
📌 Numpy
- 파이썬 기본 리스트의 한계 극복
- 연산 최적화 X
- 대규모 수치 연산시 속도 저하
- 메모리 사용 비효율적
- 벡터 연산 불가, 반복문 사용
Matlab과 같은 수치계산 환경 필요
- 과학/공학 연구자들이 오픈소스 기반의 수치 계산 환경 필요
- C언어로 구현된 파이썬 라이브러리(외부 라이브러리)
- 고성능 수치계산을 위해 만들어진 파이썬 패키지
Vector,Matrix,n-th array(ndarray)등의 데이터 분석을 위한 패키지- 벡터 및 행렬 연산에 있어서 매우 편리한 기능을 제공
- 벡터화 연산, 정교한 브로드캐스팅 기능
- 반복문 없는 빠른 데이터 처리, 빠르고 효율적인 메모리 관리
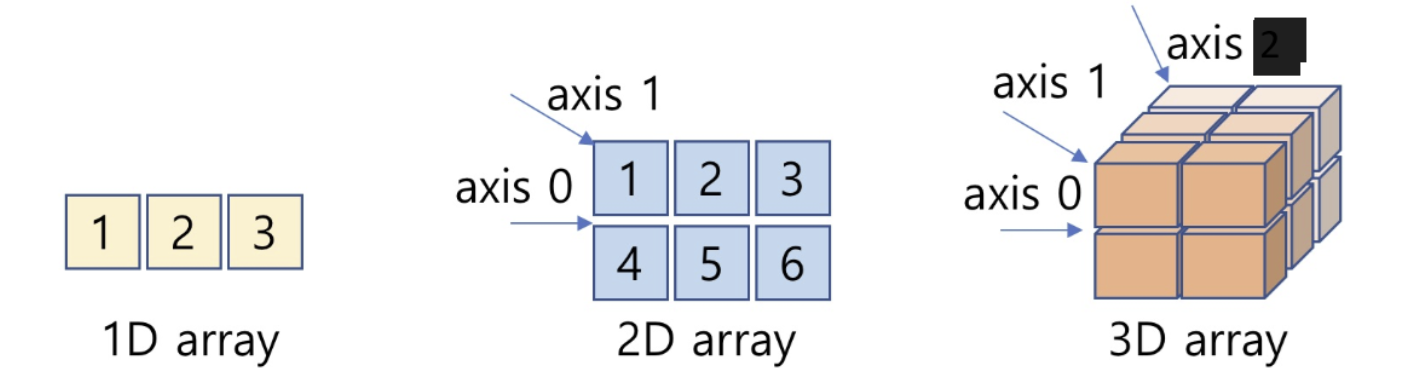
array(배열)단위로 데이터를 관리하며 이에 대해 연산을 수행
- Numpy의 기본단위가 되는
array는 Dynamic type을 지원하지 않음. 한 타입만 지원- 1차원의 Numpy array :
Vector- 2차원의 Numpy array :
Matrix- 3차원 이상의 Numpy array :
Tensor
Numpy모듈 설치
!pip install numpyNumpy모듈 임포트- 보통
as np(alias) 를 사용하여np라 흔히 칭한다.
