📌 Generation Metrics
1️⃣ 평가 지표 (Evaluation Metric)
1) 검색(Retrieval) 평가
-
Non-Rank Based Metrics: Accuracy, Precision, Recall@k 등을 통해 관련성의 이진적 평가를 수행
-
Rank-Based Metrics: MRR(Mean Reciprocal Rank), MAP(Mean Average Precision)를 통해 검색 결과의 순위를 고려한 평가를 수행
-
RAG 특화 지표: 기존 검색 평가 방식의 한계를 보완하는 LLM-as-judge 방식 도입
-
포괄적 평가: 정확도, 관련성, 다양성, 강건성을 통합적으로 측정

2) 생성(Generation) 평가
-
전통적 평가: ROUGE(요약), BLEU(번역), BertScore(의미 유사도) 지표 활용
-
LLM 기반 평가: 응집성, 관련성, 유창성을 종합적으로 판단하는 새로운 접근법 도입 (전통적인 참조 비교가 어려운 상황에서 유용)
-
다차원 평가: 품질, 일관성, 사실성, 가독성, 사용자 만족도를 포괄적 측정
-
상세 프롬프트와 사용자 선호도 기준으로 생성 텍스트 품질 평가
[출처] https://arxiv.org/abs/2405.07437
2️⃣ 검색 도구 정의
1. 벡터스토어 로드
- Chroma DB 설정에서 모델, 컬렉션명, 저장 경로 지정
# 벡터 저장소 로드
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
chroma_db = Chroma(
collection_name="db_korean_cosine_metadata",
embedding_function=embeddings,
persist_directory="./chroma_db",
)검색기 생성
# 벡터저장소 검색기 생성
chroma_k = chroma_db.as_retriever(
search_kwargs={'k': 4},
)
# 벡터저장소 검색기를 사용하여 검색
query = "테슬라의 회장은 누구인가요?"
retrieved_docs = chroma_k.invoke(query)
# 검색 결과 출력
for doc in retrieved_docs:
print(f"- {doc.page_content} [출처: {doc.metadata['source']}]")
print("-"*200)
print()- 출력
- [출처] 이 문서는 테슬라에 대한 문서입니다.
----------------------------------
### Roadster (2005–2009)
Elon Musk는 주류 차량으로 확장하기 전에 프리미엄 스포츠카로 시작하는 전략에 초점을 맞춰 적극적인 역할을 수행했습니다. 후속 자금 조달에는 Valor Equity Partners (2006)와 Sergey Brin, Larry Page, Jeff Skoll과 같은 기업가의 투자가 포함되었습니다.
2007년 8월, Eberhard는 CEO에서 물러나라는 요청을 받았고, Tarpenning은 2008년 1월에 이어졌습니다. Michael Marks는 Ze'ev Drori가 인수하기 전에 임시 CEO를 역임했으며, Musk는 2008년 10월에 인수했습니다. Eberhard는 2009년 6월 Musk를 상대로 소송을 제기했지만 나중에 기각되었습니다. [출처: data\테슬라_KR.md]
...2. BM25 검색기 준비
-
BM25 검색기 구현으로 문서 유사도 기반 검색 가능
-
한국어 텍스트 처리를 위한 Kiwi 토크나이저 설정
저장소 데이터 있는 jsonl 파일 사용
# korean_docs 파일을 로드 (jsonlines 파일)
def load_jsonlines(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
docs = [json.loads(line) for line in f]
return docs
korean_docs = load_jsonlines('data/korean_docs_final.jsonl')
print(f"로드된 문서: {len(korean_docs)}개")
pprint(korean_docs[0])- 출력
로드된 문서: 39개
('{"id":null,"metadata":{"source":"data/테슬라_KR.md","company":"테슬라","language":"ko"},"page_content":"[출처] '
'이 문서는 테슬라에 대한 문서입니다.\\n----------------------------------\\nTesla, Inc.는 미국의 '
'다국적 자동차 및 청정 에너지 회사입니다. 이 회사는 전기 자동차(BEV), 고정형 배터리 에너지 저장 장치, 태양 전지판, 태양광 '
'지붕널 및 관련 제품/서비스를 설계, 제조 및 판매합니다. 2003년 7월 Martin Eberhard와 Marc Tarpenning이 '
'Tesla Motors로 설립했으며, Nikola Tesla를 기리기 위해 명명되었습니다. Elon Musk는 2004년 Tesla의 '
'초기 자금 조달을 주도하여 2008년에 회장 겸 CEO가 되었습니다.","type":"Document"}')jsonl 의 문자열 데이터를 Document 객체로 변환
from langchain_core.documents import Document # Document 클래스 임포트
# 문자열 리스트를 Document 객체로 변환
if isinstance(korean_docs[0], str): # 첫 번째 항목이 문자열인지 확인
documents = [
Document(
page_content=json.loads(data)['page_content'], # 문자열을 파이썬 객체로 변환
metadata=json.loads(data)['metadata']
)
for i, data in enumerate(korean_docs)
]
else:
documents = korean_docs
print(f"변환된 문서: {len(documents)}개")
pprint(documents[0])- 출력
변환된 문서: 39개
Document(metadata={'source': 'data/테슬라_KR.md', 'company': '테슬라', 'language': 'ko'}, page_content='[출처] 이 문서는 테슬라에 대한 문서입니다.\n----------------------------------\nTesla, Inc.는 미국의 다국적 자동차 및 청정 에너지 회사입니다. 이 회사는 전기 자동차(BEV), 고정형 배터리 에너지 저장 장치, 태양 전지판, 태양광 지붕널 및 관련 제품/서비스를 설계, 제조 및 판매합니다. 2003년 7월 Martin Eberhard와 Marc Tarpenning이 Tesla Motors로 설립했으며, Nikola Tesla를 기리기 위해 명명되었습니다. Elon Musk는 2004년 Tesla의 초기 자금 조달을 주도하여 2008년에 회장 겸 CEO가 되었습니다.')BM25 검색기 생성
# BM25 검색기를 사용하기 위한 준비
from krag.tokenizers import KiwiTokenizer
from krag.retrievers import KiWiBM25RetrieverWithScore
kiwi_tokenizer = KiwiTokenizer(
model_type='knlm', # Kiwi 언어 모델 타입
typos='basic' # 기본 오타교정
)
bm25_db = KiWiBM25RetrieverWithScore(
documents=documents,
kiwi_tokenizer=kiwi_tokenizer,
k=4,
)Document 객체 pickle 파일로 저장
# pickle로 저장
import pickle
with open('data/korean_docs.pkl', 'wb') as f:
pickle.dump(korean_docs, f)
# BM25 검색기 로드
with open('data/korean_docs.pkl', 'rb') as f:
korean_docs_test = pickle.load(f)문서 검색
# BM25 검색기를 사용하여 문서 검색
query = "테슬라의 회장은 누구인가요?"
