
1.캐싱이란?
캐싱은 리소스를 빠르게 로드하며 불필요한 요청을 줄일 수 있어서 매우 효과적입니다.
캐싱되는 데이터는 js,css,img 등의 파일과 네트워크 요청으로 받아오는 데이터입니다.
그럼 캐싱은 어떻게 설정하는 걸까요?
캐시는 리소스를 제공하는 곳과 리소스를 요청하는 곳에서 설정합니다.
브라우저는 필요한 리소스를 받기 위해 서버에 네트워크 요청을 합니다.
이 때, 어떤 요청 및 응답에 대한 데이터를 설정하는 곳이 있는데 바로 Request Header와 Response Header입니다. 단어 그대로 요청과 응답에 대한 헤더입니다.
이 곳엔 쿠키, 토큰 등의 데이터를 키 벨류 형태로 넣을 수가 있습니다.
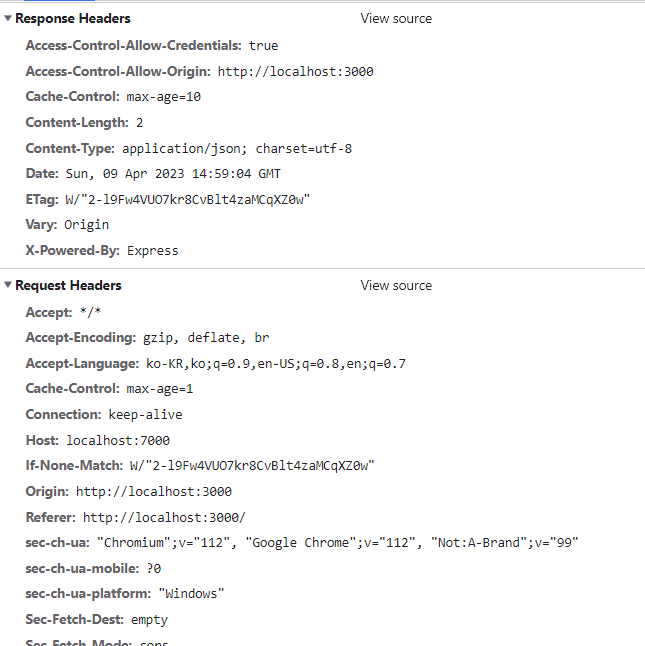
**캐시 또한 이 곳 헤더에 설정을 합니다
Cache-Control : max-age=10 이렇게 헤더에 설정을 하면 10초 동안 데이터를 캐싱하게 됩니다.
여기서 문제는 서버와 클라이언트 양쪽에서 캐싱을 설정을 할 수 있는데, 서버는 1시간으로 캐싱 설정을 했지만 클라이언트에서는 30분으로 했다면 어디를 기준으로 캐싱이 설정될까요
2.케이스별 캐싱의 동작
1번 케이스 - 클라이언트에서만 캐시를 설정했을 경우
fetch('http://localhost:7000/api/getName', {
method: 'GET',
headers: {
'Cache-Control': 'max-age=1800',
},
});캐싱 기간을 30분으로 설정한 후 서버에 요청하는 코드입니
요청을 해보면
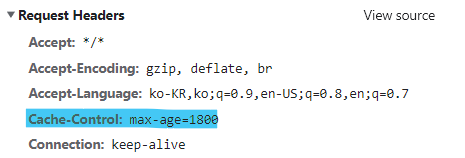
분명 캐시가 설정되었지만

캐싱되지않고 계속 데이터를 받아옵니다
즉, 서버에서 캐시 설정이 되어 있지 않다면 클라이언트에서 아무리 캐시를 설정해도 캐싱되지 않는다는 것이죠.
좀 더 자세히 설명하자면 사실 이것도 어느정도는 캐싱이 이루어진 것입니다. Browser는 자체적으로 요청을 캐싱한 후에 동일 요청이 있을때마다 if-none-match 헤더에 ETag(리소스의 ID라고 생각하면 됨)값을 넣어보내 서버의 리소스가 변경되었는지 확인합니다. 변경이 되지 않았다면 캐싱해둔 데이터를 그대로 사용합니다. 하지만 매번 서버와 통신하여 리소스 변경 유무를 확인하기 때문에 완전한 캐싱은 아닙니다.
2번 케이스 - 서버와 클라이언트 모두 캐싱 설정을 했으나 설정이 다를 때
app.get('/getName', async (req, res) => {
res.setHeader('Cache-Control', 'max-age=3600');
res.json({ name: 'tony' });
});name을 리턴하는 API다. 캐시를 1시간으로 정해주었습니다.
클라이언트는 1번 케이스와 동일하게 30분으로 캐시를 설정해주었습니다.
