
글을 시작하기 앞서 GPU가 필수적이고 최소한의 금액으로 서버를 운영하고 싶었기에 이런 아키텍처를 구현한 것이니 허점이 있을 수 밖에 없다는 사실을 미리 말하고 시작하고 싶다.. 😥😥
또한 시행착오를 중심으로 경험에 대해 글을 작성할 것이기에 배운다기보다는 구경하는 느낌으로 보면 좋을 것 같다..
Spot 인스턴스 활용하기 ✅
이전 글에서 말했듯 필자는 Spot 인스턴스를 활용해 서버를 구축하기로 했다.
Spot은 이전에 말했듯 예상치 못한 순간에 종료된다. 이를 극복하기 위해 spot에 대해 좀 더 알아보기 시작했다.
다행히도 AWS는 생각보다 친절했다.
EC2 instance rebalance recommendation
스팟이 종료되기 직전에 리밸런싱 경고를 2분전에 생성해 준다.
이는 경고를 잘 이용한다면 중간중간 꺼지는 Spot을 대처할 수 있는 아키텍처를 구성할 수도 있다는 말이 된다.❗
1차 시도. spot 용량 재조정 💥
이런 Spot이 꺼지는 상황에서 AWS는 용량 재조정 기능을 통해 스팟인스턴스가 중단 알림이 울릴 시 교체하는 시도를 진행한다.
때문에 필자는 Target Group에 해당 Spot을 넣어 로드 밸런서를 활용해 API를 전송하는 아키텍처를 아래와 같이 구성했다. (Target Group을 구성한 이유는 IP가 고정되지않았기 때문에)
발생한 문제
실제로 위와 같은 아키텍처로 서비스를 운영했었고 사실 1~2주동안 문제가 발생하지 않았다. 때문에 해당 아키텍처에 대해 문제가 없구나! 라고 인식하던 중 서버에 에러가 발생했다.
사실 해당 문제가 발생했을때 죄없는 spring 서버를 계속 살펴보느라 시간을 아주 많이썼다....
알고보니 아키텍처의 문제였고
때문에 어떤 상황에서 에러가 발생했는지를 파악하기 위해 로그 모니터링을 확인했다.
Spot Instance가 중단되고 새로운 인스턴스가 시작되는 도중에 에러가 발생한 것을 알 수 있었다.

아키텍처를 구성할때 해당 문구를 보고 알아서 교체가 잘 되겠구나라고 생각했다.
하지만 용량 재조정 기능은 스팟이 종료된다는 경고가 울리면 새로운 spot을 확보하고 종료되기 직전에 바로 확보 된 spot이 실행되는 것이 아니라.
실제로는 spot이 종료된 다음 새로운 spot을 실행한다는 것이였다.
예상
----->spot종료할꺼임!------>spot종료
----->새로운spot확보------->spot실행!(서버구동 중!)
실제..
------>spot종료
-------------->(새로운spot실행+서버올라가는 시간)---------------->실제 서버가 구동되는시점ㅠ


이미지를 새로 업데이트해 일자가 조금 다르다.😅
아래 이미지는 디스코드에 날아온 spot종료 알림이다.
아마 경고가 울리는 시점에 spot을 확보하고 spot이 종료된 후에 spot을 변경하는 작업이 이뤄지는 것 같다. 하지만 이 작업의 기간이 1분정도 소모될 뿐만 아니라 서버가 올라가는 시간까지 고려하면 3분 이상의 중단시간이 발생하는 문제가 있다는 것이다.
아마 1~2주동안 오류가 발생하지 않았던 이유는 정확하게 그 3분의 시간동안 요청이 들어오지 않았기 때문이라 생각한다....
