
1. Postgres Hook 명세보기
airflow.providers.postgres 명세보기

tab으로 delimeter가 설정된 파일을 데이터베이스 테이블로 로드하는 기능을 제공한다.
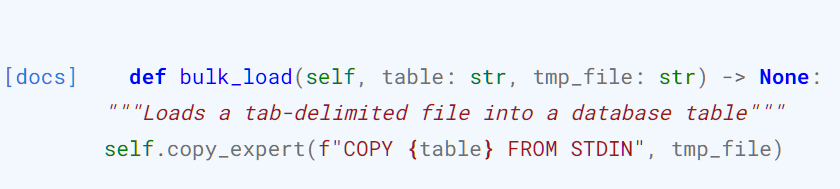
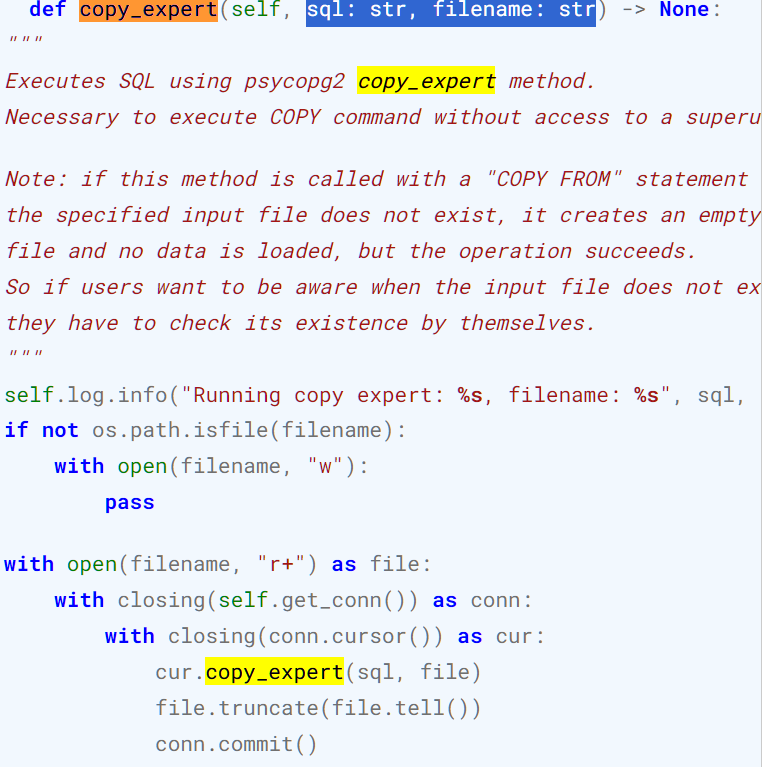
psycopg2 가 가지고 있는 copy_expert method를 postgresql cursor가 실행하고 있음을 알 수 있다. 그럼 psycopg2의 copy_expert는 뭘까?

즉, copy_expert() 메서드는 PostgreSQL의 COPY 명령어를 사용하여 데이터를 파일과 데이터베이스 테이블 간에 복사할 때 사용되는 것을 알 수 있다.
이때, 파라미터는 총 3개인데, 2개는 required이다. (또한, bulk_load는 메서드는 아까 sql, file 두 개의 파라미터만 받는다)
1. sql: 수행할 'copy'문이 포함되어 있어야 한다.
copy table To STDOUT는 데이터 베이스 테이블의 내용을 파일로 내보내는 명령을 나타낸다.copy table FROM STDOUT을 쓰면 파일의 내용을 테이블로 가져온다.
file: 데이터를 읽거나 쓸 파일 객체가 전달된다.
2. Bulk_load 하기
csv파일을 가져오기 위해 이전에 저장해두었던 파일을 가져오겠다.