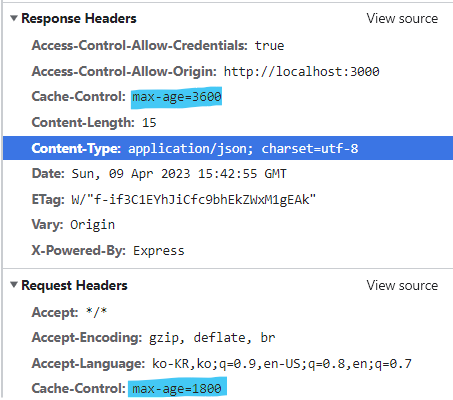
첫번째 요청을 보내면 이렇게 캐시가 설정된 걸 볼 수 있고,
두번째로 요청을 보내게되면

디스크에 캐싱된 것을 확인할 수 있습니다.
서버는 1시간 , 클라이언트는 30분으로 캐싱을 설정했는데, 과연 캐시는 얼마나 유지될까요?
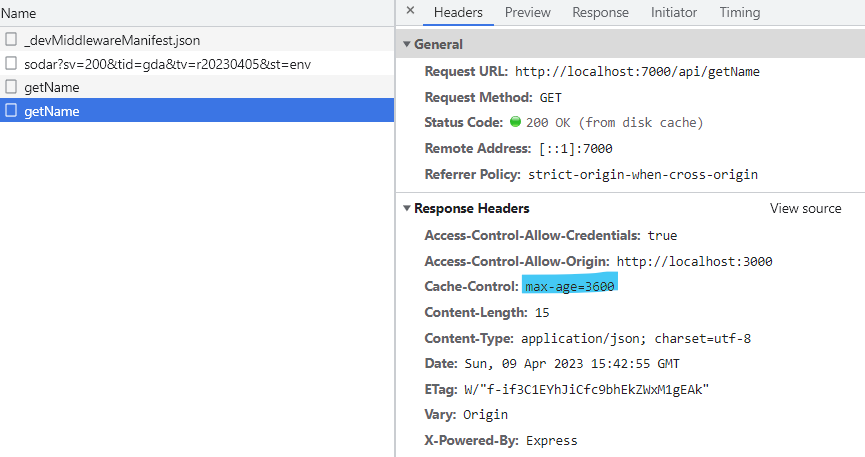
정답은 1시간입니다.
캐싱된 요청의 헤더를 보면 Request를 날리지 않기 때문에 Response헤더만 보이는걸 알 수 있죠. 응답을 캐싱하는 것이기 때문에 응답 헤더에 설정된 캐시가 설정된 것입니다.
그럼 클라이언트에서의 캐시 헤더는 아무짝에도 쓸모가 없을까요??
그건 아닙니다. 서버의 max-age값을 변경하는 것은 불가능하지만 캐시 자체를 하지 않도록 설정할 수는 있습니다.
max-age를 0으로 설정하거나, no-store, no-cache등의 옵션으로 캐싱을 방지할 수 있습니다.
이렇게 설정하면 서버에선 캐싱을 하도록 설정해도 브라우저는 매번 새로운 요청을 보냅니다.
그렇다면 서버에서 캐싱을 설정해주지 않으면 캐싱할 방법이 없을까요?
아닙니다. 방법이 있습니다. 바로 cache api를 이용하는 것입니다.
3. 클라이언트에서의 캐싱
cache api를 이용하여 응답을 캐시해뒀다가, 재요청이 발생하면 캐시된 응답(Promise)을 리턴하도록 구현하면 서버없이도 구현이 가능합니다.
그럼 또 의문이 들죠.
아니 그냥 Object에 데이터 저장해뒀다가 데이터 있으면 네트워크 요청 안하고 리턴하는거랑 뭐가 다르냐??
다릅니다.
Object에 캐싱을 할 경우 만료 기간, 버전 등을 설정하거나 캐시 크기를 제한하는 설정을 수동으로 해야 하며,
서로 다른 네트워크 요청이 많을수록 관리하기가 힘들고 코드가 더러워지기 때문에 cache api를 사용하는 것이 코드를 깔끔하게 짤 수 있습니다.
또한 cache api는 비동기적으로 동작하기 때문에 메인스레드가 차단될 일이 없습니다.
(물론 Object를 사용해서 캐싱을 구현했을때 메인스레드가 차단될 정도로 오버헤드가 발생하려면 데이터가 무지막지하게 많아야 할겁니다)
나아가, cache api는 브라우저 cache storage에 저장되기때문에, 브라우저를 열고 닫아도 캐시가 남아있다면 다시 네트워크 요청을 하지 않아도 되는 이점이 있습니다.
하지만 상황에 따라 일반 Object에 데이터를 캐싱하는 것이 더 나을 때도 있습니다.
바로 데이터가 큰 경우인데, cache api의 경우 응답의 body가 아닌 응답 자체를 캐싱하기 때문에 응답 안의 데이터는 역직렬화 해야 자바스크립트에서 사용가능합니다.
데이터가 클수록 시간이 오래 걸리기 때문에, 단순하게 최초 응답 시 역직렬화하여 객체에 저장해두면 잦은 요청 시에 역직렬화를 피할 수 있습니다.
항상 결론은 두루뭉술하게 상황에 맞게 캐싱 정책을 설정하는 것이 좋습니다!