retrieved_docs = bm25_db.invoke(query)
# 검색 결과 출력
for doc in retrieved_docs:
print(f"BM25 점수: {doc.metadata["bm25_score"]:.2f}")
print(f"\n{doc.page_content}\n[출처: {doc.metadata['source']}]")
print("-"*200)- 출력
BM25 점수: 6.04
[출처] 이 문서는 리비안에 대한 문서입니다.
----------------------------------
**개요**
Rivian은 "스케이트보드" 플랫폼(R1T 및 R1S 모델)을 기반으로 한 전기 스포츠 유틸리티 차량(SUV), 픽업 트럭 및 전기 배달 밴(Rivian EDV)을 생산합니다. R1T 배송은 2021년 말에 시작되었습니다. 회사는 2022년에 미국에서 충전 네트워크를 시작하여 2024년에 다른 차량에도 개방했습니다. 생산 공장은 일리노이 주 노멀에 있으며, 다른 시설은 미국, 캐나다, 영국 및 세르비아의 여러 주에 있습니다.
**역사**
**초창기 (2009–15):**
[출처: data/리비안_KR.md]
...3. Ensemble Hybrid Search 준비
-
BM25, 벡터 검색 결과를 rank-fusion 알고리즘으로 통합 (EnsembleRetriever)
-
각 검색기의 순위 점수를 고려한 최종 순위 결정
-
두 검색 방식의 장점을 결합해 검색 품질 향상
Ensemble 검색기 생성
from langchain.retrievers import EnsembleRetriever
# 검색기 초기화
hybrid_retriever = EnsembleRetriever(
retrievers=[bm25_db, chroma_k],
weights=[0.5, 0.5],
)문서 검색
query = "테슬라의 회장은 누구인가요?"
retrieved_docs = hybrid_retriever.invoke(query)
# 검색 결과 출력
for doc in retrieved_docs:
print(f"\n{doc.page_content}\n[출처: {doc.metadata['source']}]")
print("-"*200)- 출력
[출처] 이 문서는 테슬라에 대한 문서입니다.
----------------------------------
Tesla, Inc.는 미국의 다국적 자동차 및 청정 에너지 회사입니다. 이 회사는 전기 자동차(BEV), 고정형 배터리 에너지 저장 장치, 태양 전지판, 태양광 지붕널 및 관련 제품/서비스를 설계, 제조 및 판매합니다. 2003년 7월 Martin Eberhard와 Marc Tarpenning이 Tesla Motors로 설립했으며, Nikola Tesla를 기리기 위해 명명되었습니다. Elon Musk는 2004년 Tesla의 초기 자금 조달을 주도하여 2008년에 회장 겸 CEO가 되었습니다.
[출처: data/테슬라_KR.md]
...3️⃣ RAG Chain 정의
Chain 정의
# 각 쿼리에 대한 검색 결과를 한꺼번에 Context로 전달해서 답변을 생성
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
def create_rag_chain(retriever, llm):
template = """Answer the following question based on this context. If the context is not relevant to the question, just answer with '답변에 필요한 근거를 찾지 못했습니다.'
<Context>
{context}
</Context>
<Question>
{question}
</Question>
"""
prompt = ChatPromptTemplate.from_template(template)
def format_docs(docs):
return "\n\n".join([f"{doc.page_content}" for doc in docs])
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
return rag_chainChain 생성 및 테스트
# RAG 체인 생성 및 테스트
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.5)
openai_rag_chain = create_rag_chain(hybrid_retriever, llm)
question = "Tesla 회장은 누구인가요?"
answer = openai_rag_chain.invoke(question)
print(f"쿼리: {question}")
print(f"답변: {answer}") - 출력
쿼리: Tesla 회장은 누구인가요?
