
📌 DataFrame 인덱스 변경
📌 행 인덱스 변경
- 기본인덱스 : 행인덱스를 명시적으로 지정하지 않는 경우 0부터 1씩 증가하는 정수 인덱스로 설정
set_index(keys, drop=True, append=False, inplace=False, ...,)
- 기존의 행인덱스를 제거하고 지정한 열로 인덱스 변경
reset_index(level=None, drop=False, inplace=False, ...)
- 기존의 행인덱스를 제거하고 기본인덱스로 변경
예시 데이터
# 행인덱스를 명시적으로 지정하지 않은 데이터프레임 생성
df = pd.DataFrame({'a': [1, 3, 2, 4, 5],
'b': [20, 30, 40, 20, 10],
'c': [1, 5, 7, 3, 2]})
df- 출력
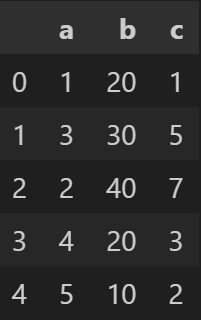
1️⃣ set_index
df.set_index(열이름): 지정한 열을 인덱스로 설정한다.
# 'a' 열을 인덱스로 설정
df2 = df.set_index('a')
df2- 출력

- 이때, 원본은 변경되지 않으며 원본을 변경하려면
inplace=True옵션을 지정하면 된다.
# 'a' 열을 인덱스로 설정하며 원본에 적용
df.set_index('a', inplace=True)
df- 출력
2️⃣ reset_index
df.reset_index(): 기본 인덱스로 초기화한다. (정수 인덱스)- 이때, 원본은 변경되지 않으며 원본을 변경하려면
inplace=True옵션을 지정하면 된다.
df.reset_index()- 출력
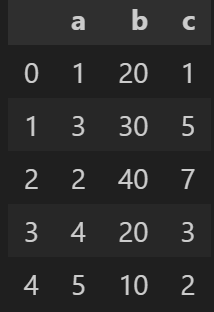
drop=True옵션을 사용하면 기존에 사용하던index열은 삭제된다.
df3 = df.reset_index(drop=True)
df3| df(원본데이터) | df3(drop=True) |
|---|---|
|  |
📌 새 인덱스 지정 (reindex)
- 새로운 색인(index)에 적합하도록 객체를 새로 생성
- 시계열 같은 순차적인 데이터를 재색인할 경우
Series.reindex(index=None, *, axis=None, method=None, copy=None,
level=None, fill_value=None, limit=None, tolerance=None)
DataFrame.reindex(labels=None, *, index=None, columns=None, axis=None,
method=None, copy=None, level=None,
fill_value=nan, limit=None, tolerance=None)
labels: 색인으로 사용할 새로운 순서. Index 인스턴스나 다른 순차적인 파이썬 자료구조 사용 가능하며index는 복사가 이루어지지 않고 그대로 사용index: array-like, 전달된 시퀀스를 새로운 행(index) 레이블로 지정columns: 전달된 시퀀스를 새로운 열 레이블로 지정axis: int or str, 색인으로 사용할 축(행 또는 열)을 지정. 기본값은 행(index).reindex(index=new_labels)또는reindex(columns=new_labels)와 같이 사용method: 채움 메서드.{None, ‘backfill’/’bfill’, ‘pad’/’ffill’, ‘nearest’}fill_value: scalar, default np.nan. 재색인 과정 중에 새롭게 나타나는 비어 있는 데이터를 채우기 위한 값. 빈 곳의 결과에null을 채워 넣으려면fiil_value='missing'을 이용limit: 전/후 보간(backward fill 또는 forward fill)을 위한 최대 갭 크기(채워 넣을 원소의 수)tolerance: 전/후 보간 시에 사용할 최대 갭 크기(값의 차이)level: Multiindex의 단계(level)에 단순 색인을 맞춘다. 그렇지 않으면 Mulitindex의 하위집합에 맞춘다.copy: True 인 경우 새로운 색인이 이전 색인과 동일하더라도 기본 데이터를 복사하고, False 인 경우 새로운 색인이 이전 색인과 동일하면 복사하지 않는다.
1️⃣ Series Reindex
예시 시리즈
s = pd.Series([4.5, 7.2, -5.3, 3.6], index=list('dabc'))
s- 출력
d 4.5
a 7.2
b -5.3
c 3.6
dtype: float64- 새로 지정한 인덱스에 해당하는 데이터가 없는 경우
NaN출력한다.
s.reindex('a b c d e'.split())- 출력
a 7.2
b -5.3
c 3.6
d 4.5
e NaN
dtype: float64순차적인 데이터 재색인할 때 값을 보완하거나 채워야하는 경우
method='ffill' | 'bfill' | 'nearest'
예시 시리즈
s2 = pd.Series(['blue', 'purple', 'yellow'], index=[0, 2, 4])
s2- 출력
0 blue
2 purple
4 yellow
dtype: strs2인덱스 설정
s2.reindex(np.arange(6))- 출력
0 blue
1 NaN
2 purple
3 NaN
4 yellow
5 NaN
dtype: strs2결측치 대체
s2.reindex(np.arange(6), method='ffill')- 출력
0 blue
1 blue
2 purple
3 purple
4 yellow
5 yellow
dtype: str2️⃣ DataFrame Reindex
예시 데이터프레임
df = pd.DataFrame(np.arange(9).reshape(3, 3),
index='a c d'.split(),
columns='A B C'.split())
df- 출력

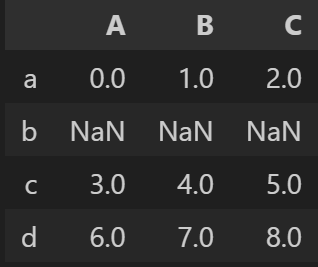
행 인덱스 재색인
- 새로 지정한 인덱스에 해당하는 데이터가 없는 경우
NaN출력한다.
