프로젝트 : https://github.com/HoonInPark/ServerHyperion.git
본 포스트에 대한 내용은 feat/lockfree 브랜치에 있다.
사담
드미트리 뷰코프라는 구글 재직 중인 천재 개발자가 만든 자료형을 보고 역으로 그 사람이 의도한 바를 추적해 나가는 과정이 진짜 힘들었다.
근데 진짜 이런거 어떻게 생각해낸건지 대단하다.
나도 저렇게 돼야지!
문제
내가 이전에 작성한 순환큐 구현하기를 feat/framesync에 적용하고 main에까지 병합했는데 문제가 생겼다.
서버가 다운된다.
왜?
원래 언리얼에 구현된 TCircularQueue의 주석을 잘 보니 이건 단일 생산 - 단일 소비 상황(Single Producer - Single Consumer, SPSC)에서만 쓸 수 있다고 나와 있었다.
나 왜 이걸 까먹고 신나게 서버 코드에 집어넣었던 것인가...
동시접근으로 서버가 터지는 거였다.
기껏 lock-free 해졌다고 흐뭇하게 완성 코드를 구경하던 차였는데...
내 서버에서 요구사항은 다음과 같다.
1. 런타임 동적할당이 없어야 하고
2. MPMC(Multiple Producer - Multiple Consumer) 상황에서 Race Condition이 없고
3. 내부에 mutex 같은 잠금이 없으면 좋겠다.
해결
이미 꽤 간단하게 구현돼 있는 mpmc_bounded_queue 헤더 파일을 분석하며 원리를 이해하고, 이를 기반으로 내 프로젝트에 적용되도록 튜닝해 보고자 한다.
다음은 Dmitry Vyukov의 mpmc_bounded_queue.h 파일이다.
#pragma once
#include<cassert>
#include<atomic>
using namespace std;
template<typename T>
class mpmc_bounded_queue
{
public:
mpmc_bounded_queue(size_t buffer_size)
: buffer_(new cell_t[buffer_size])
, buffer_mask_(buffer_size - 1)
{
assert((buffer_size >= 2) && ((buffer_size & (buffer_size - 1)) == 0));
for (size_t i = 0; i != buffer_size; i += 1)
buffer_[i].sequence_.store(i, memory_order_relaxed);
enqueue_pos_.store(0, memory_order_relaxed);
dequeue_pos_.store(0, memory_order_relaxed);
}
~mpmc_bounded_queue()
{
delete[] buffer_;
}
bool enqueue(T const& data)
{
cell_t* cell;
size_t pos = enqueue_pos_.load(memory_order_relaxed);
for (;;)
{
cell = &buffer_[pos & buffer_mask_];
size_t seq = cell->sequence_.load(memory_order_acquire);
intptr_t dif = (intptr_t)seq - (intptr_t)pos;
if (dif == 0)
{
if (enqueue_pos_.compare_exchange_weak(pos, pos + 1, memory_order_relaxed))
break;
}
else if (dif < 0)
return false;
else
pos = enqueue_pos_.load(memory_order_relaxed);
}
cell->data_ = data;
cell->sequence_.store(pos + 1, memory_order_release);
return true;
}
bool dequeue(T& data)
{
cell_t* cell;
size_t pos = dequeue_pos_.load(memory_order_relaxed);
for (;;)
{
cell = &buffer_[pos & buffer_mask_];
size_t seq =
cell->sequence_.load(memory_order_acquire);
intptr_t dif = (intptr_t)seq - (intptr_t)(pos + 1);
if (dif == 0)
{
if (dequeue_pos_.compare_exchange_weak
(pos, pos + 1, memory_order_relaxed))
break;
}
else if (dif < 0)
return false;
else
pos = dequeue_pos_.load(memory_order_relaxed);
}
data = cell->data_;
cell->sequence_.store
(pos + buffer_mask_ + 1, memory_order_release);
return true;
}
private:
struct cell_t
{
atomic<size_t> sequence_;
T data_;
};
static const size_t cacheline_size = 64;
typedef char cacheline_pad_t[cacheline_size];
cacheline_pad_t pad0_;
const cell_t* buffer_;
const size_t buffer_mask_;
cacheline_pad_t pad1_;
atomic<size_t> enqueue_pos_;
cacheline_pad_t pad2_;
atomic<size_t> dequeue_pos_;
cacheline_pad_t pad3_;
mpmc_bounded_queue(mpmc_bounded_queue const&);
void operator = (mpmc_bounded_queue const&);
};순환 큐 크기를 2의 승수로 설정
언리얼의 TCircularQueue에서도 그렇고, 지금 가져온 코드에서도 그런데,
순환큐 크기를 2의 n승으로 설정하는 부분이 있다.