답변: Elon Musk입니다.4️⃣ RAG 답변 평가
-
정확성과 관련성이 RAG 시스템의 핵심 평가 지표
-
자동 평가(ROUGE, BLEU)와 인간 평가 병행 필요
-
일관성 측정을 통한 답변의 논리적 모순 확인
-
정량적, 정성적 평가를 종합해 RAG 시스템의 실질적 성능 측정
-
평가 시스템의 구조:
- 입력: 데이터셋 예시와 실행 결과를 포함
- 출력: key(메트릭명), score/value(점수), comment(설명)를 포함하는 표준화된 형태
- 구현: Python/TypeScript 기반의 커스텀 코드 또는 LangSmith 내장 평가기 활용
-
평가 방법의 유형:
- 휴리스틱 평가: 답변 길이, JSON 유효성, 코드 문법 등 기본적 규칙 검증
- 자동화 메트릭: ROUGE, BLEU 등을 통한 정량적 평가
- LLM-as-judge: LLM을 활용한 출력 품질 평가
- Pairwise 비교: 두 시스템 출력의 직접적인 비교 평가
-
- LangChain 평가도구 활용
- 다양한 평가 방식 지원: Q&A 정확도, 맥락 이해도, 사고 과정 검증
- 문자열/임베딩 거리 및 JSON 평가 기능 포함
LangChainStringEvaluator로 평가도구 설정 및 매개변수 조정 가능- 참고: https://docs.smith.langchain.com/reference/sdk_reference/langchain_evaluators
1. 휴리스틱 평가
-
휴리스틱 평가자는 특정 규칙에 기반한 결정론적 함수로 작동하며, 명확한 기준에 따라 판단을 수행
-
주로 단순 검증에 활용되며, 챗봇 응답의 공백 여부, 생성된 코드의 컴파일 가능성 등을 확인
-
평가 기준이 명확하고 객관적이어서 정확한 분류나 검증이 필요한 경우에 효과적
-
복잡한 상황보다는 명확한 규칙이 존재하는 간단한 검증 작업에 적합
(1) 답변 길이 평가
길이 평가도구 정의
# 길이 평가도구 정의
def evaluate_string_length(text, min_length=50, max_length=200):
length = len(text)
return {
"score": min_length <= length <= max_length,
"length": length
}
# 길이 평가 수행
print(f"답변: {answer}")
# 길이 평가
result = evaluate_string_length(answer)
print(f"길이 평가 결과: {result}")- 출력
답변: Elon Musk입니다.
길이 평가 결과: {'score': False, 'length': 13}토큰 길이 평가도구 정의
# 토큰 길이 평가도구 정의
def evaluate_token_length(text, tokenizer, min_tokens=10, max_tokens=100):
tokens = tokenizer.tokenize(text)
num_tokens = len(tokens)
return {
"score": min_tokens <= num_tokens <= max_tokens,
"num_tokens": num_tokens
}
# 토큰 길이 평가 수행
from krag.tokenizers import KiwiTokenizer
kiwi_tokenizer = KiwiTokenizer()
result = evaluate_token_length(answer, kiwi_tokenizer)
print(f"토큰 길이 평가 결과: {result}")- 출력
토큰 길이 평가 결과: {'score': False, 'num_tokens': 5}요약 및 평가 체인 생성
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
# 여러 평가 도구를 병렬로 실행하는 함수
def create_evaluator_chain(*evaluator_funcs):
evaluator_dict = {
getattr(func, '__name__', f'eval_{i}'): lambda x, func=func: func(x)
for i, func in enumerate(evaluator_funcs)
}
return RunnableParallel(evaluator_dict)
# 길이 평가 도구 생성 함수
def create_length_evaluator(min_length=50, max_length=200):
def evaluate_string_length(text: str):
length = len(text)
return {
"score": min_length <= length <= max_length,
"length": length
}
return evaluate_string_length
# 토큰 길이 평가 도구 생성 함수
def create_token_length_evaluator(tokenizer, min_tokens=10, max_tokens=100):
def evaluate_token_length(text: str):
tokens = tokenizer.tokenize(text)
num_tokens = len(tokens)
return {
"score": min_tokens <= num_tokens <= max_tokens,
"num_tokens": num_tokens
}
return evaluate_token_length
# 요약 체인 생성 함수
def create_summary_chain(llm, evaluators=None):
prompt = ChatPromptTemplate.from_template(
"""제시된 텍스트를 50자 이내로 요약하세요. (공백 포함)
[텍스트]
{text}
"""
)
base_chain = prompt | llm | StrOutputParser()
if evaluators:
eval_chain = create_evaluator_chain(*evaluators)
chain = base_chain | RunnableParallel({
"answer": RunnablePassthrough(),
"evaluation": eval_chain
})
return chain
return base_chain
# 요약 체인 생성
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.3, max_tokens=100)
evaluators = [
create_length_evaluator(min_length=30, max_length=50),
create_token_length_evaluator(kiwi_tokenizer, min_tokens=10, max_tokens=20),
]
summary_chain = create_summary_chain(llm, evaluators)
# 요약 체인 테스트
text = """
테슬라는 미국의 전기 자동차 제조업체이자, 태양광 발전 및 에너지 저장장치 제조업체이다.
테슬라의 창업자이자 CEO인 일론 머스크는 2003년 테슬라를 설립하였다.
테슬라는 2008년 테슬라 로드스터를 출시하며 전기 자동차 시장에 진출하였다.
"""
summary = summary_chain.invoke(text)
print(f"요약: {summary['answer']}")
print(f"평가: {summary['evaluation']}")- 출력
요약: 테슬라는 일론 머스크가 2003년에 설립한 전기차 및 에너지 회사이다.
