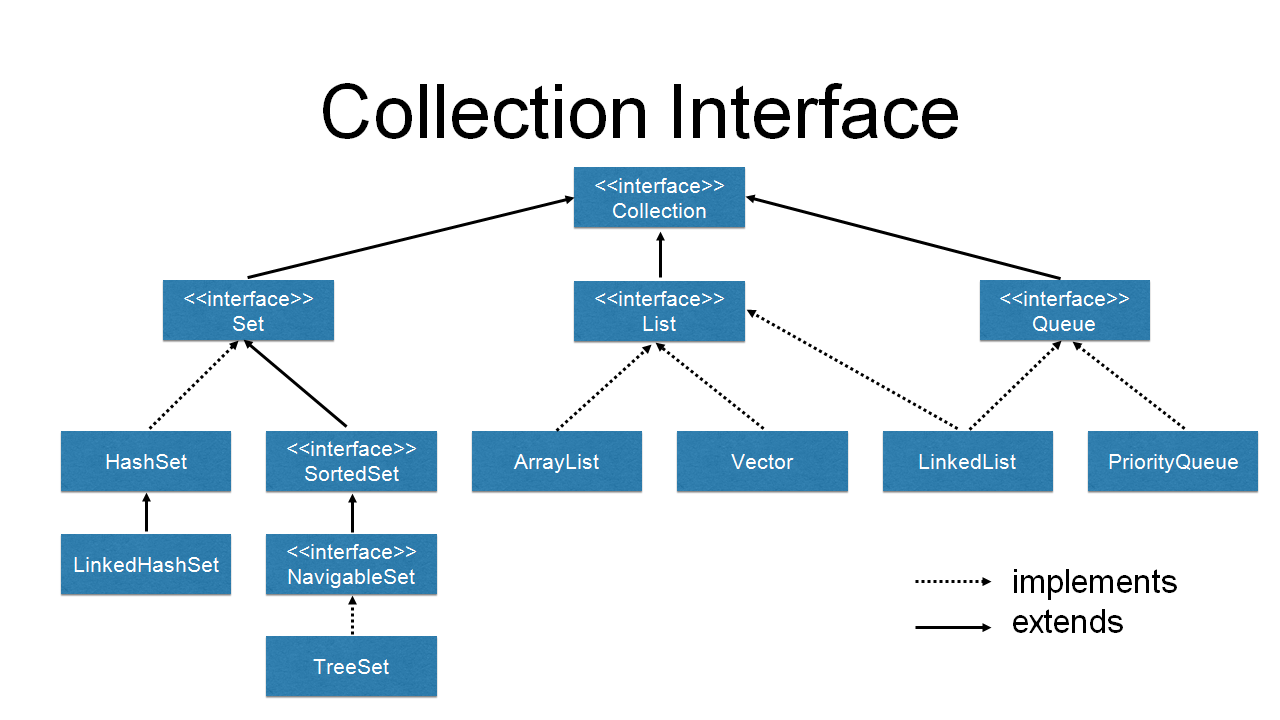
컬렉션(Collection) : 여러 객체(데이터)를 모아 놓은 것을 의미
프레임 워크
- 표준화,정형화된 체계적인 프로그래밍 방식
컬렉션 프레임 워크
- 컬렉션(다수의 객체)을 다루기 위한 표준화된 프로그래밍 방식
- 컬렉션을 쉽고 편리하게 다룰 수 있는 다양한 클래스를 제공
컬렉션 클래스
- 다수의 데이터를 저장할 수 있는 클래스
컬렉션 프레임워크의 핵심 인터페이스

컬렉션이 가지는 인터페이스 및 구현 클래스
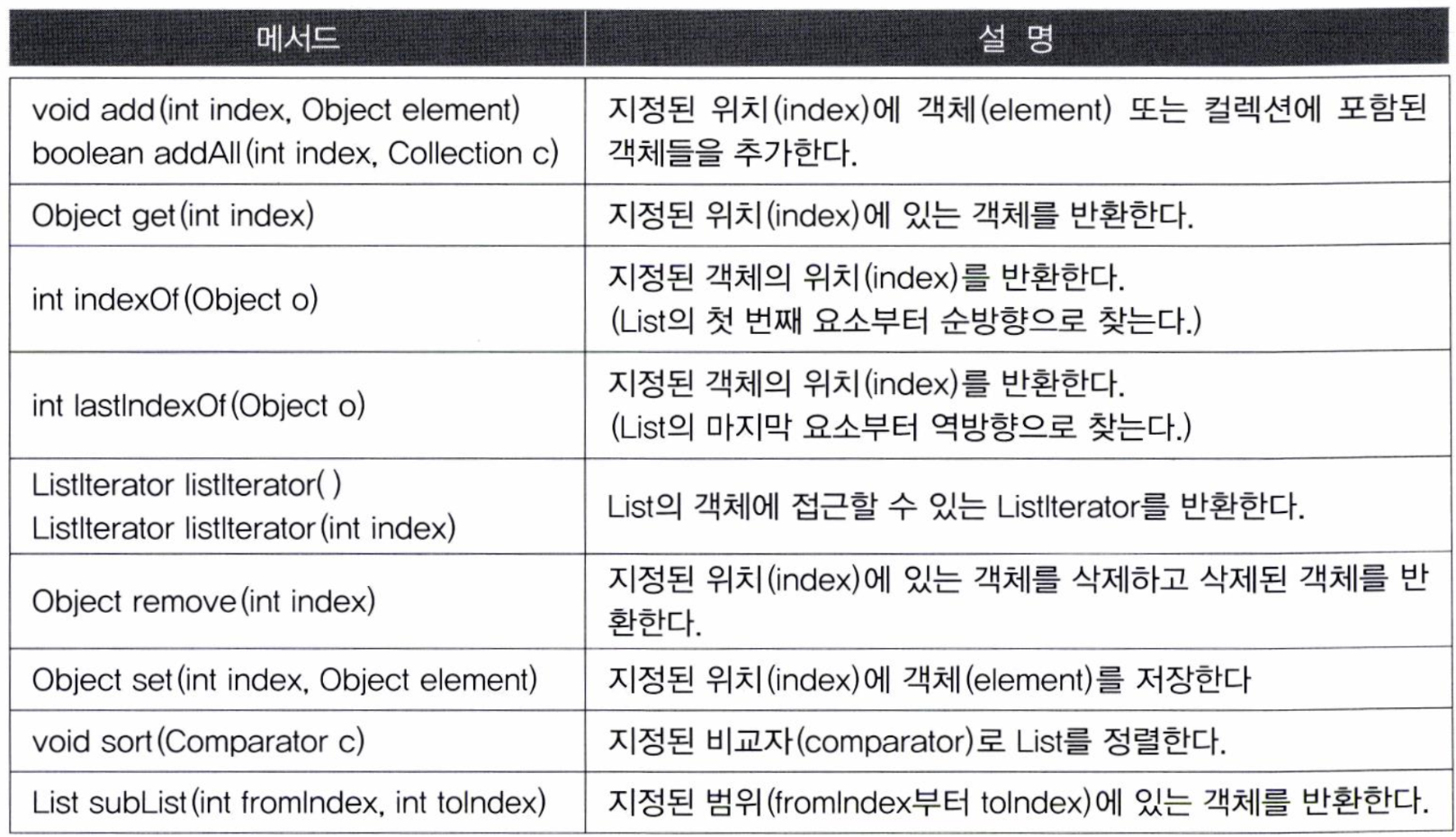
인터페이스1. List
- 순서가 있는 데이터의 집합, 데이터의 중복 허용 (ex : 대기자 목록)