(이번 코드에선 아예 인수로 넣어주는 수가 2의 승수가 아니면 프로그램을 터뜨린다.)
이런 행위를 왜 할까?
우선 비트 연산자 &에 대해 알아야.
1 0 0 0 // 8
1 1 1 0 // 14
-------
1 0 0 0 // 8두 수의 이진수의 각 자리를 비교했을 때,
둘 다 1이면 결과값의 해당 비트 자리를 1로 반환한다.
이걸 이용하여 위의 ChatGPT 설명대로 나머지 연산이 가능하고,
혹은 코드의 생성자 부분에서 나온 것과 같이 buffer_size & (buffer_size - 1)) == 0로 2의 승수가 아님을 판단할 수 있다. (& 연산의 결과를 십진수로 표현했을 때 1이 나오는 경우는 buffer_size가 2의 승수인 경우 뿐이기에.)
나머지 연산은!
사이즈를 2의 승수로 만들지 않았다면 index = pos % buffer_size_;로 표현했을 것을,
index = pos & buffer_mask_;로 표현할 수 있게 된다.
memory_order
왜 순환 큐 구현에 배열을 썼을까?
크기가 제한된 자료형은 세상에 많은데 말이다.
배열은 자료형에 대한 동시접근을 해도 인덱스가 다르면 읽기/쓰기 결과가 같기 때문이다.
심지어 실행 결과만 같다면 순서 보장도 필요 없을 때가 있다.
TCircularQueue에선 Dequeue 혹은 Peek를 Head 인덱스로 하고,
Enqueue를 Tail 인덱스에 한다.
반면 mpmc_bounded_queue는 dequeue_pos_, enqueue_pos_로 명명했다.
여기서 코드의 실행 순서 보장을 위해 std::memory_order를 사용했다.
멀티스레딩에서 코드의 실행 순서가 문제되는 경우는,
1. 쓰기 연산(store(...))을 끝내지 않았는데 다른 스레드가 해당 변수를 관측하거나,
2. 읽기 연산(load(...)) 후에 배치된 쓰기 연산이 다른 스레드에 관측되는 경우다.
이게 mpmc_bounded_queue에 적용된 기본 아이디어.
1은 memory_order_release로, 2는 memory_order_acquire로 해결.
예상 시나리오
배열로 만든 순환 큐에 대한 동시 접근 시나리오를 생각해 보면...
다음과 같은 경우는 막아야 한다.
그리고 이것도.
하지만 다음과 같은 경우는 허용된다.
