비동기 처리를 위해 Celery를 도입하려는데 메시지 브로커로 RabbitMQ, Redis 를 사용할 수 있다고 한다.
둘 중 하나를 선택하기 위해 분석해서 표로 정리해보았다.
| RabbitMQ | Redis |
|---|---|
| 메시지 브로커 용도로 개발 | 인메모리 데이터베이스 용도로 개발. 메시지 브로커 역할을 지원. |
| Redis에 비해 메시지 처리 속도는 느릴 수 있음. | 인메모리이기 때문에 메시지 처리 속도가 상대적으로 빠름 |
| 메시지 라우팅에 있어서 심화된 기능을 제공한다. | 기본적인 메시지 브로커로써의 라우팅 기능만을 제공한다. |
| 메시지를 저장하는 기능을 제공한다. Worker가 처리 실패한 경우 다시 메시지를 재 전송해서 처리할 수 있는 메커니즘을 제공한다. | 일시적으로 메시지를 전달하는 것만 지원한다. |
| 비교적 크기가 큰 메시지들을 처리하는데 유리하다. | 크기가 작은 메시지를 처리하는데 더 유용하다. |
| 메시지의 전달을 보장하기 때문에, 메시지의 손실이 없어야 하는 경우 적합하다. | 각 메시지의 전달을 보장해주지 않는다. |
내가 구현하려는 애플리케이션은 속도가 조금 느리더라도 메시지의 손실을 최소화 해야하기 때문에 RabbitMQ를 선택하였다.
그래서 오늘은 RabbitMQ 튜토리얼을 톺아보고 정리한 내용을 포스팅하려고 한다.
RabbitMQ
RabbitMQ는 메시지 브로커로 개발되었으며, 메시지라는 단위를 저장 및 전달한다. Rabbit MQ에서는 메시지 전달을 위해 크게 3가지 역할이 정의된다.
-
Producer
메시지를 생산하고 큐로 전달하는 프로그램이다.
-
Queue
RabbitMQ 안에 존재하는 메시지를 일시적으로 저장하는 저장소이다. queue는 RabbitMQ 서버가 설치되는 호스트의 메모리 및 디스크 용량에 한정된다.
여러 Producer들은 메시지를 queue 에 보내고, 여러 Consumer들은 queue 에 저장된 메시지를 읽어들인다.
-
Consumer
Consumer는 큐로부터 메시지를 소비하는 프로그램이다.
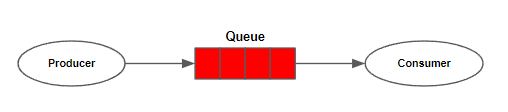
대략적인 구조는 위와 같다.
Work Queue
RabbitMQ와 같은 메시지 브로커를 사용하는 이유는 대부분 상대적으로 시간이 많이 걸리는 작업(Task)을 비동기로 처리하기 위함일 것이다.
보통은 부하 처리를 위해 consumer를 여러 개로 두는 경우가 많은데 이때 Work Queue의 동작 방식을 알아야 한다.
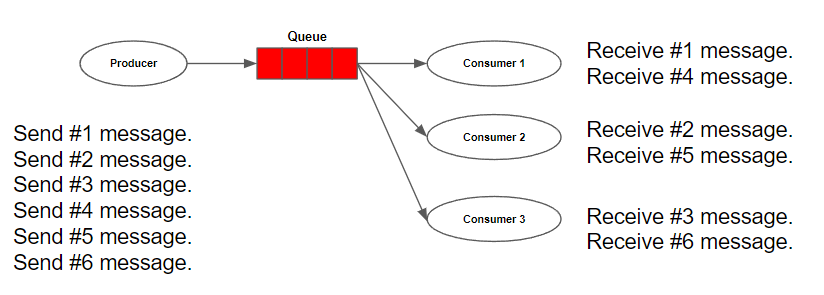
- Round-Robin Dispatching
consumer가 여러 개면 producer가 생산한 메시지를 병렬적으로 처리할 수 있다. RabbitMQ에서 consumer가 여러 개 일때 메시지를 보내는 방식은 Round-Robin 방식이다. 즉 연결된 consumer 들에 대해서 돌아가면서 메시지를 분배하여 모든 consumer 들은 평균적으로 같은 메시지를 받게 된다.