- 구현 클래스 :
ArrayList,LinkedList,Stack등
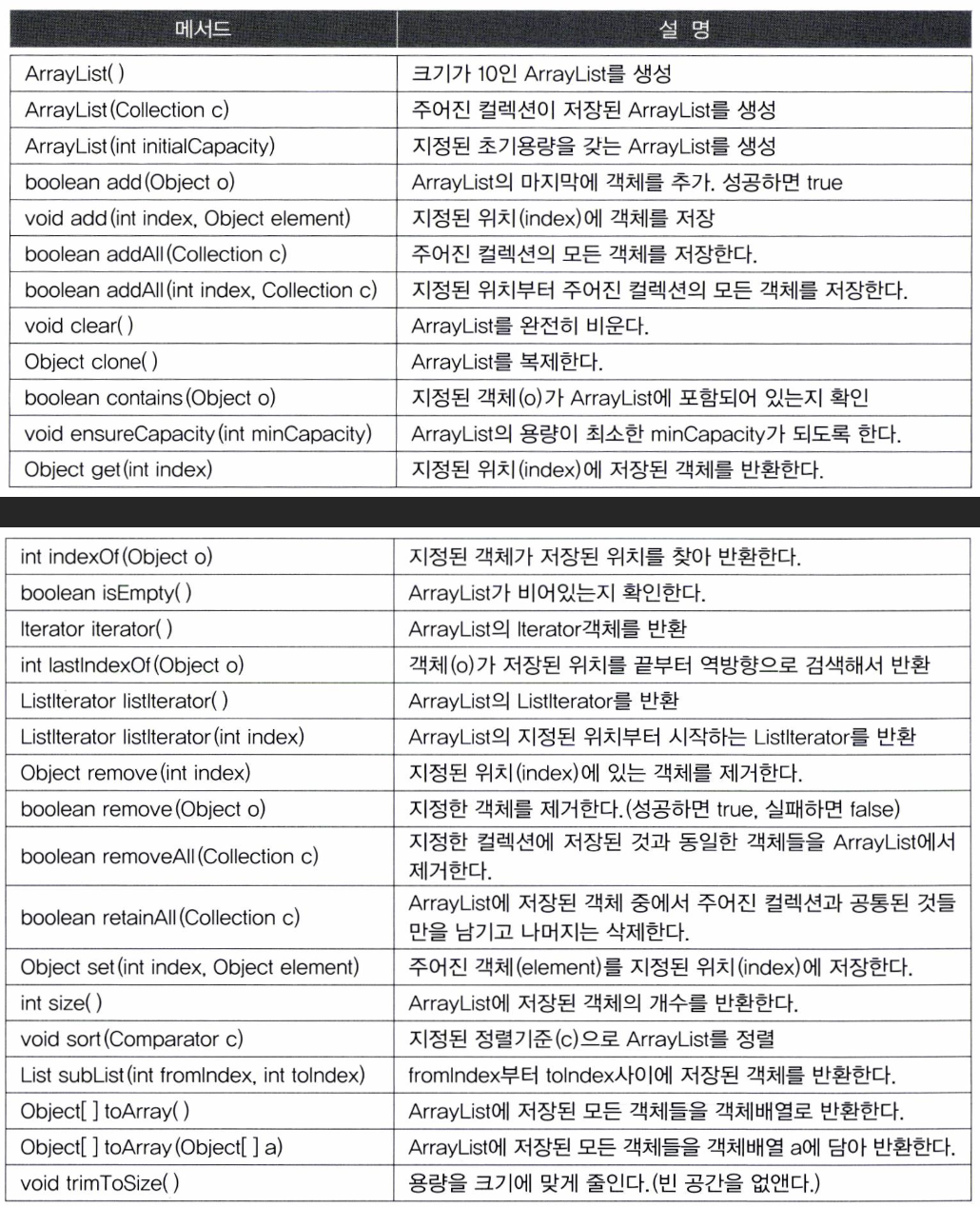
< List > 구현 클래스 1 - ArrayList
- List 인터페이스를 구현한다
- 저장 순서가 유지되고 중복 허용
- 데이터의 저장공간으로 배열을 사용한다 (배열 기반)
- 기본 크기는 10이지만 원소가 늘어나면 더 큰 배열에 옮긴다
- 인덱스로 조회가 가능 => 인덱스만 알면 해당 데이터를 빠르게 조회 가능
- 삽입,삭제시 그 뒤에 있는 데이터를 뒤로 밀거나 앞으로 당겨야 하기 때문에 느림(O)(N))
- ArrayList는 객체만 저장 가능
- auto Boxing에 의해 기본형이 참조형으로 자동 변환 되어서 저장도 된다
배열의 장단점
- 장점 : 배열은 구조가 간단하고 데이터를 읽는데 걸리는 시간(접근 시간,access time)이 짧다
- 단점 :
- 크기를 변경할 수 없다.
- 크기를 변경해야 하는 경우 새로운 배열을 생성 후 데이터를 복사해야함
- 크기 변경을 위해 충분히 큰 배열을 생성하면, 메모리가 낭비됨
- 비순차적인 데이터의 추가 또는 삭제에 시간이 많이 걸린다
- 데이터를 추가하거나 삭제하기 위해, 다른 데이터를 옮겨야 함
- 그러나 순차적인 데이터 추가(끝에 추가)와 삭제(끝부터 삭제)는 빠르다
< List > 구현 클래스 2 - LinkedList (배열의 단점을 보완!)