- 서울시 전기차 충전소 정보(csv파일)
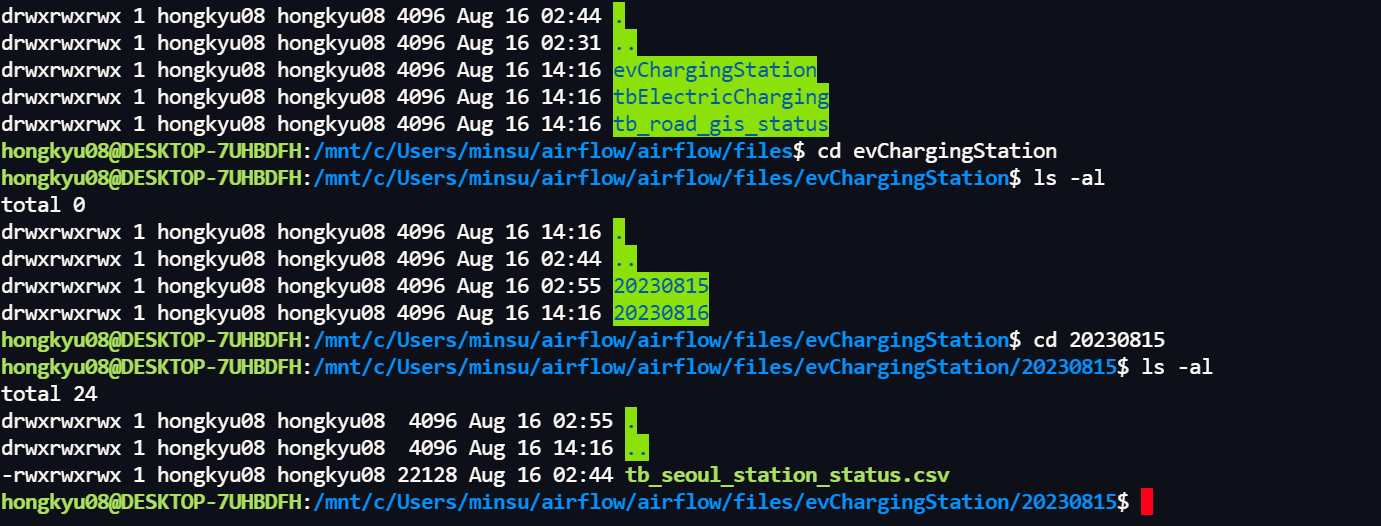
- 해당 csv파일 경로는
- /opt/airflow/files/evChargingStation/{{data_interval_end.in_timezone("Asia/Seoul") | ds_nodash}} 에 저장되어있다.
from airflow import DAG
import pendulum
from airflow.operators.python import PythonOperator
from airflow.providers.postgres.hooks.postgres import PostgresHook
with DAG(
dag_id="dags_python_with_postgres_hook_bulk_insert",
start_date=pendulum.datetime(2023, 8, 1, tz="Asia/Seoul"),
schedule="0 7 * * *",
catchup=False
) as dag:
def insert_postgres(postgres_conn_id, tbl_nm, file_nm, **kwargs):
postgres_hook = PostgresHook(postgres_conn_id)
# table이름과 file이름을 받는다.
postgres_hook.bulk_load(tbl_nm, file_nm)
insert_postgres = PythonOperator(
task_id = 'insert_postgres',
python_callable=insert_postgres,
op_kwargs={
'postgres_conn_id': 'conn-db-postgres-custom',