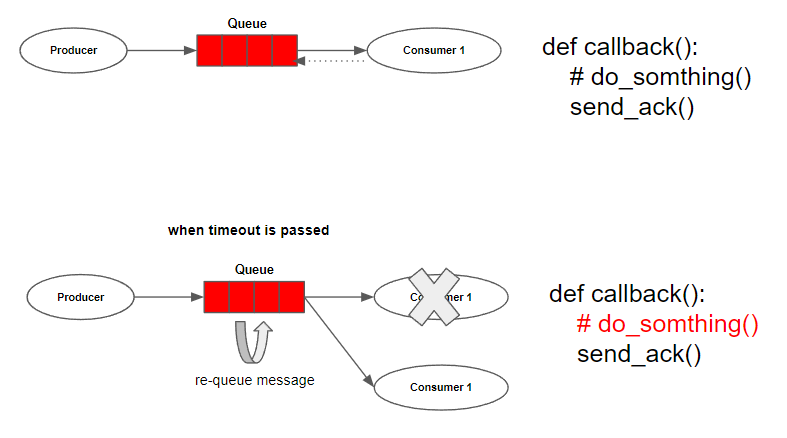
- Message Acknoledgement
consumer가 메시지를 받아 task를 처리하는데 오래 걸린다고 가정해보자. 만약 중간에 consumer 프로그램이 죽으면 어떻게 될까? 애플리케이션의 요구사항에 따라 다르겠지만, 일반적으로 처리가 완료되지 않은 작업은 다시 queue 에 들어가서 다른 worker에서 처리되는 것을 요구한다.
이를 달성하기 위해서 RabbitMQ는 Message acknowledgement라는 기능을 제공한다. Ack는 consumer가 메시지를 받고 나서 응답을 보내는 것이다. ack의 의미는 특정 메시지를 잘 받았고, 정상적으로 처리되었다는 것이며, RabbitMQ에서 그 메시지를 삭제해도 된다는 뜻이다.
만약 consumer가 ack를 보내지 않고 죽으면, RabbitMQ는 메시지가 완벽히처리 되지 않았다고 간주하며, 다시 해당 메시지를 queue 에 집어넣을 것이다.
task가 처리되는 시간은 상황에 따라 다르기 때문에 ack가 언제까지 오지 않았을 때, 메시지가 정상적으로 처리되지 않았다는 것을 인지하고 메시지를 다시 queue 에 넣을 것인지 판단하는 기준인 timeout을 설정해야 한다.
- Message durability
만약에 RabbitMQ 를 호스팅하고 있는 서버가 죽으면 어떻게 될까? queue 에 있는 메시지가 다 날아가면 내 작업들도 다 날아갈 것이다.
RabbitMQ에서는 queue, message들을 durable하게 만들 수 있는 메커니즘을 제공한다. messages, queue에 옵션을 넣으면 메모리에 있던 메시지들을 disk로 저장한다. 그러나, 모든 메시지를 손실 없이 저장할 수는 없는데, 메모리에 있던 메시지가 disk로 전달되기 전 서버가 죽을수 있기 때문에 100% 보장은 불가능하다.
- Fair Dispatch
consumer가 여러 개 있는 상황에서 처리 시간이 다른 task들이 생산된다고 가정하자. consumer1, consumer2는 동일한 프로그램이고 동일한 성능을 가지고 있다고 가정하자. 모든 홀수 번째 메시지들은 오랜 처리 시간을 가지고 모든 짝수 번째 메시지들은 짧은 처리 시간을 가진다 했을 때, 우리는 메시지를 효율적으로 처리할 수 있을까?
아까 설명했던 대로 RabbitMQ는 Round Robin 방식으로 메시지를 전달한다. 이 경우 메시지가 4 개가 들어왔다고 가정했을 때, consumer1가 긴 메시지를 처리할 동안 consumer2는 짧은 메시지만 처리하게 되기 때문에 남은 시간에 긴 메시지를 처리할 수 있음에도 불구하고 처리 효율이 떨어질 수 밖에 없다.