# 1번째 방법
df.reindex(index='a b c d'.split())
# 2번째 방법
df.reindex(['a', 'b', 'c', 'd'], axis='index')- 출력
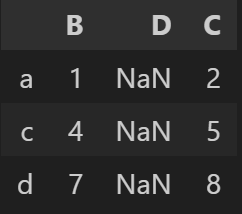
열 인덱스 재색인
- 새로 지정한 인덱스에 해당하는 데이터가 없는 경우
NaN출력하고, 원본 데이터의 인덱스를 새로 지정한 인덱스에 포함시키지 않으면 해당 인덱스는 삭제된다.
# 1번째 방법
df.reindex(columns=['B', 'D', 'C'])
# 2번째 방법
df.reindex(['B', 'D', 'C'], axis='columns')- 출력
날짜 인덱스 재색인
예시 데이터
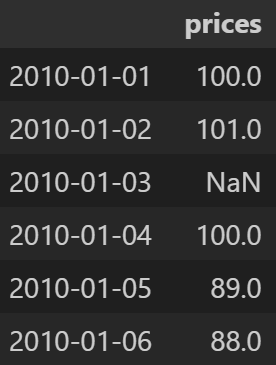
date_index = pd.date_range('1/1/2010', periods=6, freq='D')
df2 = pd.DataFrame({"prices": [100, 101, np.nan, 100, 89, 88]},
index=date_index)
df2- 출력
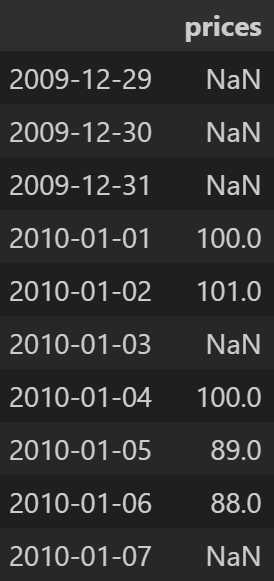
새 날짜 인덱스 지정
date_index2 = pd.date_range('12/29/2009', periods=10, freq='D')
df2.reindex(date_index2)- 출력
📌 인덱스 이름 변경
- 행인덱스(index) 또는 열인덱스(columns)의 값 변경
rename(index= { }, columns={ }, ..., inplace=False,...)함수
- 딕셔너리 형식으로 지정
- 행인덱스(index) 이름 변경 :
rename(index={행이름1:변경값1, 행이름1:변경값1, ...})- 열인덱스(columns) 이름 변경 :
rename(columns={열이름1:변경값1 , 열이름2:변경값2 , ... })
1️⃣ 열 인덱스 이름 변경
예시 데이터
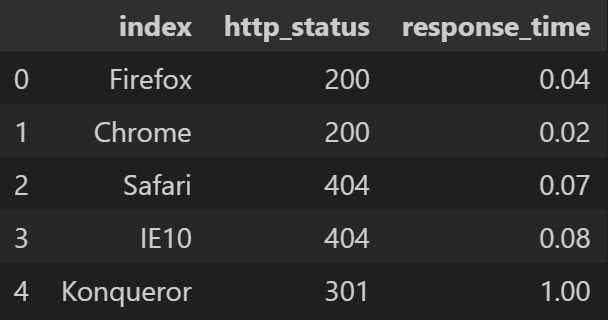
index = ['Firefox', 'Chrome', 'Safari', 'IE10', 'Konqueror']
df = pd.DataFrame({'http_status': [200, 200, 404, 404, 301],
'response_time': [0.04, 0.02, 0.07, 0.08, 1.0]},
index=index)
df.reset_index(inplace=True)
df- 출력
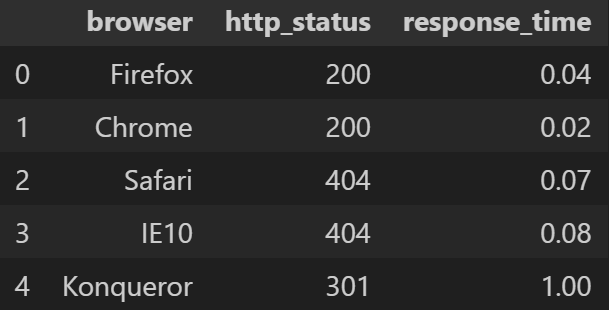
index컬럼에 해당하는 이름을browser로 변경한다.
df.rename(columns={'index': 'browser'}, inplace=True)
df- 출력
2️⃣ 행 인덱스 이름 변경
- 행 인덱스 또한 열 인덱스처럼 딕셔너리 형태로 입력하되 파라미터만
index=을 사용하면 된다.
df.rename(index={0: 'I', 1: 'J', 2: 'K', 3: 'L', 4: 'M'}, inplace=True)
df- 출력
3️⃣ 인덱스 이름 데이터 형태 변경
행 인덱스 이름 변경 전으로 복구
df.index = range(5)
df- 출력
- 다음과 같이 데이터 타입을 주면
index의dtype이 변경된다.
df.rename(index=str).index- 출력
Index(['0', '1', '2', '3', '4'], dtype='str')