
오늘은 데이터베이스 인덱스에 대해 학습했는데요.
이에 관해 글을 쓰고자 합니다.
index 란?
인덱스는 빠른 정렬과 그룹핑을 위한 데이터베이스 기능입니다.
지정한 칼럼들을 기준으로 index를 설정하면 지정한 칼럼들이 정렬되어 index로 나타납니다.
장점
- binary search 방식으로 조회하기 때문에 O(logN)의 시간복잡도를 가져 full scan 하는 O(N)보다 성능이 좋습니다.
- index는 메모리 영역에 올라가 있으므로 캐싱을 한다면 디스크로 조회하는 것보다 빠릅니다.
단점
- insert, update, delete 시에는 index를 재설정 해주어야하기 때문에 성능적으로 더 느립니다.
- index를 설정하게 되면 데이터베이스 공간을 더 차지합니다.
언제 사용할까?
조회 시에는 성능적으로 유리하고 생성, 수정, 삭제 시에는 성능적으로 비효율적이기 때문에 조회 쿼리가 많이 쓰이는 table에 index를 설정하면 됩니다!
하지만 조회 또한 권장하는 방향이 있는데요. 1개의 칼럼만 인덱스를 걸어야 한다면 해당 컬럼은 카디널리티(Cardinality)가 가장 높은 것을 잡아야 유리합니다.
카디널리티는 전체 행에 대한 특정 컬럼의 중복 수치를 나타내는 지표이다.
중복도가 ‘낮으면’ 카디널리티가 ‘높다’고 표현한다.
중복도가 ‘높으면’ 카디널리티가 ‘낮다’고 표현한다.
Index 만들어보기
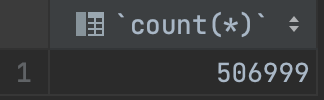
실험을 위해 아래와 같은 테이블로 index를 만들어보도록 하겠습니다.
빅데이터 사이트에서 도서 데이터를 50만 개 다운받아 실험 데이터베이스에 넣어주었습니다.
create table book
(
SEQ_NO bigint not null
primary key,
ISBN_THIRTEEN_NO varchar(13) not null,
VLM_NM varchar(20) null,
TITLE_NM varchar(1000) not null,
AUTHR_NM varchar(1000) null,
PUBLISHER_NM varchar(1000) null,
PBLICTE_DE varchar(30) null,
ADTION_SMBL_NM varchar(5) null,
PRC_VALUE decimal(9, 2) null,
IMAGE_URL varchar(1000) null,
BOOK_INTRCN_CN varchar(1000) null,
KDC_NM decimal(14, 8) null,
TITLE_SBST_NM varchar(1000) null,
AUTHR_SBST_NM varchar(1000) null,
TWO_PBLICTE_DE varchar(10) null,
INTNT_BOOKST_BOOK_EXST_AT varchar(1) null,
PORTAL_SITE_BOOK_EXST_AT varchar(1) null,
ISBN_NO varchar(41) null
);
보통 isbm 13자리로 도서를 검색하는 경우가 많다고 생각해 ISBM_THIRTEEN_NO 칼럼을 index로 걸어보겠습니다.
create index book_idx on book(ISBN_THIRTEEN_NO);index가 잘 걸렸는지 확인해보겠습니다.
show index from book;
사진을 보면 book_idx가 잘 들어가있는 것을 확인할 수 있습니다.
하지만 걸지 않은 PRIMARY라는 이름의 index도 보이는데요. 이는 테이블을 생성할 때 PK 기준으로 자동으로 index를 생성해주는 mysql의 특징 때문입니다.
성능 검증
index를 걸기 전과 후의 속도를 비교해보도록 하겠습니다.
index 적용 전

