CS를 공부하자
1.N+1은 왜 발생할까?
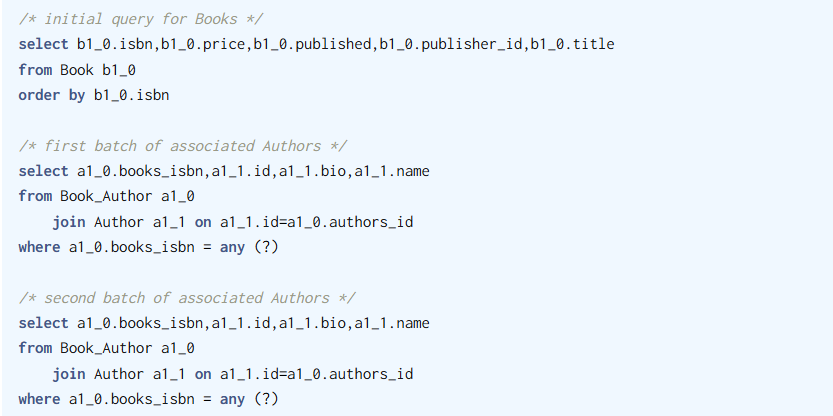
N+1를 해결하는 방법에 대해서는 알지만이게 정확히 왜 발생하는지에 대해서는 원인을 명확히 파악하지 못했다.한번 이를 정리해보자.JPA N+1 발생원인과 해결 방법\[JPA] N+1 문제 원인 및 해결방법 알아보기\[Spring] JPA N+1 문제에 대한 고찰. (원
2.연관관계 Collection은 SET이 좋을까 List가 좋을까?

우선, List와 Set의 차이를 생각해보자List는 순서가 보장되고 Set은 중복을 제거한다.영한샘은 우선 Set을 쓰면 지연 로딩 때 성능 이슈가 있다고 하셨다. 개념적으로, 지연로딩은 필요할 때 데이터를 조회한다. 그런데, Set 특성상 컬렉션에 데이터를 추가할
3.공간 인덱스란?

공간 데이터도 조회 성능 향상을 위해 인덱스를 사용할 수 있다. MySQL의 공간 인덱스는 MBR의 포함관계를 바탕으로 트리 구조를 생성하여 이용한다. MBR(Minimum Bounding Rectangle)의 약어로 최소 경계 사각형을 의미한다. 각각의 물체들을 최소
4.DB commit과 flush는 다르다.
