
[RAG] 평가 지표 (1) Metric 에서 이어집니다.
K-RAG DOCS 페이지
📌 RAG Evaluation _ K-RAG
pip install krag / poetry add krag
-
문서 표현
KragDocument클래스를 사용하여 문서를 표현- 각 문서는
page_content속성을 통해 내용을 저장
-
평가 방식:
- 텍스트 매칭:
OfflineRetrievalEvaluators사용 - ROUGE 매칭:
RougeOfflineRetrievalEvaluators사용 (rouge1, rouge2, rougeL 지원)
- 텍스트 매칭:
-
주요 매개변수:
match_method: 문서 매칭 방식 ("text", "rouge1", "rouge2", "rougeL")averaging_method: 평균 계산 방식matching_criteria: 매칭 기준 (완전/부분)rouge_threshold: ROUGE 매칭시 임계값 (F1 스코어)
- 제공되는 평가 지표:
- Hit Rate: 검색 결과의 적중률
- MRR: 첫 관련 문서 순위의 역수 평균
- Recall: 검색된 관련 문서의 비율
- Precision: 검색 결과의 정확도
- F1 Score: 정밀도와 재현율의 조화평균
- MAP: 평균 정밀도
- NDCG: 순위를 고려한 누적 이득
1️⃣ ROUGE 점수
pip install rouge_score / poetry add rouge_score
rouge_score 관련해서는 추후에 다뤄보겠습니다 .. !
- ROUGE-N: 기준 텍스트와 생성 텍스트 간의 n-그램(예: 1-그램, 2-그램 등) 일치를 측정
-
ROUGE-1은 단어 하나 하나의 일치여부 ( 단어 단위의 정확도 ) -
ROUGE-2는 두 단어씩 묶어 평가 ( 구 또는 짧은 문장 단위의 일치도 평가 )
ROUGE-L: 가장 긴 공통 부분 (Longest Common Subsequence, LCS)를 사용, 요약의 순서를 고려한 일치도 측정
-
생성 텍스트와 기준 텍스트 간에 얼마나 비슷한 순서로 내용이 나타나는지를 평가
-
요약의 순서와 연속성을 반영
2️⃣ K-RAG
Evaluator 클래스 정의
from krag.evaluators import (
OfflineRetrievalEvaluators,
RougeOfflineRetrievalEvaluators,
)
class RAGEvaluator:
"""RAG 시스템의 검색 성능을 평가하는 클래스"""
def __init__(
self,
match_method="text", # "text", "rouge1", "rouge2", "rougeL"
rouge_threshold=0.5
):
self.match_method = match_method
self.rouge_threshold = rouge_threshold
self.evaluator = None # evaluator 인스턴스를 저장할 속성 추가
def _initialize_evaluator(self, actual_docs, predicted_docs):
"""평가자 초기화"""
if self.match_method in ["rouge1", "rouge2", "rougeL"]:
self.evaluator = RougeOfflineRetrievalEvaluators(
actual_docs,
predicted_docs,
match_method=self.match_method,
threshold=self.rouge_threshold
)
else:
self.evaluator = OfflineRetrievalEvaluators(
actual_docs,
