프로젝트를 시작하기에 앞서 준비 단계로
서울시 가게 데이터 50만 건 중 10만 건 이상의 데이터를 DB에 넣어야 했다.
DB에 데이터를 넣는 방법은 세가지 정도다.
-
DB툴을 이용하는 것
-
파이썬을 쓰는 것
-
자바를 이용해서 넣는 것
DB툴을 이용하는 방식은 쉬웠지만, 배포 DB로 보낼 때는 속도가 상당히 느렸다.
1000건의 데이터가 삽입되는 데 1분 정도가 걸렸다.
파이썬은 익숙하지 않아서 사용하지 않기로 했다.
남은 방식은 자바를 이용하는 것이다.
SQL을 단건 VS 벌크로
성능을 튜닝할 때는 주로 DB에 접근하는 횟수를 줄이는 식으로 한다.
쿼리를 모아서 한번에 보내는 식으로 말이다..
SQL 단건으로 전송
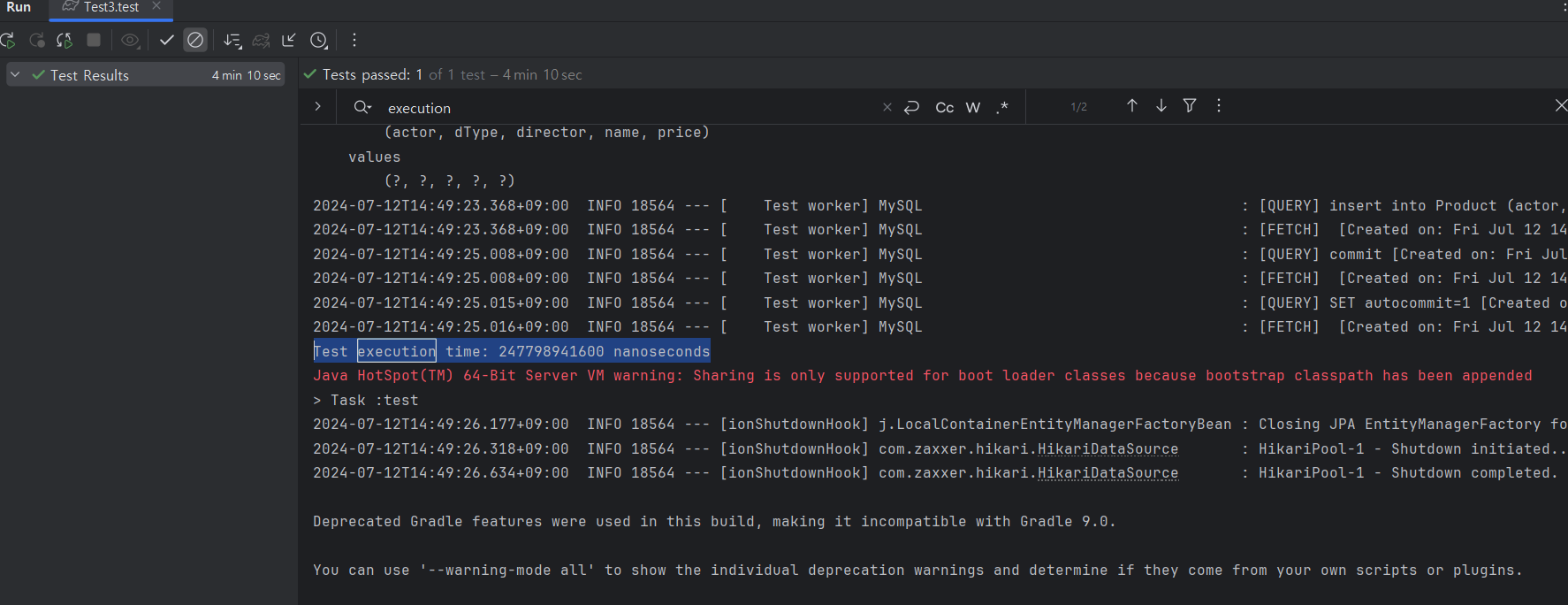
JPA의 saveAll() API를 사용했더니 INSERT 쿼리가 DB에 단건으로 전송됐다.