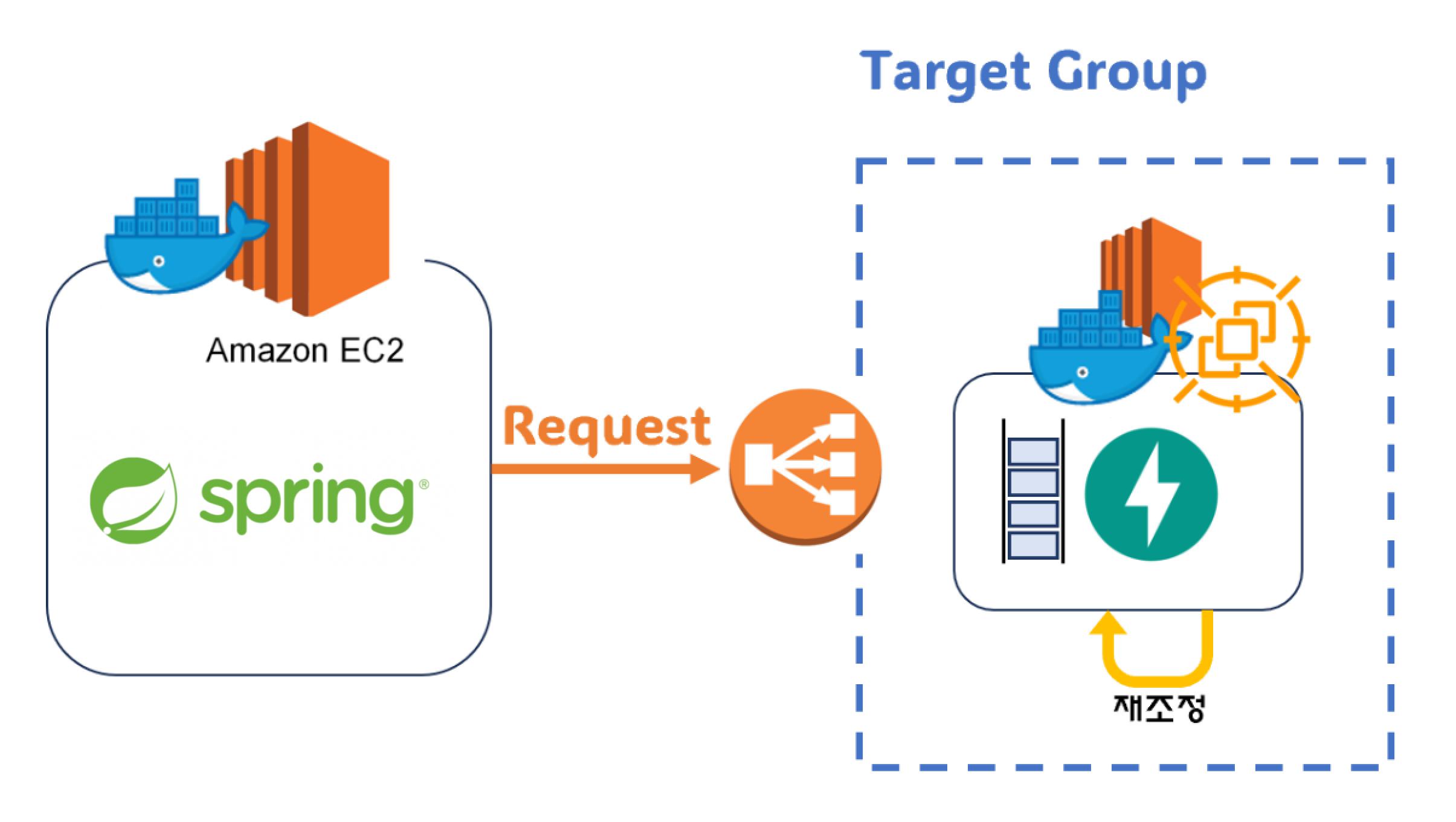
2차 시도. spot + ondemand + CloudWatch
spot에서 제공하는 용량 재조정은 서버 중단시간이 발생해 적합하지 않다는 사실을 알 수 있었다.