predicted_docs,
match_method=self.match_method,
)
return self.evaluator
def evaluate_all(self, actual_docs, predicted_docs, k=10, visualize=False):
"""
모든 평가 지표를 계산
Args:
actual_docs: 실제 관련 문서 리스트 (List[List[Document]])
predicted_docs: 시스템이 검색한 문서 리스트 (List[List[Document]])
k: 상위 k개 문서만 고려
visualize: 결과 시각화 여부
Returns:
Dict[str, float]: 각 평가 지표의 계산 결과
"""
# evaluator가 초기화되지 않았거나 새로운 문서로 평가할 경우 재초기화
if self.evaluator is None:
self._initialize_evaluator(actual_docs, predicted_docs)
results = {
'hit_rate': self.evaluator.calculate_hit_rate(k=k),
'mrr': self.evaluator.calculate_mrr(k=k),
'recall': self.evaluator.calculate_recall(k=k),
'precision': self.evaluator.calculate_precision(k=k),
'f1_score': self.evaluator.calculate_f1_score(k=k),
'map': self.evaluator.calculate_map(k=k),
'ndcg': self.evaluator.calculate_ndcg(k=k)
}
if visualize:
self.evaluator.visualize_results(k=k)
return results
def get_evaluator(self):
"""현재 설정된 evaluator 인스턴스를 반환"""
return self.evaluator평가 수행 (이전 글에서 사용했던 doc1 ~ doc6 샘플)
# krag 라이브러리를 사용한 평가 (샘플 데이터셋)
evaluator = RAGEvaluator(match_method="text") # 텍스트 일치 기반 평가
results = evaluator.evaluate_all(actual_docs, predicted_docs, k=10, visualize=False)
pprint(results)- 출력
{'f1_score': {'macro_f1': 0.7058823529411765, 'micro_f1': 0.7272727272727272},
'hit_rate': {'hit_rate': 0.5},
'map': {'map': 0.625},
'mrr': {'mrr': 0.75},
'ndcg': {'ndcg': 0.8154648767857288},
'precision': {'macro_precision': 0.6666666666666666,
'micro_precision': 0.6666666666666666},
'recall': {'macro_recall': 0.75, 'micro_recall': 0.8}}평가 수행 (이전 글에서 사용했던 테슬라 샘플)
from langchain_core.documents import Document
# 검색 결과를 Document 객체로 이루어진 리스트로 변환
retrieved_contexts = [
[Document(page_content=doc) for doc in result["retrieved"]]
for result in retrieved_results
]