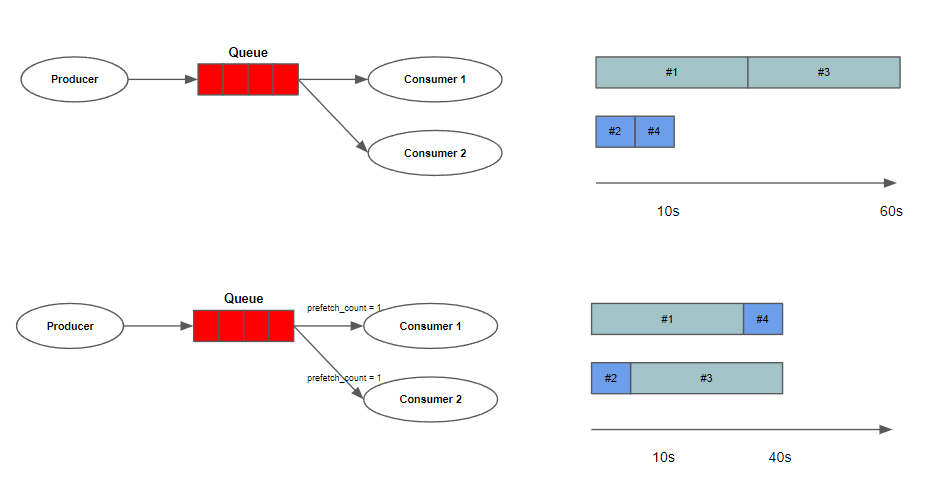
이 문제를 해결하기 위해서 RabbitMQ에서는 Channel#basic_qos 채널 method를 prefetch_count=1 세팅을 제공한다. 이 옵션을 주면 하나의 worker가 하나의 메시지만 전달 받고, 그 메시지에 대한 ack를 보내기 전까지 새로운 메시지를 받지 않는다는 것이다.
이렇게 되면 작업을 처리하고 있지 않은 한가한 worker에 메시지를 바로 분배할 수 있다.
Publish/Subscribe
위에 설명했던 메커니즘들은 하나의 queue를 가지고 설명했다. producer는 queue에게 메시지를 직접 보내는 식으로 이해할 수 있는데 원래는 그렇지 않다.
- exchanges
RabbitMQ에서는 producer가 메시지를 직접 queue 에 보내지 않는다. 바로 exchange 에 보낸다. exchange 는 producer로부터 온 메시지를 queue 에 전달하는 역할을 수행한다. 즉 exchange 는 메시지를 받았을 때 어떻게 전달해야 해야하는지를 명시하는 규칙 같은 것이라고 볼 수 있다. 어떤 특정 메시지는 어떤 queue에만 보내거나, 아님 여러 개의 queue에 보내야하는지? 등에 대한 규칙은 exchange type 이라고 부른다.
- exchange type
exchange type은 4가지가 있다. 애플리케이션에 따라 설정하면 된다.
- direct
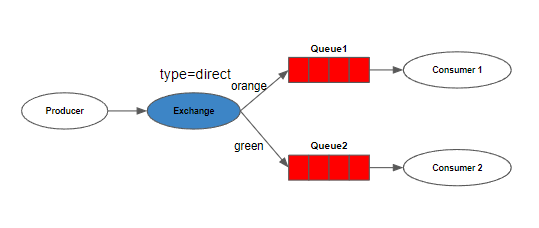
메시지에 포함된 routing key 를 기반으로 queue에 메시지를 전달한다. queue에는 binding key가 지정되어 있고 이 binding key를 바탕으로 메시지가 라우팅된다.
- topic
메시지에 임의의 routing_key를 지정하는 것이 아니라 점으로 구분되는 단어의 목록으로 routing_key를 지정하는 방법이다.
“stock.usd.nyse”, “nyse.vmw”, “quick.orange.rabbit” 와 같이 설정할 수 있다.
queue에 지정되는 binding key도 동일한 형태를 가져야 한다. exchange 에서는 메시지에 지정된 routing key를 가지고 일치하는 패턴의 binding key를 가지는 queue에 메시지를 라우팅한다.
binding key를 지정하는 두 개의 중요한 경우는 다음과 같다.
- *(star) 정확히 하나의 단어를 대체한다.
- #(hash) 는 0개 혹은 여러 개의 단어를 대체한다.
consumer들 사이에서 메시지 형태에 따라 선택적으로 수신 해야하는 조건이 필요할 때 유용하게 사용될 수 있다.
