이슈
서비스를 운영하다가 Production 환경에서 Celery worker 및 백엔드 서버에서 RabbitMQ Connection Refused 문제가 발생했다. 처음에는 오류 개수가 많지 않아서 일시적인 오류라 생각했으나, 꽤 많은 건수의 보고가 잡혀서 원인을 파악하고 문제를 해결해야 했다.
원인 파악
현재 Aws EKS 환경에서 RabbitMQ Cluster Operator를 활용해서 EKS 클러스터 내 RabbitMQ 를 운영하고 있다.
애플리케이션 및 노드 그리고 RabbitMQ 의 성능을 모니터링하기 위해 사내에서 Grafana + Prometheus를 활용하고 있다.
그 중 RabbitMQ 대시보드를 통해 Publisher, Consumer 수 In/out 메시지 per second 등 여러 가지 성능 지표들을 볼 수 있다.
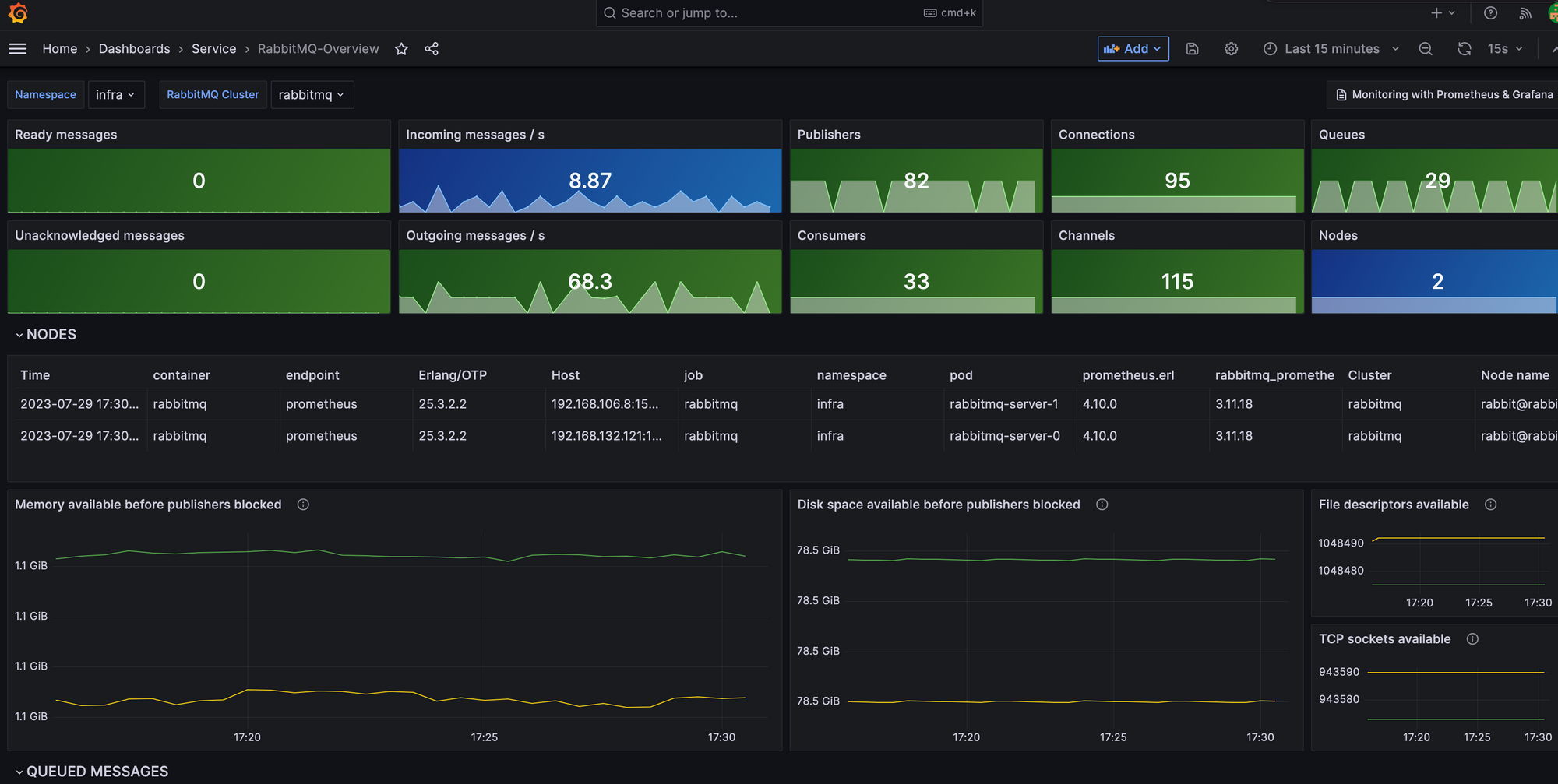
대시보드에서 RabbitMQ Connection Refused 에러가 많이 보고된 시간으로 time range를 설정하고 보니 다음과 같은 그래프를 볼 수 있었다.