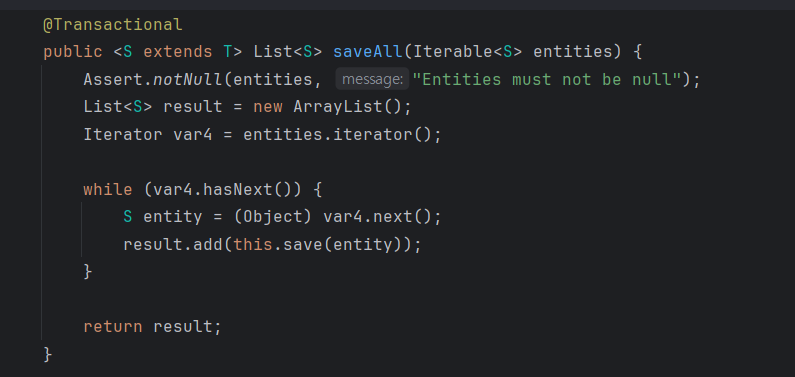
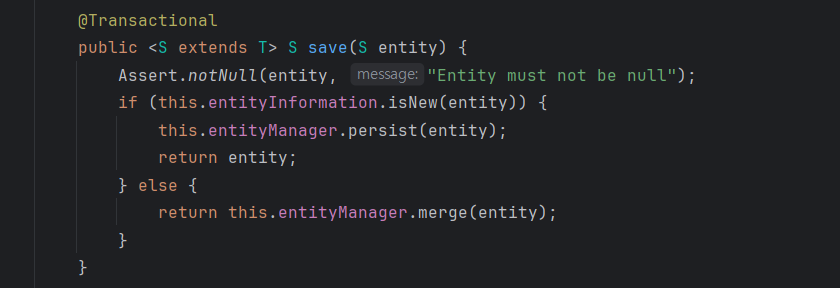
saveAll의 내부를 보면 결국 for문을 돌려서 하나씩 save하는 구조였다.
디버깅을 해봤다.
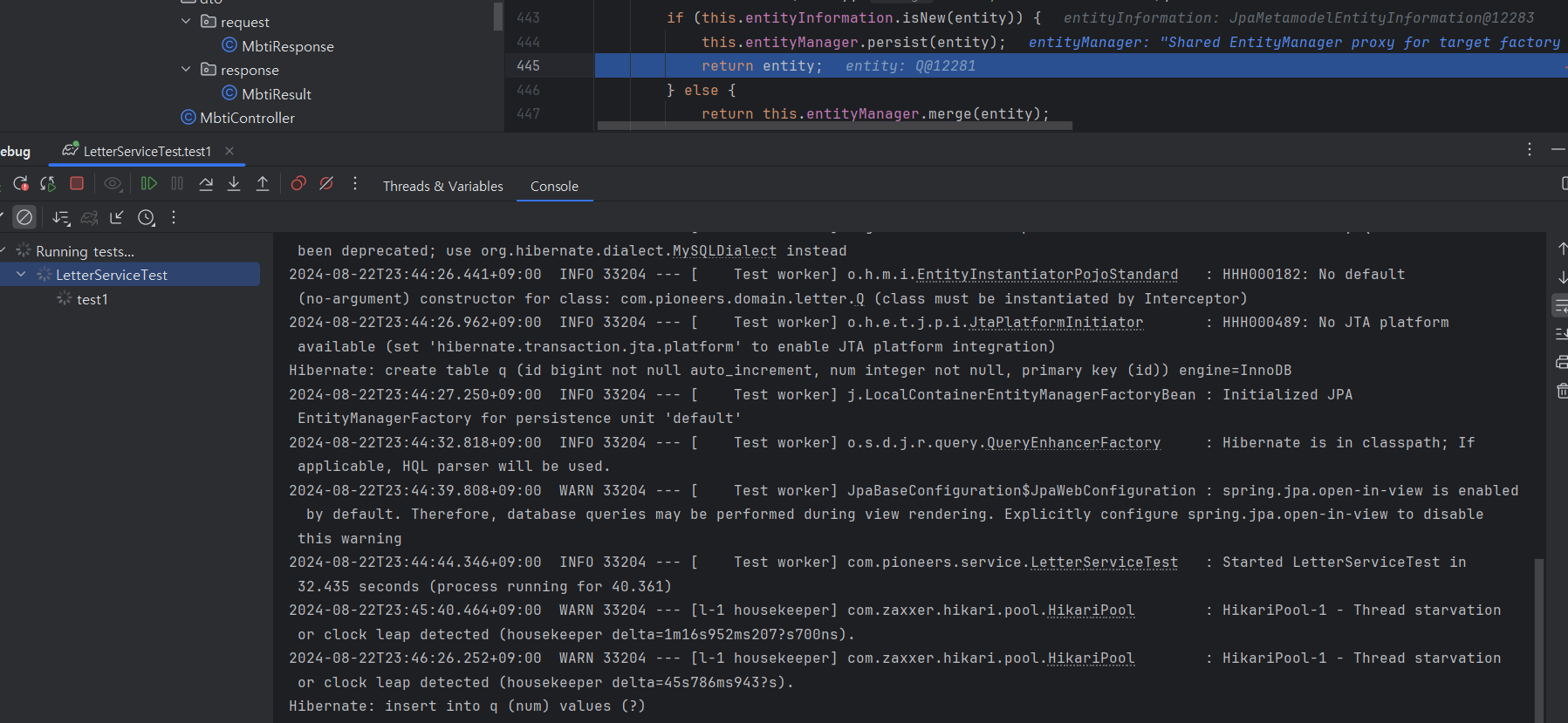
save메서드를 한번 돌때마다 쿼리가 DB로 전송되는 것을 확인할 수 있었다. 쿼리를 몰아서 보내지 않고 하나씩 간다는 게 특징이다.
