
📌 RAG (Retrieval-Augmented Generation)
-
RAG란?
- RAG는 기존 LLM의 한계를 보완하기 위한 방법론
- 외부 데이터를 검색하여 LLM의 지식을 보강하는 방식으로 동작 (기존의 언어 모델에 검색 기능을 추가)
- 최신 정보나 특정 도메인의 전문 지식을 활용 가능
- 주어진 질문이나 문제에 대해 더 정확하고 풍부한 정보를 기반으로 답변을 생성
-
RAG의 장점
- 환각(Hallucination) 감소
- 최신 정보 반영 가능
- 도메인 특화된 응답 생성
- 소스 추적 가능성 확보
-
핵심 구성요소
-
검색(Retrieval) 시스템
- 임베딩 모델: 텍스트를 벡터로 변환
- 벡터 데이터베이스: 임베딩 벡터를 저장 (인덱싱)
- 유사도 검색 알고리즘:
- Cosine Similarity
- Euclidean Distance
- Dot Product
-
증강(Augmentation)
- 검색된 문서의 전처리
- 프롬프트 엔지니어링 기법
- 컨텍스트 길이 제한 관리
-
생성(Generation) 단계
- LLM의 기본 동작으로 응답 생성
- 응답 형식 제어
-
1️⃣ Indexing
- 문서 수집 및 전처리
- 문서 청크 분할
- 임베딩 생성
- 벡터 저장소 구축
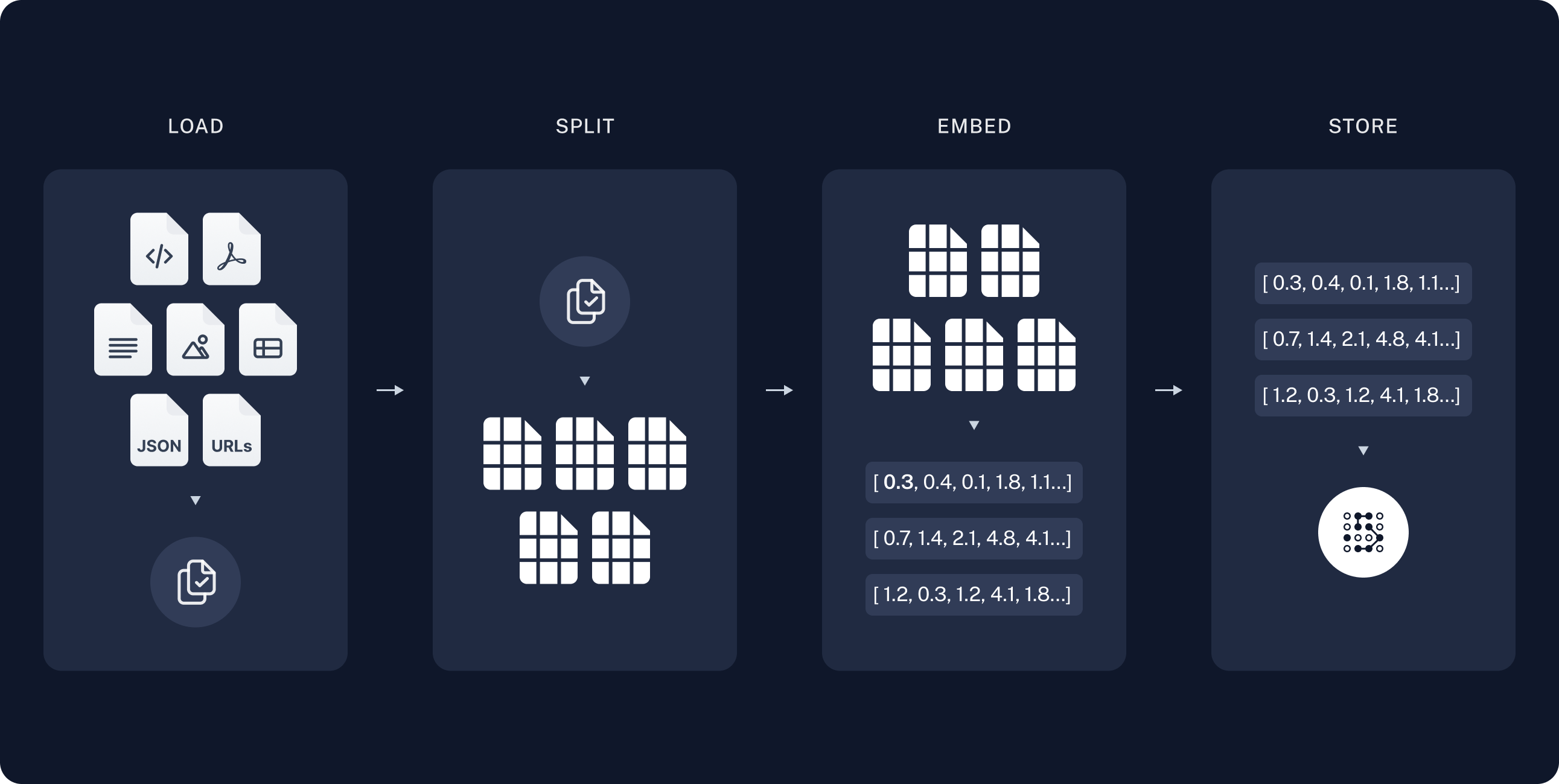
1. 문서 데이터 로드
-
RAG에 사용할 데이터를 불러오는 단계 (검색에 사용될 지식이나 정보)
-
외부 데이터 소스에서 정보를 수집하고, 필요한 형식으로 변환하여 시스템에 로드
-
설치:
pip install beautifulsoup4/poetry add beautifulsoup4
# Data Loader - 웹페이지 데이터 가져오기
from langchain_community.document_loaders import WebBaseLoader # type: ignore
# 위키피디아 정책과 지침
url = 'https://ko.wikipedia.org/wiki/%EC%9C%84%ED%82%A4%EB%B0%B1%EA%B3%BC:%EC%A0%95%EC%B1%85%EA%B3%BC_%EC%A7%80%EC%B9%A8'
loader = WebBaseLoader(url)
# 웹페이지 텍스트 -> Document 객체로 변환
docs = loader.load()
# 결과 확인
print(f"Document 개수: {len(docs)}")
print(f"Document 길이: {len(docs[0].page_content)}")
print(f"Document 내용: {docs[0].page_content[5000:6000]}")- 출력
Document 개수: 1
Document 길이: 13312
Document 내용: 체의 규범을 총체적으로 어기고 있다면 규범 준수를 위해 좀 더 빠르게 강력한 수단을 이용해야 합니다. 특히 ...Document 객체 확인
