
📌 LangGraph - 병렬처리
1️⃣ 병렬 처리
-
분기(branching) 기능을 통해 LangGraph에서 노드의 병렬 실행이 가능
-
병렬 처리는 독립적인 작업들을 동시에 실행함으로써 전체 처리 시간을 단축
-
다양한 데이터 소스에서 정보 수집 및 처리가 필요한 경우 병렬 실행이 특히 효과적
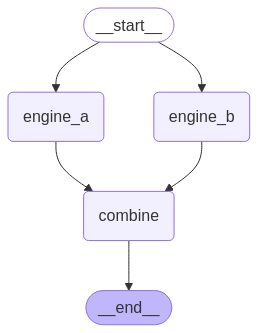
1. 표준 엣지를 사용한 분기 (Fan-out/Fan-in)
-
Fan-out 구조는 하나의 노드에서 여러 병렬 노드로 데이터를 분산시키는 방식을 구현
-
Fan-in 구조는 병렬로 처리된 여러 노드의 결과를 단일 노드에서 취합하는 역할
-
가장 기본적이고 직관적인 병렬 처리 구조
# 여러 검색 엔진에서 정보 가져오기
import operator
from typing import Annotated, Any, TypedDict
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
# 상태 정의: 검색 결과를 누적할 리스트를 포함
class SearchState(TypedDict):
search_results: Annotated[list, operator.add]
# 각 검색 엔진에 대한 노드 정의
def search_engine_a(state: SearchState):
print("Searching with Engine A...")
return {"search_results": ["Result A1", "Result A2"]}
def search_engine_b(state: SearchState):
print("Searching with Engine B...")
return {"search_results": ["Result B1"]}
def combine_results(state: SearchState):
print("Combining search results...")
return {"search_results": ["Combined Result"]}
# 그래프 구성
search_builder = StateGraph(SearchState)
search_builder.add_node("engine_a", search_engine_a)
search_builder.add_node("engine_b", search_engine_b)
search_builder.add_node("combine", combine_results)
# 엣지 연결: START -> engine_a, engine_b (병렬 실행) -> combine -> END
search_builder.add_edge(START, "engine_a")
search_builder.add_edge(START, "engine_b")
search_builder.add_edge("engine_a", "combine")
search_builder.add_edge("engine_b", "combine")
search_builder.add_edge("combine", END)
# 그래프 컴파일
search_graph = search_builder.compile()
# 그래프 시각화
display(Image(search_graph.get_graph().draw_mermaid_png()))- 출력
그래프 실행
# 그래프 실행
search_graph.invoke({"search_results": []})- 출력
Searching with Engine A...
Searching with Engine B...
Combining search results...{'search_results': ['Result A1', 'Result A2', 'Result B1', 'Combined Result']}2. 조건부 엣지를 사용한 분기 (Conditional Branching)
구현 예시
-
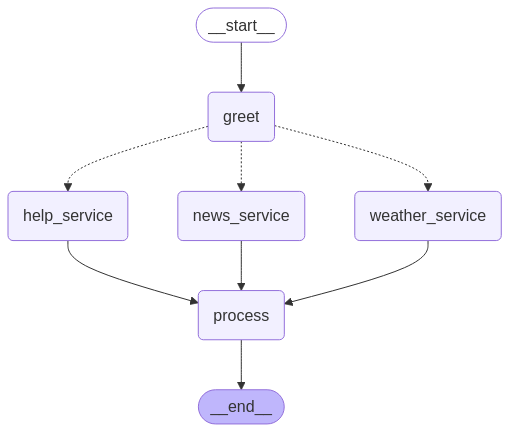
초기 그리팅 후 조건부로 서비스를 실행
-
선택된 서비스들을 병렬로 실행
-
모든 서비스 실행 후 최종 처리를 수행
-
전체 과정의 상태를 추적
import operator
from typing import Annotated, Sequence, TypedDict
from langgraph.graph import StateGraph, START, END
# 상태 정의: aggregate 리스트와 라우팅을 위한 user_intent 필드 포함
class ChatState(TypedDict):
messages: Annotated[list, operator.add] # aggregate 대신 messages 사용
user_intent: str # 라우팅 조건
# 서비스 노드 정의
def greet_service(state: ChatState):
print(f'Adding "greet" to {state["messages"]}')
return {"messages": ["Hello!"]}
def weather_service(state: ChatState):
print(f'Adding "weather" to {state["messages"]}')
return {"messages": ["The weather is sunny."]}
def news_service(state: ChatState):
print(f'Adding "news" to {state["messages"]}')
return {"messages": ["Here's the latest news."]}
def help_service(state: ChatState):
print(f'Adding "help" to {state["messages"]}')
return {"messages": ["How can I help you?"]}
def process_response(state: ChatState):
print(f'Adding "process" to {state["messages"]}')
return {"messages": ["Processing complete."]}
# 라우팅 함수: user_intent 값에 따라 서비스 노드 결정
def route_services(state: ChatState) -> Sequence[str]:
if state["user_intent"] == "weather_news":
# 날씨와 뉴스 서비스를 병렬 실행
return ["weather_service", "news_service"]
