Matryoshka Representation Learning
Matryoshka Representation Learning (Kusupati et al., NeurIPS’22) 논문 리뷰
[근황]
최근 회사 업무로 인해 매우 바쁜 시간들이 지나가고 있다. 그렇다고 뭔가 실력의 향상이 이뤄졌다 라고 말하기엔 애매한 것이, 대부분 의사 결정에 필요한 회의 및 근거 마련에 초점을 두었기 때문이다. 현재 봉착한 문제에 대해 새로운 솔루션을 내는 것보단, 왜 이것이 문제인지를 설명하는 것이었기 때문에, 자료 정리 및 시각화 위주의 업무를 많이 수행한 것 같다. 이번에 정리해보고자 하는 논문은 새로운 솔루션에 대한 갈망에서 찾게된 논문이다.
[선정 배경]
이번에 정리해보고자 하는 논문은 Matryoshka Representation Learning (MRL; 또는 Matryoshka Sentence Embeddings (MSE))이라는 NeurIPS ‘22에 나온 논문이다. 찾게 된 경위는, 자주 사용하는 Sentence Transformers Main 홈페이지에 못보던 탭이 있어서 봤더니, 아예 Matryoshka Embeddings라는 탭이 있어서 읽어보게 되었다. Sentence-Transformers에서 공식적인 Training Method 및 Loss로 포함을 시킨 것을 보아 문장 임베딩 훈련에 있어 중요한 위치에 올라온 듯하다 (Adaptive Layers Tab에 보면 2D-MSE)까지 추가되어, Transformer Layer에 대한 훈련도 포함되어 있다).
항상 논문을 읽고 바로 이해하는 적은 없기 때문에 참고 자료를 소개하고자 한다.
- https://aniketrege.github.io/blog/2024/mrl/
- https://www.sbert.net/examples/training/matryoshka/README.html
- https://ritvik19.medium.com/papers-explained-matryoshka-representation-learning-e7a139f6ad27
- https://huggingface.co/blog/matryoshka
[개요]
Sentence Embedding은 Clustering / Classification 등 다양한 Downstream Task에 활용될 수 있다. 단순히 Huggingface에 있는 모델을 가져다가 사용해도 되지만, NLI / STS Task 같은 Finetuning을 통해 자신의 Domain Dataset에 맞는 모델을 구성할 수 있다.
하지만 문제는, 보통 PLM의 임베딩 사이즈가 768차원에서 속도를 위해 차원 축소를 진행하고자 하면, 어떤 차원이 가장 좋은 성능을 나타내는 지 판단하기 어려운데 이는, 다양한 차원으로 축소한 다음 모든 경우에 대해 평가해야 하기 때문이다.
또한 아쉬운 점은 PCA를 사용할지, UMAP을 사용할지에 따라 결과는 천차만별이기에 따라서, 결과를 분석하기에 난이도가 증가한다.
따라서 MSE는 이를 한번에 진행할 수 있는 방법을 제안하는데, 왜 이름이 마트료시카인지는 결과물을 보면 이해가 된다.
[기법]
기법은 사실 매우 간단하다. 하나의 임베딩에 대해 여러 차원으로 잘라서 Downstream Task를 수행한 뒤, Loss를 모두 합치는 방식으로 진행된다.