- 배열과 달리
LinkedList는 불연속적으로 존재하는 데이터를 연결(link) - 노드와 포인터를 이용하여 만든 리스트
- 특정 원소를 조회하는 경우 첫 노드부터 순회해야 하기 때문에
ArrayList보다 느리다 - 포인터로 각각 노드들을 연결하고 있으므로,
삽입/삭제가 빠르다- 단순히 기존 포인터를 끊고 새로운 노드에 연결하면 되기 때문
- 그러나 중간에 데이터를
삽입/삭제할 경우 그 데이터까지 순차적으로 조회해야 하기때문에 O(N)의 시간복잡도를 가진다
이처럼 조회시에는
ArrayList가 우위에 있지만,
삽입/삭제 시에는LinkedList가 뛰어난 성능을 보여준다.소량의 데이터를 가지고 사용할 때는 사실 큰 차이가 없지만,
정적인 데이터를 활용하면서 조회가 빈번하다면ArrayList를 사용하는 것이 좋고,
동적으로 추가/삭제 요구사항이 빈번하다면LinkedList를 사용하는 것이 좋다.
✚ Queue
- 클래스로 구현된
stack과는 달리 자바에서 큐 메모리 구조는 별도의 인터페이스 형태로 제공한다. - 선입선출(FIFO) 형태이며, 하위 인터페이스로 Deque 등이 있고 구현한 클래스로
LinkedList등이 있다.
인터페이스2. < Set >
- 순서를 유지하지 않는 데이터의 집합, 데이터 중복 허용X (ex : 양의 정수집합, 소수의 집합...)
- 구현 클래스 :
HashSet,TreeSet등 - 컬렉션 인터페이스를 상속하고 있기 때문에 컬렉션의 메서드 기능을 모두 가지고 있다
< Set > 구현 클래스 1 - HashSet
- Set 인터페이스를 구현한 대표적인 컬렉션 클래스
- 순서X,중복X
- 순서를 유지하려면
LinkedHashSet클래스를 사용하면 된다 - 객체를 저장하기 전에 기존에 같은 객체가 있는지 확인
- 같은 객체가 없으면 저장, 있으면 저장하지 않는다
public class Ex {
public static void main(String[] args) {
Set<String> hashSet = new HashSet<>();
hashSet.add("하나");
hashSet.add("둘");
hashSet.add("셋");
System.out.println(hashSet);
hashSet.add("넷");
hashSet.add("다섯");
System.out.println(hashSet);
}
}
< Set > 구현 클래스 2 - LinkedHashSet
- 중복은 허용하지 않지만, 순서를 가진다
public class Ex {
public static void main(String[] args) {
Set<String> hashSet = new LinkedHashSet<>();
hashSet.add("하나");
hashSet.add("둘");
hashSet.add("셋");
System.out.println(hashSet);
hashSet.add("넷");
hashSet.add("다섯");
System.out.println(hashSet);
}
}
< Set > 구현 클래스 3 - TreeSet
- 범위 검색과 정렬에 유리한 컬렉션 클래스
- 중복은 허용하지 않고, 순서를 가지지 않는다. 그러나 정렬이 되어있다
HashSet보다 데이터 추가, 삭제에 시간이 더 걸린다- 이진트리를 기반으로 한 Set 컬렉션
인터페이스3. < Map >
- 키(key)와 값(value)의 쌍으로 이루어진 데이터의 집합 (ex : 사전,지역번호,ID & PW)
- 순서는 유지되지 않으며, 키는 중복을 허용하지 않고, 값은 중복을 허용
- 구현 클래스 :
HashMap(LinkedHashMap : 순서가 있는 hashMap) ,TreeMap,HashTable
< Map > 구현 클래스 1 - HashMap
- Map 인터페이스를 구현. 데이터를 키와 값의 쌍으로 저장
- 순서는 기억하지 않으며 key는 중복 불가능, value는 중복 허용
- key와 value에
null허용 - 동기화를 보장 하지 않는다
public class Ex {
public static void main(String[] args) {
Map<String, String> hashMap = new HashMap<>();
hashMap.put("하나", "one");
hashMap.put("둘", "two");
hashMap.put("셋", "three");
hashMap.put("셋_셋", "three"); // key는 중복X value는 중복 가능
System.out.println(hashMap);
}
}
< Map > 구현 클래스 2 - LinkedHashMap
- HashMap에서 순서를 보장 받고싶을 때 가지는 Map
public class Ex {
public static void main(String[] args) {
Map<String, String> hashMap = new LinkedHashMap<>();
hashMap.put("하나", "one");
hashMap.put("둘", "two");
hashMap.put("셋", "three");
hashMap.put("셋_셋", "three");
System.out.println(hashMap);
}
}

걍 하자 저스트 뚜잇