'tbl_nm': 'evChargingStation_bulk1',
'file_nm': '/opt/airflow/files/evChargingStation/{{data_interval_end.in_timezone("Asia/Seoul") | ds_nodash}}/tb_seoul_station_status.csv'
}
)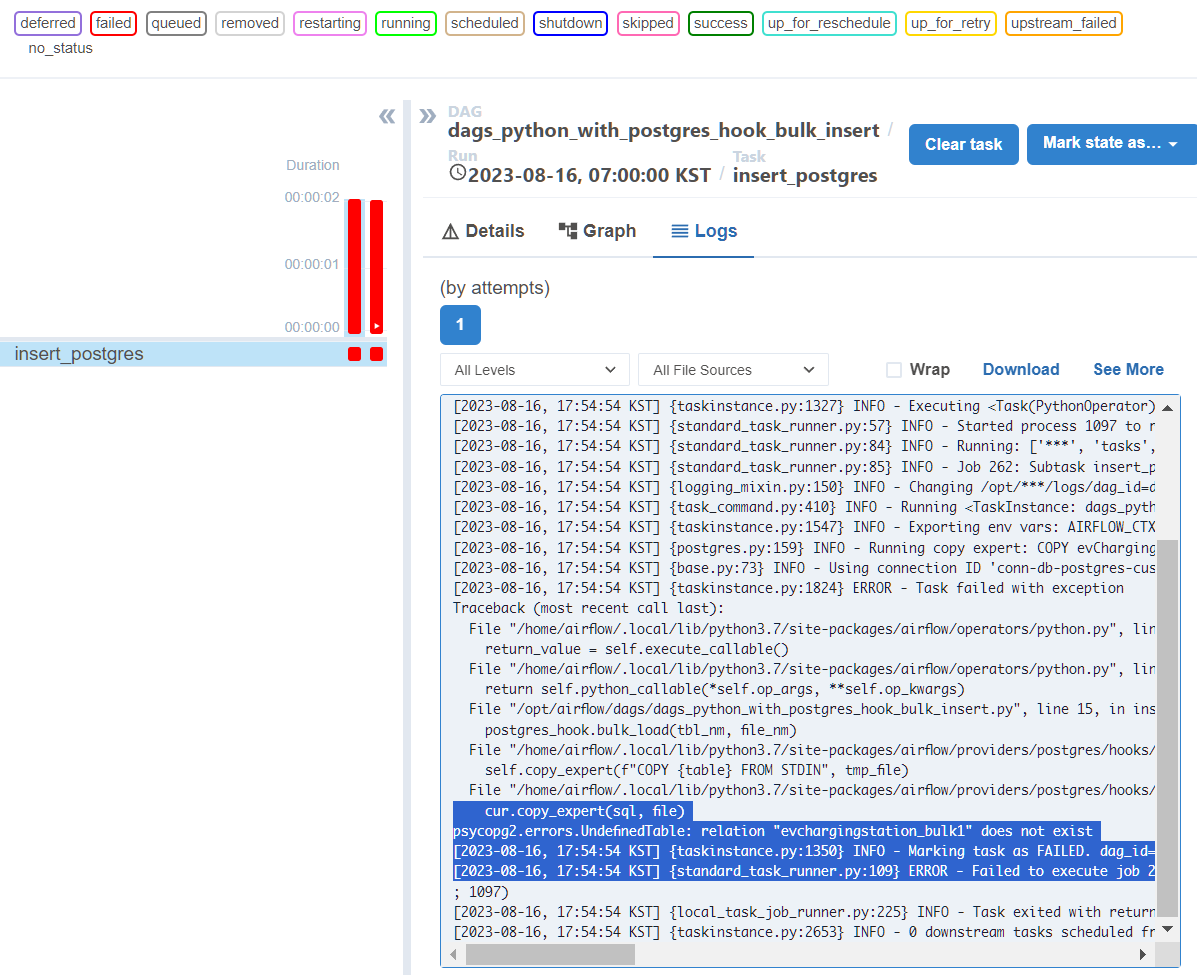
에러 사항을 들여다보면 다음과 같다.
cur.copy_expert(sql, file)
psycopg2.errors.UndefinedTable: relation "evchargingstation_bulk1" does not exist
[2023-08-16, 17:54:54 KST] {taskinstance.py:1350} INFO - Marking task as FAILED. dag_id=dags_python_with_postgres_hook_bulk_insert, task_id=insert_postgres, execution_date=20230814T220000, start_date=20230816T085454, end_date=20230816T085454
[2023-08-16, 17:54:54 KST] {standard_task_runner.py:109} ERROR - Failed to execute job 262 for task insert_postgres (relation "evchargingstation_bulk1" does not exist
테이블이 존재하지 않아서 에러가 난다고 한다. 테이블을 만들어줘야 하나보다.
일단, 테이블 구조를 살펴보기 위해 해당 파일로 이동해서 칼럼을 살펴보자.

확인해보니 하나같이 다 text필드이다.