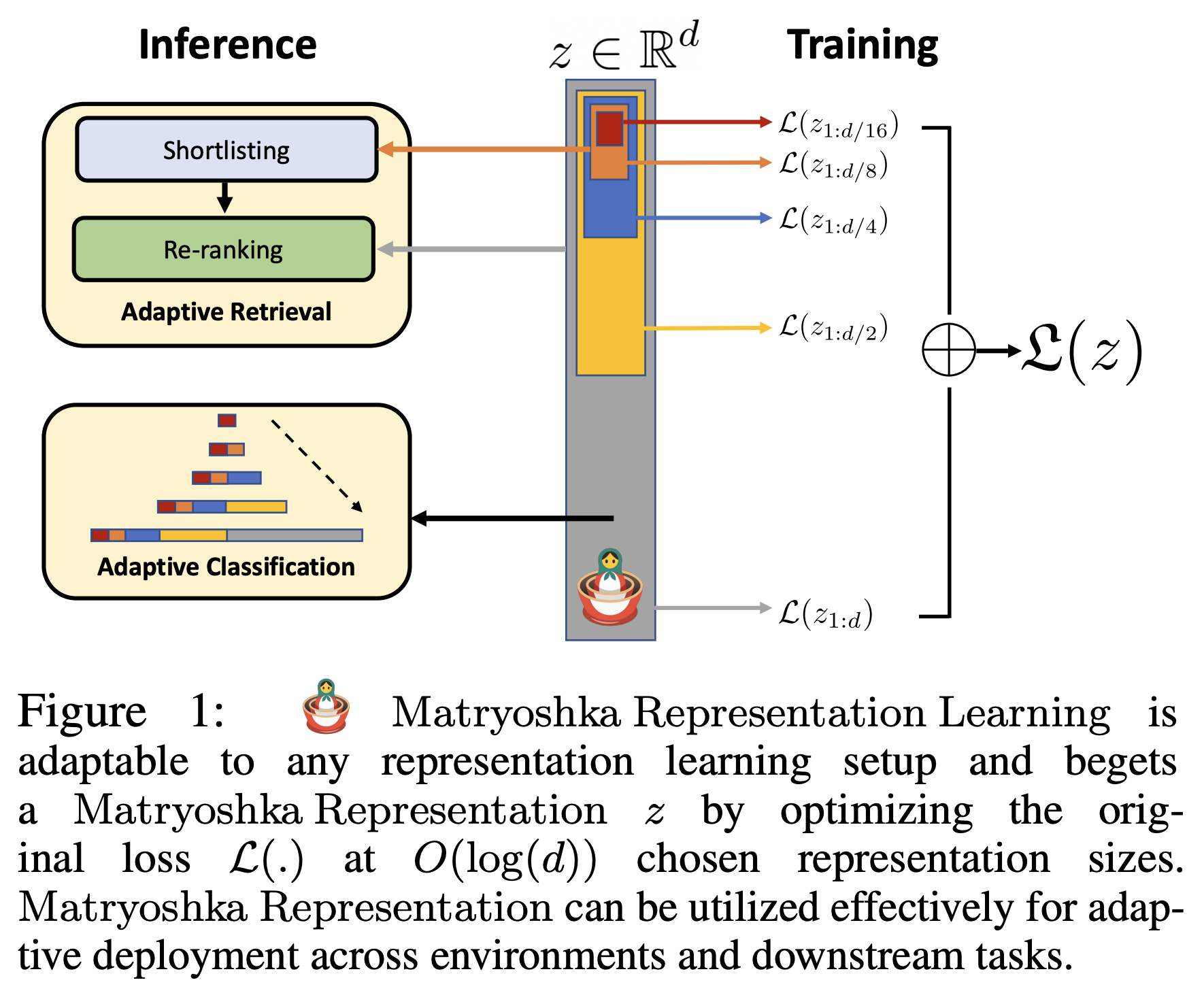
위의 그림에서 d 차원의 임베딩이 있을 때, d/2, d/4, d/8, … 차원의 임베딩도 같은 task를 수행하는 것이다. 즉, 768차원의 임베딩을 8, 16, 32, 64차원의 임베딩으로 차원을 압축 / 축소해서 사용하는 것이 아니라, 임베딩 자체의 차원을 지정하여 d차원까지만 활용하는 것이다. 이렇게 각 임베딩들 끼리 포함관계를 갖기 때문에 마트료시카의 꼴이 이루어지는 것이다. 좀 더 직관적인 이미지는 아래와 같다.