로컬 DB에 10만 건을 INSERT 걸린 시간은 4분 정도다.
배포 DB에서는 더 많은 시간이 걸렸을 것으로 보인다.
spring batch를 활용
//단일 쿼리
INSERT INTO table1 (col1, col2) VALUES (val11, val12);
INSERT INTO table1 (col1, col2) VALUES (val21, val22);
INSERT INTO table1 (col1, col2) VALUES (val31, val32);
//벌크 INSERT 쿼리 ->쿼리를 하나로 묶어서 보낸다
INSERT INTO table1 (col1, col2) VALUES
(val11, val12),
(val21, val22),
(val31, val32);스프링배치와 MySQL의 연동문제는 MySQL에 Spring Batch 연동하기에 정리해두었다.
BulkInsert 방식을 쓰면 쿼리를 묶어서 보내기 때문에 그만큼 DB에 쿼리를 보내는 횟수가 줄어들게 된다. DB로 쿼리를 보내는 네트워크 전송 횟수 자체가 크게 줄어든다.
DB부하와 관련된 내용
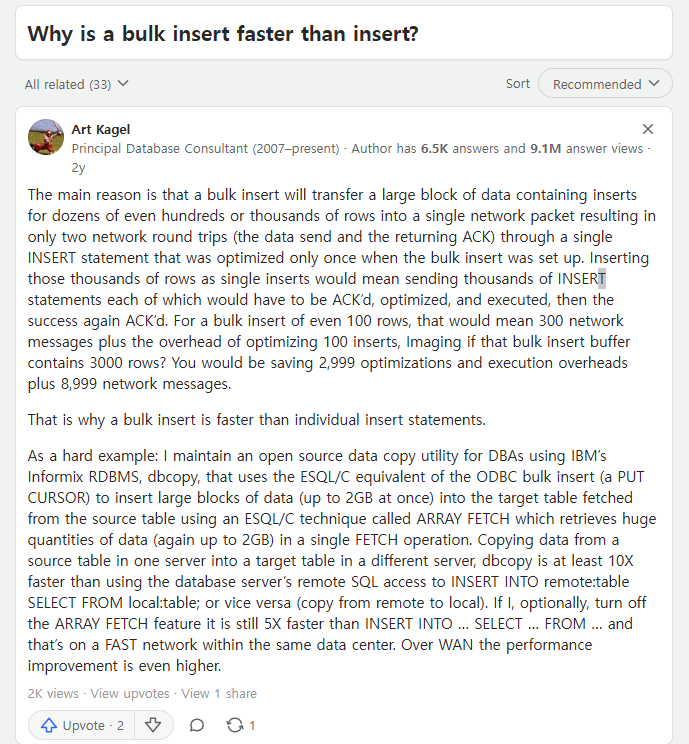
이 내용을 보니까 3000건의 쿼리를 단건으로 보내면 DB에서 이걸 3000번 쿼리를 파싱하고 최적화하고 실행해야 해야 하는데, 1번만 보내면 파싱,최적화, 실행도 한번으로 끝낼 수 있는 것으로 보인다.
참고: Individual inserts vs. Bulk inserts.
1)트랜잭션 오버헤드 감소 : 단건 쿼리들은 트랜잭션 안에서 처리되며, 이것들은 트랜잭션 관리에 따른 오버헤드를 증가시킨다. 벌크 쿼리는 트랜잭션 하나로 관리돼서 오버헤드를 줄인다.