평가: {'evaluate_string_length': {'score': True, 'length': 39}, 'evaluate_token_length': {'score': True, 'num_tokens': 19}}(2) JSON 유효성 평가
from langchain.evaluation import load_evaluator
# Evaluator 초기화
json_validity_evaluator = load_evaluator(
evaluator="json_validity", # JSON 유효성 검사
)
# JSON 평가
json_result = json_validity_evaluator.evaluate_strings(
prediction='{"name": "test", "value": 123}',
reference=None
)
print(f"JSON 유효성 평가 결과: {json_result}")- 출력
JSON 유효성 평가 결과: {'score': 1}2. 정량 평가지표 사용
-
ROUGE와 BLEU는 텍스트 생성 품질을 평가하는 대표적인 정량 평가지표
-
이러한 메트릭들은 생성된 텍스트와 참조 텍스트 간의 단어 중첩도를 계산하여 품질을 수치화
-
대규모 자동화 평가가 필요한 경우 효율적이며, 객관적인 비교가 가능한 장점
-
하지만, 문맥이나 의미의 유사성은 완벽하게 포착하지 못하는 한계점이 존재
-
단순 단어 비교만 가능
- "날씨가 좋다"와 "날씨가 훌륭하다"는 의미는 비슷하지만 다른 점수를 받을 수 있음
-
문맥 이해 불가
- "강아지가 공을 물었다"와 "공을 강아지가 물었다"는 의미가 같아도 다른 점수를 받을 수 있음
-
-
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
- 생성된 요약문의 품질을 평가
-
ROUGE-1:
- 참조 문서와 생성된 요약문 사이의 단일 단어(unigram) 중복을 측정
- 예시: "고양이가 잠을 잡니다"와 "고양이는 낮잠을 잡니다" 비교
- 참조: ["고양이", "가", "잠", "을", "잡니다"]
- 생성: ["고양이", "는", "낮잠", "을", "잡니다"]
- 일치: ["고양이", "을", "잡니다"]
- Precision = 3/5 = 0.6
- Recall = 3/5 = 0.6
- F1 = 0.6
-
ROUGE-2:
- 연속된 두 단어(bigram) 시퀀스의 중복을 평가
- 예시: "고양이가 잠을 잡니다"와 "고양이는 낮잠을 잡니다" 비교
- 참조: ["고양이 가", "가 잠", "잠 을", "을 잡니다"]
- 생성: ["고양이 는", "는 낮잠", "낮잠 을", "을 잡니다"]
- 일치: ["을 잡니다"]
- Precision = 1/4 = 0.25
- Recall = 1/4 = 0.25
- F1 = 0.25
-
ROUGE-L:
- 최장 공통 부분수열(LCS)을 기반으로 텍스트의 유사도를 측정
- 예시: "고양이가 잠을 잡니다"와 "고양이는 낮잠을 잡니다" 비교
- 참조: "고양이 가 잠 을 잡니다"
- 생성: "고양이 는 낮잠 을 잡니다"
- LCS: "고양이 을 잡니다"
- Precision = 3/5 = 0.6
- Recall = 3/5 = 0.6
- F1 = 0.6
-
각 메트릭은 정밀도(Precision), 재현율(Recall), F1-score로 표현
-
ROUGE-1은 개별 단어 일치를, ROUGE-2는 문장 구조를, ROUGE-L은 전체적인 의미 유사성을 중점적으로 평가
-
BLEU (Bilingual Evaluation Understudy)
- BLEU는 기계 번역의 품질을 평가하는 대표적인 메트릭으로, 생성된 번역문과 참조 번역문 간의 n-gram 정확도를 계산
- 0에서 1 사이의 값을 가지며, 1에 가까울수록 번역 품질이 좋음을 의미
-
BLEU-1 (단일 단어):
- 예시: "나는 학교에 간다" vs "나는 학원에 간다"
- 참조: ["나는", "학교에", "간다"]
- 생성: ["나는", "학원에", "간다"]
- 일치: ["나는", "간다"]
- Precision = 2/3 = 0.67
- BP(Brevity Penalty) = 1 (같은 길이)
- BLEU-1 = 0.67
- 예시: "나는 학교에 간다" vs "나는 학원에 간다"
-
BLEU-2 (두 단어 시퀀스):
- 예시: "나는 학교에 간다" vs "나는 학원에 간다"
- 참조의 bigram: ["나는 학교에", "학교에 간다"]
- 생성의 bigram: ["나는 학원에", "학원에 간다"]
- 일치하는 bigram: 없음
- Precision = 0/2 = 0
- BP = 1
- BLEU-2 = 0
- 예시: "나는 학교에 간다" vs "나는 학원에 간다"
-
BLEU-3 (세 단어 시퀀스):
- 예시: "나는 학교에 간다" vs "나는 학원에 간다"
- 참조의 trigram: ["나는 학교에 간다"]
- 생성의 trigram: ["나는 학원에 간다"]
- 일치하는 trigram: 없음
- Precision = 0/1 = 0
- BP = 1
- BLEU-3 = 0
- 예시: "나는 학교에 간다" vs "나는 학원에 간다"
-
주요 특징:
-
Brevity Penalty(BP):
- 생성문이 참조문보다 짧을 경우 페널티 부여
- BP = min(1, exp(1 - 참조문길이/생성문길이))
-
최종 BLEU 점수:
- 일반적으로 BLEU-1부터 BLEU-4까지의 기하평균 사용
- BLEU = BP × exp(∑(wn × log(pn)))
- wn은 각 n-gram의 가중치 (보통 균등 가중치 0.25 사용)
-
ROUGE와의 차이점:
- BLEU는 Precision 중심, ROUGE는 Recall 중심
- BLEU는 기계 번역 평가에 주로 사용
- BLEU는 항상 BP(Brevity Penalty)를 고려함
- BLEU는 여러 n-gram의 기하평균을 사용
-
(1) ROUGE 스코어
-
ROUGE-1: 한 단어씩 비교 (예: "날씨가", "좋습니다" 등)
-
ROUGE-2: 두 단어(bigram)씩 연속으로 비교 (예: "날씨가 좋습니다")
-
ROUGE-L: 가장 긴 공통 단어열(LCS)을 찾아 비교
-
자동 요약과 기계 번역 평가에 사용
[korouge_score] https://github.com/HeegyuKim/korouge
-
기존 rouge_score 에서 한국어 처리 가능하게 만든 라이브러리
krouge_score 활용 ROUGE 스코어 계산
