AWS에서 GPU서버를 저렴하게 사용해보자 - 3(데이터 유실 방지를 위한 RabbitMQ 적용 + SocketException해결)
HairBe(헤어비) 개발,운영 기록

AI 서버의 요청 처리 과정에서 발생한 문제를 RabbitMQ를 도입하여 해결한 경험을 공유해보려 합니다.
왜 문제가 발생했는가..
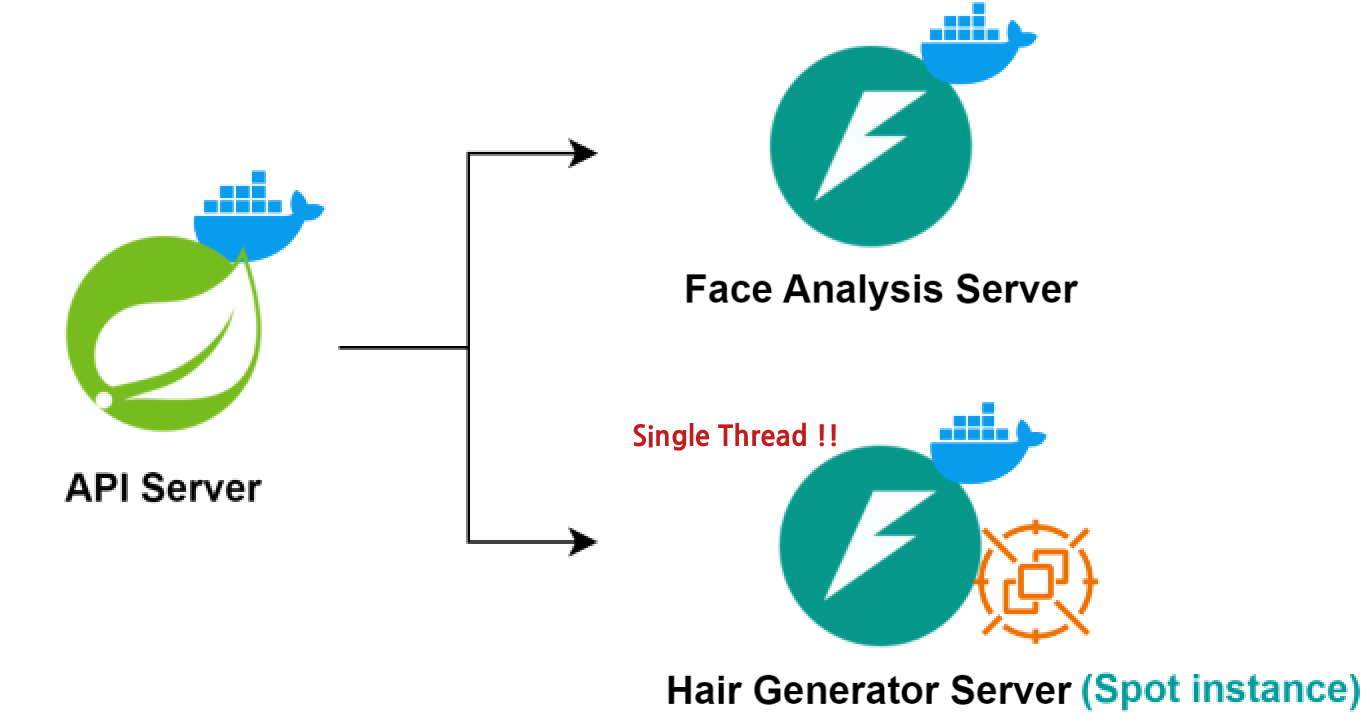
기존 AI서버의 구현
먼저 필자의 프로젝트에서 사용하는 stable diffusion은 다른 AI모델에 비해 무겁고 모델을 돌리기위해 요구하는 GPU의 성능이 매우 높다...
서버에 API를 한 번 보내면 GPU 사용률이 즉시 100%에 도달했고 GPU가 이미 최대 성능을 발휘하고 있기 때문에, 추가 요청이 들어오면 기존에 처리 중이던 요청의 처리속도가 저하되는 문제가 발생했다.
이를 해결하기위해 필자는 Lock을 걸었다. AI 서버에 하나의 요청만 처리되도록 단일스레드 형태로 서버를 구성하였다. 이렇게 구성해야 먼저 요청한 유저에게 빠르게 응답을 줄 수 있으니 말이다...
진짜 문제
하지만 필자의 AI 서버는 Spot 인스턴스로 운영되고 있다. Spot 인스턴스는 저렴한 비용으로 서버를 운영할 수 있는 장점이 있지만, 언제든지 중단될 수 있다. 이로 인해 서버가 중단되는 경우, 기존 서버의 작업 큐에 쌓여있는 데이터들이 소멸되는 문제가 발생한다.
