프로젝트 : https://github.com/HoonInPark/ServerHyperion
서버 권위 모델 구현을 위한 브래인스토밍을 하는 중이다.
Jolt Physics가 나온지 얼마 되지 않았고, 유니티 진영엔 포톤 서버가, 언리얼 진영엔 dedicated server가 이미 있기에 Jolt Physics로 서버 권위 모델을 한땀한땀 구현하는 시도는 지금껏 별로 없었다.
하지만 세상엔 dedicated server만 있는 게 아니고, 많은 대형 게임사들은 자체 서버를 운영 중이다.
문제
본 프로젝트의 목표는 다음과 같다.
1. 3D 게임의 서버 권위 모델을 구현
2. 이를 위한 물리 시뮬레이션이 서버에서 작동해야 하고, 이것의 결과 값이 클라이언트에 Replicate돼야 한다.
3. 한 룸 내 100명의 동접자가 있고, 한 프로세스는 총 3000명의 동접자를 감당한다. 총 60개 방이 만들어질 수 있는 것.
4. 패킷 형식을 자유롭게 작성할 수 있어야 한다.
5. 애니메이션 시스템이 있어야 한다. 히트 판정을 위해 필요.
6. 언리얼 클라이언트 개발에 필요한 SDK를 제공해야 한다.
7. 클라이언트는 월드 내 100명의 Replicant를 표출한다.
8. 기본적인 DB 연동을 염두하여 설계한다.
9. AWS에서 테스트 해볼 수 있어야 한다.
왜 서버 권위 모델로 게임 서버를 만들어야 하는가?
멀티 플레이 게임, 특히나 승패가 있는 게임들에서 중요한 건 공정성이다.
승패에 영향을 미치는 히트 판정과 같은 판단이 클라이언트(사용자 컴퓨터)에서 일어난다면, 사용자는 프로그램의 허점을 파악하여 에임핵과 같은 해킹을 시도할 수 있다.