하지만 이전에 말했듯 spot은 종료되기 2분전 경고알림을 보낸다. 필자는 기존 용량 재조정 기능을 보안하기 위해 이 경고알림을 이용해 아래와 같은 방법으로 서버를 구성했다.
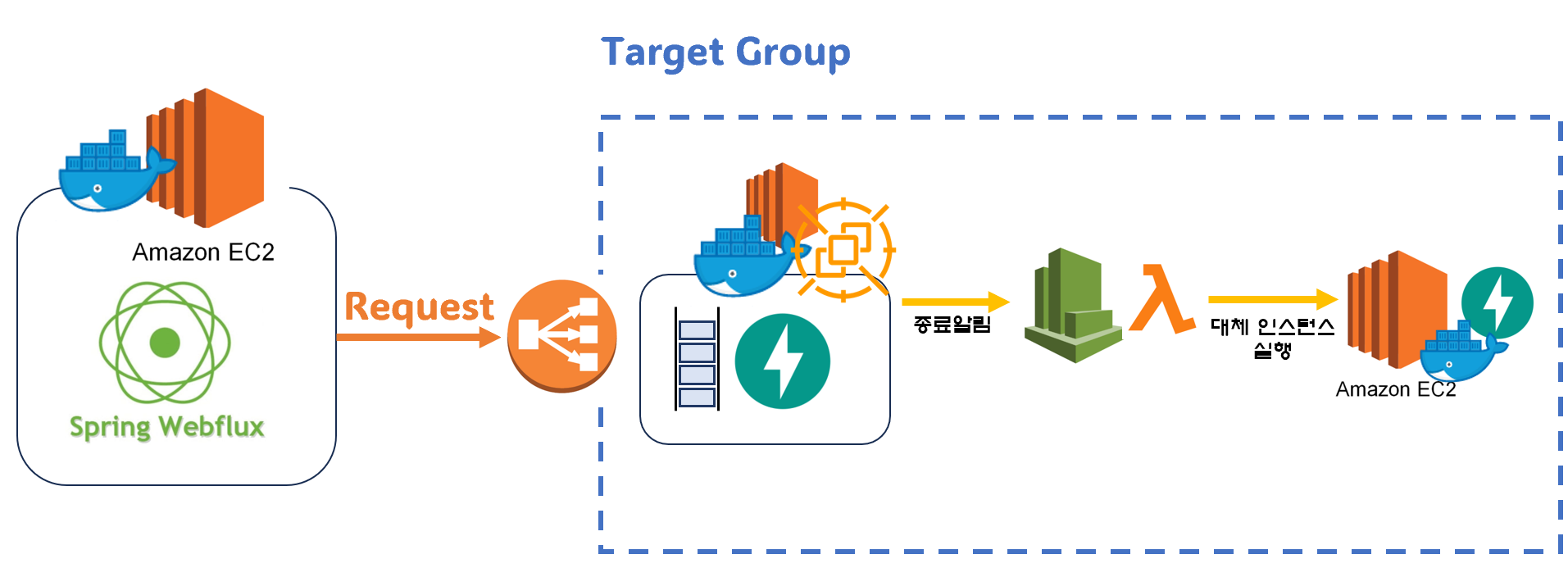
위와 같은 구조로 처리하기위해 CloudWatch로 알림 이벤트를 감지하고 lambda를 통해 다양한 처리를 진행했다.
내가 CloudWatch를 통해 처리할 이벤트는 대략적으로 2가지이다.
EC2 Spot Instance Request Fulfillment
EC2 Spot Instance Interruption Warning
서버중단시간 보완하기
이벤트를 감지하면 어떤 처리를 진행해야할까?
필자는 이 서버중단시간을 보완하기 위해 on-demand EC2를 다시 이용하기로했다.
on-demand ec2를 사용하지 않기위해 Spot을 사용했는데 다시 이 Spot을 보완하기 위해 on-demand를 사용하니 뭔가 이상하게 보일 수 있다.
필자가 on-demand 인스턴스를 사용하지 않았던 가장 큰 이유는 비용이였다.