# 검색 결과 확인
print(f"검색 결과: {len(retrieved_contexts)}개 문서")
retrieved_contexts[:2]# 테스트셋의 정답 문서를 Document 객체로 변환
actual_contexts = [
[Document(page_content=doc) for doc in result["context"]]
for result in retrieved_results
]
# 정답 문서 확인
print(f"정답 문서: {len(actual_contexts)}개 문서")
actual_contexts[:2]# rouge1, rouge2, rougeL 평가 (테슬라 테스트셋) - 텍스트의 일치 여부가 아닌 Rouge 점수로 평가 (문서의 유사성)
rouge_evaluator = RAGEvaluator(match_method="rouge1", rouge_threshold=0.8) # Rouge1 기반 평가
# 평가 수행
rouge_results = rouge_evaluator.evaluate_all(actual_contexts, retrieved_contexts, k=10, visualize=False)
pprint(rouge_results)- 출력
{'f1_score': {'macro_f1': 0.28041919470490895, 'micro_f1': 0.28181818181818186},
'hit_rate': {'hit_rate': 0.2857142857142857},
'map': {'map': 0.32142857142857145},
'mrr': {'mrr': 0.4217687074829932},
'ndcg': {'ndcg': 0.9340557384601141},
'precision': {'macro_precision': 0.21088435374149658,
'micro_precision': 0.2108843537414966},
'recall': {'macro_recall': 0.41836734693877553,
'micro_recall': 0.4246575342465753}}3️⃣ Information Retrieval 평가지표
-
Hit Rate는 0~1 사이의 값으로 검색된 문서 중 실제 관련 있는 문서의 비율을 측정하며, 순서를 고려하지 않은 기본적인 평가 지표
-
Mean Reciprocal Rank (MRR) 은 첫 번째 관련 문서가 등장하는 순위의 역수를 평균 내어 계산하며, 검색 결과의 순서를 고려한 평가가 가능
-
Mean Average Precision (mAP@k) 는 상위 k개 문서 내에서 관련 문서 검색의 정확도를 평균화하여 산출
-
NDCG@k는 문서의 관련성과 검색 순위를 동시에 고려하여 이상적인 순위와 비교한 정규화 점수를 제공하는 종합적인 평가 지표
-
이러한 평가 지표들은 RAG 시스템의 검색 품질을 다각도로 분석하여 성능 개선에 활용
텍스트 매칭 기반 평가
# 텍스트 매칭 기반 평가 (전부 문서내용이 완벽하게 일치하는 경우)
text_evaluator = RAGEvaluator(match_method="text")
text_results = text_evaluator.evaluate_all(
actual_docs,
predicted_docs,
k=10,
visualize=True
)
print("\nText Matching Results:", text_results)- 출력
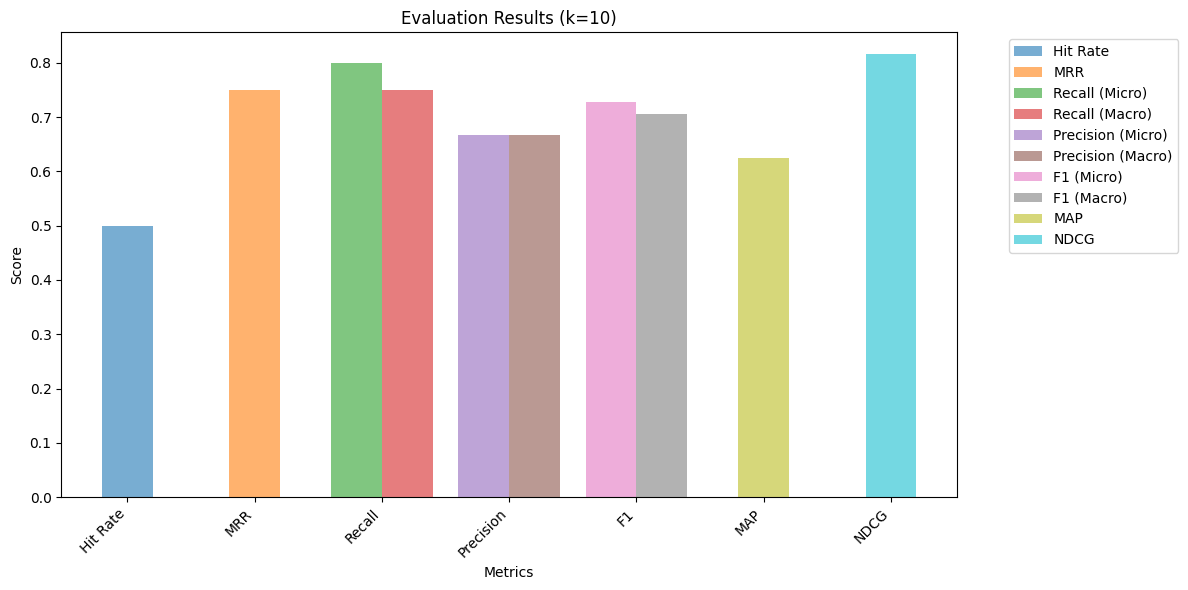
