N+1를 해결하는 방법에 대해서는 알지만
이게 정확히 왜 발생하는지에 대해서는 원인을 명확히 파악하지 못했다.
한번 이를 정리해보자.
JPA N+1 발생원인과 해결 방법
[JPA] N+1 문제 원인 및 해결방법 알아보기
[Spring] JPA N+1 문제에 대한 고찰. (원인, 테스트, 해결방법)
이 내용들을 보면서 정리해보자.
JPA와 JPQL의 관계
JPA는 인터페이스 메소드 이름을 분석해서 JPQL로 변환하고, 이를 통해서 SQL을 실행한다.
- JPQL은 ava Persistence Query Language의 약자로, DB 테이블이 아니라 엔티티의 객체를 대상으로 검색하는 객체 지향 쿼리다.
(JPQL을 사용하기 전까지는 EntityManger의 find를 통해 Select를 했었는데,이러한 find 함수만 활용하기에는 조회가 복잡해지고 어려워질수록 사용하기가 까다로워진다고 한다)
JPA와 JPQL의 동작 특성 때문에 N+1이 발생한다.
fetch type과는 관련이 있어?
EAGER 로딩이면 JPQL에서 만든 SQL로 데이터를 조회한다. 이후 JPA에서 fetch 전략을 갖고서 해당 데이터의 연관 관계인 하위 엔티티들을 추가로 조회하는데 여기서 N+1이 발생한다.
LAZY 로딩이면 JPQL에서 만든 SQL을 통해 데이터를 조회한 뒤, 지연 로딩이기 때문에 추가 조회를 하지 않는다. 나중에 이 하위 엔티티를 갖고서 작업할 때 쿼리를 날린다.
결국, 포인트는 eager든 lazy든 데이터를 조회하는 구조상 연관관계를 select 쿼리 하나에 담아서 가져오는 게 불가능하다는 것이다. 이를 위해서 join 작업을 별도로 해주거나 batch로 한번에 가져와야 한다.
처음 나가는 JPQL 쿼리가 Join으로 연관관계들을 가져오지 않기 때문이다.
Fetch Join
JPAL에서 성능 개선 및 최적화를 위해서 제공하는 기능이다. 연관된 엔티니나 컬렉션을 함께 한번에 조회한다.
A "fetch" join allows associations or collections of values to be initialized along with their parent objects using a single select. This is particularly useful in the case of a collection. It effectively overrides the outer join and lazy declarations of the mapping file for associations and collections. (fetch join을 쓰면 연관관계까지 한번의 쿼리로 가져올 수 있다)
참고:하이버네이트 공식문서
연관관계를 매번 같이 사용할 때 fetch join을 쓰는 것으로 보인다.(Eager를 쓰더라도 n+1이 발생할 수 있으니, 아예 fetch join으로 join을 써서 한번에 다 가져오는 방식으로 이해했다)
다만, 이 방식은 카다시안 곱이 발생할 수 있다
(@OneToMany, @ManyToMany와 같은 연관관계에서 데이터가 중복 조회될 수 있다는 뜻.)
카다시안 곱이 뭔데?
카다시안 곱은 join을 할 때 두 테이블의 모든 데이터를 전부 결합한 경우의수가 결과값으로 반한되는 걸 말한다.
[Group 1: "개발팀"]
- User 1: "김철수"
- Post 1: "안녕하세요"
- Post 2: "반갑습니다"
- User 2: "이영희"
- Post 3: "좋은아침"
이걸 조인해서 가져와보자.
1. 개발팀 - 김철수 - 안녕하세요
2. 개발팀 - 김철수 - 반갑습니다 <- "개발팀"과 "김철수" 중복
3. 개발팀 - 이영희 - 좋은아침
[Group 1: "개발팀"]
- User 1: "김철수" (게시글 2개)
- User 2: "이영희" (게시글 3개)
[Group 2: "디자인팀"]
- User 2: "이영희" (게시글 3개) <- 이영희가 두 그룹에 속함
- User 3: "박지민" (게시글 2개)
이렇게 하면 더 복잡해진다.