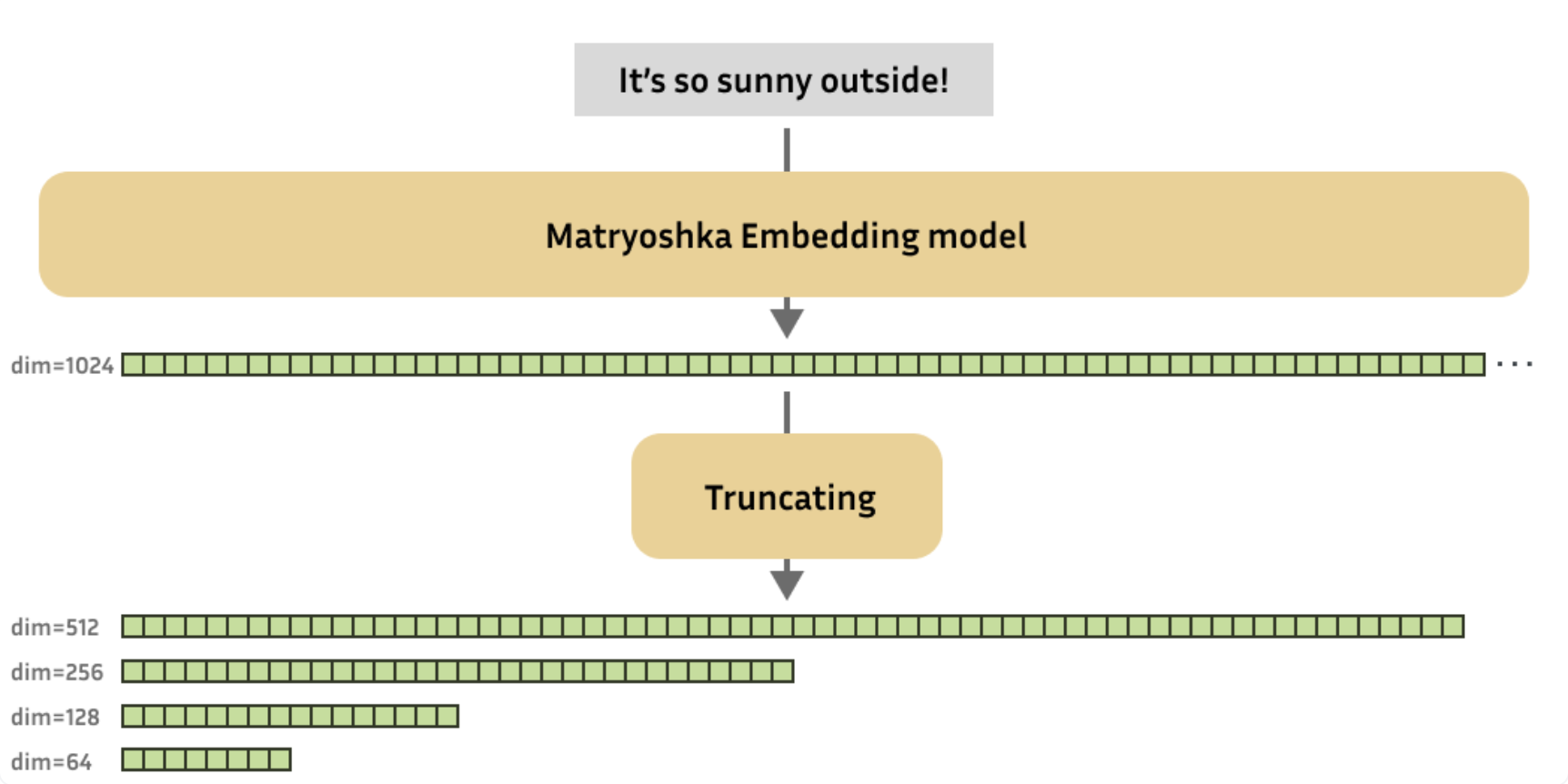
본 논문에서는 아쉽게도 이미지에 대한 실험을 위주로 진행했다. 아쉬운건 NLP를 다루는 본인이지만, 사실 차원축소가 더 중요하게 여겨지는 분야는 고차원의 이미지를 사용하는 이미지 분야이기 때문에 당연하긴 하다.