테스트 코드를 작성하다보면 commit을 하고 아예 새로운 트랜잭션을 시작해야 할 때가 있다. 이런 경우는 롤백이 되지 않으므로 내가 알아서 지워줘야 한다.EntityManager로 flush()할 때는 자동으로 롤백이 됐는데커밋한 건 롤백이 안 된다. 어떤 차이가 있
5.TCP/IP란
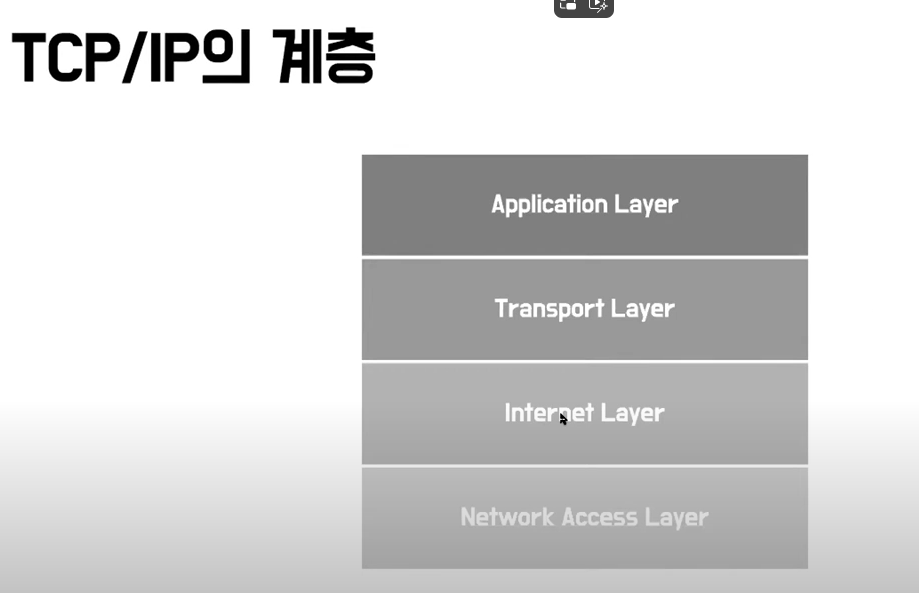
\[10분 테코톡] 🔮 수리의 TCP/IPTCP/IP는 인터넷에서 컴퓨터들이 서로 정보를 주고받는데 쓰이는 프로토콜의 집합이다.어플리케이션 레이어는 특정 서비스를 제공하기 위해 애플리케이션끼리 정보를 주고 받을 수 있따. FTP, HTTP, SSH, Telnet, S
6.프로세스 VS 스레드
\[10분 테코톡] 🌷 코다의 Process vs Thread프로그램과 프로세스프로그램을 실행시키기 전에 단순히 실행 코드일뿐이다. 이걸 실행시키면 프로세스가 된다.이때 필요한 내용들이 메모리에 올라간다.해당 프로세스에 대한 정보를 담고 있는 PCB블럭도 생성된다.사
7.CS 스터디 -네트워크 1편
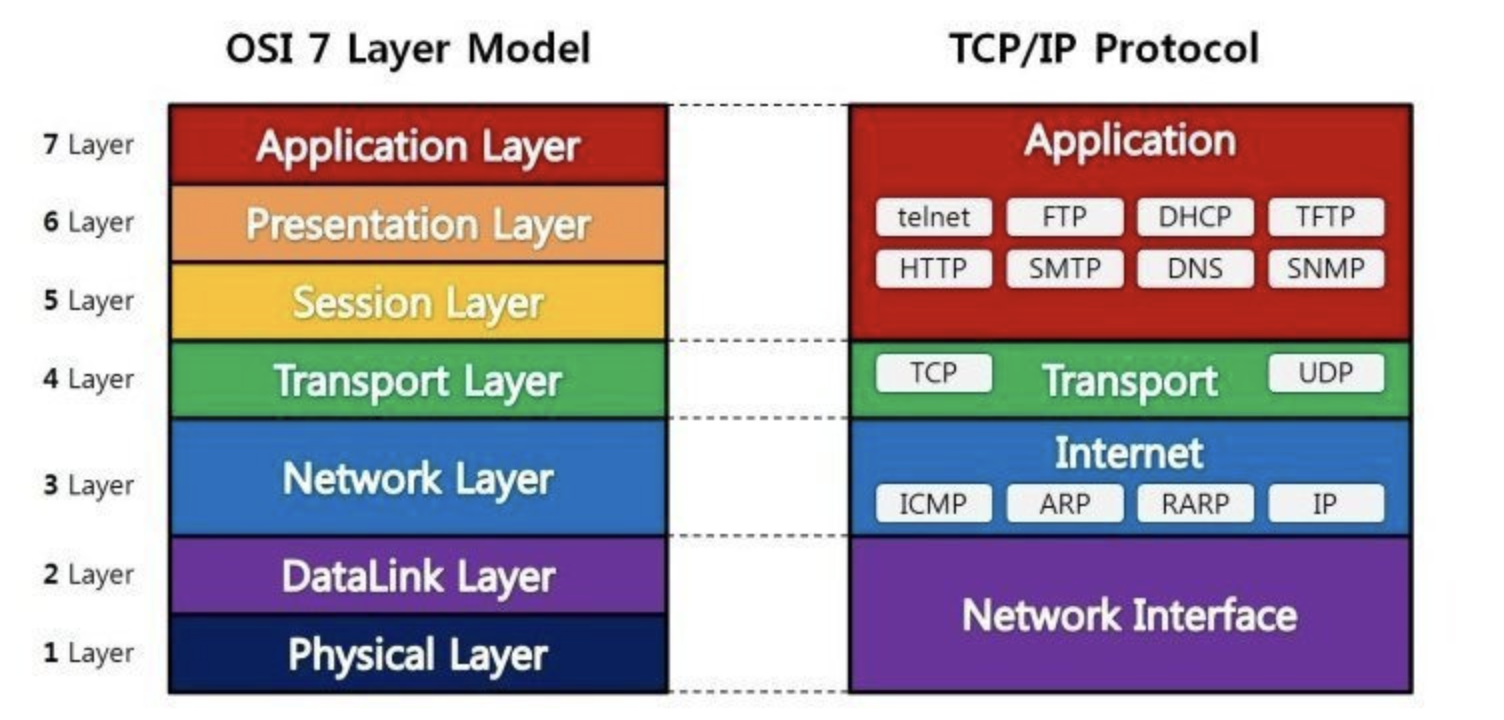
네트워크란 '둘 이상의 컴퓨터와 이들을 연결하는 링크 조합'이다. 단말기 간 통신을 위한 연결다리라고 생각하면 된다. 연결은 네트워크 통신을 위해선 유선/무선 연결이 필요하다. 가까운 거리는 무선으로 연결해도 속도가 괜찮지만, 국가 단위의 연결은 아직 유선 케이블을 주