# 기본적으로 헬프 데스크와 뉴스 서비스를 병렬 실행
return ["help_service", "news_service"]
# 그래프 구성
chat_builder = StateGraph(ChatState)
# 노드 추가
chat_builder.add_node("greet", greet_service)
chat_builder.add_node("weather_service", weather_service)
chat_builder.add_node("news_service", news_service)
chat_builder.add_node("help_service", help_service)
chat_builder.add_node("process", process_response)
# 엣지 추가
chat_builder.add_edge(START, "greet")
# 중간 노드 정의
intermediates = ["weather_service", "news_service", "help_service"]
# greet 노드에서 조건부 엣지 추가
chat_builder.add_conditional_edges(
"greet",
route_services,
intermediates,
)
# 중간 노드들을 process 노드에 연결
for node in intermediates:
chat_builder.add_edge(node, "process")
chat_builder.add_edge("process", END)
# 그래프 컴파일
chat_graph = chat_builder.compile()
# 그래프 시각화
display(Image(chat_graph.get_graph().draw_mermaid_png()))- 출력
그래프 실행 (1)
# "weather_news" 의도를 가지고 실행
chat_graph.invoke({"messages": [], "user_intent": "weather_news"})- 출력
Adding "greet" to []
Adding "weather" to ['Hello!']
Adding "news" to ['Hello!']
Adding "process" to ['Hello!', "Here's the latest news.", 'The weather is sunny.']{'messages': ['Hello!',
"Here's the latest news.",
'The weather is sunny.',
'Processing complete.'],
'user_intent': 'weather_news'}그래프 실행 (2)
# 다른 의도를 가지고 실행
chat_graph.invoke({"messages": [], "user_intent": "news"})- 출력
Adding "greet" to []
Adding "news" to ['Hello!']
Adding "help" to ['Hello!']
Adding "process" to ['Hello!', 'How can I help you?', "Here's the latest news."]{'messages': ['Hello!',
'How can I help you?',
"Here's the latest news.",
'Processing complete.'],
'user_intent': 'news'}3. 다단계 분기 (Multi-Step Parallel Paths)
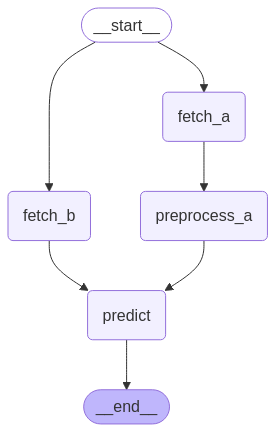
-
다단계 분기는 각각의 병렬 경로에서 여러 단계의 독립적인 처리를 지원
-
각 분기는 서로 다른 데이터 처리 파이프라인을 포함할 수 있어, 복잡한 워크플로우 구현이 가능
-
최종적으로 각 분기의 결과는 하나의 노드에서 통합되어 처리될 수 있음
# 데이터 전처리와 모델 예측을 병렬로 수행하기
import operator
from typing import Annotated, TypedDict
from langgraph.graph import StateGraph, START, END
class ModelState(TypedDict):
data: Annotated[list, operator.add]
def fetch_data_a(state: ModelState):
return {"data": ["Data A1"]}
def preprocess_data_a(state: ModelState):
return {"data": ["Preprocessed A1"]}
def fetch_data_b(state: ModelState):
return {"data": ["Data B1"]}
def make_prediction(state: ModelState):
return {"data": ["Prediction from A and B"]}
model_builder = StateGraph(ModelState)
model_builder.add_node("fetch_a", fetch_data_a)
model_builder.add_node("preprocess_a", preprocess_data_a)
model_builder.add_node("fetch_b", fetch_data_b)
model_builder.add_node("predict", make_prediction)
model_builder.add_edge(START, "fetch_a")
model_builder.add_edge(START, "fetch_b")
model_builder.add_edge("fetch_a", "preprocess_a")
model_builder.add_edge(["preprocess_a", "fetch_b"], "predict")
model_builder.add_edge("predict", END)
model_graph = model_builder.compile()
display(Image(model_graph.get_graph().draw_mermaid_png()))- 출력
그래프 실행
# 그래프 실행
model_graph.invoke({"data": []})- 출력
{'data': ['Data A1', 'Data B1', 'Preprocessed A1', 'Prediction from A and B']}4. 동적 엣지 생성 및 개별 상태 전달하기 (Map-Reduce 패턴)
-
기본 동작의 한계
-
기본적으로 LangGraph의 노드와 엣지는 미리 정의되며, 모든 노드는 동일한 공유 상태(shared state)를 사용함. 하지만 다음과 같은 경우에는 문제가 발생할 수 있음.