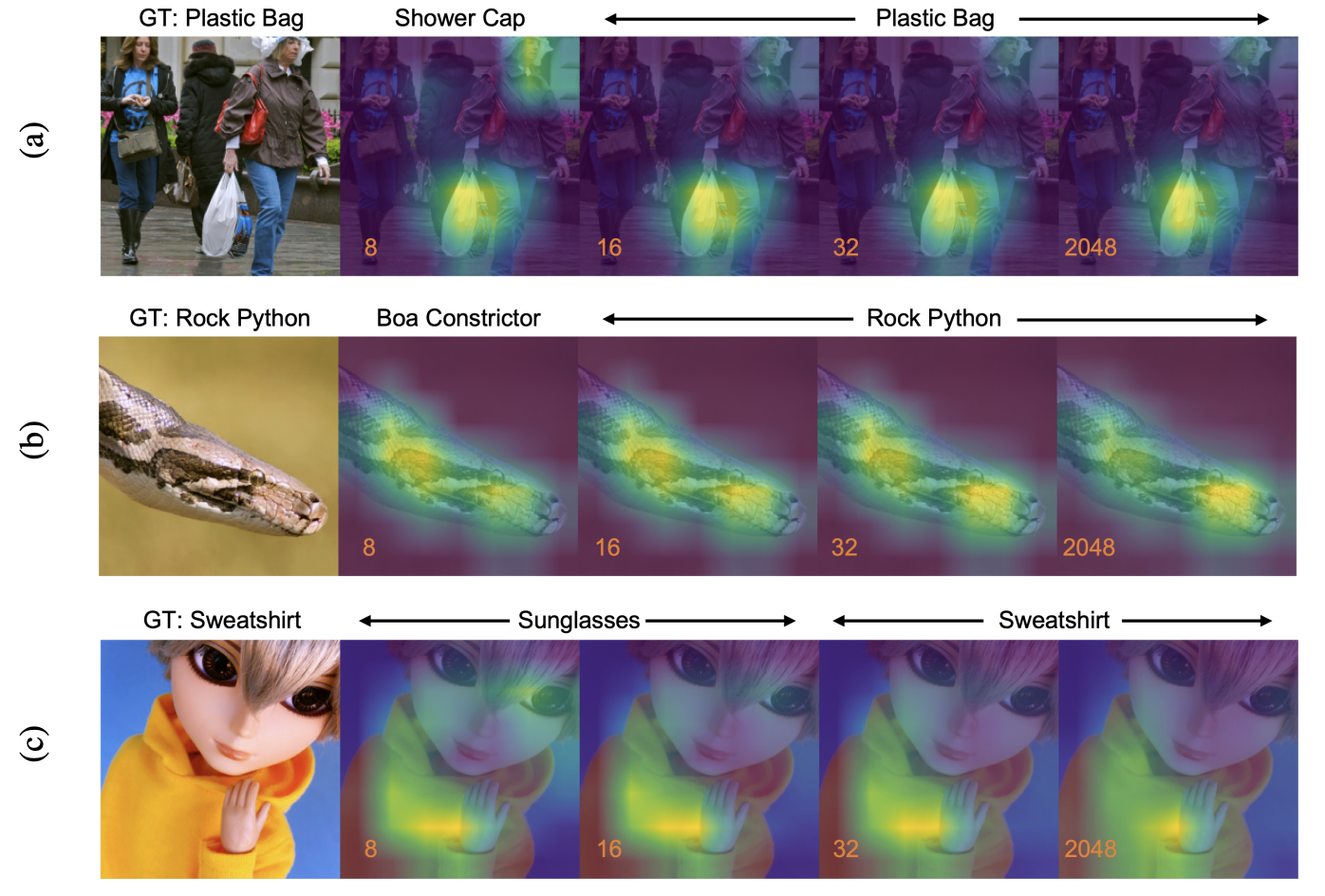
또한 차원 축소에 대해 Grad-CAM을 통한 분석을 진행했을 때, 동일한 사진이라도 어떻게 차원 축소를 진행했는지에 따라 결과가 달라지는 것을 볼 수 있다. 위의 (c) 결과를 봤을 때 8,16 차원은 Sunglasses로 예측을 했기 때문에 Grad-CAM 결과가 눈쪽으로 가있지만, 그 이상의 차원에서는 노란색 후드에 떨어져있는 것을 볼 수 있다.
즉, 차원 축소 관점에서 적절한 차원을 구성하여 Speed & Accuracy Trade-off의 균형을 잡는 것은 매우 중요한 일이라고 볼 수 있다.
