
(2) FAISS 에 이어 계속됩니다.
📌 Pinecone
- 상용 클라우드 기반의 벡터 데이터베이스 서비스 (SaaS)
- 실시간 고성능 벡터 검색 제공
- 회원가입 및 API 인증키 발급 (.env 파일에
PINECONE_API_KEY등록) - 설치:
pip install langchain-pinecone pinecone-notebooks/poetry add langchain-pinecone pinecone-notebooks
- 회원가입 및 로그인 후 Organization / Project 생성 후 우상단의
Generate API key에서 API key 생성 - 생성 당시 이후로는 API 키 확인이 불가하기 때문에
.env파일에 복사 및 저장하도록 한다. PINECONE_API_KEY=' *** ...'
1. 환경 설정
# PINECONE_API_KEY 환경 변수 설정 후에 실행
from dotenv import load_dotenv
load_dotenv()# 인증 설정
import os
from pinecone import Pinecone, ServerlessSpec
pinecone_api_key = os.environ.get("PINECONE_API_KEY")
pc = Pinecone(api_key=pinecone_api_key)# 기존 인덱스 리스트 확인
existing_indexes = [index_info["name"] for index_info in pc.list_indexes()]
print(f"기존 인덱스: {existing_indexes}")인덱스 리스트 형태
pc.list_indexes()- 출력
[
{
"name": "ai-sample",
"dimension": 1024,
"metric": "euclidean",
"host": "ai-sample-sesac-6ckgty0.svc.aped-4627-b74a.pinecone.io",
"spec": {
"serverless": {
"cloud": "aws",
"region": "us-east-1"
}
},
"status": {
"ready": true,
"state": "Ready"
},
"deletion_protection": "disabled"
},
...
]2. 벡터 저장소 초기화
import time
# 인데스 이름 설정
index_name = "ai-sample"
# 인덱스가 없으면 생성
if index_name not in existing_indexes:
pc.create_index(
name=index_name,
dimension=1024,
metric="euclidean", # 유사도 측정 방법 - euclidean, cosine, dotproduct
spec=ServerlessSpec(cloud="aws", region="us-east-1"),
)
while not pc.describe_index(index_name).status["ready"]:
time.sleep(1)
# 인덱스 이름을 사용하여 인덱스 객체 생성
index = pc.Index(index_name)
▶ index 가 생성된 모습, 혹은 Pinecone 홈페이지에서 직접 인덱스를 생성해도 된다.

인덱스 정보 확인
# 인덱스 정보 확인
index_name = "ai-sample"
index_info = pc.describe_index(index_name)
index_info- 출력
{
"name": "ai-sample",
"dimension": 1024,
"metric": "euclidean",
"host": "ai-sample-6ckgty0.svc.aped-4627-b74a.pinecone.io",
"spec": {
"serverless": {
"cloud": "aws",
"region": "us-east-1"
}
},
"status": {
"ready": true,
"state": "Ready"
},
"deletion_protection": "disabled"
}벡터 저장소 생성
from langchain_pinecone import PineconeVectorStore
# PINECONE 벡터 저장소 생성
pinecone_db = PineconeVectorStore(index=index, embedding=embeddings_model)
# 벡터 저장소 객체 확인
pinecone_db- 출력
<langchain_pinecone.vectorstores.PineconeVectorStore at 0x2b707...>저장된 문서 갯수 확인
# 저장된 문서의 갯수 확인
pinecone_db._index.describe_index_stats()- 출력
{'dimension': 1024,
'index_fullness': 0.0,
'namespaces': {},
'total_vector_count': 0}2. 벡터 저장소 관리
- 문서 추가:
vector_store.add_documents(documents, ids)
from langchain_core.documents import Document
# 문서 데이터 - (텍스트, 소스)
documents = [
("인공지능은 컴퓨터 과학의 한 분야입니다.", "AI 개론"),
("머신러닝은 인공지능의 하위 분야입니다.", "AI 개론"),
("딥러닝은 머신러닝의 한 종류입니다.", "딥러닝 입문"),
("자연어 처리는 컴퓨터가 인간의 언어를 이해하고 생성하는 기술입니다.", "AI 개론"),
("컴퓨터 비전은 컴퓨터가 디지털 이미지나 비디오를 이해하는 방법을 연구합니다.", "딥러닝 입문")
]
# Document 객체 생성
doc_objects = []
for content, source in documents:
doc = Document(
page_content=content,
metadata={"source": source},
)
doc_objects.append(doc)
# 순차적 ID 리스트 생성
doc_ids = [f"DOC_{i}" for i in range(1, len(doc_objects) + 1)]
# 문서를 벡터 저장소에 저장
added_doc_ids = pinecone_db.add_documents(documents=doc_objects, ids=doc_ids)
# 벡터 저장소에 저장된 문서를 확인
print(f"{len(added_doc_ids)}개의 문서가 성공적으로 벡터 저장소에 추가되었습니다.")