2)locking과 관련된 오버헤드 감소: 여러 사용자가 동시에 데이터를 추가하거나 수정하면, 데이터가 충돌하지 않도록 잠금을 걸어야 한다. 개별삽입은 각 삽입마다 잠금이 필요해서, 여러 사용자가 동시에 작업하려고 하면 서로의 작업이 겹치면서 성능이 느려질 수 있다. 벌크 인서트를 하면 데이터베이스는 전체 테이블이나 특정 행들을 잠그는 경우가 많다. 이렇게 하면 한꺼번에 데이터를 처리할 수 있어 여러 사용자가 동시에 작업을 하더라도 성능 문제가 줄어들 수 있다.
3)로그와 인덱싱:데이터베이스는 데이터의 일관성을 유지하고 빠르게 검색할 수 있도록 로그와 인덱스를 관리한다. 개별삽입을 하면 데이터를 하나씩 넣을 때마다 로그와 인덱스도 하나씩 업데이트해야 하는데 시간이 많이 걸릴 수 있다. 많은 데이터를 한꺼번에 넣으면, 로그와 인덱스도 한 번에 업데이트된다. 이렇게 하면 전체 작업에 필요한 시간이 줄어들고, 더 효율적으로 데이터가 처리된다.
Bulk Insert 활용하기
Entity의 ID 생성전략이 INCREMENT로 설정하면 Hibernate가 JDBC 수준에서 batch insert를 비활성화한다. 그래서, JdbcTemplate의 batchUpdate를 직접 사용해야 한다.
@Repository
@RequiredArgsConstructor
public class Test2BatchRepository {
private final JdbcTemplate jdbcTemplate;
public void insert(List<Product> productList){
String itemSql = "INSERT INTO PRODUCT (DTYPE, name, price, actor, director) VALUES (?, ?, ?, ?, ?)";
jdbcTemplate.batchUpdate(itemSql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
Product product = productList.get(i);
ps.setString(1, product.getdType());
ps.setString(2, product.getName());
ps.setInt(3, product.getPrice());
ps.setString(4, product.getActor());
ps.setString(5, product.getDirector());
}
@Override
public int getBatchSize() {
return productList.size();
}
});
}
}
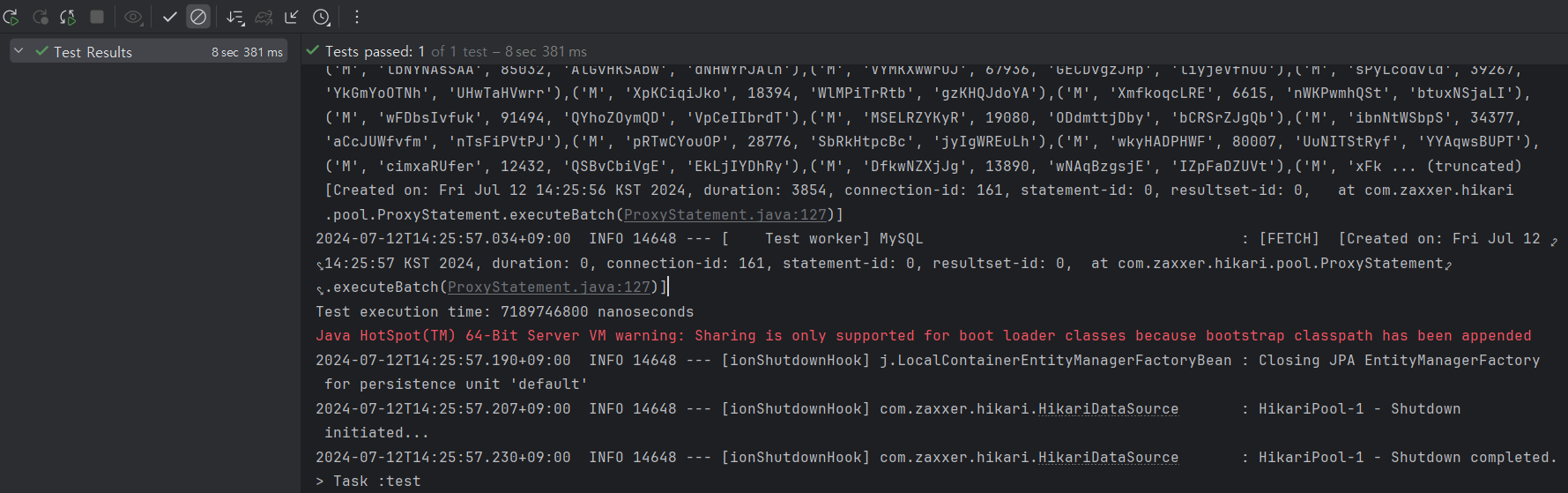
데이터 10만건을 로컬 DB에 넣을 때 7초 정도 걸렸다.