이를 막고자, 클라이언트는 키입력만을 서버에 보내고 실제 '사건'은 서버 내에서 시뮬레이션 되는 것이다.
물리 시뮬레이션이 서버에서 돌아간 뒤,
그 결과 플레이어의 이동(어느 방향으로 얼마만큼 이동했는지), 히트 판정 결과 값(맞았는지)이 사용자 컴퓨터로 전송된다.
이런 식의 서버-클라이언트 구성을 '서버 권위 모델'이라 부른다.
이렇게 하면 서버 해킹이 일어나지 않는 이상 게임 내 부정행위는 사라진다.
해결
1. 3D 게임의 서버 권위 모델을 구현
언리얼 클라이언트에서는 키입력만 전송하고, 실제 게임 로직은 서버에서 돌아간다.
2. 물리 시뮬레이션이 서버에서 작동해야 하고, 이것의 결과 값이 클라이언트에 Replicate돼야
물리 시뮬레이션으로는, CPU로 작동해야 하는 물리엔진이 필요하다.
가장 첨단이자 상용 게임(최근 출시된 데스 스트랜딩2)에도 쓰이는 Jolt Physics를 쓸 거다.
https://github.com/jrouwe/JoltPhysics
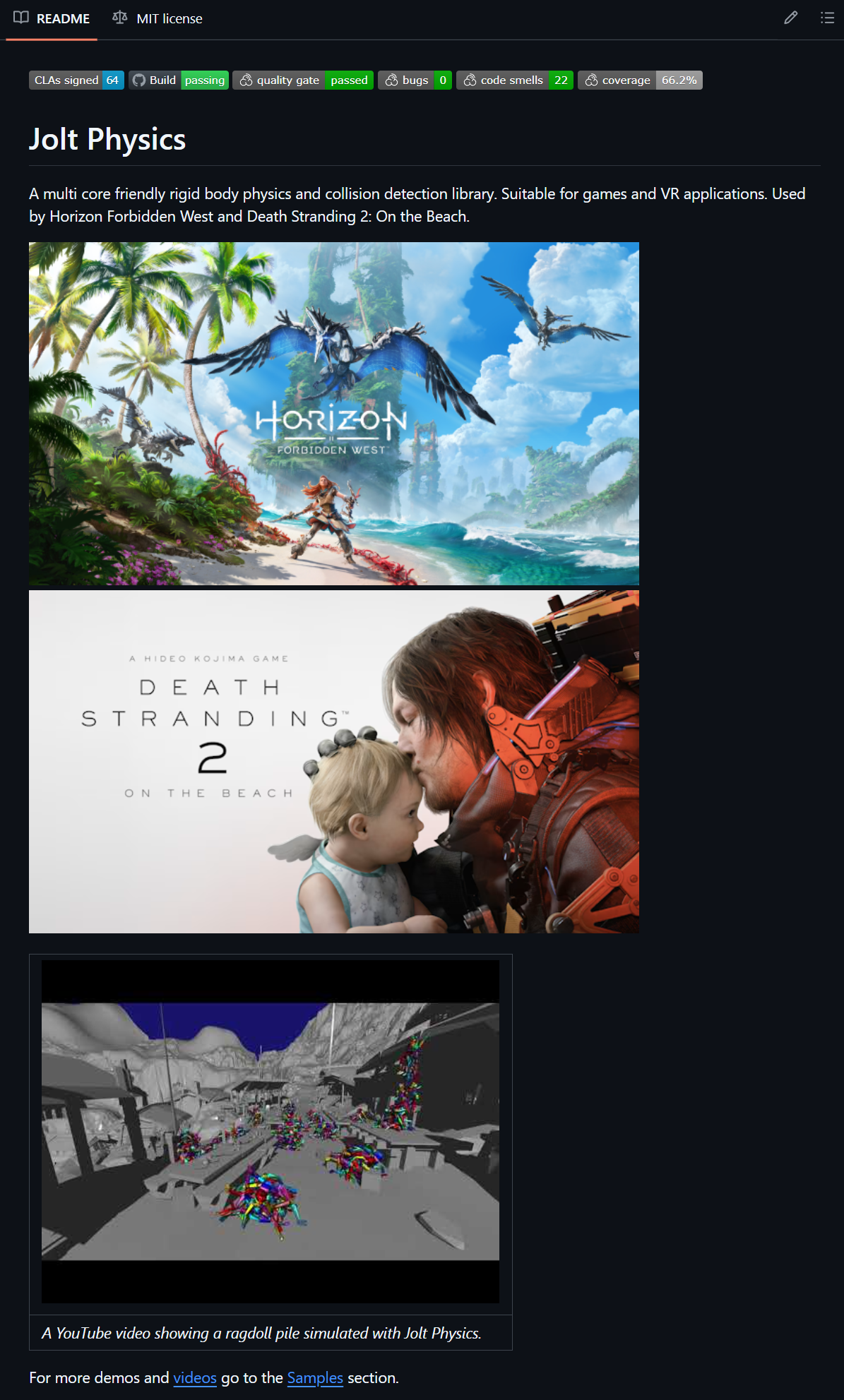
기본적인 캐릭터 이동/가속은 물론,
피격 판정을 자세하게 하기 위해 스켈레톤과 애님 시퀀스 uasset에서 추출한 관절 별 트랜스폼의 변화를 시뮬레이션할 수 있어야 한다.
이렇게 할 경우 서버가 움직임을 시뮬레이션하는 본에 달린 콜리젼을 통해 자세한 피격 판정을 할 수 있다.
여기서 '자세한 피격 판정'이란, 팔을 맞았을 때와 몸통, 머리를 맞았을 때의 데미지를 달리 하는 것을 말한다.
문제는 uasset에서 원하는 정보를 어떻게 뽑아내는지다.
뽑아내서 내가 원하는 자료형에 담는 건 ChatGPT가 대략 알려줬다.