print(added_doc_ids)- 출력
5개의 문서가 성공적으로 벡터 저장소에 추가되었습니다.
['DOC_1', 'DOC_2', 'DOC_3', 'DOC_4', 'DOC_5']저장된 문서 갯수 확인
# 저장된 문서의 갯수 확인 - 동기화에 시간이 걸릴 수 있음
pinecone_db._index.describe_index_stats()- 출력
{'dimension': 1024,
'index_fullness': 0.0,
'namespaces': {'': {'vector_count': 5}},
'total_vector_count': 5} 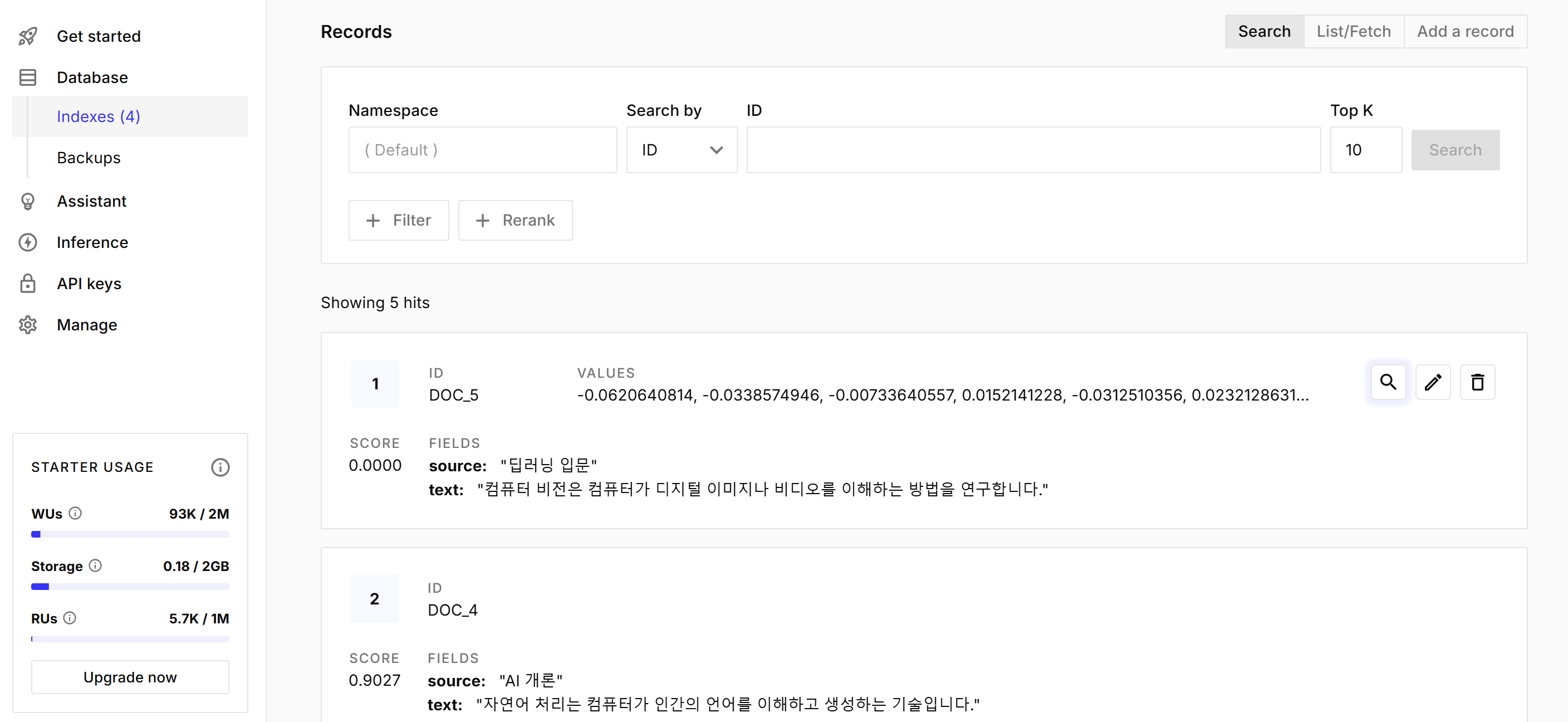
▶ 문서가 저장된 모습
- 문서 삭제:
vector_store.delete(ids)
# 문서 id를 지정하여 삭제
pinecone_db.delete(ids=["DOC_5"])# 컬렉션 확인
pinecone_db._index.describe_index_stats()- 출력
{'dimension': 1024,
'index_fullness': 0.0,
'namespaces': {'': {'vector_count': 4}},
'total_vector_count': 4}3. 문서 검색
- 유사도 검색
similarity_search- 주어진 쿼리와 가장 유사한 문서를 반환
- k=2는 상위 2개의 결과를 반환하도록 지정
- filter를 사용하여 특정 출처의 문서만 검색 가능
query = "인공지능과 머신러닝의 차이점은 무엇인가요?"
results = pinecone_db.similarity_search(
query,
k=2,
filter={"source": "AI 개론"}
)
print("유사도 검색 결과:")
for doc in results:
print(f"- {doc.page_content} [출처: {doc.metadata['source']}]")- 출력
유사도 검색 결과:
- 머신러닝은 인공지능의 하위 분야입니다. [출처: AI 개론]
- 인공지능은 컴퓨터 과학의 한 분야입니다. [출처: AI 개론]- 유사도 점수가 포함된 검색
similarity_search_with_score- 유사도 점수를 함께 반환
- 점수가 낮을수록 더 유사한 것을 의미 (거리 기준으로 점수가 산정되기 때문)
query = "딥러닝은 어떤 분야에서 사용되나요?"
results = pinecone_db.similarity_search_with_score(
query,
k=2,
filter={"source": "AI 개론"}
