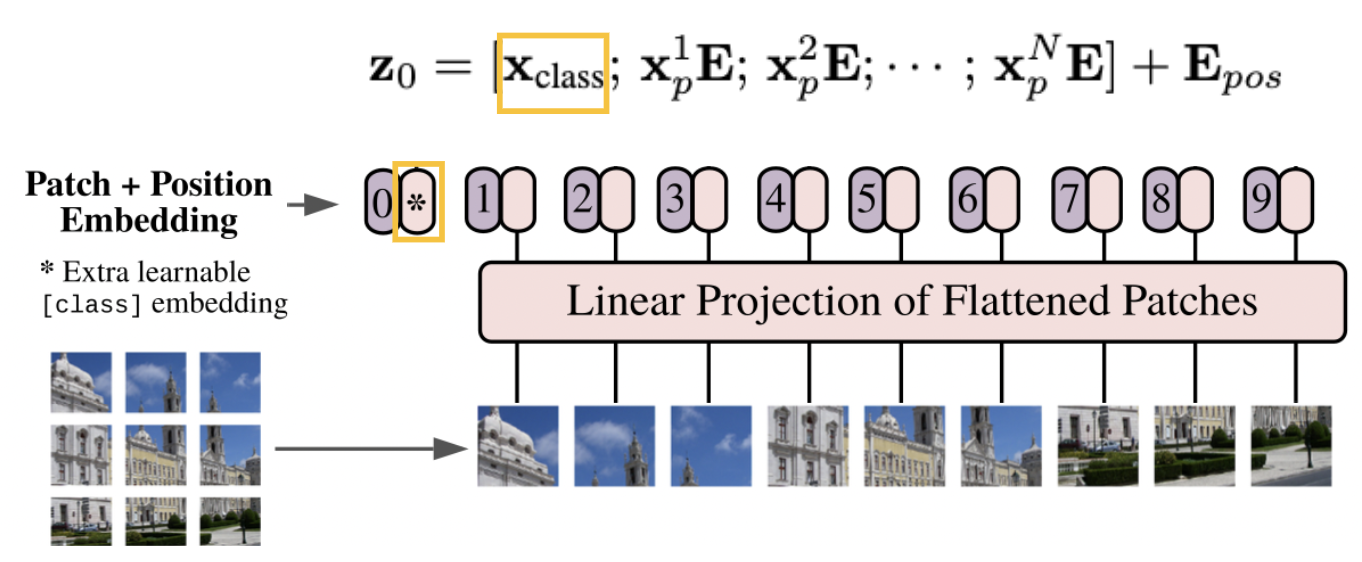
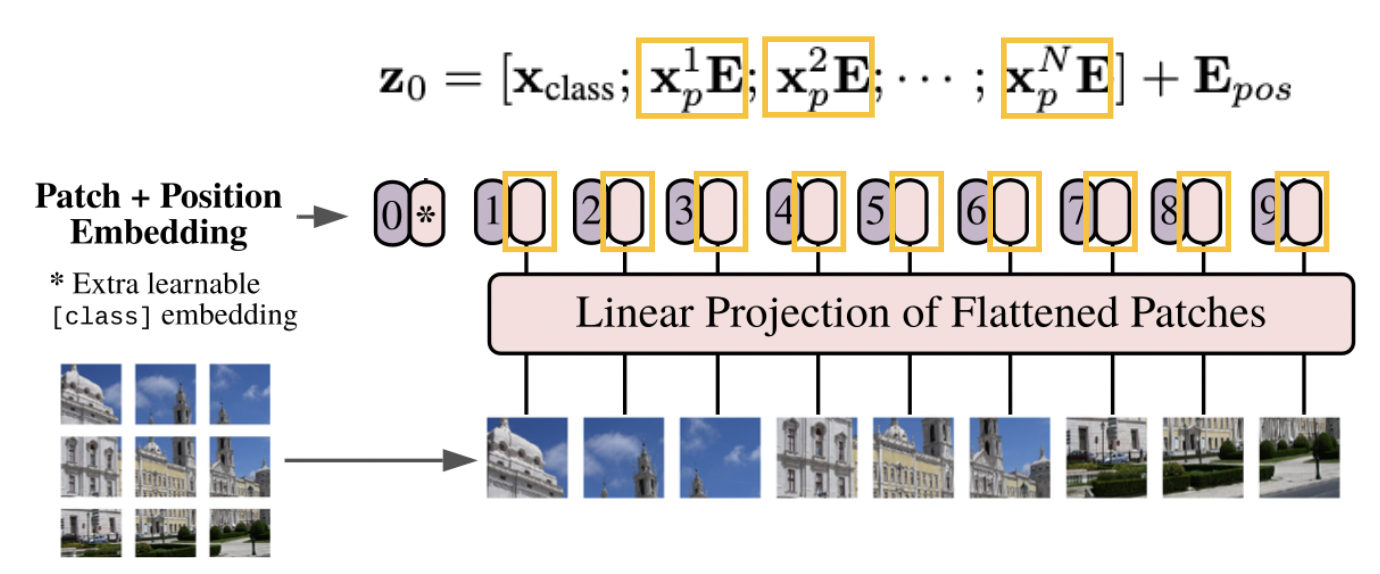
그리고 필자가 하려는 image classification을 위해 class 정보에 대한 class embedding()가 추가가 된다.