실제로 이러한 문제가 발생했고 이를 해결하기 위해 AI 서버에서 스레드할당을 받지 못한 데이터를 가지고 있는 것이 아니라 다른 방법이 필요했다.
방법
1. 요청을 보내는 서버에 큐 구현 ❌
첫번째로 요청을 보관하는 큐를 API서버인 spring 서버로 옮기는 방법을 생각했다.
하지만 이 경우 좀 비효율적이라는 생각이 든다. 큐에 데이터를 쌓아놨다가 이전 요청이 완료되었다는 콜백요청이 오면 다시 API를 전송하는 형태가 될텐데 속도측면에서 비효율적이란 생각을 했다. 또한 엄청나게 많은 요청이 쌓이게 된다면 최악의 경우 spring 서버가 터질 수도 있다는 위험성도 있다.
2. 재시도 로직 구현 ❌
요청을 보내고 일정시간 이상 응답받지 못한다면, 데이터가 유실되었다 판단하고 재시도 로직을 구현하는 방법이다.
하지만 이 방법 또한 걸리는 부분이 존재한다. 대량의 요청이 있는 경우 재시도로 인한 부하가 서버의 성능에 영향을 줄 수 있기 때문이다.
더 나아가 분명 먼저 요청을 보냈지만 재시도 로직으로 인해 나중에 응답을 받는 일이 발생할 수 있다.
3. 외부에 요청데이터 보관 ✅
기존에는 AI서버의 큐에 요청데이터를 보관하고 하나씩 처리하는 방식이다.
Spring서버도 AI서버도 아닌 외부에서 요청을 보관하고 재시도 로직을 담당한다면 위에서 발생한 문제를 해결할 수 있을 것이다.
결론적으로..
전반적으로 생각해보았을 때 MessageQueue를 통해 대기열시스템을 도입하는 것이 좋겠다고 판단했다.
MessageQueue 란?
Message Queue는 비동기 통신을 위해 사용되는 중간 매개체이다.
Producer가 메시지를 큐에 넣으면, Consumer가 해당 큐에서 메시지를 가져와 처리한다.

MessageQueue는 시스템 간의 통신을 분리하여 서로 독립적으로 동작하고, 비동기적으로 통신할 수 있도록 해준다.
MessageQueue 장점
- 비동기
- 데이터 유실 방지
- 확장성
MessageQueue는 현재로서 딱 필요한것들을 가지고 있다. 때문에 이를 활용해 문제를 해결해보려한다.
RabbitMQ
필자는 다양한 메시지 큐 중에 RabbitMQ를 사용하기로 결정했다.
간단하게 대기열을 구현하기때문에 기능적인면에서 Amazon SQS를 사용해도 상관없지만 현재 필자의 AI서버는 단일스레드환경이다...... 때문에 조금이라도 빠르게 요청을 처리하고자 RabbitMQ를 사용했다. Kafka가 가장 빠르지만...너무 비싸다
추가적으로 RabbitMQ는 분산 메시징 시스템으로 설계되어 있어서 요구사항에 따라 확장이 가능하다. 만약 이후 요구사항이 추가됐을때 좀 더 용이하게 사용될 것같다.
적용 후의 서버
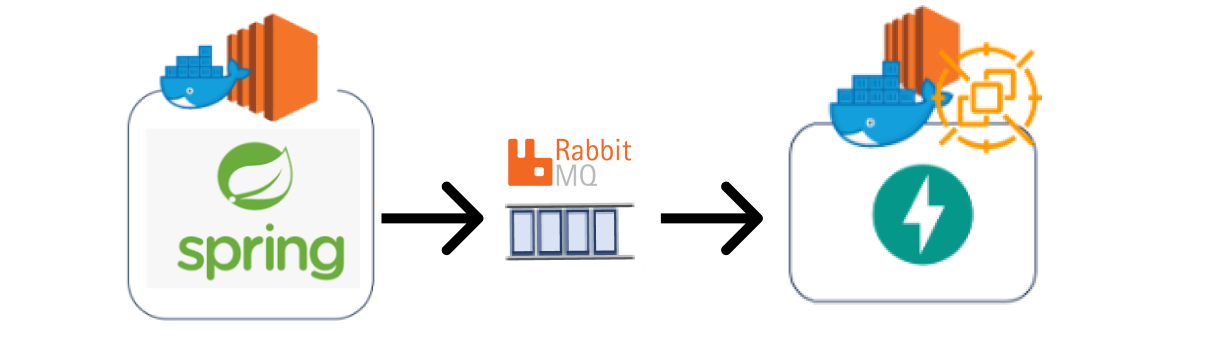
사실 해결방법은 간단했지만 문제를 파악하는 과정이 오래걸렸다....다행히도 RabbitMQ를 적용한 이후 데이터 유실이 발생하지 않았다..😂