)
print("점수가 포함된 유사도 검색 결과:\n")
for doc, score in results:
print(f"- 점수: {score:.4f}")
print(f" 내용: {doc.page_content}")
print(f" [출처: {doc.metadata['source']}]")
print()- 출력
점수가 포함된 유사도 검색 결과:
- 점수: 0.8444
내용: 머신러닝은 인공지능의 하위 분야입니다.
[출처: AI 개론]
- 점수: 0.9846
내용: 인공지능은 컴퓨터 과학의 한 분야입니다.
[출처: AI 개론]- 관련성 점수가 포함된 검색
similarity_search_with_relevance_scores- 문서와 함께 0에서 1 사이의 관련성 점수를 반환
- 0은 가장 관련성이 낮고, 1은 가장 관련성이 높음을 의미
query = "딥러닝은 어떤 분야에서 사용되나요?"
results = pinecone_db.similarity_search_with_relevance_scores(
query,
k=2,
filter={"source": "AI 개론"}
)
print(f"쿼리: {query}")
print("\n검색 결과 (관련성 점수 포함):")
for doc, score in results:
print(f"- 관련성 점수: {score:.4f}")
print(f" 내용: {doc.page_content}")
print(f" [출처: {doc.metadata['source']}]")
print()- 출력
쿼리: 딥러닝은 어떤 분야에서 사용되나요?
검색 결과 (관련성 점수 포함):
- 관련성 점수: 0.9221
내용: 머신러닝은 인공지능의 하위 분야입니다.
[출처: AI 개론]
- 관련성 점수: 0.9923
내용: 인공지능은 컴퓨터 과학의 한 분야입니다.
[출처: AI 개론]4. 벡터 저장소 로드
# 저장된 인덱스 확인해서 초기화
index_name = "ai-sample"
index = pc.Index(index_name)
pinecone_db2 = PineconeVectorStore(index=index, embedding=embeddings_model)
# 저장된 문서 정보를 확인
pinecone_db2._index.describe_index_stats()- 출력
{'dimension': 1024,
'index_fullness': 0.0,
'namespaces': {'': {'vector_count': 4}},
'total_vector_count': 4}