굉장히 빠르게 데이터를 넣었다.
단건으로 데이터를 넣을 때 걸린 시간인 4분과 비교하면 성능이 33배 향상됐다.
배포된 DB에서는?
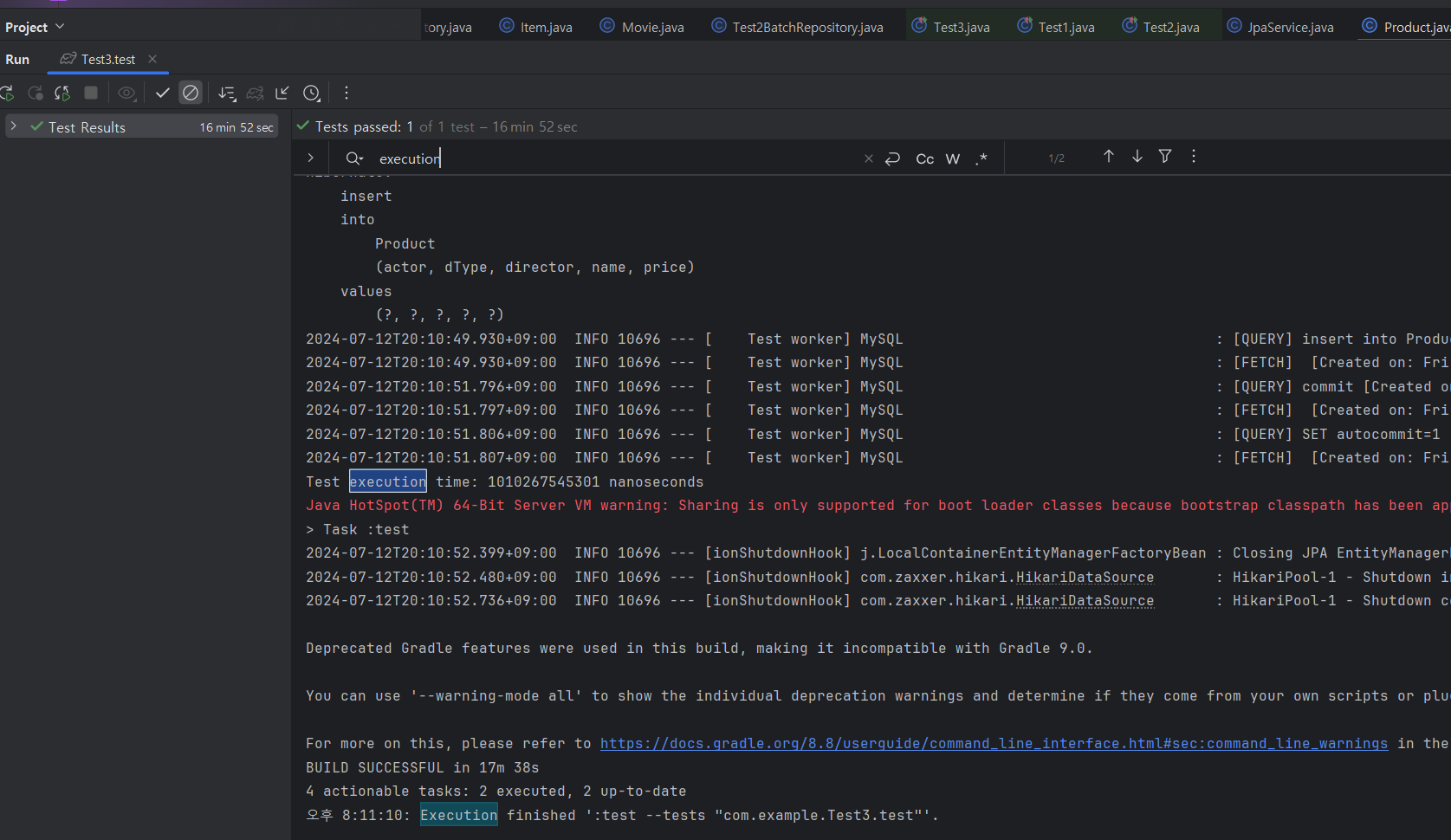
배포 서버에 있는 DB에 엔티티를 하나씩 INSERT할 때는 17분 정도 시간이 걸렸다.