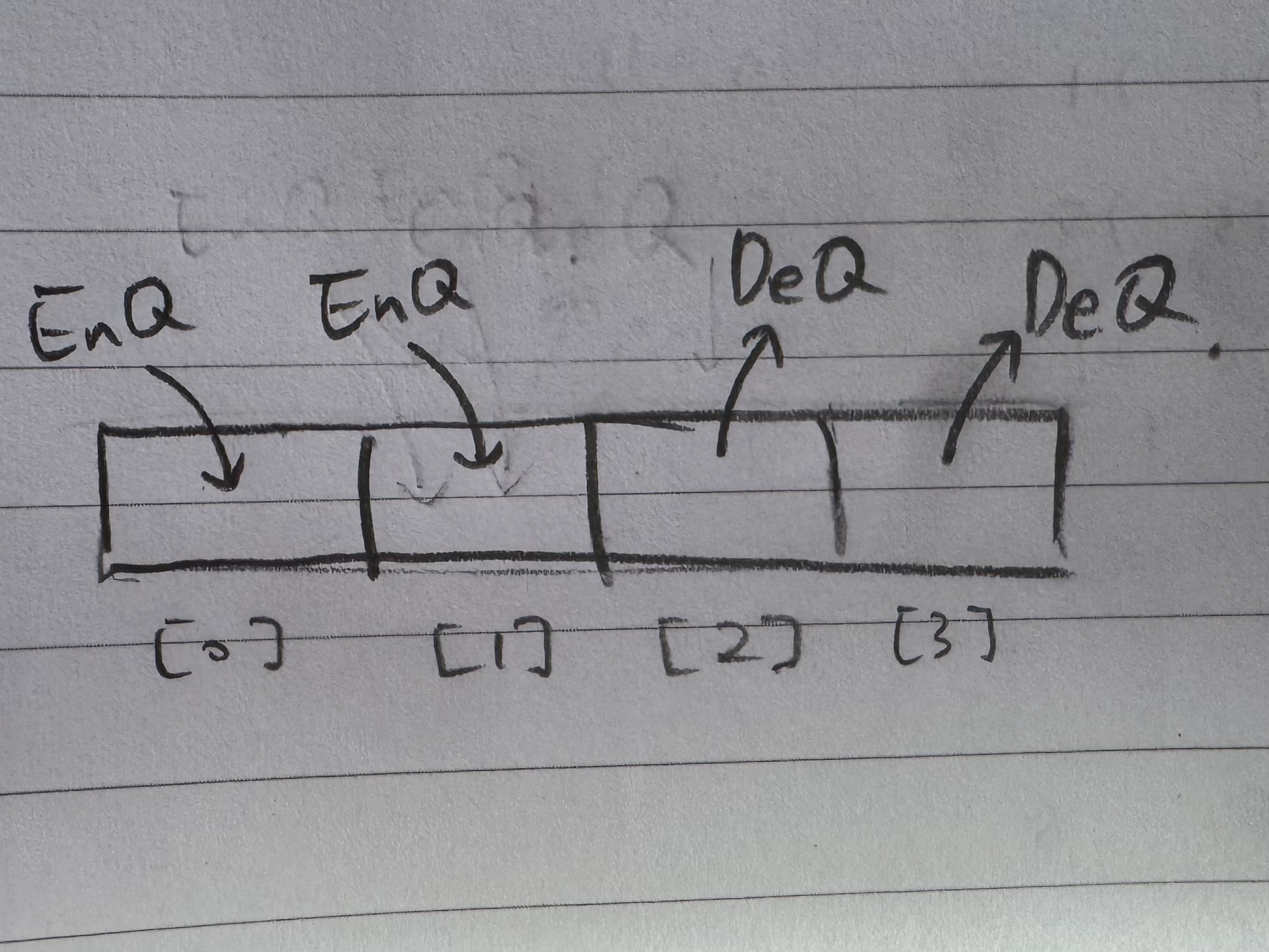
위 그림에서 [1]에 Enqueue하는 행위가 [0]에 Enqueue하는 행위 보다 느리게 끝나도 상관 없다.
즉, 임의의 스레드가 Enqueue/Dequeue할 인덱스를 설정할 때 다른 스레드에서 쓰고 있는 공간이면 안된다.
어떤 스레드가 배열에 접근할 때, 정확히 어느 인덱스에 접근할지 정하는 부분에서의 동시접근만 막으면 되는 것.
그럼 Dmitry Vyukov는 어떻게 구현했는가?
함수 bool enqueue(T const&)와 bool dequeue(T&)를 보면, 처음 enqueue_pos_.load(memory_order_relaxed)로 얻어서 저장한 pos 값과 반복문 내에서의 pos 값이 동일한지 검사한다.
그 과정에서 쓰이는 compare_exchange_weak는...
만약 enqueue_pos_의 값이 pos와 같으면 pos + 1로 값을 변경하고 true 반환하고,
반면 enqueue_pos_의 값이 pos와 다르면 곧바로 false 반환한다.
후자의 경우, 그 사이에 다른 스레드가 Enqueue하며 enqueue_pos_ 값을 변경했다는 것이고, compare_exchange_weak(...) 함수가 false를 리턴하여 다시 무한 루프 for(;;)를 돌며 Busy Wait한다.
그럼 드미트리 선생의 핵심 트릭,
enqueue_pos_의 값을 로드한 pos 값과 이 값을 이용하여 접근한 cell 객체의 sequence_ 값을 비교(dif ~ 0)하는 건 어떤 의도가 숨어 있는가?
Data Race는 앞서 기술한 과정에서 해소됐다고 할 때, Enqueue하는 경우를 생각해보자.
1. 비어있는 cell은 Enqueue만 할 수 있고, 채워져 있는 cell은 Dequeue만 할 수 있다.
2. 한번 채우고 비운 cell은 다음 라운드, 즉 sequence_ + buffer_size가 될 때까지 다시 채워 넣을 수 없다.
3. seq == pos인 경우, 비어 있다는 뜻.
4. seq < pos인 경우, 이미 채워져 있고 dequeue를 기다리는 인덱스에 접근했다는 뜻.
5. seq > pos인 경우는, 이미 누가 dequeue까지 끝나서 다음 라운드로 넘어갔거나이므로 전역 enqueue_pos_에서 load한다.