1. 개발팀 - 김철수 - 게시글1
2. 개발팀 - 김철수 - 게시글2
3. 개발팀 - 이영희 - 게시글1
4. 개발팀 - 이영희 - 게시글2
5. 개발팀 - 이영희 - 게시글3
6. 디자인팀 - 이영희 - 게시글1 <- 이영희의 게시글 중복
7. 디자인팀 - 이영희 - 게시글2 <- 이영희의 게시글 중복
8. 디자인팀 - 이영희 - 게시글3 <- 이영희의 게시글 중복
9. 디자인팀 - 박지민 - 게시글1
10. 디자인팀 - 박지민 - 게시글2한 유저가 여러 게시글을 가지면 유저 정보가 중복된다.
Set을 사용하면 이런 중복된 데이터를 자동으로 제거해준다.
다만, 쿼리 실행 시에는 여전히 많은 데이터를 가져와야 한다.
Users Set: [김철수, 이영희] // 중복된 유저 정보는 하나로
Posts Set: [게시글1, 게시글2, 게시글3] // 중복된 게시글도 하나로Set은 순서를 보장하지 않기에 주로 LinkedHashSet을 사용하여 순서를 보장한다.
List를 쓰고 싶으면 Distinct를 통해서 중복을 제거하면 된다고 한다.
컬렉션이 두개라면?
Fetch join은 1:N 관계 컬렉션이 두 개 이상인 경우 사용 불가하다.
이때는 Batch 설정으로 한번에 가져올 수 있다.
이때는 Team을 한번 조회하고, 이에 대한 연관관계인 Member들을 sql in절로 모두 다 가져오는 방식을 쓰게 된다.
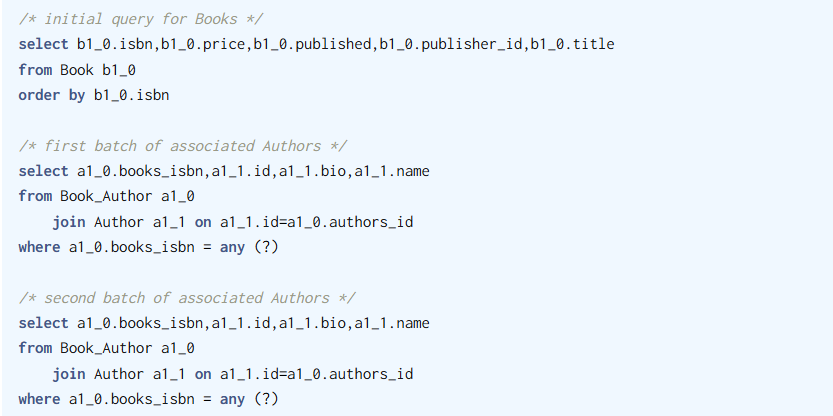
이런 느낌이다.
무슨 방법이 좋아?
공식문서에서는

batch보다는 fetch join을 쓰돼, fetch join을 쓰지 못하는 상황에서 batch 방식을 쓰면 된다고 한다.
Outer join fetching is usually the best way to fetch associations, and it’s what we use most of the time. Unfortunately, by its very nature, join fetching simply can’t be lazy. So to make use of join fetching, we must plan ahead. Our general advice is:
Join fetching, despite its non-lazy nature, is clearly more efficient than either batch or subselect fetching, and this is the source of our recommendation to avoid the use of lazy fetching.
There’s one interesting case where join fetching becomes inefficient: when we fetch two many-valued associations in parallel. Imagine we wanted to fetch both Author.books and Author.royaltyStatements in some unit of work. Joining both collections in a single query would result in a cartesian product of tables, and a large SQL result set. Subselect fetching comes to the rescue here, allowing us to fetch books using a join, and royaltyStatements using a single subsequent select.
Outer join Fetching이 제일 좋은 방식이지만, 이 방식은 lazy가 안 된다고 한다.
LAZY 로딩을 기본으로 사용하되, 필요한 곳에 fetch join을 사용하여 EAGER하게 데이터를 가져오면 된다고 한다.
subselect fetch와 batch size 방식은 lazy하게 가져올 수 있다는 것이 공통점이다.