또한 각각의 패치의 위치 정보를 embedding하여 추가해준다.
순서는 왼쪽에서 오른쪽으로 매긴다.
가 된다.
이 모델은 Transformer의 Encoder 부분을 활용한다.
고로, 이런 구조로 이루어지게 된다.

그리고 이 부분의 attention부분을 좀 더 세밀하게 살펴보면,
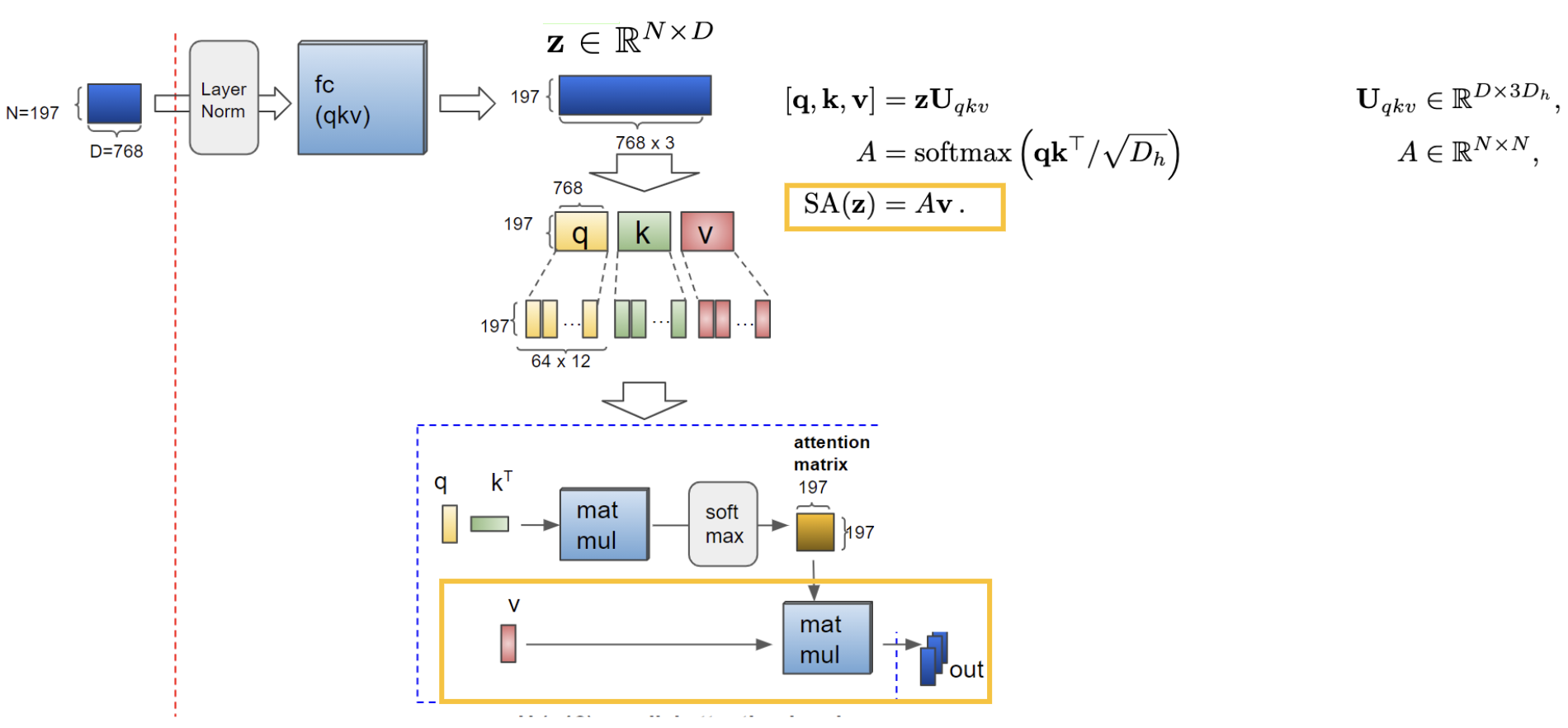
이런 식으로 되는데, 우리가 일단 위에서 patch embedding을 통해 얻은 z를 각 head의 q, k, v로 주고 내적한 후 scale과 softmax를 거쳐서 나온 attention score의 값을 다시 value에 곱하여 attention value을 구해준다.