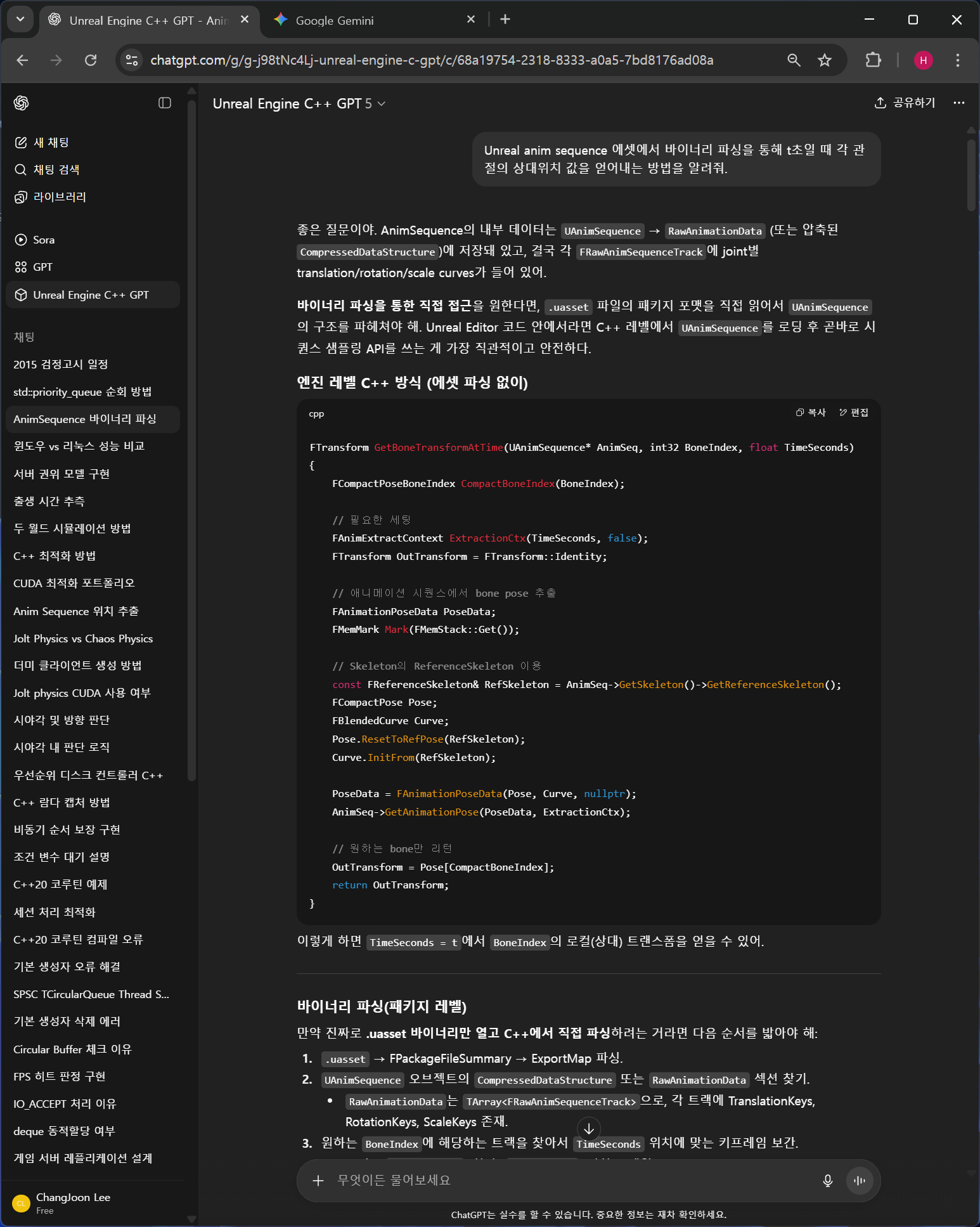
대략 엔진에 있는 API를 끌어다 쓰면 된다는 얘기.
그러면 스켈레톤과 애님 시퀀스에셋이 수정될 때마다 저 프로세스가 돌아가야 한다는 의미다.
또, 이 샘플링된 결과값이 서버에 저장돼야 한다.
그럼 DB가 필요한 듯...?
이 부분은 좀 더 고민이 필요하다.
만약 DB에 저장한다고 하면, 빠르게 필요한 애니메이션을 쿼리해서 메모리에 로드해야 한다.
반대로 DB를 쓰지 않는다고 하면, 메모리에 필요한 애니메이션 에셋이 모두 업로드된다.
둘 다 성능적으로 문제가 된다.
물론 사용하는 애니메이션 종류를 줄이면 편해지지만, 이게 해결책은 아니다.
Redis...?
빠르다, DB 서버에서 자주 접근하는 데이터를 저장할 때 쓴다, 많이들 쓴다... 아직 이 정도로만 알고 있는 솔루션이다.
서버에서 물리엔진이 돌아가면 서버의 성능을 많이 잡아먹을 것 같다는 생각도 드는데,
일단 지금 내가 상상하는 해결책은...
1. 서버에서 물리 시뮬레이션을 처리하며 돌아가는 Tick은 32ms 간격(초당 30번)으로 호출된다.
2. 만약 서버가 초당 30 * n (n > 1) 만큼 Tick을 호출할 수 있다면, 하나의 물리엔진 객체를 가지고 두 개의 월드를 감당하도록 하는 것이다.
예시 코드를 보자.
// 초당 60 프레임을 감당할 수 있다 할 때, 한 스레드 내의 작업들
Tick_World_1();
Tick_World_2();한번의 순회에서 각기 다른 두 월드의 물리 시뮬레이션을 실행하는 것.
