2D Matryoshka Sentence Embedding
2D Matryoshka Sentence Embeddings (2024)
Xianming Li, Zongxi Li, Jing Li, Haoran Xie, Qing Li
지난 포스트에서 Matryoshka Embedding에 대한 소개가 있었다. 이후 관련 논문을 찾아봤을 때 파급력에 비해 Variant가 하나밖에 없어서 그에 대한 소개를 진행하고자 한다.
Matryoshka Sentence Embedding (MSE)라고 줄여 적는다.
MSE를 통해 (약간 낮지만) 유사한 성능을 가질 수 있는 문장 임베딩을 얻을 수 있게 되었으며, 14배 더 줄어든 임베딩을 통해서도 Downstream Task에서 속도와 성능을 모두 향상 시킬 수 있는 임베딩을 만들 수 있게 되었다. 하지만 MSE는 모든 Sentence Transformer Embedding과 같게 ‘Last Transformer Layer’를 사용하는데 이는 Efficiency의 다양한 면에서 일부를 놓치고 있는 것이며 이는 Inference Speed이다.
Forward Pass를 많이 사용하는 MSE 특성 상 Burden이 좀 될 수 있다.
(훈련을 할 때도 Back Prop을 위해서 Forward Pass를 해야하는데 결국 차원의 종류 개수가 6개라면 한번의 훈련에 6번 Forward Pass가 필요). BERT-base를 Ang1E Loss를 사용해서 훈련시켰을 때, intermediate layer에서 성능 하락을 목도하였는데, 모든 Layer에서 좋은 성능을 달성하고자 하는게 2D MSE의 목적이다. 즉, 2D MSE는 Embedding Size 뿐만 아니라 Transformer Layer에 대해서도 MSE가 제대로 훈련될 수 있도록 하는 연구이다.
아래의 그림과 같이 모든 Layer에서 Final Layer와 동일한 결과를 내고자 하는 것이다.
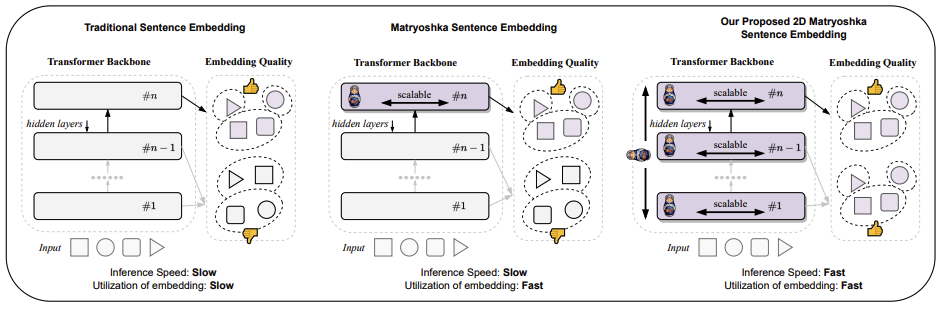
Takeaways
2D MSE의 장점
- Last Layer 뿐 아니라 이전 Layer를 Last Layer처럼 쓸 수 있어서 Full Forward Pass가 필요 없다
- 이는 가용한 컴퓨팅 자원에 따라 PLM 활용 방법을 변화시킬 수 있다
Method
- 기본적인 아이디어는 Last Layer의 Loss가 Last Layer 이전의 Layer들 중 Random Sample한 Layer의 Loss와 같아지게 만드는 것
- Loss 분포를 유사하게 만들기 위해 KL Divergence를 사용
- 즉, Last Layer의 분포를 다른 Non-Last Layer에 Distillation하는 것.
Experiment
baseline
- bert base를 PLM
- Ang1E Loss를 기본 Loss
comparison - Ang1E (Baseline)
- MRL (Matryoshka Representation Learning)
- 2D MSE
Result
- 당연한 말이긴 하지만, Layer가 낮아질수록 더 낮은 성능을 보이는 일반 훈련법에 비해 2DMSE에서는 더 좋은 성능
- 기본적으로 MSE도 Distillation과 같은 모양이지만, 2DMSE는 Layer별 Distillation
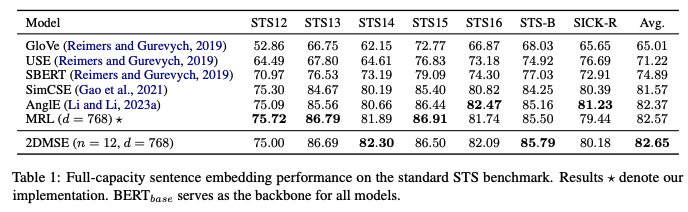
- 768 차원 임베딩의 전체 성능을 비교해봤을 때는 아쉽게도 큰 차이는 없다.
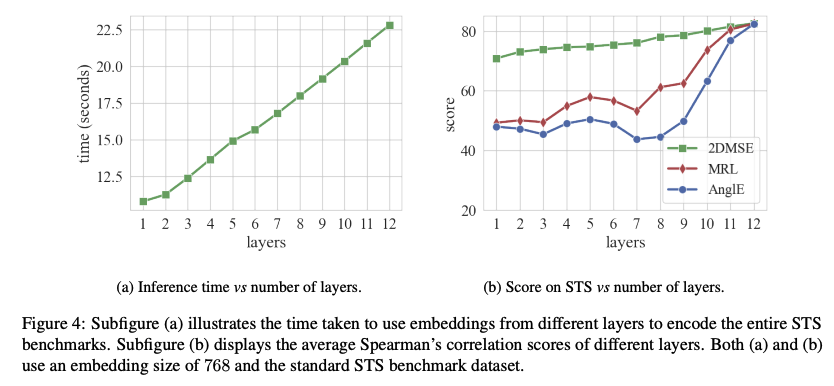
- Inference Time은 당연히 Lower Layer에서 가장 빠르며, 2DMSE와 다른 Baseline과 비교했을 때 성능 하락 폭은 가장 적다.
Contribution
- Inference 속도가 매우 중요하게 필요한 경우에는 더 작은 사이즈의 임베딩과 1번째 Transformer Layers에서는 매우 좋은 활용이 될 수 있다.
- 하지만 Inference 속도 이외에 정확성을 높이는 훈련을 이제 연구해야할 때가 온 것 같다.