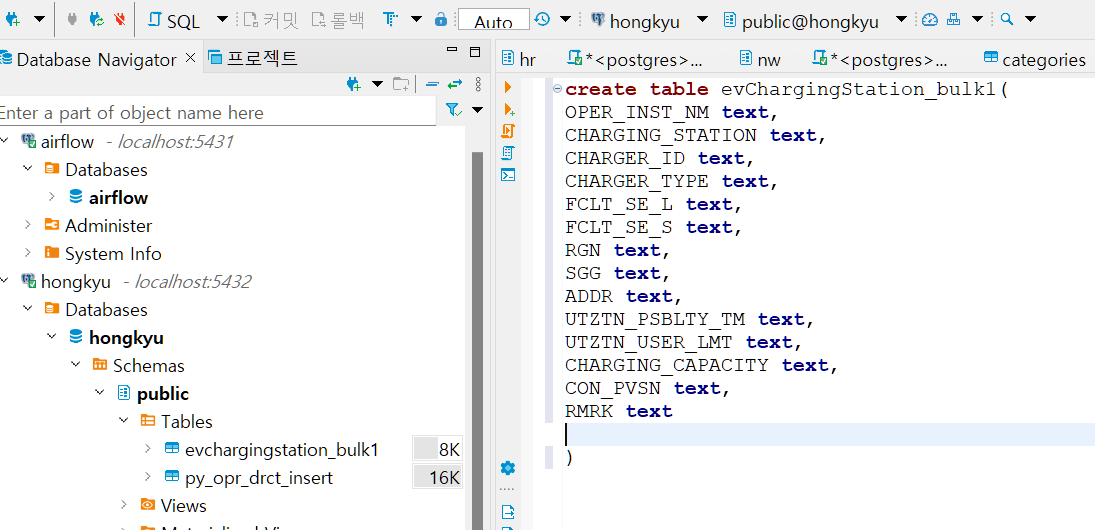
column은 다음과 같다.
OPER_INST_NM,CHARGING_STATION,CHARGER_ID,CHARGER_TYPE,FCLT_SE_L,FCLT_SE_S,RGN,SGG,ADDR,UTZTN_PSBLTY_TM,UTZTN_USER_LMT,CHARGING_CAPACITY,CON_PVSN,RMRK
해당 테이블 구조 evChargingStation_bulk1 테이블을 만들어주겠다.
추가) 해당 데이터가 결측치도 엄청 많고 누락된 값이 많아서, 테이블을 만들었는데 에러가 계속 나서, 다른 걸로 바꾸어주었다.
- 서울시 급속 충전기 정보이다.
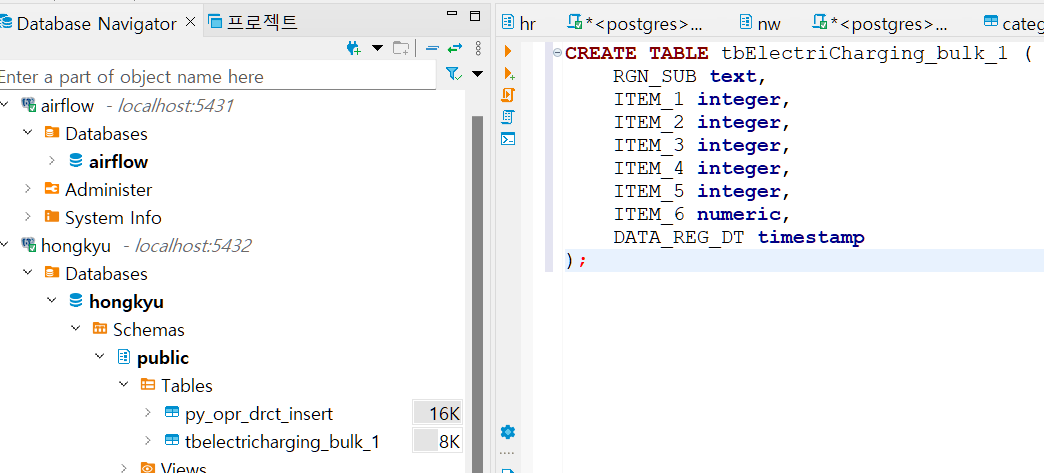
음... 특수문자로 인해서 계속 에러가 난다. 하나하나 고치는게 너무 노가다이고, 데이터도 너무 많아서 이걸 다 언제 고치나 싶다..