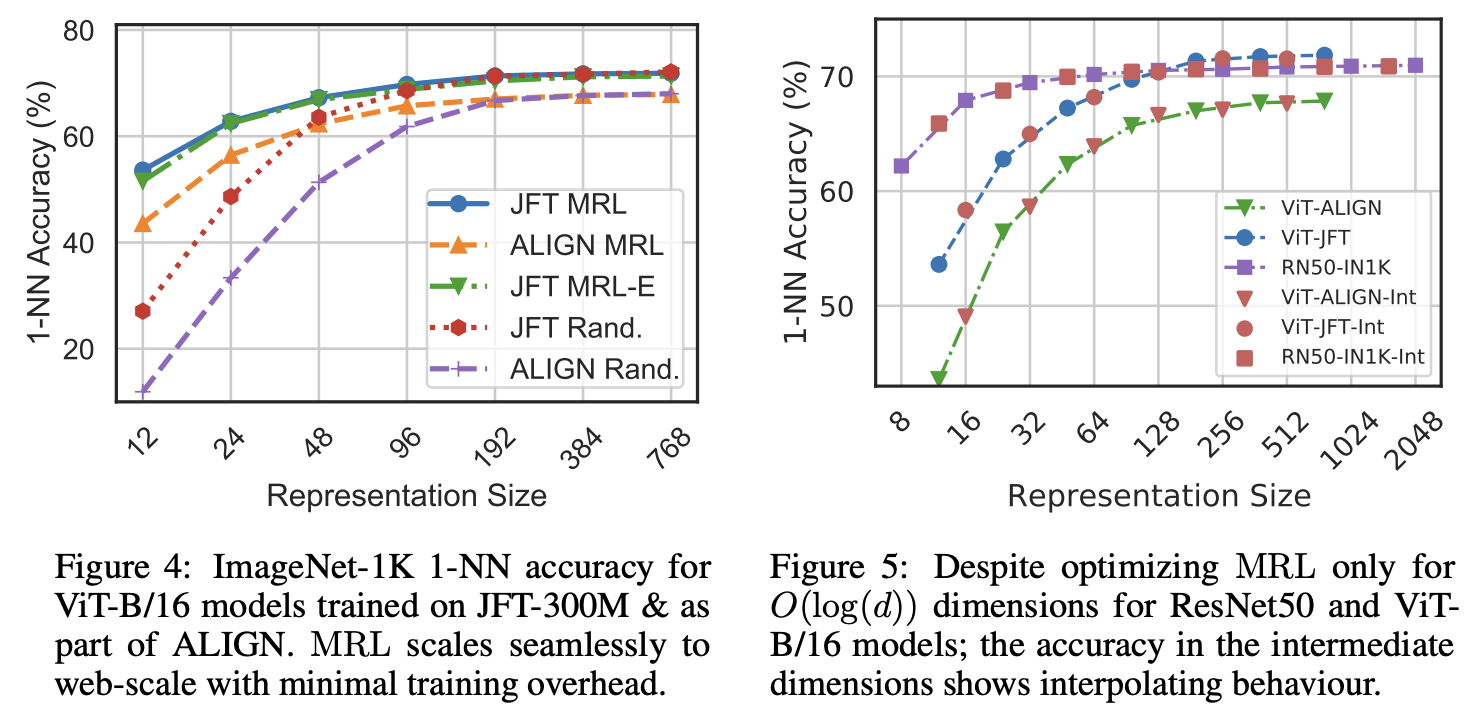
위의 그림에서 볼 수 있듯, MRL을 사용한 Embedding들이 Downstream Task (Classification)에서 낮은 차원일 때 더 좋은 성능을 볼 수 있다. MRL이 아닌 임베딩들은 단순히 이미지에 대해 Feed Forward를 통해 차원을 낮춘 임베딩들이지만, MRL은 기존 임베딩에서 사용하고자 하는 차원까지만 잘라서 사용할 수 있는 것이다.
논문에서 진행한 실험들의 요지는 다음과 같다.
- MRL이 원래 임베딩에 비해 성능이 하락하는 수준이 기존보다 훨씬 적으며, 구성도 더 간편하다
하지만 내가 주목한 포인트는 해당 실험들이 아니다.
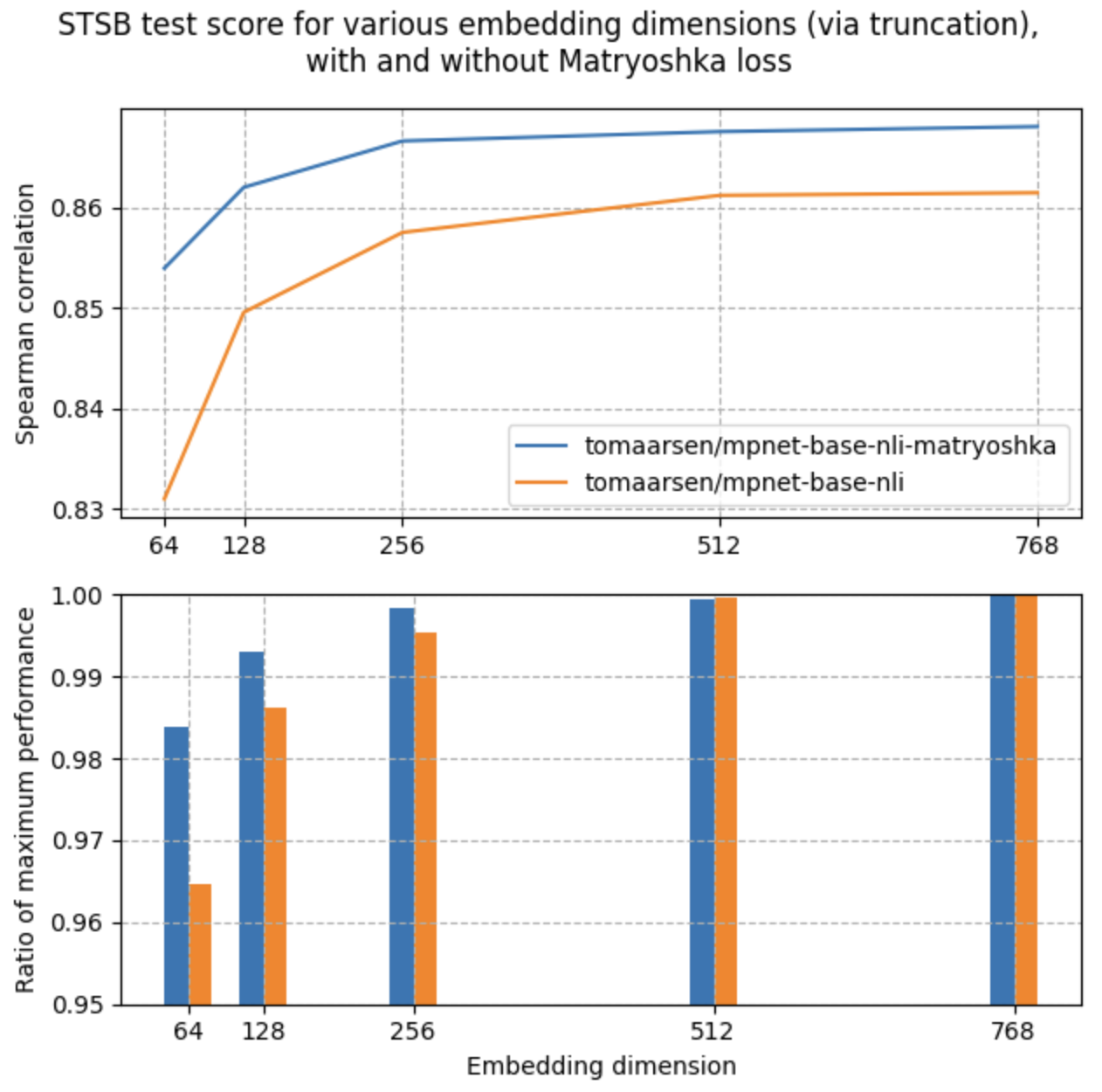
Sentence Transformers 홈페이지에 있는 마트료시카 임베딩을 활용한 Sentence Embedding의 성능 평가를 살펴보면, MRL 훈련을 진행한 임베딩이 모든 차원에서 더 좋은 성능을 나타내는 것을 볼 수 있다.