-
동적 엣지: 실행 시점에 따라 연결해야 할 노드의 수가 달라지는 경우 (예: 입력 데이터에 따라 다른 개수의 하위 작업을 생성해야 하는 경우)
-
개별 상태: 각 노드가 독립적인 상태를 가지고 작업해야 하는 경우 (예: 각 하위 작업이 서로 다른 데이터를 처리해야 하는 경우)
-
-
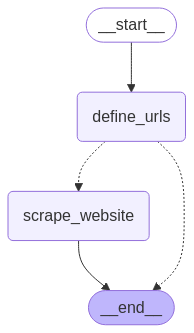
Map-Reduce 패턴
- Map: 하나의 노드(mapper)가 여러 개의 객체(또는 작업)를 생성
- Reduce: 다른 노드(reducer)가 mapper가 생성한 객체들을 처리하고 결과를 결합
-
Send객체-
LangGraph에서는
Send객체를 사용하여 map 단계를 구현할 수 있음 -
Send객체는 조건부 엣지(add_conditional_edges)의condition_function에서 반환될 수 있으며, 다음과 같은 두 가지 인수를 받아서 구현node_name(str): 실행할 노드의 이름state(dict): 해당 노드에 전달할 개별 상태
-
import operator
from typing import Annotated, List, TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.types import Send
from IPython.display import Image, display
# 글로벌 상태 정의
class WebScrapingState(TypedDict):
urls: List[str] # 스크래핑할 URL 목록 (글로벌)
scraped_data: Annotated[List[dict], operator.add] # 스크래핑된 데이터 (글로벌, 누적)
# 노드 정의
def define_urls(state: WebScrapingState):
"""URL 목록을 정의합니다. (글로벌 상태 사용)"""
print("Using provided URLs...")
return {"urls": state["urls"]} # 글로벌 상태(urls) 사용
def scrape_website(state: dict): # 로컬 상태를 받음
"""각 웹사이트를 스크래핑합니다. (로컬 상태 사용)"""
print(f"Scraping {state['url']}...") # 로컬 상태(url) 사용
# 실제 스크래핑 로직 (여기서는 시뮬레이션)
return {"scraped_data": [f"Data from {state['url']}"]} # 글로벌 상태(scraped_data) 사용
def route_to_scraping(state: WebScrapingState):
"""스크래핑 노드로 라우팅합니다. (글로벌 상태 사용, 로컬 상태 생성)"""
if not state["urls"]:
# URL 목록이 없으므로 바로 END 노드로 이동
print("No URLs provided. Terminating flow.")
return [Send(END, {})]
# 글로벌 상태(urls)를 사용하여 로컬 상태({"url": url})를 생성하고 Send로 전달
return [Send("scrape_website", {"url": url}) for url in state["urls"]]
# 그래프 구성
graph = StateGraph(WebScrapingState)
graph.add_node("define_urls", define_urls)
graph.add_node("scrape_website", scrape_website)
graph.set_entry_point("define_urls") # 시작 노드 설정, graph.add_edge(START, "define_urls")와 동일
graph.add_conditional_edges(
"define_urls",
route_to_scraping,
)
graph.add_edge("scrape_website", END)
# 그래프 컴파일
compiled_graph = graph.compile()
# 그래프 시각화
display(Image(compiled_graph.get_graph().draw_mermaid_png())) route_to_scraping에서 현재state['urls']로 리스트 형태이기에 각각의 url 을 불러 스크래핑 노드를 실행하기 위해 로컬 상태 딕셔너리로state['url']을 생성한다.
- 출력
그래프 실행
# 그래프 실행 (외부에서 URL 목록 입력)
initial_state = {"urls": ["https://example.com", "https://example.net", "https://example.org"]}
result = compiled_graph.invoke(initial_state)
print("-"*100)
pprint(result)- 출력
Using provided URLs...
Scraping https://example.com...
Scraping https://example.net...
Scraping https://example.org...
----------------------------------------------------------------------------------------------------
{'scraped_data': ['Data from https://example.com',
'Data from https://example.net',
'Data from https://example.org'],
'urls': ['https://example.com', 'https://example.net', 'https://example.org']}