메모리를 최적화할 수도 있고, 스레드 갯수를 줄여 컨텍스트 스위칭도 줄일 수 있다.
3. 한 룸 내 100명의 동접자가 있고, 한 프로세스는 총 3000명의 동접자를 감당한다.
이 부분은 정말 최적화 싸움.
렌더가 없는 헤드리스 더미 클라이언트 프로그램으로 무작위적인 패킷(혹은 실제 입력 값을 기록한 샘플링 데이터)으로 스트레스 테스트를 해보면 좋을 듯 하다.
다만 이론적으로 한 컴퓨터에서 이 테스트를 하는 게 실제 서비스와 동일한지 검토가 필요하다.
한 컴퓨터 내에서 더미 클라가 돌아가고 또한 서버도 이를 받는다면, 서울에 서버가 있고 제주도에서 클라가 접속하는 상황과는 확실히 다를 것이기 때문.
단지 레이턴시 때문만은 아니다.
한 컴퓨터에서 서버/클라 포트를 열고 이 프로세스가 서로 통신하는 상황이기 때문.
시야에 보이지 않을 경우 렌더와 Replicate을 중단하는 심리스 방식 최적화도 필요.
4. 패킷 형식을 자유롭게 작성할 수 있어야 한다.
현재까지의 프로젝트 진행 상황에서, 난 내가 직접 바이트 배열을 설계하고 압축 로직, (역)직렬화 로직을 짰다.
이렇게 구현하니 보내야 할 데이터의 내용이 달라질 때마다 분기문을 추가해야 하는 등의 번거로움이 있다.
그래서 구글 protobuf를 사용할 예정.
https://github.com/protocolbuffers/protobuf
서버 엔지니어 채용공고에서 봤는데, 몇몇 상용 서버(메이플스토리였나)가 이 라이브러리를 사용하고 있다.
패킷에 들어갈 데이터를 형식에 맞게 작성하면 (역)직렬화를 알아서 해준다고 한다.
다만 패킷 압축은 내가 따로 구현할 여지가 있다.
또, 전체 구조 차원에서 클라에 아무런 변화가 없으면 패킷을 보내지 않는 '델타 압축' 방식도 고려해볼만 하다.
5. 애니메이션 시스템이 있어야 한다. 히트 판정을 위해 필요.
언리얼 최신 기능인 '모션 매칭 시스템' 정도로 고도화할 순 없다.
간단한 로코모션 시스템 정도는 필요.
6. 언리얼 클라이언트 개발에 필요한 SDK를 제공해야 한다.
현재까지의 진행으로 상당히 많이 진행돼 있다.
다만 옵저버 패턴 + 멀티스레딩을 활용한 Replication 구현까지 플러그인 속에 모듈화돼야 한다.
7. 클라이언트는 월드 내 100명의 Replicant를 표출한다.
클라 최적화의 영역인데, 자세한 내용은 Unreal에서 Multithreading으로 Observer Pattern 최적화하기에서 다룬다.
8. 기본적인 DB 연동을 염두하여 설계한다.
DB를 붙인다는 얘기가 아니다.
붙이기 쉽도록 설계한다는 이야기다.
아직 DB에 대한 지식이 부족하여 구체적인 구상은 나중으로 미뤄 둔다.
사용할 DB는 관계형 DB로 가장 많이 쓰는 MySQL.
DB가 필요한 경우는 보통...
1. 계정 관리 시스템
2. 게임 리플레이 시스템. 오버워치나 배틀그라운드는 사용자가 끝난 경기를 리플레이 해볼 수 있게 돼 있다. 이건 서버가 플레이어의 움직임을 기록해 두고 있다가 다시 렌더해서 보여주는 것임.
9. AWS에서 테스트 해볼 수 있어야 한다.
심심해서 침대에 누워서 견적을 내봤는데,
12코어 윈도우 서버를 하루 동안 운용하는데에 7만원이 들더라.
어떻게 하면 최소한의 테스트를 해볼지 고민해 봐야 한다.
가끔 보면 포트폴리오로 서버 URL 첨부하라는 곳이 있던데, AWS 서비스 지원해 주는 대학교 다니는 친구들에게 도움을 요청해 보자.
변경 사항
AZURE는 처음 가입하면 무료로 1년을 사용할 수 있게 해준다.
너무 고맙다.
고마운 김에 마이크로소프트 패밀리로 MS SQL을 써보자.