- 보통
import numpy as np선언된 모듈과 패키지의 영향 범위
- 파이썬(or IPython) 콘솔이나 주피터 노트북의 코드 셀에서 import로 불러온 모듈이나 패키지는 한번만 선언하면 다시 선언하지 않고 이용가능
- 주피터 노트북에서 새로운 노트북을 실행한 경우 다시 선언 필요
- 파이썬 코드를 파일로 저장할 때도 모듈과 패키지는 이를 사용하는 코드 앞에 한번만 선언
📌 Array 정의 및 생성
- 시퀀스 데이터(리스트, 튜플 등)로부터 배열 생성
1️⃣ np.array()
arr_obj = np.array(seq_data)
data1 = [1, 2, 3]
arr1 = np.array(data1)
arr1- 출력
array([1, 2, 3])배열 타입
type(arr1)- 출력
numpy.ndarray배열 리스트로 반환
list1 = arr1.tolist()
list1- 출력
[1, 2, 3]① .shape
- Array 크기 확인, 튜플 형태로 반환
(n, ): 1차원 배열,(n, m): 2차원 배열,(n, m, l): 3차원 배열
1차원 배열
arr1 = np.array([1, 2, 3])
arr1.shape- 출력
(3,)2차원 배열
arr2 = np.array([[1, 2], [3, 4]])
arr2.shape- 출력
(2, 2)② .dtype
Numpy자료형
- 부호가 있는 정수
int(8, 16, 32, 64)- 부호가 없는 정수
uint(8 ,16, 32, 64)- 실수
float(16, 32, 64, 128)- 복소수
complex(64, 128, 256)- 불리언
bool- 문자열
string_- 파이썬 오프젝트
object- 유니코드
unicode_
- Array 자료형 확인
- 정수형 (INT) 은 기본값이
'int64'자료형
정수형 (INT)
arr1 = np.array([1, 2, 3])
arr1.dtype- 출력
dtype('int64')실수형 (FLOAT)
arr3 = np.array([1.3, 4, 7.9, 10, 5])
arr3.dtype- 출력
dtype('float64')문자열 포함
dtype='<U21'U: Unicode 문자열 기반 의미 (utf-32 기반), 각 문자는 내부적으로 4바이트 (32비트)를 사용21: 최대 문자열 길이, 최대 21개의 유니코드 문자 저장 가능한 고정길이 문자열- Numpy 는 문자열이 가변길이가 아닌 고정길이 문자열 사용
<: 최대 21개 문자열 길이를 넘지 않음을 의미'<U21': 21 * 4 = 84바이트 차지하는 문자열
arr4 = np.array([0, 1, 2, 4, 'a'])
arr4.dtype- 출력
dtype('<U21')Ex) 가장 긴 문자열 길이가 6 이라서 데이터 타입이 U6 로 나타나는 모습이다.
arr5 = np.array(['hello', 'world!'])
arr5- 출력
array(['hello', 'world!'], dtype='<U6')Object
- 시퀀스가 아닌 딕셔너리가 포함된 경우 0차원으로 취급한다.
arr8 = np.array({'name': 'Kim', 'addr': 'Seoul'})
arr8.shape, arr8.dtype - 출력
((), dtype('O'))- 딕셔너리를 리스트로 감싸게 되면 1차원 배열이 된다.
arr9 = np.array([{'name': 'Kim', 'addr': 'Seoul'}, {'name': 'Lee', 'addr': 'Seoul'}])
arr9.shape, arr9.dtype- 출력
((2,), dtype('O'))2️⃣ np.arange()
arr_obj = np.arange([start,] stop[, step])
np.arange(10)- 출력
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])- 파이썬의
range와 같은 원리이다.
np.arange(10, -5, -1)- 출력
array([10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0, -1, -2, -3, -4])3️⃣ .reshape()
Array형태를 원하는 크기로 변경한다. 따라서 만들고자 하는 크기와Array의 크기가 동일해야 한다.
np.arange(12).reshape(3, 4)- 출력
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])- 2 x 3 x 2 = 12 로 여러 가지 형태의 차원으로 변경 가능하다.
np.arange(12).reshape(2, 3, 2)- 출력
array([[[ 0, 1],
[ 2, 3],
[ 4, 5]],
[[ 6, 7],
[ 8, 9],
[10, 11]]])4️⃣ np.linspace()
arr.obj = np.linspace(start, stop[, num=50])
start와stop범위를 일정한 간격으로 쪼개주는 함수로, 기본값은 50개 구간이다.
np.linspace(1, 10)- 출력
array([ 1. , 1.18367347, 1.36734694, 1.55102041, 1.73469388,
1.91836735, 2.10204082, 2.28571429, 2.46938776, 2.65306122,
2.83673469, 3.02040816, 3.20408163, 3.3877551 , 3.57142857,
3.75510204, 3.93877551, 4.12244898, 4.30612245, 4.48979592,
4.67346939, 4.85714286, 5.04081633, 5.2244898 , 5.40816327,
5.59183673, 5.7755102 , 5.95918367, 6.14285714, 6.32653061,
6.51020408, 6.69387755, 6.87755102, 7.06122449, 7.24489796,
7.42857143, 7.6122449 , 7.79591837, 7.97959184, 8.16326531,
8.34693878, 8.53061224, 8.71428571, 8.89795918, 9.08163265,
9.26530612, 9.44897959, 9.63265306, 9.81632653, 10. ])pi 값 20개 구간으로 나누기
np.linspace(1, np.pi, 20)- 출력
array([1. , 1.1127154 , 1.22543081, 1.33814621, 1.45086161,
1.56357701, 1.67629242, 1.78900782, 1.90172322, 2.01443863,
2.12715403, 2.23986943, 2.35258483, 2.46530024, 2.57801564,
2.69073104, 2.80344645, 2.91616185, 3.02887725, 3.14159265])5️⃣ np.zeros()
np.zeros(shape, dtype=float, ...)