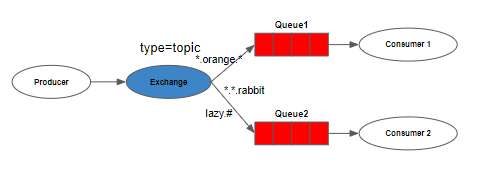
위의 예시에서 모든 동물을 묘사하는 메시지들을 보낸다고 가정해보자. Queue1은 오랜지 색 동물에 관심있고, Queue2는 토끼 혹은 게으른 모든 동물에 관심이 있다.
- quick.orange.rabbit 의 경우 → Queue1, Queue2에 전달
- quick.orange.fox의 경우 → Queue1에만 전달
- quick.brown.fox 의 경우 → 버려짐.
Topic의 경우 복잡한 메시지 라우팅이 필요할 때 사용할 수 있을 것 같다. 복잡한 마이크로 서비스를 설계할 때 도움이 많이 될 것 같다.
- headers
routing key 보다 메시지 헤더로 표현되는 여러 속성에 대한 라우팅을 위해 설계되었다. header type을 설정하면 routing key 속성은 무시되고, headers 속성에서 가져오게 된다.
- fanout
exchange에 등록된 모든 queue에 메시지를 broadcast 하는 방식이다.
RPC
RPC(Remote Procedure Call)은 원격 컴퓨터에 있는 프로시져를 호출하고 응답하는 패턴이다. RPC 시스템을 구축하기 위해서 RabbitMQ를 활용할 수 있다.
- client interface
원격 프로시져를 호출하는 client 입장에서 코드를 나타내면 다음과 같은 형식일 것이다.
fibonacci_rpc = FibonacciRpcClient()
result = fibonacci_rpc.call(4)
print("fib(4) is %r" % result)이 때 call함수는 RPC 요청에 대한 응답이 올 때까지 block될 것이다. 근데 RabbitMQ는 비동기 통신을 위해 만들어졌는데 이 메커니즘을 어떻게 구현할까?
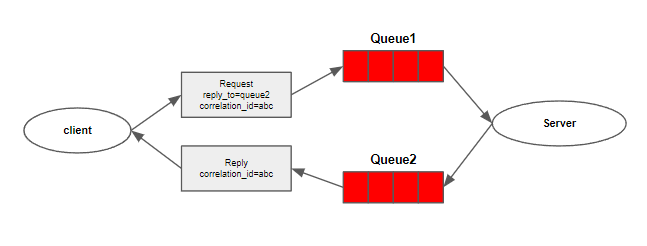
- callback queue
RabbitMQ에서는 callback queue를 메시지를 보낼 때 지정하게 함으로써 client가 server로부터 응답을 받을 수 있게 하였다.
result = channel.queue_declare(queue='', exclusive=True)
callback_queue = result.method.queue
channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = callback_queue,
),
body=request)- correlation id
사실 모든 RPC 요청에 대해서 callback queue를 생성할 수도 있으나, 그것 보다는 client당 하나의 callback queue를 생성해서 관리하는 것이 더 효율적이다. 그러나 이 구조에서 callback queue에 온 response들이 어떤 요청에 대한 response인지 분간이 안되기 때문에 correlation_id를 지정해서 어떤 요청에 대한 응답인지를 확인할 수 있다.
정리하며..
RabbitMQ 튜토리얼을 톺아보면서 RabbitMQ의 동작 방식에 대해 알아보았다. 복잡한 라우팅 스키마를 제공하고, 메시지 fallback을 지원하며, RabbitMQ 서버가 다운 시 메시지 복구 기능 지원, RPC 구현 등 엔터프라이즈 애플리케이션을 개발하는 데 필요한 기능들을 제공하기 때문에 많이 사용하는 것 같다.
공부하다가 궁금했던 부분은 Fair dispatch 를 위해 prefetch_count를 설정을 어떤 근거로 해야하는지 였다. task 평균 처리 시간이랑 queue와 consumer 사이의 통신 시간을 고려해서 최적의 prefetch_count를 설정해야 Worker들에게 작업을 효율적으로 배정할 수 있을 것 같은데, 이 부분은 자료를 좀 더 찾아보고 포스팅할 예정이다.