from korouge_score import rouge_scorer
from krag.tokenizers import KiwiTokenizer
# Kiwi 토크나이저 사용하여 토큰화하는 클래스 정의
class CustomKiwiTokenizer(KiwiTokenizer):
def tokenize(self, text):
return [t.form for t in super().tokenize(text)]
# 토크나이저 생성
kiwi_tokenizer = CustomKiwiTokenizer(model_type='knlm', typos='basic')
# ROUGE 스코어 계산
scorer = rouge_scorer.RougeScorer(
["rouge1", "rouge2", "rougeL"],
tokenizer=kiwi_tokenizer # tokenize 메소드를 갖는 토크나이저 사용
)
# 예시 데이터
reference = "오늘 날씨가 매우 좋습니다. 공원에서 산책하기 좋은 날이에요." # 정답 텍스트
generated1 = "오늘은 날씨가 정말 좋네요. 공원에서 산책하면 좋을 것 같아요." # 생성된 텍스트
generated2 = "비가 많이 오고 있어요. 실내에서 쉬는 게 좋을 것 같습니다." # 생성된 텍스트
print("=== 유사한 텍스트 비교 ===")
rouge_scores = scorer.score(reference, generated1)
print(f"ROUGE-1: {rouge_scores['rouge1'].fmeasure:.3f}")
print(f"ROUGE-2: {rouge_scores['rouge2'].fmeasure:.3f}")
print(f"ROUGE-L: {rouge_scores['rougeL'].fmeasure:.3f}")
print("\n=== 다른 텍스트 비교 ===")
rouge_scores = scorer.score(reference, generated2)
print(f"ROUGE-1: {rouge_scores['rouge1'].fmeasure:.3f}")
print(f"ROUGE-2: {rouge_scores['rouge2'].fmeasure:.3f}")
print(f"ROUGE-L: {rouge_scores['rougeL'].fmeasure:.3f}")- 출력
=== 유사한 텍스트 비교 ===
ROUGE-1: 0.649
ROUGE-2: 0.286
ROUGE-L: 0.595
=== 다른 텍스트 비교 ===
ROUGE-1: 0.368
ROUGE-2: 0.056
ROUGE-L: 0.263점수 출력
rouge_scores- 출력
{'rouge1': Score(precision=0.35, recall=0.3888888888888889, fmeasure=0.36842105263157887),
'rouge2': Score(precision=0.05263157894736842, recall=0.058823529411764705, fmeasure=0.05555555555555555),
'rougeL': Score(precision=0.25, recall=0.2777777777777778, fmeasure=0.2631578947368421)}(2) BLEU (Bilingual Evaluation Understudy)
-
생성된 텍스트가 얼마나 자연스러운지를 평가
-
0부터 1 사이의 값으로 표시 (1에 가까울수록 좋음)
-
기계 번역 평가의 대표적 지표
-
n-gram 정밀도 기반
-
간결성 페널티 적용
-
1-4gram까지의 기하평균 사용
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction
from typing import List, Union
# BLEU 스코어 계산
def calculate_bleu_score(
reference: Union[str, List[str]],
hypothesis: str,
weights: tuple = (0.25, 0.25, 0.25, 0.25), # n-gram 가중치 설정 (기본값: 균등 가중치)
smoother=SmoothingFunction().method1, # Smoothing 메소드 설정 -> method1 사용 (0으로 나누는 것 방지)
tokenizer=CustomKiwiTokenizer(model_type='knlm', typos='basic') # Kiwi 토크나이저 사용 (기본값)
) -> float:
"""
BLEU 스코어 계산
Args:
reference (Union[str, List[str]]): 참조 텍스트 또는 텍스트 리스트
hypothesis (str): 비교할 생성 텍스트
weights (tuple): n-gram 가중치 (기본값: 균등 가중치)
tokenizer: 토크나이저 객체 (기본값: Kiwi 토크나이저)
Returns:
float: BLEU 스코어 (0~1)
"""
try:
# 참조 텍스트 처리 (문자열이면 바로 토크나이징, 리스트면 각 항목을 토크나이징)
if isinstance(reference, str):
references = [tokenizer.tokenize(reference)]
else:
references = [tokenizer.tokenize(ref) for ref in reference]
# 생성 텍스트 토크나이징
hypothesis_tokens = tokenizer.tokenize(hypothesis)
# BLEU 스코어 계산
score = sentence_bleu(
references,
hypothesis_tokens,
weights=weights,
smoothing_function=smoother
)
return score
except Exception as e:
print(f"BLEU 스코어 계산 중 오류 발생: {str(e)}")
return 0.0
# 예시 데이터
reference = "오늘 날씨가 매우 좋습니다. 공원에서 산책하기 좋은 날이에요." # 정답 텍스트
generated1 = "오늘은 날씨가 정말 좋네요. 공원에서 산책하면 좋을 것 같아요." # 생성된 텍스트
generated2 = "비가 많이 오고 있어요. 실내에서 쉬는 게 좋을 것 같습니다." # 생성된 텍스트
print("=== 유사한 텍스트 비교 ===")
bleu_score = calculate_bleu_score(reference, generated1, tokenizer=kiwi_tokenizer)