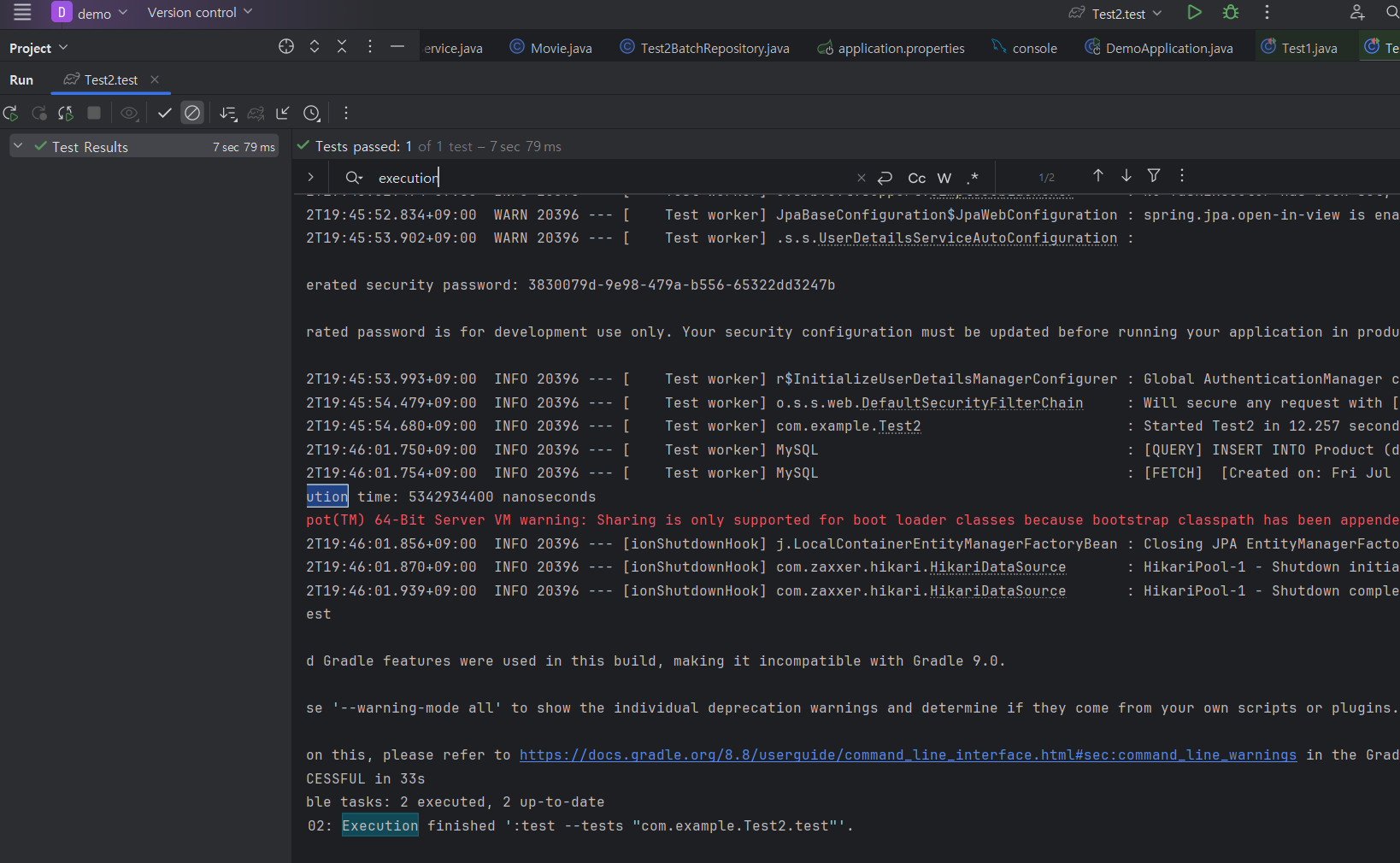
Bulk Insert를 활용하니 배포 서버의 DB에는 5초 만에 10만건의 데이터가 들어갔다.
거의 1000배에 가까운 성능 향상이 일어났다.
트러블 슈팅
1) db연결할 때 퍼블릭키를 가져오지 못한다는 내용이 나온다.
jdbc url에 allowPublicKeyRetrieval=true 추가
2)트러블 슈팅 -db에 테이블이 있는데 없다고 나옴
디비에서는 Product라고 돼 있는데 sql insert 구문에서는 PRODUCT라고 돼 있어서