8.웹 브라우저에 URL 입력하면 일어나는 일 - 인프라 위주
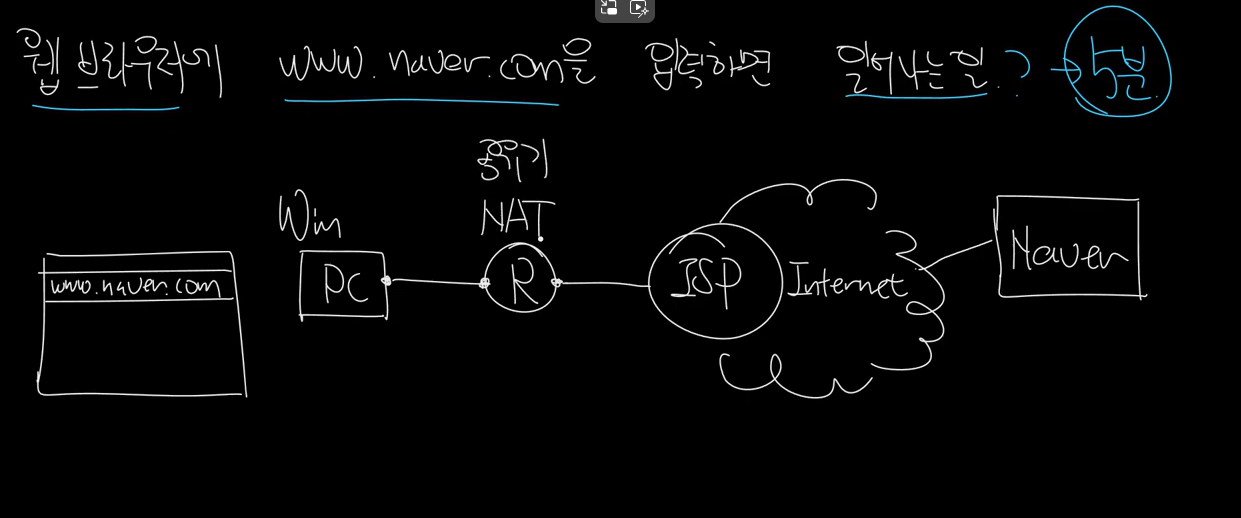
출처 :https://www.youtube.com/watch?v=GAyZ_QgYYYo우선 PC 브라우저에 주소를 입력한다.주소는 URL(위치지정자)과 URI가 있다PC 운영체제가 host 파일을 확인한다. DNS 응답을 캐싱한 걸 화확인한다. 그리고 없으면 질
9.HTTPS의 원리를 공부해보자
HTTP는 인터넷에서 데이터를 주고받는 통신 프로토콜이다. 여기에 보안 기능을 강화한 것 프로토콜이 HTTPS이다.imageHTTP는 원래 보안을 염두에 두지 않고 설계된 프로토콜이라, 모든 요청이 평문(일반 문자열)이다. 그래서 보안에 매우 취약하다. 특히 스니핑과
10.HTTPS는 HTTP보다 느릴까?

막연하게 암호화헤 따른 비용 때문에 HTTPS가 더 느릴 것이라고 생각했다.하지만 이번에 스터디를 하면서 새로운 내용을 배우게 돼서 공유한다.참고자료 : HTTPS는 HTTP보다 빠르다지난 2010년 이후로 HTTPS 암호화에 쓰이는 TLS는 크게 변하지 않았지만, 클
11.서브넷과 CIDR이란?