- 모든 요소가 0인 배열 생성
np.zeros(5)- 출력
array([0., 0., 0., 0., 0.]).reshape()과dtype변경도 가능하다.
np.zeros(15).reshape(3, 5)
np.zeros(10, dtype='int64')6️⃣ np.ones()
np.ones(shape, dtype=None)
- 모든 요소가 1인 배열 생성
np.ones(10)- 출력
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]).reshape없이 처음부터 다차원 배열로 생성도 가능하다.
np.ones((2, 5), dtype='int32')- 출력
array([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]], dtype=int32)7️⃣ np.eye()
np.eye(N, M, k=K, dtype=자료형)
- 대각요소가 1인 배열 생성
행, 열 크기 모두 4인 정방행렬의 대각요소가 1인 단위행렬
np.eye(4)4행 6열의 행렬
np.eye(4, 6)- 출력
array([[1., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0.],
[0., 0., 0., 1., 0., 0.]])대각요소 위치 이동
k: 대각요소의 행 위치를 오른쪽으로k만큼 이동시킨다.
np.eye(4, 6, k=1) # 대각 요소 시작 행 이동 값 k- 출력
array([[0., 1., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0.],
[0., 0., 0., 1., 0., 0.],
[0., 0., 0., 0., 1., 0.]])8️⃣ np.identity()
np.identity(n, dtype=자료형)
- 대각요소가 1인 배열 생성
np.identity(3, dtype='int32')- 출력
array([[1, 0, 0],
[0, 1, 0],
[0, 0, 1]], dtype=int32)9️⃣ np.empty()
np.empty(shape, dtype=float)
- 초기화되지 않은 배열 생성
- 트레쉬 값으로 이루어져 있으며 빠르게 배열을 생성하고자 할 때 사용한다. 따라서, 해당 배열을 가지고 연산에 활용하는 것은 지양한다.
np.empty((3, 4))- 출력
array([[1.23674245e-311, 3.16202013e-322, 0.00000000e+000,
0.00000000e+000],
[0.00000000e+000, 5.16203768e-066, 1.38054801e-071,
1.05118767e-046],
[8.15594968e-043, 1.90147180e-052, 1.34661310e+165,
2.85222614e-056]])1️⃣0️⃣ np.full()
np.full(shape, fill_value, dtype=None)
- 같은 값의 요소로 채운 배열 생성
np.full((3, 4), 6)- 출력
array([[6, 6, 6, 6],
[6, 6, 6, 6],
[6, 6, 6, 6]])📌 난수 배열 생성
1️⃣ random.rand()
random.rand([d0, d1, ..., dn])
[0, 1)사이의 실수 난수를 갖는 NumPy 배열을 생성rand(d0, d1, ..., dn)을 실행하면(d0, d1, ..., dn)의 형태를 보이는 실수 난수 배열 생성
np.random.rand()- 출력
0.48514155770539125다차원 난수 배열
np.random.rand(3, 4)- 출력
array([[0.44351364, 0.31092424, 0.59754525, 0.73167845],
[0.11204261, 0.49007257, 0.14971646, 0.79217428],
[0.41088396, 0.65839426, 0.34597045, 0.35892379]])2️⃣ random.randint()
random.randint([low,] high [,size])
[low, high)사이의 정수 난수를 갖는 NumPy 배열을 생성size : (d0, d1, ..., dn)형식으로 입력
np.random.randint(10)- 출력
2다차원 난수 배열
np.random.randint(10, size=(3, 4))- 출력
array([[4, 9, 3, 0],
[0, 0, 5, 9],
[3, 4, 1, 5]], dtype=int32)