하지만 99%의 시간은 spot을 사용하고 단 1%의 시간만 ondemand를 사용한다면 어떻게 될까?
ec2는 사용하는 시간에 비례하여 비용을 지불한다. 때문에 on-demand의 사용시간을 줄이면 줄일 수록 100% on-demand에 비해 훨씬 적은 금액으로 서버를 이용할 수 있다.
때문에 필자는 spot이 중단된 단 1%의 시간만 on-demand 인스턴스를 활용하려 한다.
On demand 인스턴스
먼저 기존 AI 서버와 똑같이 on-demand 인스턴스를 구축하고 이를 중지시켰다.
여기서 인스턴스를 중지하는 이유는 서버를 재구성하는 시간을 줄이기 위해서이다.
Spot은 종료되기 2분전 알림을 준다. 다시말하면 서버를 띄우고 요청이 처리가능한 상태로 만들어야하는 시간이 2분이라는 것이다.
하지만 필자가 구성한 AI서버는 굉장히 큰 용량의 AMI이미지를 구동해야한다. 때문에 서버를 새로 구성하기위한 시간이 길었고 2분내에 요청이 처리되지 않을 수도 있었다.
때문에 이를 대처하기위해 인스턴스를 중지시키고 실행하는 방법을 사용했다.
인스턴스를 중지하면 별도의 스냅샷이나 복원 작업 없이도 인스턴스의 이전 데이터를 그대로 사용할 수 있기 때문에, 새로운 인스턴스를 시작하는 것보다 초기화 및 설정 시간을 단축할 수 있다.
하지만 이전 데이터를 보관하고 있기에 해당 볼륨의 크기만큼의 비용을 지불해야한다. 하지만 적은 비용이기에 이를 선택했다.
lambda