IPv4 초기엔 IP 주소가 부족하기 때문에 IP 클래스를 나누어 할당하는 방법을 택했다.하지만, 이건 비효율적었다.한 중소기업이 클래스 B를 쓰는데 65000개의 IP를 다 쓰는 게 아니고 1만개만 쓴다고 해보자.5만개의 IP를 쓰지 않는 것이다. 그렇다고, C클래스
12.JWT 토큰과 CSRF 공격
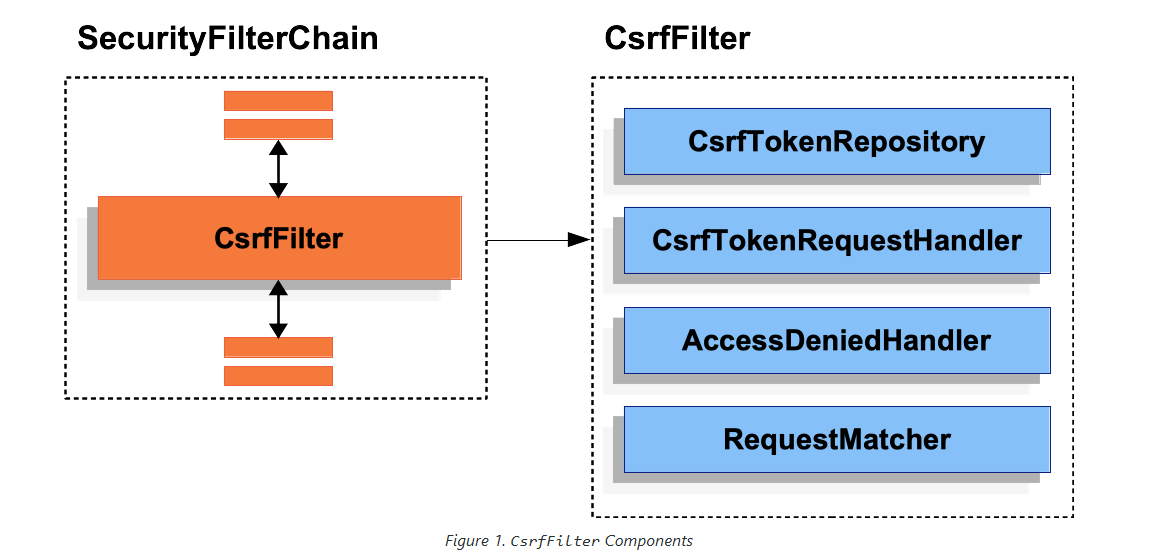
매번 스프링 시큐리티-JWT를 사용할 때 CSFR를 막는 설정을 disable을 했다. 강의에서 그렇게 해도 된다고 했다.CSRF가 뭔지 정확하게 모르겠어서 내용을 조사해봤다.우선, CSRF(Cross Site Request Forgery)는 공격자가 이용자 권한을 도
13.CS 스터디 -네트워크 2편

인터넷은 애플리케이션 게층에 트랜스포크 계층 프로토콜을 제공한다. TCP와 UDP는TCP는 신뢰적이고 연결지향적인 서비스를 요청한 애플리케이션에 제공된다.UDP는 비신뢰적이고 비연결형이 서비스를 요청한 애플리케이션에 제공된다.TCP가 필요한 이유는? IP 때문이다인터넷
14.JWT란 무엇일까?
보통 서버가 클라이언트 인증을 확인하는 방식은 쿠키,세션,토큰 세가지가 있다. 각 인증방식을 먼저 알아보자 쿠키란? 쿠키는 Key-value형태의 문자열 덩어리다. 클라이언트가 웹사이트를 방문하면, 그 사이트가 사용하는 서버를 통해 클라이언트의 브라우저에 설치되는 작은 기록 정보 파일이다. 각 사용자마다 브라우저에 정보를 저장하니 고유 정보 식별이 가능...
15.JWT를 꼭 사용해야할까?
JWT란 무엇일까?에서 인증 방식을 정리했다.여기선 JWT를 왜 써야할지 조사한 내용을 다루겠다.우선, 세션 방식과 비교해보자.세션은 DB이든 인메모리 저장소이든 이 정보를 저장해야 한다.DB에 저장하면 매번 세션 정보를 확인할 때 DB 조회를 해야하니 DB 부하가 커
16.스프링 시큐리티가 꼭 필요할까?