Text Matching Results: {'hit_rate': {'hit_rate': 0.5}, 'mrr': {'mrr': 0.75}, 'recall': {'micro_recall': 0.8, 'macro_recall': 0.75}, 'precision': {'micro_precision': 0.6666666666666666, 'macro_precision': 0.6666666666666666}, 'f1_score': {'micro_f1': 0.7272727272727272, 'macro_f1': 0.7058823529411765}, 'map': {'map': 0.625}, 'ndcg': {'ndcg': 0.8154648767857288}}스코어 분리
# precision, recall, f1 score 계산
precision = text_results["precision"] ['micro_precision']
recall = text_results["recall"]['micro_recall']
f1_score = text_results["f1_score"]['micro_f1']
print(f"Micro-average Precision: {precision:.2f}")
print(f"Micro-average Recall: {recall:.2f}")
print(f"Micro-average F1 Score: {f1_score:.2f}")- 출력
Micro-average Precision: 0.67
Micro-average Recall: 0.80
Micro-average F1 Score: 0.73Rouge 점수 평가
# rouge1, rouge2, rougeL 평가 (리비안 테스트셋) - 텍스트의 일치 여부가 아닌 Rouge 점수로 평가 (문서의 유사성)
rouge_evaluator = RAGEvaluator(match_method="rouge1", rouge_threshold=0.8) # Rouge
# 평가 수행
rouge_results = rouge_evaluator.evaluate_all(actual_contexts, retrieved_contexts, k=10, visualize=True)
pprint(rouge_results)- 출력
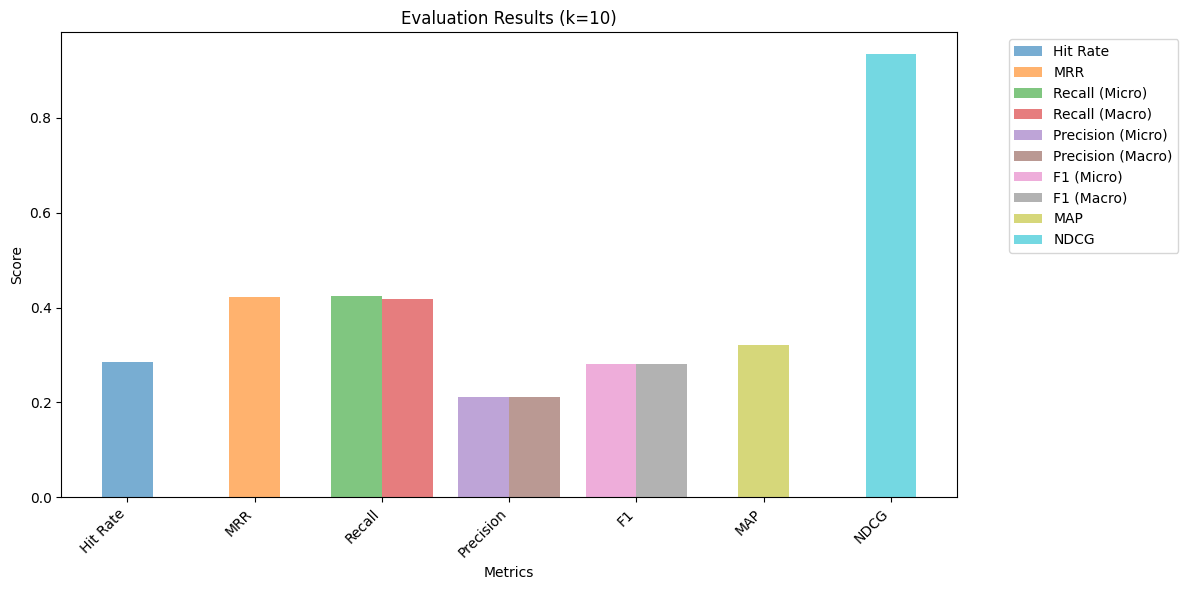
{'f1_score': {'macro_f1': 0.28041919470490895, 'micro_f1': 0.28181818181818186},
'hit_rate': {'hit_rate': 0.2857142857142857},
'map': {'map': 0.32142857142857145},
'mrr': {'mrr': 0.4217687074829932},
'ndcg': {'ndcg': 0.9340557384601141},
'precision': {'macro_precision': 0.21088435374149658,
'micro_precision': 0.2108843537414966},
'recall': {'macro_recall': 0.41836734693877553,
'micro_recall': 0.4246575342465753}}1) Hit Rate (적중률)
-
정보 검색 시스템의 성능을 측정하는 기본적인 평가 지표로, 검색 결과에 정답 문서가 (모두) 포함되어 있는지를 이진법(1 또는 0)으로 평가
-
계산 방식이 단순하여 직관적으로 이해하기 쉽고, 전체 검색 시스템의 기본적인 성능을 빠르게 파악할 수 있다는 장점
-
최종 값은 모든 검색 쿼리에 대한 평균값으로 산출되며, 0에서 1 사이의 값을 가지게 되는데, 1에 가까울수록 검색 시스템의 성능이 우수함을 의미
-
정보 검색 시스템의 기본적인 성능을 평가하는 데 널리 사용되는 지표입니다.