이제 spot이 중단된다는 경고가 울리면 CloudWatch 이벤트가 발생하고 Lambda를 통해 중지된 인스턴스를 실행하면 된다.
아래와 같이 이벤트 규칙을 만들어주고
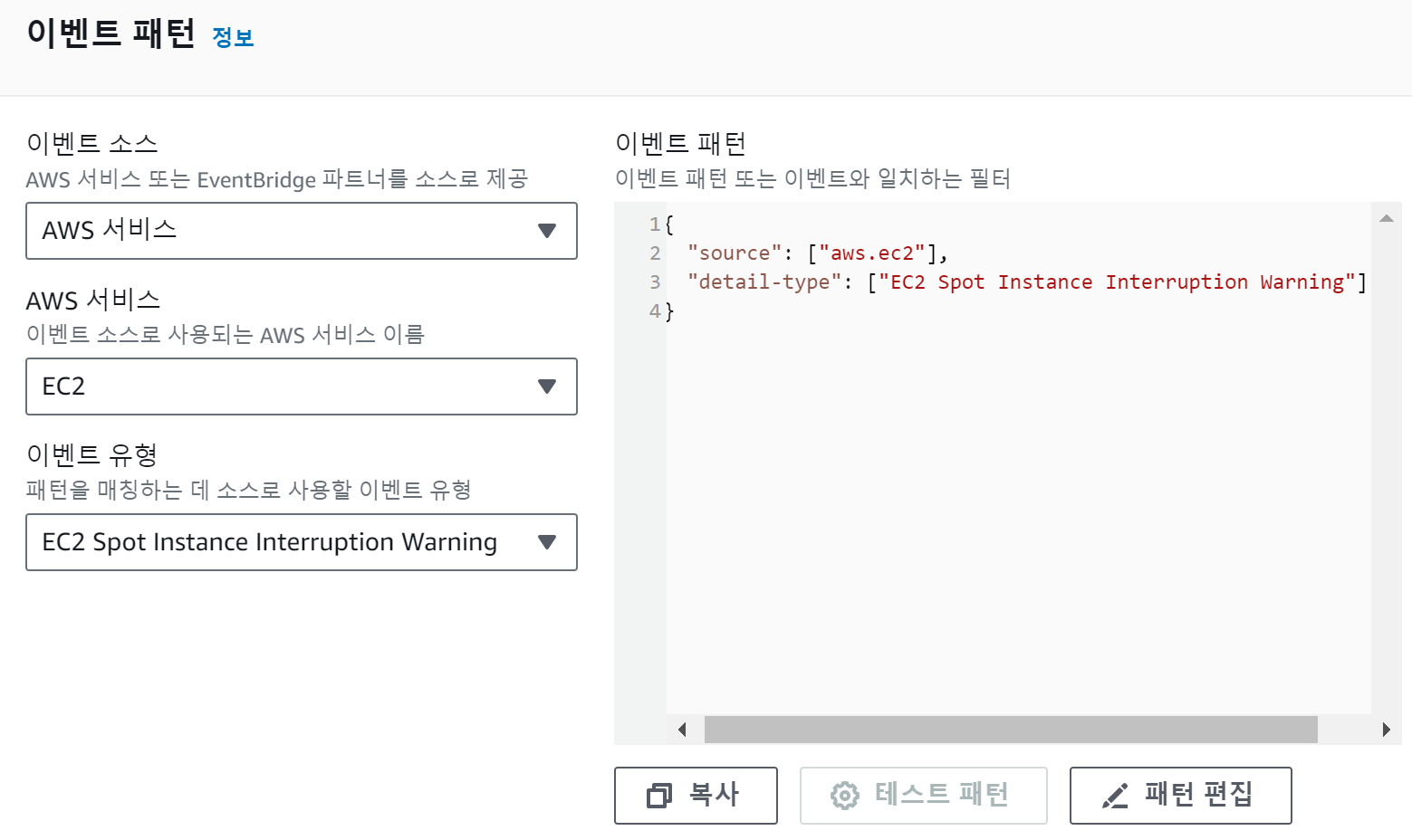
이벤트가 발생하면 lambda함수가 실행될 수 있도록 구성하였다.
EC2 Spot Instance Interruption Warning 이벤트 발생시
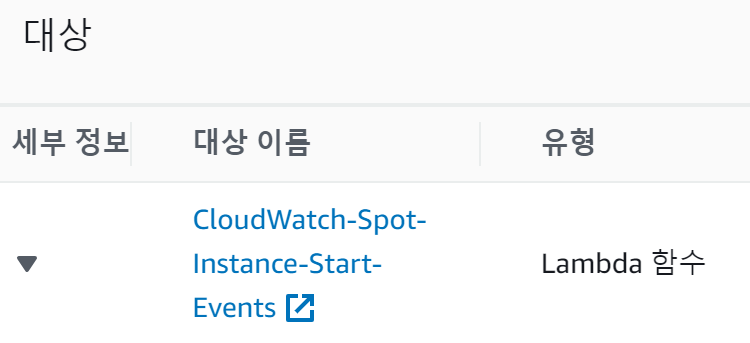
- 대체 인스턴스(on-demand)를 실행시키는 lambda 동작
EC2 Spot Instance Request Fulfillment 이벤트 발생시
- 대체 인스턴스를 종료시키는 lambda 동작
정리
전체 과정
1. spot 경고알림 발생
2. cloudWatch의 이벤트 패턴을 통해 이벤트 감지
3. 이벤트가 감지되었을때 경고알림 lambda 실행
4. lambda에서 대체 인스턴스(=on-demand) 실행 + 디스코드 알림
5. 새로운 spot을 확보했고 재조정 완료했다는 알림 발생
6. cloudWatch의 이벤트 패턴을 통해 이벤트 감지
7. 이벤트가 감지되었을때 완료알림 lambda 실행
8. 10분뒤 대체 인스턴스(=on-demand) 종료 + 디스코드 알림
위와같이 아키텍처를 구성했다. 물론 해당 아키텍처에서 발생할 수 있는 문제가 존재한다.
이 문제는 다음 글에서 알아보도록 하자.