이 글을 통해서 스프링 시큐리티에 대한 생각을 좀 정리해보고자 한다. 우선, 이 글을 쓰게 된건 Spring Security 그렇게 쓰지 마세요! 라는 글을 보게 됐기 때문이다. 골자는 스프링 시큐리티를 정말 필요해서 쓰는 게 맞냐는것이다. 나는 스프링 시큐리티를
17.소켓에 대해 알아보자
소켓은 네트워크상에서 데이터를 주고받을 때 사용하는 엔드포인트이다.TCP/IP 4계층에서 전송 계층에 놓인다.소켓이 연결되면 중간에 파이프 같은 것이 생성되고, 이를 통해서 데이터를 주고받게 된다.서버들이 데이터를 주고받이 위해서 주요한 것은 이 소켓을 먼저 만드는 것
18.Spring Batch에 대한 정리
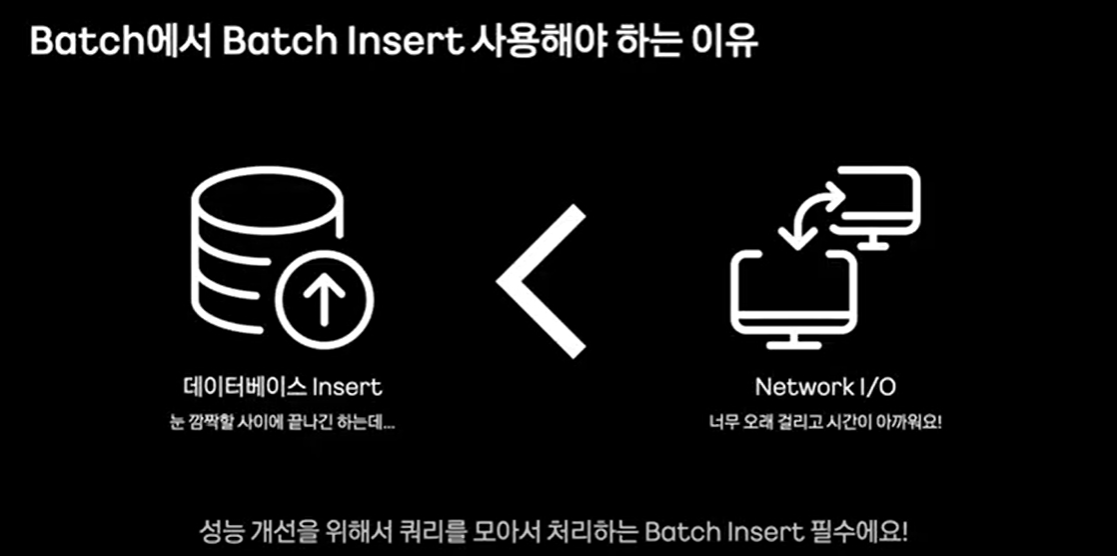
스프링 배치에서 더티체킹을 사용하는 것은 비효율적일 수 있다.영속성 컨텍스트에서 엔티티의 스냅샷을 추적하면서 변경 사항을 확인해야 하기 때문이다.데이터를 조회할 때부터 더티체킹을 포기하는 게 좋다고 한다.아예 dto로 가져오는 것도 좋은 방법이다.주로 대량의 데이터를
19.스프링 예외처리에 대해서 알아보자
여러 문서들을 참고해서 예외 처리 방법을 확인해보자위의 스펙은 아래와 같은 정보를 담고 있다.HTTP 응답 상태코드구체적인 예외 사유외의 추가할 메시지Error Handling for REST with Spring 여기서는 핸들링을 하는 방법들이 나온다.이 방법은 특정
20.예외처리 Best Practice에 대해서 알아보자
이를 사용하면, 전역적으로 예외를 가로채서 처리할 수 있다.명확한 메시지를 보내서, 예외의 원인을 정확하게 알려주는 게 좋다. 그래야 디버깅이 용이하다. 이걸 보면, 예외를 가장 추상화가 높은 단계인 서비스단에서 한다. 그리고, 가장 낮은 단계인 글로벌 예외 핸들러에서
21.REST한 API란 무엇일까? SOAP 프로토콜과 비교해보자
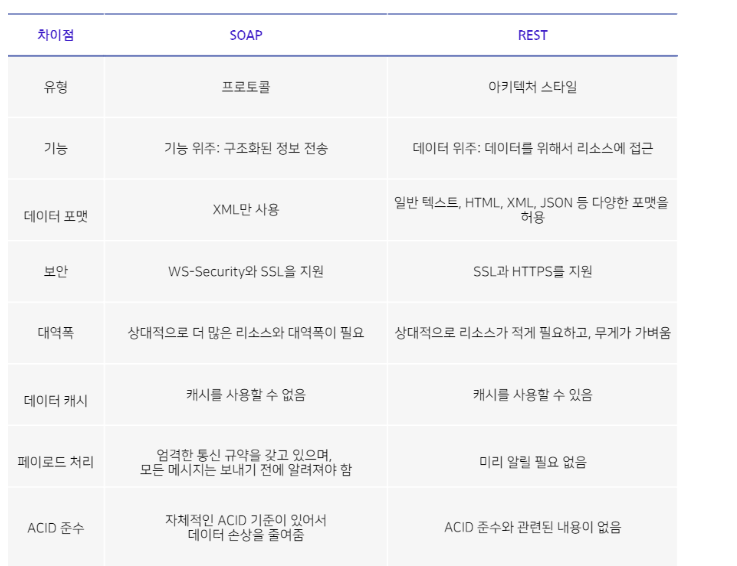
API 개발에만 신경을 쓰다보니 문서화에 너무 소홀했다.이제 클라이언트 개발자들이 API연결을 하는데URL이 너무 REST한 느낌이 아닌 거 같아서(사실 REST한 느낌이 뭐지 모르겠다)한번 조사를 해보고 적용해보기로 했다.Rest에 있어서 중요한 것은 "언어에 독립적
22.메모리에 대해 알아보자(스프링은 메모리를 어떻게 최적화할까?)