즉, 낮은 차원에서 더 좋은 성능을 보이는 것 뿐더러, 768차원 그대로의 비교에서도 더 좋은 성능을 나타내는 것을 볼 수 있다. 즉, MRL의 원래 취지는 차원 축소의 자유도의 증가인데, 취지를 넘어 원 임베딩 자체도 성능이 향상하게 되는 것을 볼 수 있다.
나는 이 현상의 이유로 다양한 관점으로 구성한 임베딩을 하나의 임베딩으로 Concat하는 과정에서 Embedding의 Expressiveness가 더 증가했기 때문이라고 생각한다.
해당 임베딩의 장점은 또 하나 있으며, 이는 Downstream Task 자체 성능 향상이다. 기본적으로 768차원을 모두 활용하지 않고 Downstream Task에서는 차원을 축소에서 사용하는데, PCA, UMAP이 매우 좋은 차원 축소 기법이긴 하지만 데이터의 의미를 반영해서 차원을 축소하는 면에서 아쉬운 성능을 보이긴 한다. UMAP 같은 경우는 Sentence의 의미를 파악해서 차원 축소하는 것이 아니라 전체 임베딩의 구조를 살펴본 뒤 적합한 차원 축소를 진행하기 때문이다.
따라서, 설령 MSE가 차원 축소를 했을 때 성능이 약간 하락하는 부분이 있다고 하더라도, PCA/ UMAP보다는 더 좋은 축소 효과를 보이지 않을까 생각한다.
다음 글 작성시에는 MRL의 Variants들을 정리해보고자 한다.