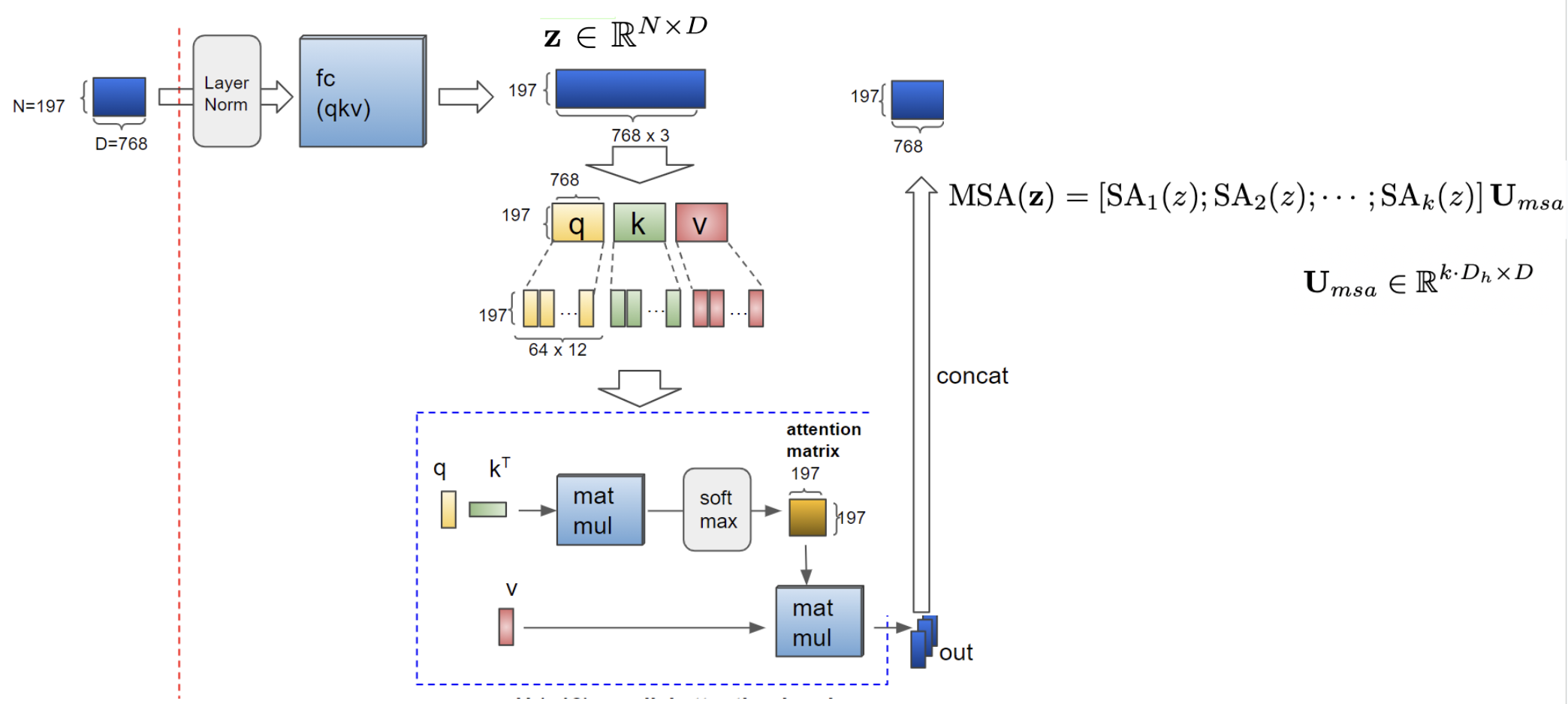
이제 나눠진 head들의 결과물들을 concat으로 묶고 마지막에 Linear Layer를 지나 attention의 output으로 나온다.