실제 문서, 예측 문서 ID
print("실제 문서 ID:", actual_ids)
print("예측 문서 ID:", predicted_ids)- 출력
실제 문서 ID: [['doc1', 'doc2', 'doc5'], ['doc3', 'doc4']]
예측 문서 ID: [['doc1', 'doc2', 'doc5'], ['doc6', 'doc4', 'doc5']]Hit Rate 계산 (k=1)
# 계산 방법 (k=1)
# 첫 번째 쿼리: doc1 문서를 찾고, doc2, doc5 문서를 못 찾음 -> 0
# 두 번째 쿼리: doc3, doc4 문서를 못 찾음 -> 0
hit_rate = (0 + 0) / 2
print("Hit Rate:", hit_rate)- 출력
Hit Rate: 0.0Hit Rate 계산 (k=2)
# 계산 방법 (k=2)
# 첫 번째 쿼리: doc1, doc2 문서를 찾고, doc5 문서를 못 찾음 -> 0
# 두 번째 쿼리: doc4 문서를 찾고, doc3 문서를 못 찾음 -> 0
hit_rate = (0 + 0) / 2
print("Hit Rate:", hit_rate)- 출력
Hit Rate: 0.0Hit Rate 계산 (k=3)
# 계산 방법 (k=3)
# 첫 번째 쿼리: doc1, doc2, doc5 문서를 찾음 -> 1
# 두 번째 쿼리: doc4 문서를 찾고, doc3 문서를 못 찾음 -> 0
hit_rate = (1 + 0) / 2
print("Hit Rate:", hit_rate)- 출력
Hit Rate: 0.5Hit Rate 계산 (패키지 활용)
# 'Hit Rate' 계산
k_values = [1, 2, 3]
for k in k_values:
hit_rate = text_evaluator.get_evaluator().calculate_hit_rate(k=k)
print(f"Hit Rate @{k}: {hit_rate['hit_rate']:.3f}")- 출력
Hit Rate @1: 0.000
Hit Rate @2: 0.000
Hit Rate @3: 0.5002) MRR (Mean Reciprocal Rank)
-
MRR은 검색 결과에서 첫 번째로 등장하는 관련 문서의 순위를 기반으로 성능을 평가하는 지표로, 특히 사용자가 원하는 정보를 얼마나 빨리 찾을 수 있는지를 측정
-
계산 방법은 각 검색 쿼리별로 첫 번째 관련 문서의 순위의 역수(1/rank)를 구한 후, 전체 쿼리에 대한 평균을 계산 (예: 정답이 3번째에 있다면 1/3)
-
MRR은 검색 결과의 순서를 고려하기 때문에, 단순히 관련 문서의 포함 여부만을 평가하는 Hit Rate보다 더 실용적인 성능 평가가 가능
-
특히 사용자 경험(UX) 관점에서 중요한 의미를 가지며, 검색 시스템의 실질적인 유용성을 평가하는 데 효과적
실제 문서, 예측 문서 ID
print("실제 문서 ID:", actual_ids)
print("예측 문서 ID:", predicted_ids)- 출력
실제 문서 ID: [['doc1', 'doc2', 'doc5'], ['doc3', 'doc4']]
예측 문서 ID: [['doc1', 'doc2', 'doc5'], ['doc6', 'doc4', 'doc5']]MRR 계산 (k=1)
# 계산 방법 (k=1)
# 첫 번째 쿼리: doc1 문서가 가장 먼저 찾은 관련 문서이므로 rank는 1이 됨 -> 1/1
# 두 번째 쿼리: doc6은 실제 정답이 아님 -> 0
mrr = (1/1 + 0) / 2
print("Mean Reciprocal Rank:", mrr)- 출력
Mean Reciprocal Rank: 0.5MRR 계산 (k=2)