print(f"BLEU: {bleu_score:.3f}")
print("\n=== 다른 텍스트 비교 ===")
bleu_score = calculate_bleu_score(reference, generated2, tokenizer=kiwi_tokenizer)
print(f"BLEU: {bleu_score:.3f}")- 출력
=== 유사한 텍스트 비교 ===
BLEU: 0.249
=== 다른 텍스트 비교 ===
BLEU: 0.0283. 문자열 및 임베딩 거리 평가
-
문자열 및 임베딩 거리는 예측값과 참조값 간의 유사도를 정량적으로 측정하는 평가 방식
-
String Distance Evaluator는 레벤슈타인 거리 등을 활용해 문자열 간의 편집 거리를 계산하며, 정규화된 점수를 제공
-
Embedding Distance Evaluator는 텍스트의 의미적 유사도를 코사인 거리 등 다양한 메트릭으로 측정
-
문자열과 임베딩 기반 평가 방식은 예측값의 정확도를 객관적으로 측정할 수 있으며, 유연한 커스터마이징이 가능함
(1) String Distance
-
String Distance Evaluator는 레벤슈타인 거리를 사용해 두 문자열이 얼마나 다른지 측정
-
한 문자열을 다른 문자열로 변환하는데 필요한 최소 편집 횟수를 계산
-
점수는 0에서 1 사이로 정규화되어 제공되며, 0에 가까울수록 문자열이 유사함을 의미
-
rapidfuzz라이브러리를 통해 효율적인 계산이 가능하며, 대규모 평가에 적합 (설치 필요)- pip install --upgrade --quiet rapidfuzz (또는 poetry add rapidfuzz)
평가 진행 (일치하는 경우)
from langchain.evaluation import load_evaluator
# 문자열 거리 기반 평가기 생성
string_distance_evaluator = load_evaluator(
evaluator="string_distance",
distance="levenshtein" # damerau_levenshtein, levenshtein, jaro, jaro_winkler
)
# 문자열 거리 기반 평가기를 사용하여 평가 (일치하는 사례)
result = string_distance_evaluator.evaluate_strings(
prediction= "네, 오늘은 날씨가 맑고 좋네요",
reference="네, 오늘은 날씨가 맑고 좋네요"
)
# 평가 결과 출력
print(result)- 출력
{'score': 0.0}평가 진행 (다른 경우)
# 문자열 거리 기반 평가자를 사용하여 평가 (불일치하는 사례)
result = string_distance_evaluator.evaluate_strings(
prediction= "해당 제품의 가격은 50,000원입니다",
reference="이 제품의 가격이 얼마인가요?"
)
# 평가 결과 출력
print(result)- 출력
{'score': 0.6190476190476191}(2) Embedding Distance
-
임베딩 거리 평가도구는 텍스트를 고차원 벡터로 변환하여 의미적 유사도를 계산
-
코사인 거리, 유클리디안 거리, 맨해튼 거리 등 다양한 거리 메트릭을 선택적으로 활용할 수 있음
-
OpenAI나 HuggingFace 등 다양한 임베딩 제공자를 설정할 수 있음
-
단순 문자열 비교와 달리 문맥적 의미를 고려한 평가가 가능
평가 진행 (의미가 다른 경우)
from langchain.evaluation import load_evaluator
from langchain_openai import OpenAIEmbeddings
# Evaluator 초기화
embedding_evaluator = load_evaluator(
evaluator='embedding_distance', # 임베딩 거리를 기반으로 평가
distance_metric='cosine', # 거리 측정 방법: cosine, euclidean, manhattan, chebyshev, hamming
embeddings=OpenAIEmbeddings(model="text-embedding-3-small") # 기본값: OpenAI 임베딩 모델 사용
)
# 의미가 다른 문장 비교
result1 = embedding_evaluator.evaluate_strings(
prediction="나는 학교에 갈 것이다",
reference="나는 집에 있을 것이다"
)
print("의미가 다른 문장 비교 결과:", result1)- 출력
의미가 다른 문장 비교 결과: {'score': 0.5513701796917367}평가 진행 (의미가 비슷한 경우)
# 의미가 비슷한 문장 비교
result2 = embedding_evaluator.evaluate_strings(
prediction="나는 학교에 갈 것이다",
reference="나는 학교로 이동할 것이다",
)
print("의미가 비슷한 문장 비교 결과:", result2)- 출력
의미가 비슷한 문장 비교 결과: {'score': 0.224241353553167}테스트셋 평가
OpenAI 사용 예측 생성 및 평가
# 첫번째 샘플에 대해 평가 - ground truth와 비교
question = df_qa_test.iloc[0]['user_input']
ground_truth = df_qa_test.iloc[0]['reference']
print("Question:", question)
print("Ground Truth:", ground_truth)
# OpenAI LLM을 사용하여 예측 생성
openai_rag_chain = create_rag_chain(hybrid_retriever, llm=ChatOpenAI(model="gpt-4o-mini", temperature=0))
openai_prediction = openai_rag_chain.invoke(question)
print("Prediction:", openai_prediction)
distance_score = embedding_evaluator.evaluate_strings(prediction=openai_prediction, reference=ground_truth)
print("Distance Score:", distance_score)- 출력
Question: Tesla, Inc.는 미국에서 어떤 역할을 하고 있으며, 이 회사의 주요 제품과 서비스는 무엇인가요?