그리고 그걸 다시 residual connection해주고 layer normalization을 한 후 MLP에 넣어서 다시 한번 residual connection을 해주면 결과가 나온다. 여기서 MLP는 2개의 Layer와 GELU activation을 갖음.
그리고 Transformer Layer을 L번 만큼 반복하여 최종 결과를 도출한다.
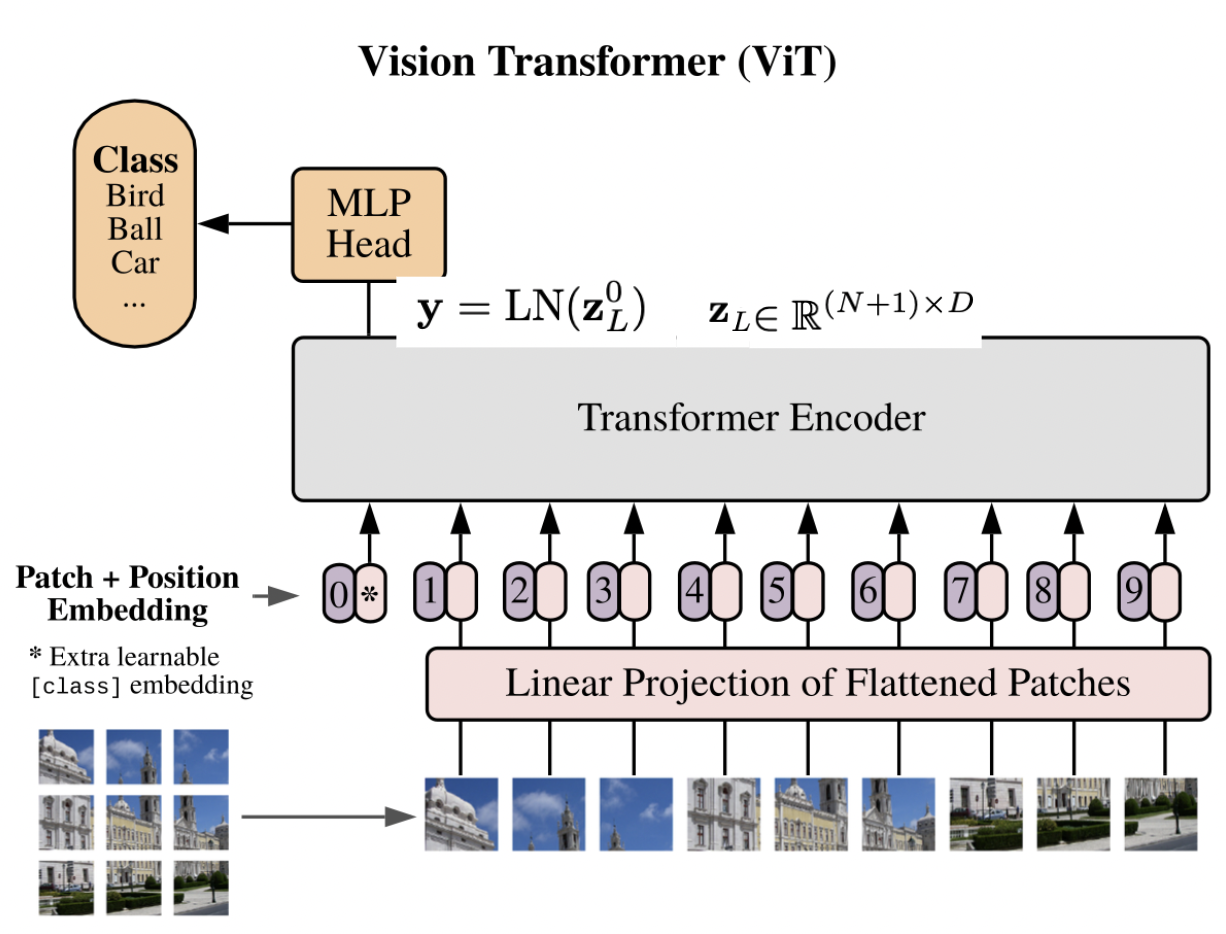
결국 마지막 L layer에서 나온 에서 첫번째 부분 즉 class 정보를 담는 부분()을 Multi Layer Perceptron을 통해 class probability를 계산한다.