# 계산 방법 (k=2)
# 첫 번째 쿼리: doc1 문서가 가장 먼저 찾은 관련 문서이므로 rank는 1이 됨 -> 1/1
# 두 번째 쿼리: 두 번째 위치한 doc4 문서가 가장 먼저 찾은 관련 문서이므로 rank는 2이 됨 -> 1/2
mrr = (1/1 + 1/2) / 2
print("Mean Reciprocal Rank:", mrr)- 출력
Mean Reciprocal Rank: 0.75MRR 계산 (k=3)
# 계산 방법 (k=3)
# 첫 번째 쿼리: doc1 문서가 가장 먼저 찾은 관련 문서이므로 rank는 1이 됨 -> 1/1
# 두 번째 쿼리: 두 번째 위치한 doc4 문서가 가장 먼저 찾은 관련 문서이므로 rank는 2이 됨 -> 1/2
mrr = (1/1 + 1/2) / 2
print("Mean Reciprocal Rank:", mrr)- 출력
Mean Reciprocal Rank: 0.75MRR 계산 (패키지 활용)
# 'Mean Reciprocal Rank' 계산
for k in k_values:
mrr = evaluator.get_evaluator().calculate_mrr(k=k)
print(f"MRR @{k}: {mrr['mrr']:.3f}")- 출력
MRR @1: 0.500
MRR @2: 0.750
MRR @3: 0.7503) mAP@k (Mean Average Precision at k)
-
mAP@k는 검색 결과의 품질을 평가하는 고급 지표로, 상위 k개의 검색 결과 내에서 관련 문서들의 순위와 정확도를 종합적으로 평가
-
단순히 관련 문서의 존재 여부나 첫 등장 순위뿐만 아니라, 상위 k개 결과 내에서 관련 문서들의 전반적인 분포와 순서까지 고려하여 더욱 세밀한 성능 평가가 가능
-
검색 서비스에서 사용자에게 가장 중요한 상위 검색 결과의 품질에 초점을 맞추고 있어, 실용적인 관점에서 시스템의 성능을 평가하는 데 매우 효과적
-
정보 검색 시스템의 실제 사용성과 가장 밀접하게 연관되어 있어, 현대 검색 엔진 개발에서 널리 사용되고 있음
실제 문서, 예측 문서 ID
print("실제 문서 ID:", actual_ids)
print("예측 문서 ID:", predicted_ids)- 출력
실제 문서 ID: [['doc1', 'doc2', 'doc5'], ['doc3', 'doc4']]
예측 문서 ID: [['doc1', 'doc2', 'doc5'], ['doc6', 'doc4', 'doc5']]AP(Average Precision)
-
계산식: (각 정답 문서 위치에서의 Precision의 합) / (전체 정답 문서 수)`
- : i번째 위치에서의 Precision
- : i번째 문서가 정답이면 1, 아니면 0
- : 전체 정답 문서의 수
- : 예측된 문서의 수
-
예시 케이스:
-
실제 정답: →
-
예측 결과: → 정답인 는 2번째 위치
-
: 예측 결과에 없음 →
-
: 2번째 위치 →
-
따라서,
-
-
여기서 2로 나누는 것은 전체 정답 문서 수()로 나누는 것
- 정답 문서의 수가 다른 쿼리들 간의 공정한 비교
- AP 값을 범위로 정규화
mAP@k (Mean Average Precision at k)
-
mAP@1 계산
-
쿼리 1의 AP@1:
- 예측: [doc1, doc2, doc5], 정답: [doc1, doc2, doc5]
- (첫 번째 위치의 정밀도)
- (정답 문서 3개로 나눔)
-
쿼리 2의 AP@1:
- 예측: [doc6, doc4, doc5], 정답: [doc3, doc4]
- (첫 번째 위치의 정밀도)
- (정답 문서 2개로 나눔)
-
-
-
mAP@2 계산
-
쿼리 1의 AP@2:
- ,
-
쿼리 2의 AP@2:
- ,
-
-
-
mAP@3 계산
-
쿼리 1의 AP@3:
- , ,
-
쿼리 2의 AP@3:
- , ,
- (주의: P(3)은 새로운 정답이 아니므로 포함하지 않음)
-
-
설명:
1. 각 k에서는 상위 k개의 문서만 고려합니다.
