
1. Base Hook 명세 보기
여기서 잠깐!
@classmethod란?
원래 클래스를 import해오면, 해당 클래스를 인스턴스화하여 객체를 만들고 객체의 메서드를 사용하는 것이 일반적이다.
그런데, 클래스메서드로 정의가 되면, 객체를 만들지 않고도 클래스.클래스메서드를 사용할 수 있다.
import BaseHook
a = BaseHook.get_connections(conn_id)
type(a) # List이런식으로 사용이 가능하다.
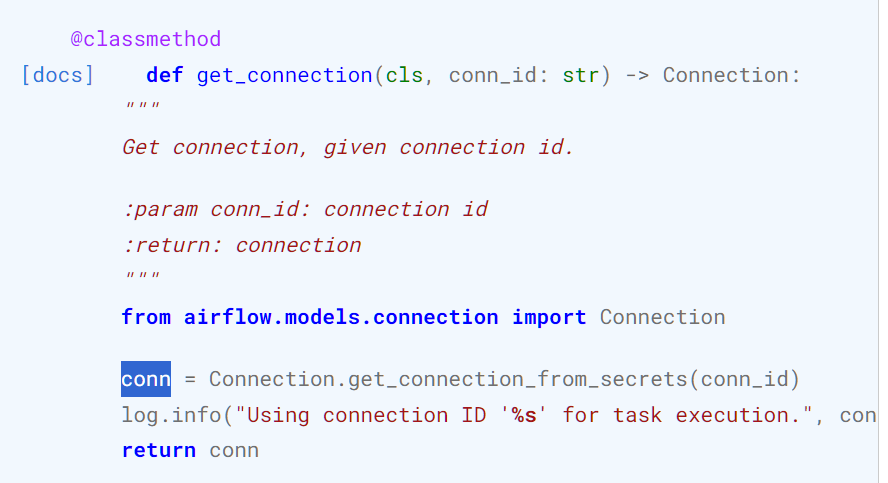
위에 있는 get_connections는 사라질 거라고 하니 안봐도 될 것같다.

BaseHook을 상속할 시 반드시 get_conn()을 오버라이딩 해줘야한다.
2. Custom Hook개발
- To do List
(1) get_conn 메서드 구현하기
-> DB와의 연결 섹션 객체인 conn을 리턴하도록 구현한다.
(이때, Airflow에 등록한 Connection 정보를 담은 conn이 아니다!)
-> BaseHook의 추상 메서드, 자식 클래스에서 구현이 필요하다.
(2) bulk_load 메서드를 구현한다.
- CustomHook 오버라이딩
from typing import Any
from airflow.hooks.base import BaseHook
import psycopg2
import pandas as pd
class CustomPostgresHook(BaseHook):
def __init__(self, postgres_conn_id, **kwargs):
self.postgres_conn_id = postgres_conn_id
# 반드시 오버라이딩 해줘야 하는 것
def get_conn(self):
# get_connection은 @classmethod
airflow_conn = BaseHook.get_connection(self.postgres_conn_id)
self.host = airflow_conn.host
self.user = airflow_conn.login
self.password = airflow_conn.password
self.dbname = airflow_conn.schema
self.port = airflow_conn.port
# db연결해서 session객체 리턴
self.postgres_conn = psycopg2.connect(
host=self.host, user=self.user, password=self.password, dbname=self.dbname, port=self.port
)
return self.postgres_conn
def bulk_load(self, table_name, file_name, delimiter:str, is_header:bool, is_replace:bool):
from sqlalchemy import create_engine
self.log.info("적재 대상파일: " + file_name)
self.log.info("테이블: " + table_name)