Ground Truth: Tesla, Inc.는 미국의 다국적 자동차 및 청정 에너지 회사로, 전기 자동차(BEV), 고정형 배터리 에너지 저장 장치, 태양 전지판, 태양광 지붕널 및 관련 제품/서비스를 설계, 제조 및 판매합니다.
Prediction: Tesla, Inc.는 미국의 다국적 자동차 및 청정 에너지 회사로, 전기 자동차(BEV), 고정형 배터리 에너지 저장 장치, 태양 전지판, 태양광 지붕널 및 관련 제품/서비스를 설계, 제조 및 판매합니다. 주요 제품과 서비스에는 전기 자동차, Supercharger 네트워크, Destination 충전 위치 네트워크, 차량 보험 서비스, 원격 진단 및 수리 서비스, 태양 에너지 생성 시스템 및 배터리 에너지 저장 제품이 포함됩니다.
Distance Score: {'score': 0.07595994297470321}Google Generative AI 사용 예측 생성 및 평가
# Google Generative AI LLM을 사용하여 예측 생성
from langchain_google_genai import ChatGoogleGenerativeAI
google_genai_rag_chain = create_rag_chain(
retriever=hybrid_retriever,
llm=ChatGoogleGenerativeAI(model="gemini-1.5-flash", temperature=0)
)
google_genai_prediction = google_genai_rag_chain.invoke(question)
print("Prediction:", google_genai_prediction)
distance_score = embedding_evaluator.evaluate_strings(prediction=google_genai_prediction, reference=ground_truth)
print("Distance Score:", distance_score)- 출력
Prediction: Tesla, Inc.는 미국의 다국적 자동차 및 청정 에너지 회사로, 전기 자동차(BEV), 고정형 배터리 에너지 저장 장치, 태양 전지판, 태양광 지붕널 및 관련 제품/서비스를 설계, 제조 및 판매합니다. 주요 제품 및 서비스는 전기 자동차, Supercharger 네트워크 및 Destination 충전 위치 네트워크를 포함한 충전 서비스, Tesla Insurance Services를 통한 차량 보험, 그리고 태양 전지판, Solar Roof, Powerwall, Megapack 등의 에너지 제품입니다. 또한 차량 서비스(원격 진단 및 수리, 모바일 기술자 파견 등)도 제공합니다.
Distance Score: {'score': 0.11660984698692545}Ollama 사용 예측 생성 및 평가 (qwen2.5)
# Ollama LLM을 사용하여 예측 생성
from langchain_ollama import ChatOllama
ollama_rag_chain = create_rag_chain(
retriever=hybrid_retriever,
llm=ChatOllama(model="qwen2.5", temperature=0)
)
ollama_prediction = ollama_rag_chain.invoke(question)
print("Prediction:", ollama_prediction)
distance_score = embedding_evaluator.evaluate_strings(prediction=ollama_prediction, reference=ground_truth)
print("Distance Score:", distance_score)- 출력
Prediction: Tesla, Inc.는 미국에서 다국적 자동차 및 청정 에너지 회사이자 전기 자동차(BEV), 고정형 배터리 에너지 저장 장치, 태양 전지판, 태양광 지붕 및 관련 제품/서비스를 설계, 제조 및 판매하는 역할을 수행합니다. 주요 제품과 서비스는 다음과 같습니다:
1. **전기 자동차 (BEV)**: Tesla의 주력 제품 중 하나로, 다양한 모델이 있습니다.
2. **고정형 배터리 에너지 저장 장치**: Powerwall 및 Megapack 등으로, 가정이나 대규모 고객을 위한 에너지 저장 솔루션입니다.
3. **태양 전지판 및 태양광 지붕**: Solar Roof와 같은 제품으로, 태양 에너지를 활용한 에너지 생성 시스템을 제공합니다.
4. **충전 네트워크**: Supercharger 네트워크와 Destination 충전 위치 네트워크를 통해 전기차 사용자에게 편리한 충전 경험을 제공합니다.
5. **차량 서비스**: 원격 진단 및 수리를 포함하여 차량 유지 보수 서비스를 제공하며, 브레이크액, 에어컨, 타이어 및 에어 필터 등의 주기적인 서비스 권장사항도 있습니다.
6. **보험 서비스**: Tesla Insurance Services, Inc.를 통해 차량 보험을 제공합니다.
또한, 회사는 로봇 공학 분야에서도 연구 개발 중이며, 전 세계에 소매점, 갤러리, 서비스 센터 등을 운영하고 있습니다.