여담
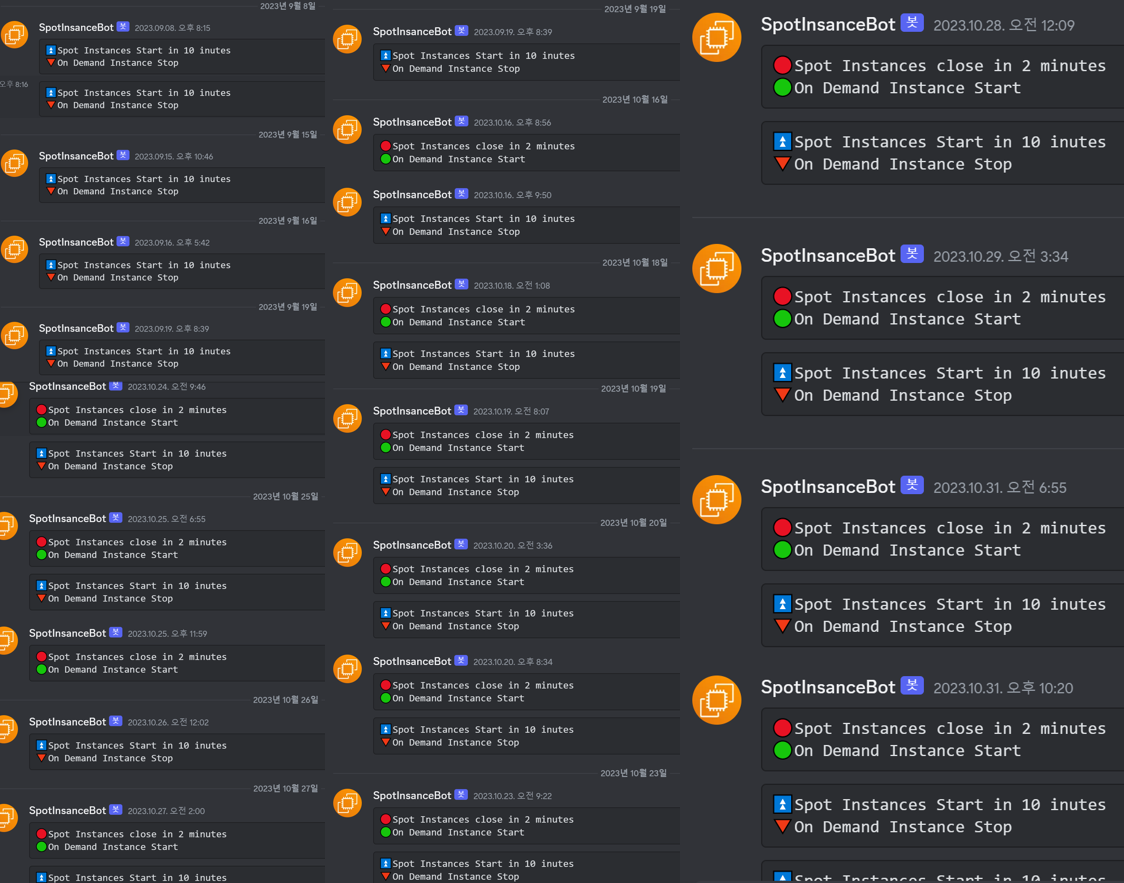
spot이 종료되거나 켜질때마다 디스코드 알림이 울릴 수 있도록 구성했었다.
처음 이 spot을 사용할땐 생각보다 종료되는일 별로 없어~ 라는 조언을 들었었다. 하지만 실제로 운영에 사용해보니 하루에 2번 종료된적도 있었고 아래와같이 정말 매일매일 알림처럼 하루에 한번은 꼭.. 종료되는 것을 확인할 수 있었다....💦

유익한 글 너무 잘 읽었습니다! 혹시 spot ec2 인스턴스 사양이랑 요금 얼마정도 나오셨는지 여쭤봐도 될까요?