index 적용 후

31ms로 10배 이상의 성능 차이를 보였습니다.
실행시간만 본다면 60배 이상의 차이를 보였습니다.
주의 사항
단일 칼럼으로 index를 구성했기 때문에 다른 칼럼에 대해서는 정렬된 상태로 저장되어있지 않습니다. 따라서 where a = 1 and b = 2와 같은 다중 필터링의 경우에는 index를 적용할 때보다 성능이 떨어질 수도 있습니다.
(보통 다중 필터링을 사용하는 경우는 칼럼 자체의 카디널리티가 떨어질 것이기 때문에 index를 사용하지 않을 것 같습니다.)
그럼 MySQL index는 어떤 방법으로 이렇게 빠르게 데이터를 검색할 수 있는 것일까요?
B-Tree
index는 B-tree 구조로 되어있는데요. 이 구조에서 이분 탐색까지 더해져 좋은 성능을 내는 것입니다.
완벽하게 B-tree의 구조를 이해하지는 못했습니다.
따라서 해당 내용에 대해 궁금하신 분들은 동욱님의 블로그를 참고해주시면 감사하겠습니다.
B-tree 구조에서 root와 branch는 자식 노드의 위치를 저장하고, leaf는 조회하려는 데이터 칼럼의 데이터베이스 포인터를 저장합니다. 그리고 포인터를 통해서 데이터베이스의 해당 주소로 바로 이동하는 방식입니다.
ISBN_THIRTEEN_NO가 1313131313131인 책을 찾는다고 가정했을 때 위와 같이 Root1 -> BRANCH2 -> LEAF4 를 거쳐 데이터베이스 주소로 다이렉트로 이동하는 방식입니다. (실제로는 브랜치가 더 깊게 퍼져있습니다.)
Composite Index
두 가지 이상의 칼럼으로 조합된 index를 composite index라고 합니다.
두 가지 칼럼의 조합으로 카디널리티가 높을 때 사용합니다.
지금 도서 데이터에서는 책 제목 + 저자를 기준으로 복합 index를 적용할 수 있겠습니다.
책 제목은 겹치는 경우가 종종 있고, 한 저자가 여러권의 서로 다른 책을 쓰는 경우도 많죠. 하지만 보통 작가들은 겹치는 책 제목을 짓지는 않을 것 같아서 책 제목 + 저자의 조합은 카디널리티가 높다고 생각했습니다.
어떻게 composite index를 만드는지 살펴보겠습니다.
create index title_author_idx on book(TITLE_NM, AUTHOR_NM);이전과 크게 다르지 않습니다. 하지만 동작 방식에서 차이가 있습니다.
만약 TITLE_NM 칼럼만을 index로 설정했다면 title은 사전순대로 정렬되어 있지만 author는 사전순대로 정렬되어 있지 않습니다.
당연한 이야기인데요. index를 title에만 걸었으니 나머지 칼럼에 대해서는 정렬이 되어있지 않게 index가 생성됩니다.
결국 title만 이분 탐색을 하고, author에 대해서는 full scan을 하게 됩니다.
복합 index는 title로도 정렬하고, author에 대해서도 정렬하게 됩니다. 두 칼럼 모두를 검색할 때 이분 탐색을 합니다.
단점
하지만 단점 또한 존재합니다.
책 제목 + 저자 조합이 아닌 저자로만 검색하고 싶을 땐 full scan을 하게 됩니다.
책 제목으로 검색하는 경우에는 이 composite index를 사용하면 빠르게 검색할 수 있습니다. 1차 정렬을 책 제목으로 했고, 2차 정렬을 저자로 했기 때문입니다. 하지만 저자로 검색하는 경우 composite index가 처음에는 제목 기준으로 정렬되어 있기 때문에 full scan을 하는 것보다 더 오래 걸릴 수도 있습니다.
select * from book where title_nm = '클린코드';
select * from book where title_nm = '클린코드' and author_nm = '로버트C.마틴';위 두 가지 경우에는 빠르게 검색 가능하지만
select * from book where author_nm = '로버트C.마틴';위와 같은 경우는 검색 속도가 떨어집니다.
이를 해결하기 위해서는 저자에 대한 index를 만들어주어야 합니다. index를 더 만들면 좋지만 그만큼 용량 차지도 하기 때문에 정말 자주 사용하는 쿼리인지 판단하고 신중하게 index를 설정하는 것이 좋습니다.
Explain
index가 많아질수록 쿼리가 어떤 index를 사용하고 있는지 헷갈릴 수 있는데요.
이때 explain 키워드를 통해 어떤 index를 사용하고 있는지 알 수 있습니다.
create index isbn_no_idx on book(ISBN_NO);
create index isbn_thirteen_no_idx on book(ISBN_THIRTEEN_NO);
create index isbn_no_isbn_thirteen_no_idx on book(ISBN_NO, ISBN_THIRTEEN_NO);이렇게 3개의 index를 생성했다고 가정하겠습니다.
explain select SQL_NO_CACHE * from book where ISBN_NO = '9780358354352';위의 explain 문을 실행시키면