docs[0] # Document 객체 확인- 출력
Document(metadata={'source': 'https://ko.wikipedia.org ...Document 의 메타데이터 확인
docs[0].metadata # Document의 메타데이터 확인- 출력
{'source': 'https://ko.wikipedia.org/wiki/%EC%9C%84%ED%82%A4%EB%B0%B1%EA%B3%BC:%EC%A0%95%EC%B1%85%EA%B3%BC_%EC%A7%80%EC%B9%A8',
'title': '위키백과:정책과 지침 - 위키백과, 우리 모두의 백과사전',
'language': 'ko'}Document 의 페이지 내용 확인
docs[0].page_content # Document의 페이지 내용 확인- 출력
'\n\n\n\n위키백과:정책과 지침 - 위키백과, 우리 모두의 백과사전\n\ ...2. 문서 청크 분할
-
불러온 데이터를 작은 크기의 단위(chunk)로 분할하는 과정
-
자연어 처리(NLP) 기술을 활용하여 큰 문서를 처리가 쉽도록 문단, 문장 또는 구 단위로 나누는 작업
-
검색 효율성을 높이기 위한 중요한 과정
-
청크 크기 선택
- 너무 작은 청크: 문맥 손실
- 너무 큰 청크: 관련성 저하
-
중복 영역 설정
- 문맥 유지를 위해 필요
- 일반적으로 10-20% 권장
-
-
설치:
pip install langchain_text_splitters/poetry add langchain_text_splitters
# Text Split (Documents -> small chunks: Documents)
from langchain_text_splitters import CharacterTextSplitter # type: ignore
# 1000자씩 잘라서 200자씩 겹치는 Document로 변환
text_splitter = CharacterTextSplitter(
separator="\n\n", # 문단 구분자
chunk_size=1000, # 문단 길이
chunk_overlap=200, # 겹치는 길이
length_function=len, # 길이 측정 함수
is_separator_regex=False, # separator가 정규식인지 여부
)
splitted_docs = text_splitter.split_documents(docs)
# 결과 확인
print(f"Document 개수: {len(splitted_docs)}")
print("\n\n")
for i, doc in enumerate(splitted_docs):
print(f"Document {i} 길이: {len(doc.page_content)}")
print(f"Document {i} 내용: {doc.page_content[:200]}...")
print(f"Document {i} 뒷 내용: {doc.page_content[-200:]}...")