Distance Score: {'score': 0.11659734296627644}전체 모델에 대한 평가 진행
- rag_chain 의 llm 모델을 변경하면 됩니다.
# 모든 모델에 대해 평가 결과를 비교
def embedding_evaluate_all_models(question, ground_truth):
results = {}
for model_name, rag_chain in {
"OpenAI": openai_rag_chain,
"Google": google_genai_rag_chain,
"Ollama": ollama_rag_chain,
}.items():
prediction = rag_chain.invoke(question)
distance_score = embedding_evaluator.evaluate_strings(prediction=prediction, reference=ground_truth)
results[model_name] = f"{distance_score['score']:.3f}"
return results
question = df_qa_test.iloc[0]['user_input']
ground_truth = df_qa_test.iloc[0]['reference']
results = embedding_evaluate_all_models(question, ground_truth)
pprint(results)- 출력
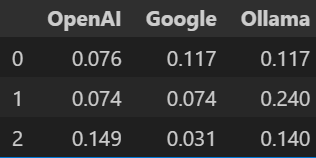
{'Google': '0.117', 'Ollama': '0.117', 'OpenAI': '0.076'}전체 데이터셋에 대한 평가 진행
- 여기서는 3개 평가하였으며, 반복문 값을 조절하면 됩니다.
# 전체 데이터셋에 대해 A/B 테스트 - 여기서는 3개만 평가 (데이터프레임으로 정리)
def embedding_evaluate_qa_dataset(df_qa_test):
results = []
for i in range(3):
question = df_qa_test.iloc[i]['user_input']
ground_truth = df_qa_test.iloc[i]['reference']
result = embedding_evaluate_all_models(question, ground_truth)
results.append(result)
return pd.DataFrame(results)
df_result_embedding = embedding_evaluate_qa_dataset(df_qa_test.iloc[:3])
df_result_embedding - 출력
5️⃣ LangChainStringEvaluator
-
LangSmith와 연동되어 다양한 평가 도구를 제공하는 클래스
-
문자열 거리, 임베딩 거리, LLM 기반 평가 등 다양한 내장 평가자를 쉽게 이용 가능
-
평가 결과는 LangSmith 플랫폼에서 체계적으로 관리되고 시각화될 수 있음
-
사용자 정의 평가자를 만들거나 기존 평가자를 커스터마이즈하는 것도 가능
사전 준비
-
데이터셋 생성이 평가 과정의 첫 단계로 요구됨
-
LangSmith 클라이언트 설정이 평가 시작 전 필수적으로 이루어져야 함
from langsmith import Client
# Langsmith 클라이언트 초기화
client = Client()
# 유사 문장 데이터셋 정의
similar_sentences = [
("오늘 날씨가 좋네요.", "날씨가 정말 좋은 하루네요."),
("이 책은 재미있어요.", "이 책이 너무 재미있네요."),
("저는 커피를 좋아해요.", "커피를 정말 사랑합니다."),
("이 영화 추천해요.", "이 영화 꼭 보시는 걸 추천드립니다."),
("서울은 인구가 많아요.", "서울은 사람이 매우 많은 도시예요.")
]
# 데이터셋 생성
dataset_name = "Korean_Similarity_Set_V3"
dataset = client.create_dataset(dataset_name=dataset_name)데이터셋 고유 ID
dataset.id- 출력
UUID('26dbb531-6f22-48ae-891b-51e1c34dcf80')데이터셋에 예제 추가
# 입력과 출력 데이터 준비
inputs = [{"input_text": input_text} for input_text, _ in similar_sentences]
outputs = [{"similar_text": similar_text} for _, similar_text in similar_sentences]
# 데이터셋에 예제 추가
client.create_examples(inputs=inputs, outputs=outputs, dataset_id=dataset.id)문장 유사도 평가
- 직접 LangSmith - Evaluation 메뉴에서 확인하거나 하단의 출력 링크에서 확인 가능
from langsmith.evaluation import LangChainStringEvaluator, evaluate
from langchain_openai import OpenAIEmbeddings
# 문자열 거리 기반 평가
string_distance_evaluator = LangChainStringEvaluator(
"string_distance",
config={"distance": "levenshtein", "normalize_score": True},
prepare_data=lambda run, example: {
"prediction": run.outputs["predicted_text"], # 실험을 통해 생성되는 예측값
"reference": example.outputs["similar_text"], # 데이터셋에서 제공되는 참조값
}
)
# 임베딩 거리 기반 평가
embedding_distance_evaluator = LangChainStringEvaluator(
"embedding_distance",
config={
"distance_metric": "cosine",
"embeddings": OpenAIEmbeddings(model="text-embedding-3-small")
},
prepare_data=lambda run, example: {
"prediction": run.outputs["predicted_text"],
"reference": example.outputs["similar_text"],
}
)
# 평가 실행
def similarity_test(input_data):
# 여기서는 간단한 예시로 입력 문장을 그대로 반환
return {"predicted_text": input_data["input_text"]}
evaluation_result = evaluate(
similarity_test,
data=dataset_name,
evaluators=[
string_distance_evaluator,
embedding_distance_evaluator
]
)- 출력
View the evaluation results for experiment: 'virtual-earth-85' at:
https://smith.langchain.com/o/ed651458-0d10-40ec-a782-...
5it [00:11, 2.25s/it]평가 결과 출력
evaluation_result- 출력