# 세션 객체 가져온다.
self.get_conn()
header = 0 if is_header else None
if_exists = 'replace' if is_replace else 'append'
file_df = pd.read_csv(file_name, header=header, delimiter=delimiter)
for col in file_df.columns:
try:
file_df[col] = file_df[col].str.replace('\r\n', '')
self.log.info(f'{table_name}.{col}: 개행문자 제거')
except:
continue
self.log.info("적재 건수: " + str(len(file_df)))
uri = f'postgresql://{self.user}:{self.password}@{self.host}/{self.dbname}'
engine = create_engine(uri)
file_df.to_sql(name=table_name,
con=engine,
schema='public',
if_exists=if_exists,
index=False)- Dag작성
from airflow import DAG
import pendulum
from airflow.operators.python import PythonOperator
from hooks.custom_postgres_hook import CustomPostgresHook
with DAG(
dag_id="dags_python_with_custom_hook_bulk_load",
start_date=pendulum.datetime(2023, 8, 1, tz="Asia/Seoul"),
schedule="0 7 * * *",
catchup=False
) as dag:
def insert_postgres(postgres_conn_id, tbl_nm, file_nm, **kwargs):
custom_postgres_hook = CustomPostgresHook(postgres_conn_id=postgres_conn_id)
custom_postgres_hook.bulk_load(
table_name=tbl_nm,
file_name=file_nm,
delimiter=',',
is_header=True,
is_replace=True
)
insert_postgres = PythonOperator(
task_id = "insert_postgres",
python_callable=insert_postgres,
op_kwargs={
'postgres_conn_id' : 'conn-db-postgres-custom',
'tbl_nm': 'test02',
'file_nm': '/opt/airflow/files/tbElectricCharging/{{data_interval_end.in_timezone("Asia/Seoul") | ds_nodash}}/tb_seoul_fast_charger_status.csv'
}
)- airflow에서 확인
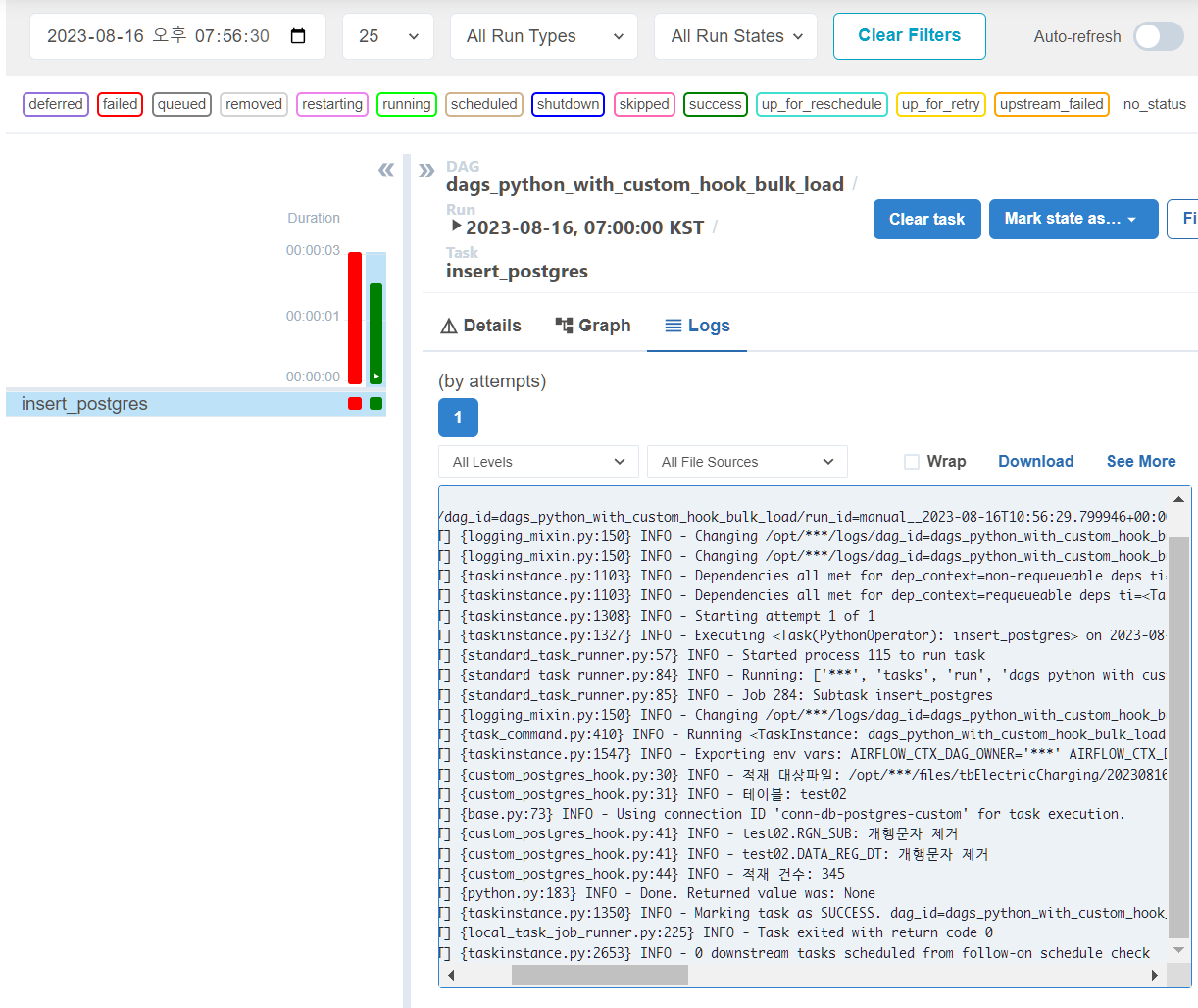
{custom_postgres_hook.py:30} INFO - 적재 대상파일: /opt/***/files/tbElectricCharging/20230816/tb_seoul_fast_charger_status.csv
[2023-08-16, 19:56:31 KST] {custom_postgres_hook.py:31} INFO - 테이블: test02
[2023-08-16, 19:56:31 KST] {base.py:73} INFO - Using connection ID 'conn-db-postgres-custom' for task execution.