사진과 같이 isbn_no_idx를 사용하고 있다고 알려주고 있습니다.
그리고 가능한 index 목록도 보여주는데요. 저는 isbn_no 칼럼 만을 index로 만들기도 했고 isbn_no + isbn_thirteen_no 조합으로도 index를 만들었습니다. 두 index를 사용할 수 있고 mysql은 isbn_no_idx를 사용한 모습입니다.
만약 isbn_thirteen_no를 검색할 땐 어떻게 될까요?
explain select SQL_NO_CACHE * from book where ISBN_THIRTEEN_NO = '9780358354352';
사진과 같이 isbn_thirteen_no 만을 이용한 index를 사용하고 가능한 index 목록에도 해당 index밖에 표시되지 않습니다.
composite index도 있는데 해당 index를 possible keys에 포함시키지 않은 이유는 mysql에서는 첫 순서의 칼럼이 포함되어 있지 않은 select 문에 대해서는 possible keys로 두지 않기 때문입니다.
그리고 mysql은 optimizer가 알아서 적절하게 index를 선택할 수 있게 하기 때문에 index를 선택하지 않아도 index 방식으로 조회를 하는 것입니다.
Index hint
그렇다면 개발자가 원하는 index를 사용하게 하려면 어떻게 해야할까요?
use
select 시에 use 키워드를 사용하면 해당 index로 조회가 가능합니다!
explain select SQL_NO_CACHE * from book use index(isbn_no_isbn_thirteen_no_idx) where ISBN_NO = '9780358354352';이전에 같은 쿼리에서 optimizer는 isbn_no_idx를 사용했는데요. 이렇게 use를 이용해서 isbn_no_isbn_thirteen_no_idx로 지정해주게 되면 해당 index를 사용합니다.

force
explain select SQL_NO_CACHE * from book force index(isbn_no_isbn_thirteen_no_idx) where ISBN_NO = '9780358354352';force도 use와 같이 원하는 index를 사용하게끔 합니다.
하지만 이름에서 유추할 수 있듯이 더 강한 권장처럼 보이죠.
어떤 것에 use를 써야하고 어떤 것에 force를 써야하는지 추상적이어서 저는 헷갈렸었는데요.
아래와 같은 특징을 가집니다.
- use
- optimizer에게 지정한 index를 사용하라고 권장합니다.
- 만약 full scan이 더 빠르다면 optimizer는 index 대신 full scan으로 수행할 수 있습니다.
- force
- full scan이 더 효율적이어도 무조건 index를 사용합니다.
- index를 사용할 수 없는 쿼리 (index가 걸려있지 않은 컬럼이 조건에 있는 경우)인 경우에만 다른 방법을 선택할 수 있습니다.
ignore
explain select SQL_NO_CACHE * from book ignore index(isbn_no_isbn_thirteen_no_idx) where ISBN_NO = '9780358354352';ignore index는 이름에서 유추할 수 있듯이 지정한 index를 무시하는 문법입니다.
위의 예시처럼 isbn_no_isbn_thirteen_no_idx를 무시하면 이 index를 제외하고 다른 index로 실행하게 됩니다.

기존의 isbn_no_index를 사용하고 있네요!
Covering index
굳이 database까지 가지 않고 index만으로 커버할 수 있는 것을 말합니다.
예를 들어 아래와 같은 쿼리가 있다고 가정하겠습니다.
select book.ISBN_NO, book.ISBN_THIRTEEN_NO from book where ISBN_NO ='8988557212';이전에 걸어둔 isbn_no_isbn_thirteen_no_idx 인덱스가 존재한다면 해당 인덱스에서 모든 정보를 추출할 수 있기 때문에 데이터베이스까지 통신하지 않고 메모리 영역에서만 탐색하고 결과를 반환합니다.
데이터베이스와 직접 통신하지 않기 때문에 속도가 개선이 되겠죠!
마무리
간단한 index 관련해서 글을 남겨보았는데요.
이외에 hash index, b+ tree 등 여러 개념을 봤는데, 아직 공부할 필요성을 느끼지 못해 자세히 보지 않았습니다.
나중에 필요할 때 사용해볼 예정입니다.
참고