3. Bulk_load의 문제점 & 해결방안
직접 실습을 해보니까 특히 raw데이터를 받아올경우, 데이터 구조가 뒤죽박죽 섞여서 제대로 파싱이 되지 않는 문제점이 있었다. (원래는 더 이상했는데, 최대한 insert 로 수작업으로 수정을 해줬다)
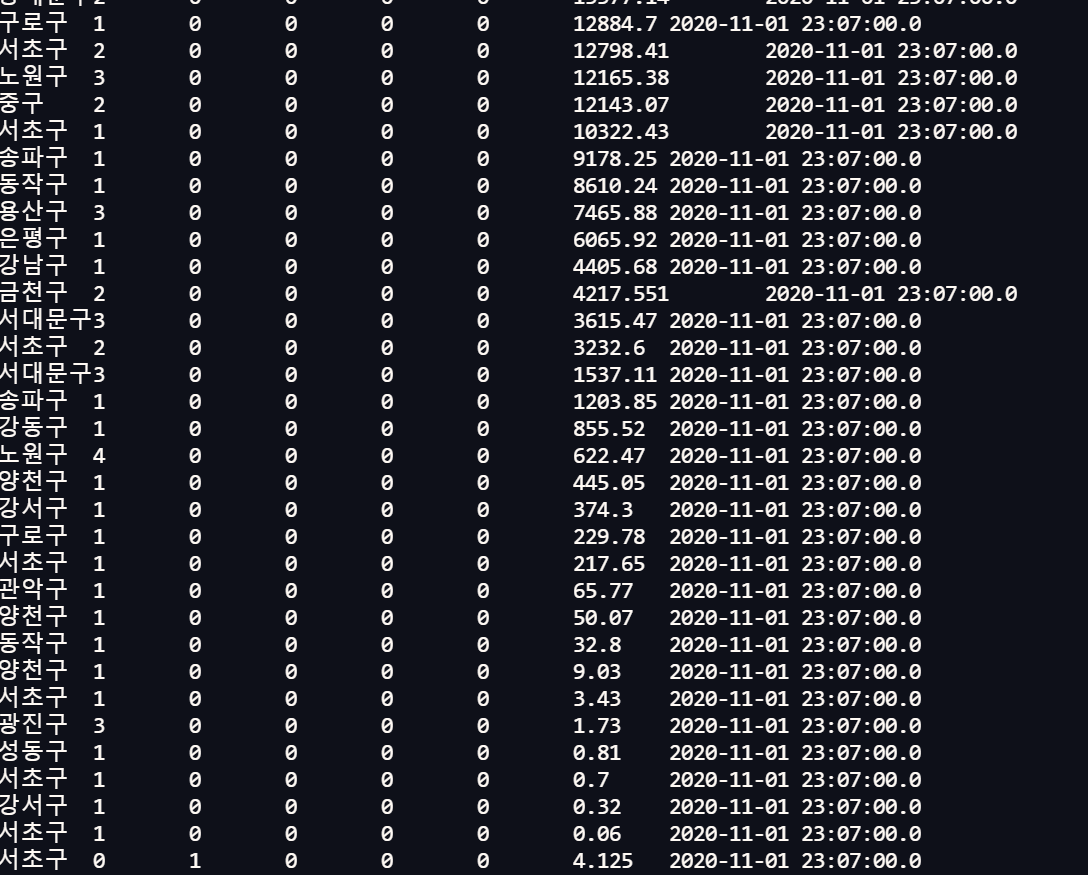
데이터 구조가 어긋나면 계속해서 에러가 난다.
- 문제점
(1) Load 가능한 Delimiter는 Tab으로 고정되어있다.
(2) Header까지 포함해서 업로드가 된다.
(3) 특수문자로 인해 파싱이 안될 경우 에러가 발생한다.
- 개선방안
(1) Custom Hook을 만들어서 Delimiter유형을 입력받게 하고
(2) Header 여부를 선택하게끔 하며
(3) 특수문자를 제거하는 로직을 추가후
(4) sqlalchemy를 이용하여 Load한다면? 그리고 테이블을 생성하면서 업로드까지 할 수 있다면?