print("-"*50)- 출력
Created a chunk of size 1525, which is longer than the specified 1000
Created a chunk of size 1439, which is longer than the specified 1000
Document 개수: 16
Document 0 길이: 480
Document 0 내용: 위키백과:정책과 지침 - 위키백과, 우리 모두의 백과사전 ...- 글자 수 (chunk_size) 기준으로 엄격하게 분할하고 싶다면 문단 구분자 (separator) 를 공백으로 설정
# 글자 수 기준으로 엄격하게 분할하기
from langchain_text_splitters import CharacterTextSplitter # type: ignore
# 1000자씩 잘라서 Document로 변환
text_splitter = CharacterTextSplitter(
separator="", # 문단 구분자
chunk_size=1000, # 문단 길이
length_function=len, # 길이 측정 함수
is_separator_regex=False, # separator가 정규식인지 여부
)
equally_splitted_docs = text_splitter.split_documents(docs)
# 결과 확인
print(f"Document 개수: {len(equally_splitted_docs)}")
print("\n\n")
for i, doc in enumerate(equally_splitted_docs):
print(f"Document {i} 길이: {len(doc.page_content)}")
print("-"*50)- 출력
Document 개수: 17
Document 0 길이: 996
--------------------------------------------------
Document 1 길이: 1000
--------------------------------------------------
Document 2 길이: 9993. 문서 임베딩 생성
- 임베딩 모델을 사용하여 텍스트를 벡터로 변환
- 임베딩을 기반으로 유사성 검색에 사용
- 임베딩 모델 선택
- 성능과 비용 고려
- 다국어 지원 여부 확인
# OpenAI Embeddings - 문장 임베딩
from langchain_openai import OpenAIEmbeddings # type: ignore
# embedding model 생성
embedding_model = OpenAIEmbeddings(
model="text-embedding-3-small", # 사용할 모델 이름을 지정 가능
)
sample_text = "위키피디아 정책 변경 절차를 알려주세요"
embedding_vector = embedding_model.embed_query(sample_text)
print(f"임베딩 벡터의 차원: {len(embedding_vector)}")
print(f"임베딩 벡터: {embedding_vector[:10]}...")- 출력
임베딩 벡터의 차원: 1536
임베딩 벡터: [-0.008793548680841923, 0.04734107851982117, ...]4. 벡터 저장소 구축
- 임베딩 벡터를 벡터저장소에 저장
- 저장된 임베딩을 기반으로 유사성 검색을 수행하는데 활용
# In-memory 벡터 저장소에 문서 저장하기
from langchain_core.vectorstores import InMemoryVectorStore # type: ignore
vector_store = InMemoryVectorStore(embedding_model)