눈에 띄는 지표는 Memory available before publishers blocked 및 Disk space available before publishers blocked 였다. 직관적으로 RabbitMQ 노드의 메모리가 부족해서 발생했구나라고 짐작할 수 있었다.
그런데 현재 RabbitMQ 노드의 메모리는 4GB 인데 왜 대시보드에서는 1GB 만 넘어가도 Publisher를 Block 시키는지 궁금하였다.
RabbitMQ 설정
RabbitMQ 공식 문서를 관련된 문서를 살펴보았다.
문서에 따르면 RabbitMQ 에는 vm_memory_high_watermark 라는 값이 있다. 이 값을 예를 들어 0.4(기본 값)로 설정하면 노드 메모리의 40% 초과 사용 시 메모리 경고를 발생시키고 모든 Publisher로부터의 Connection을 Block시킨다. 즉 이 옵션은 RabbitMQ가 OOM 을 방지하고 고가용성을 확보하기 위해 설정하는 옵션인 것이다.
우리의 경우 운영 시간에 RabbitMQ에 메시지가 과도하게 쌓여 노드 메모리의 40%를 초과하게 되었고, RabbitMQ가 Publisher들이 더이상 메시지를 보내지 못내도록 Block하였기 때문에 Publisher 단에서 Connection Refused를 받았던 것이었다.
RabbitMQ에서는 이를 좀 더 완화하기 위한 설정으로 vm_memory_high_watermark_paging_ratio 값을 설정할 수 있다. vm_memory_high_watermark_paging_ratio 은 큐가 메모리를 개방하기 위해 메시지를 디스크로 옮기기 시작하는 비율이다. 이 값을 높게 설정해 브로커가 high watermark에 다달아 publisher들을 block 하기 전에 메모리에 있는 컨텐츠를 디스크로 옮기는 작업을 통해 메모리의 부하를 줄일 수 있다.
평소 트래픽보다 오히려 덜 받았는데 큐에 메시지가 많이 쌓인 이유를 파악해보았다.
해당 시간 RabbitMQ의 큐를 확인했는데 dev 환경에서 쓰는 vhost의 queue가 꽉차있었다. 우리는 dev, production 환경의 애플리케이션들이 동일한 RabbitMQ 노드를 쓰고 vhost로 분리하여 사용하고 있었는데, 운영 시간에 AI 팀에서 dev 환경으로 엄청난 수의 요청을 보냈으나, 메시지를 처리하는 Consumer 인 AI 및 3D 서버의 노드 수를 늘리지 않아서 큐에 메시지가 과도하게 쌓이게 되었고 위 이슈를 일으켰던 것으로 파악하였다.
문제 해결
dev 환경에서의 어떠한 Operation도 운영환경에 절대 부하를 주어서는 안된다. dev환경을 활용하는 개발자가 항상 Consumer를 올바르게 설정할 것이라는 보장이 없다. 따라서 별도의 namespace를 만들고 dev 환경을 위한 RabbitMQ 를 구축하여 분리하는 것으로 문제를 해결하였다.