2. 정답 문서가 나타나는 위치의 정밀도만 합산합니다.
3. 합산된 정밀도를 해당 쿼리의 전체 정답 문서 수로 나눕니다.
- 모든 쿼리의 AP 값을 평균하여 최종 mAP를 계산합니다.
mAP 계산 (패키지 활용)
# mAP 계산 - KRAG 라이브러리 사용
for k in k_values:
map_score = text_evaluator.get_evaluator().calculate_map(k=k)
print(f"mAP@{k}: {map_score['map']:.3f}")- 출력
mAP@1: 0.167
mAP@2: 0.458
mAP@3: 0.6254) NDCG (Normalized Discounted Cumulative Gain)
-
NDCG는 검색 및 추천 시스템의 순위 품질을 평가하는 고급 지표로, 단순히 관련성 여부뿐만 아니라 결과의 순서까지 고려하여 시스템의 성능을 평가
-
검색 결과의 위치에 따라 가중치를 다르게 부여 (상위에 있는 관련 문서에는 더 높은 가중치를, 하위에 있는 문서에는 더 낮은 가중치를 부여)
-
NDCG는 이상적인 순위(ideal ranking)와 비교하여 정규화된 점수를 제공하므로, 다른 검색 결과나 시스템 간의 비교가 용이 (0~1 범위. 1에 가까울수록 이상적)
-
특히 사용자의 실제 만족도와 밀접한 관련이 있어, 현대의 검색 및 추천 시스템 평가에서 매우 중요하게 사용됨
-
기본 공식:
- DCG@k =
- 는 i번째 문서의 관련성(이진의 경우 0 또는 1)
- NDCG@k = DCG@k / IDCG@k
- DCG@k =
-
NDCG@1 계산
- 쿼리 1 (k=1):
- 예측: [doc1, doc2, doc5], 정답: [doc1, doc2, doc5]
- DCG@1 계산:
- rel₁ = 1 (doc1은 정답)
- DCG@1 = (2¹-1)/log₂(2) = 1/1 = 1
- IDCG@1 계산:
- 최적의 경우도 동일
- IDCG@1 = 1
- NDCG@1 = 1/1 = 1
- 쿼리 2 (k=1):
- 예측: [doc6, doc4, doc5], 정답: [doc3, doc4]
- DCG@1 계산:
- rel₁ = 0 (doc6은 정답 아님)
- DCG@1 = (2⁰-1)/log₂(2) = 0
- IDCG@1 계산:
- 최적의 경우 첫 위치에 정답
- IDCG@1 = (2¹-1)/log₂(2) = 1
- NDCG@1 = 0/1 = 0
- 평균 NDCG@1: (1 + 0)/2 = 0.500
-
NDCG@2 계산
- 쿼리 1 (k=2):
- DCG@2 계산:
- rel₁ = 1, rel₂ = 1
- DCG@2 = (2¹-1)/log₂(2) + (2¹-1)/log₂(3) = 1/1 + 1/1.58 = 1.631
- IDCG@2 = 1.631 (동일한 최적 순서)
- NDCG@2 = 1.631/1.631 = 1
- 쿼리 2 (k=2):
- DCG@2 계산:
- rel₁ = 0, rel₂ = 1
- DCG@2 = (2⁰-1)/log₂(2) + (2¹-1)/log₂(3) = 0 + 1/1.58 = 0.631
- IDCG@2 = 1 + 1/1.58 = 1.631
- NDCG@2 = 0.631/1.631 = 0.63
- 평균 NDCG@2: (1 + 0.63)/2 = 0.815
-
NDCG@3 계산
- 쿼리 1 (k=3):
- DCG@3 계산:
- rel₁ = 1, rel₂ = 1, rel₃ = 1
- DCG@3 = 1/1 + 1/1.58 + 1/2 = 2.131