# Document를 VectorStore에 저장
document_ids = vector_store.add_documents(splitted_docs)
# 결과 확인
print(f"저장된 Document 개수: {len(document_ids)}")- 출력
저장된 Document 개수: 16저장된 Document ids 확인
vector_store.store.keys() # 저장된 Document ids 확인- 출력
dict_keys(['06032f64-1302-4665-a1cc-4db36403a966', '68dbd057-ecb8-482e-8f18-8743278e9d0e', ...])VectorStore 에 저장된 문서 삭제하기
# 문서 삭제하기
vector_store.delete(ids=list(vector_store.store.keys())[:1])
# VectorStore에 저장된 Document 개수 확인
print(f"VectorStore에 저장된 Document 개수: {len(vector_store.store.keys())}")- 출력
VectorStore에 저장된 Document 개수: 152️⃣ Retrieval and Generation
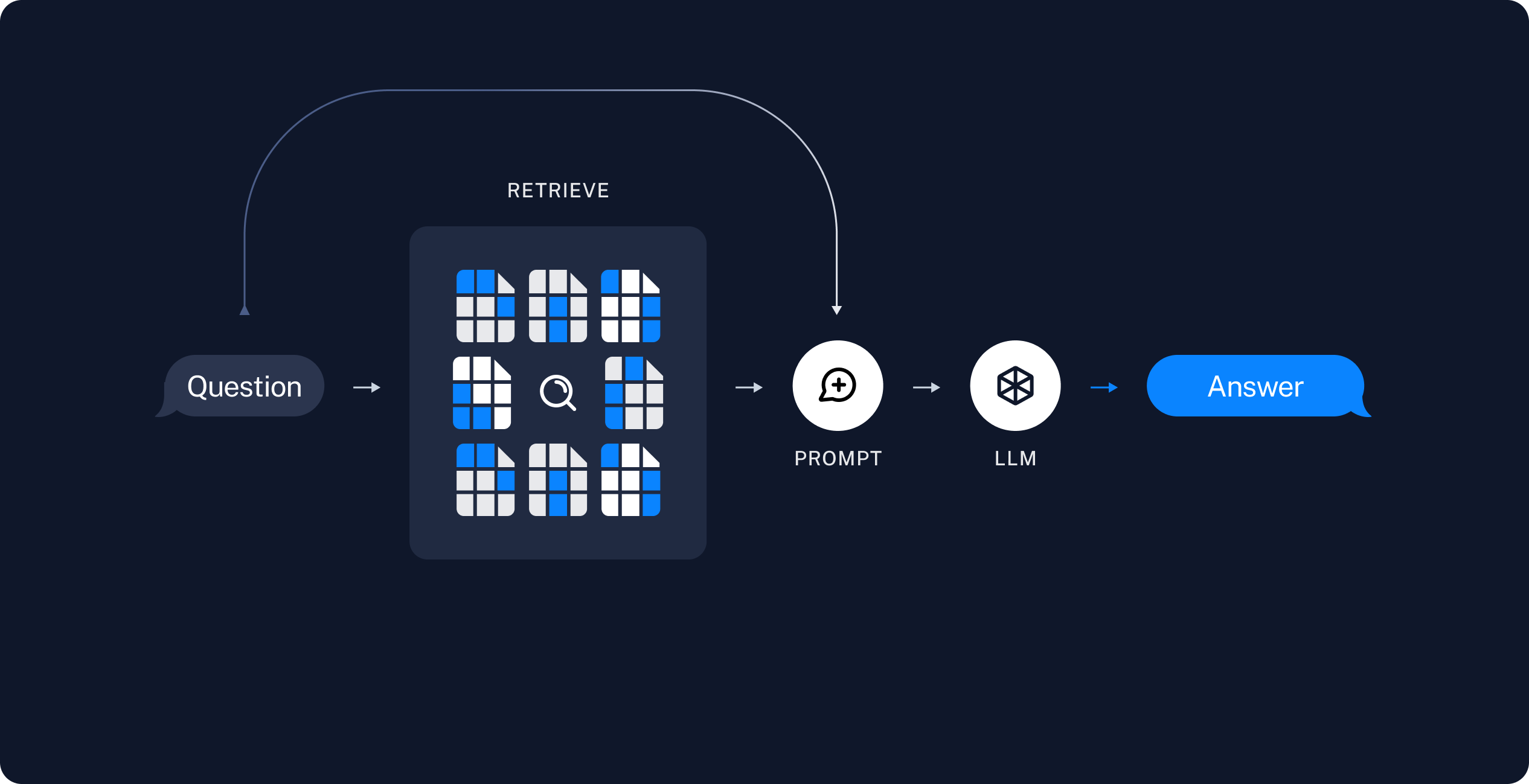
5. 검색 및 생성
# 벡터 스토어 문서 검색 - 유사도 기반 검색
search_query = "위키피디아 정책 변경 절차를 알려주세요"
results = vector_store.similarity_search(query=search_query, k=2) # k : 검색할 문서의 개수
for doc in results:
print(f"* {doc.page_content} [{doc.metadata}]")
print("-"*50)검색기 (Retriever) 정의 후 검색 (결과 동일)
# 벡터 스토어 검색기 설정 - 유사도 기반 검색
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 2},
)
# 검색기로 검색하기
results = retriever.invoke(input=search_query)
# 결과 확인
for doc in results:
print(f"* {doc.page_content} [{doc.metadata}]")
print("-"*50)- 출력
* 내용 변경
정책과 지침은 다른 위키백과 문서처럼 편집할 수 있습니다. 사전에 ... [{'source': 'https ...}]✅ QA 체인 실습
# QA 체인 구성
from langchain.chains import RetrievalQA # type: ignore
from langchain_openai import ChatOpenAI # type: ignore
qa_chain = RetrievalQA.from_chain_type(
# Chain for question-answering against a vector database.
llm=ChatOpenAI(model="gpt-4o-mini"),
chain_type="stuff",
retriever=retriever,
)
# 질문 응답
query = "위키피디아 정책 변경 절차를 알려주세요"
response = qa_chain.invoke(query)
# 결과 확인
print(f"Q: {response['query']}")
print(f"A: {response['result']}")- 출력
Q: 위키피디아 정책 변경 절차를 알려주세요
A: 위키피디아 정책 변경 절차는 다음과 같습니다:
1. **토론 먼저 하세요**: 정책의 ...