[2023-08-16, 19:56:31 KST] {custom_postgres_hook.py:41} INFO - test02.RGN_SUB: 개행문자 제거
[2023-08-16, 19:56:31 KST] {custom_postgres_hook.py:41} INFO - test02.DATA_REG_DT: 개행문자 제거
[2023-08-16, 19:56:31 KST] {custom_postgres_hook.py:44} INFO - 적재 건수: 345
[2023-08-16, 19:56:31 KST] {python.py:183} INFO - Done. Returned value was: None
[2023-08-16, 19:56:31 KST] {taskinstance.py:1350} INFO - Marking task as SUCCESS. dag_id=dags_python_with_custom_hook_bulk_load, task_id=insert_postgres, execution_date=20230816T105629, start_date=20230816T105631, end_date=20230816T105631만세! 드디어 성공했다.
역시 pandas는 최고다.
그리고 db도 확인해보자
- test02테이블 데이터 확인
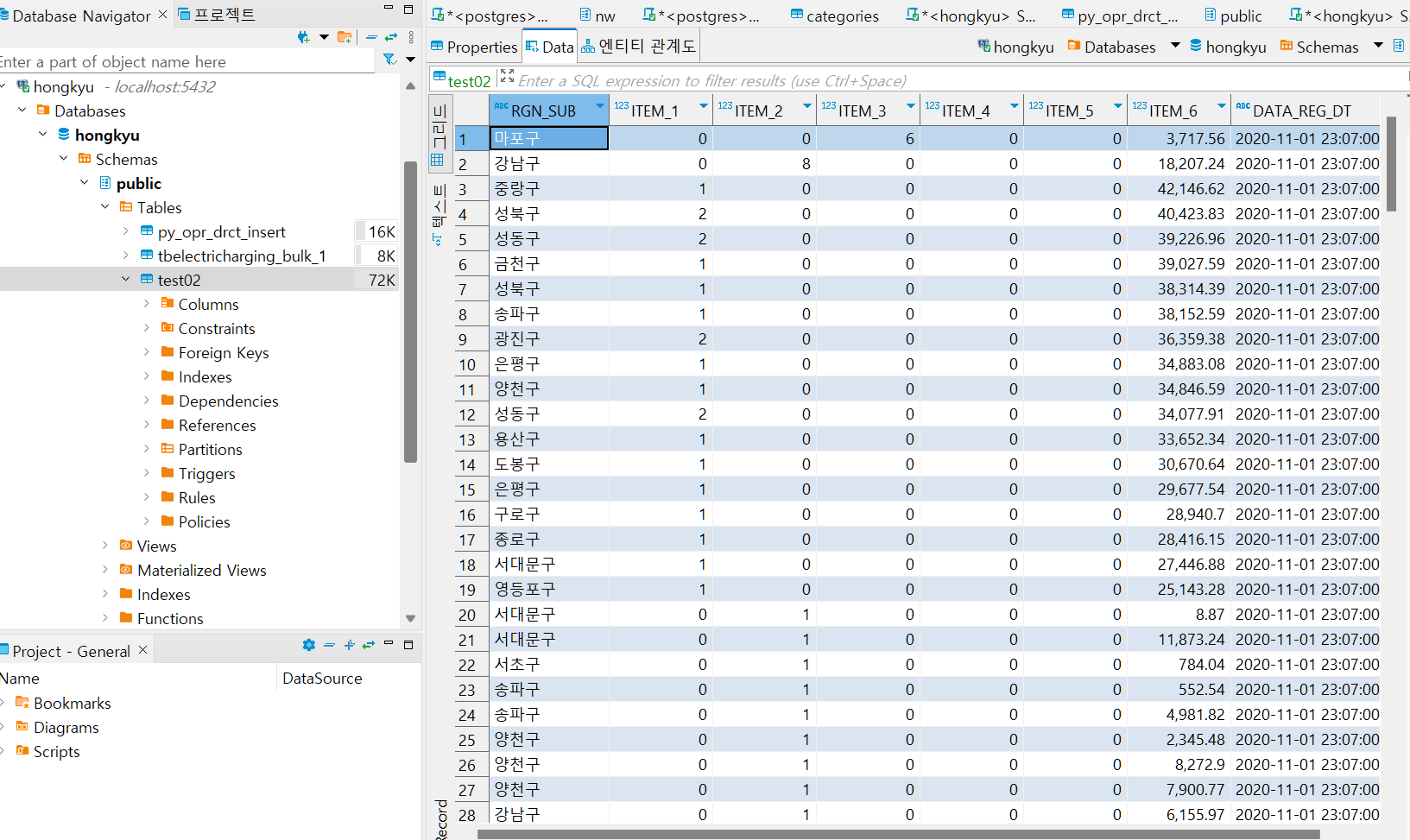
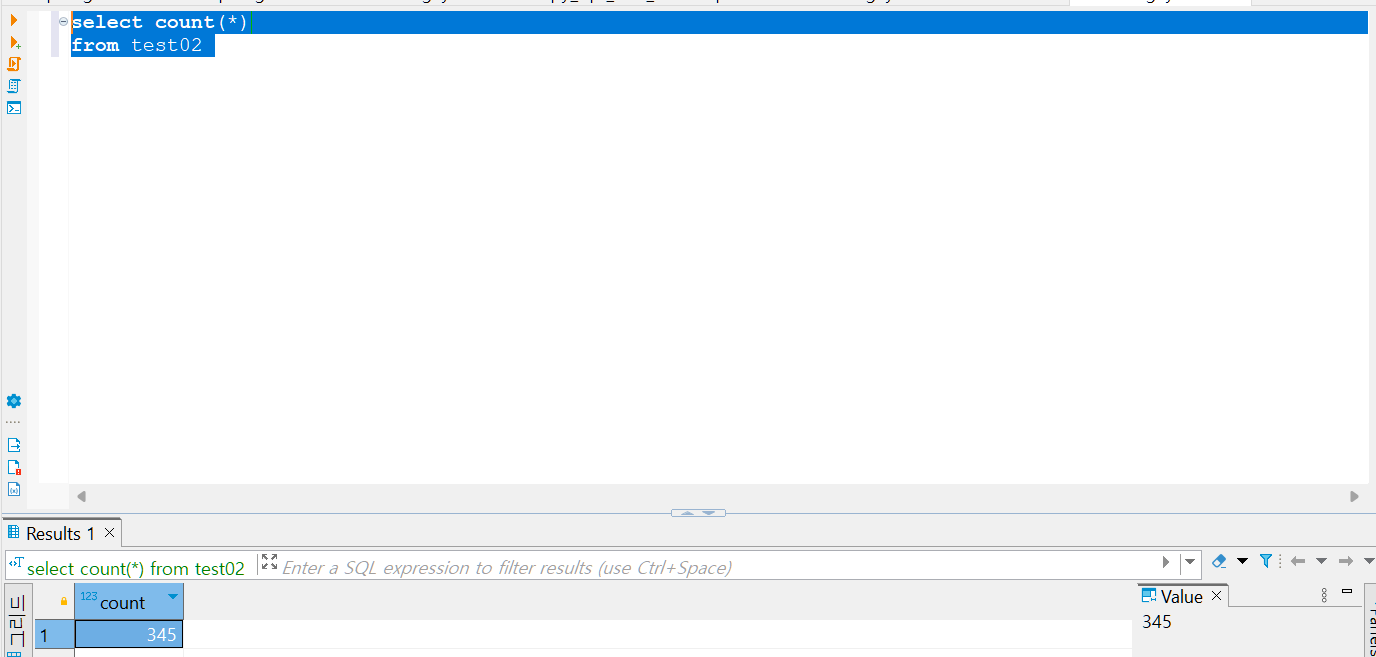
우와! 드디어 db에 데이터가 적재되었다.
매일 345개의 데이터가 들어온다.

공대생의 코딩 정복기