- IDCG@3 = 2.131
- NDCG@3 = 2.131/2.131 = 1
- 쿼리 2 (k=3):
- DCG@3 계산:
- rel₁ = 0, rel₂ = 1, rel₃ = 0
- DCG@3 = 0 + 1/1.58 + 0 = 0.631
- IDCG@3 = 1 + 1/1.58 = 1.631
- NDCG@3 = 0.631/1.631 = 0.63
- 평균 NDCG@3: (1 + 0.63)/2 = 0.815
NDCG@k 결과 해석
-
NDCG@1 = 0.500
- 첫 번째 위치만 고려했을 때의 성능을 나타냄
- 0.5라는 값은 시스템이 두 쿼리 중:
- 쿼리 1에서는 완벽히 성공 (doc1이 정답)
- 쿼리 2에서는 완전히 실패 (doc6이 오답)
- 즉, 가장 첫 번째 순위에 대해서는 50%의 정확도를 보여줌
-
NDCG@2 = 0.815
- 상위 2개 문서까지 고려했을 때 성능이 크게 향상됨
- 성능 향상의 이유:
- 쿼리 1: 여전히 완벽한 순서 (doc1, doc2 모두 정답)
- 쿼리 2: 두 번째 위치에서 정답 문서(doc4)를 찾아 점수가 상승
-
NDCG@3 = 0.815
- 상위 3개 문서까지 봤을 때 NDCG@2와 동일한 점수를 유지
- 이는 세 번째 순위가 추가되어도 성능 변화가 없었다는 의미
- 쿼리 1: 세 번째도 정답 (doc5)이지만 이미 완벽했기 때문에 변화가 없음
- 쿼리 2: 세 번째는 오답 (doc5)이라 점수에 영향 없음
NDCG 계산 (패키지 활용)
# NDCG 계산 - KRAG 라이브러리 사용
for k in k_values:
ndcg = text_evaluator.get_evaluator().calculate_ndcg(k=k)
print(f"NDCG @{k}: {ndcg['ndcg']:.3f}")- 출력
NDCG @1: 0.500
NDCG @2: 0.815
NDCG @3: 0.8155) 주요 평가 지표(NDCG, mAP, MRR, Hit Rate) 비교
-
목적과 평가 방식
- NDCG는 전체 검색 결과의 순위 품질을 평가하며, 상위 결과에 더 높은 가중치를 부여하여 순위의 적절성을 종합적으로 측정하는 지표임
- mAP는 상위 k개 결과 내에서 관련 문서들의 정확도를 평가하여, 검색의 전반적인 정확성을 측정하는 방식임
- MRR은 첫 번째 관련 문서의 등장 순위만을 고려하여, 원하는 정보를 얼마나 빨리 찾을 수 있는지 평가하는 지표임
- Hit Rate는 검색 결과에 관련 문서가 포함되어 있는지 여부만을 이진법(0 또는 1)으로 평가하는 가장 기본적인 지표로 판단됨
-
계산 방식의 특징
- NDCG는 문서의 순위에 따라 로그 스케일로 감소하는 가중치를 적용하여, 상위 결과의 중요성을 강조하는 특징이 있음
- mAP는 각 관련 문서의 위치에서의 정밀도를 평균하여, 검색 결과의 전반적인 품질을 평가하는 방식임
- MRR은 첫 관련 문서의 순위 역수만을 사용하여, 가장 단순하고 직관적인 평가를 제공하는 특징이 있음
- Hit Rate는 단순히 관련 문서의 포함 여부만을 확인하므로, 계산이 매우 단순하고 직관적인 특징을 가짐
-
활용 상황
- NDCG는 검색 결과의 전체적인 순위 품질이 중요한 일반 검색 엔진에 적합함
- mAP는 정보 검색 시스템의 전반적인 성능 평가에 유용함
- MRR은 질의응답 시스템처럼 첫 번째 정답의 위치가 매우 중요한 경우에 효과적임
- Hit Rate는 시스템의 기본적인 성능을 빠르게 파악해야 할 때 또는 순위가 중요하지 않은 경우에 유용함