JVM은 메모리를 크게heap 메모리와 non-heap memory 두개의 카테고리로 분류한다. heap 메모리는 애플리케이션에서 생성되는 객체들이 보관되는 곳이다. 이 객체들은 더는 다른 곳에서 참조되지 않을 때 가비지 컬렉터에 의해서 회수된다.그래서, heap 메모
23.DB Rollback이 DB 성능에 영향을줄까?
이번에 클라이언트 개발자분과 프로필 업데이트와 사진 업데이트, 프로필 등록과 사진 등록 API를 분리하지말고 하나로 합쳐야할지를 정하면서 Rollback의 범위가 길어지는 게 문제가 될지? 의문이 생겼다. 프로필과 사진 각각 비즈니스 로직이 복잡하다보니 유효성 검사
24.MVCC(Multi-Version Concurrency Control)란?
InnoDB는 각각의 레코드의 여러 버전(수정되기 전 버전들과 수정된 후의 버전)을 언두 로그 형태로 갖고 있는다. 클라이언트는 트랜잭션 동안에는 트랜잭션 시작 전에 커밋된 레코드, 그리고 그 이후의 변경된 버전만 보게 된다.(그 트랜잭션 내에서)트랜잭션 레벨은 4가지
25.트랜잭션이 길어지는 게 성능에 영향을 줄까?
데이터베이스와 한번 이상의 상호작용을 해야 한다고 해보자. 또한, 일련의 작업이 성공하거나 아니면 아예 하나라도 실패 시 모든 변화 내용이 사라지는(all or noting) 방식으로 변경되길 원한다고 해보자.이런 경우에 우리는 DB 트랜잭션을 활용한다. 트랜잭션은 작
26.AWS Certificate Manager vs Let's Encrypt
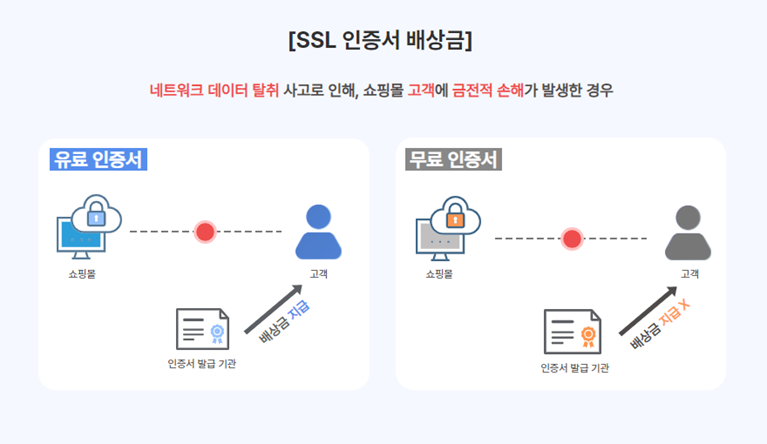
평소에는 Let's Encrypt를 사용해서 https를 적용했다.그러다 이 두개에는 무슨 차이가 있는건지 궁금했는데 이번 기회에 정리한다.참고자료를 보면이 두개는 SSL/TLS를 관리하는 대표적인 툴이다. 주로 서비스가 소규모라면 1대의 서버에 Nginx를 설치하고
27.HTTPS+NGINX 흐름에 대해 정리해보자

매번 정해진 대로 하다 보니까 각각의 과정에서 개념들이 어떻게 쓰이는지 잘 모르겠다. NS레코드란? AWS에서 Route53으로 호스팅 영역을 만들 때 NS레코드를 매번 만드든다. NS서버는 이름 서버로, NS 레코드는 인터넷에서 해당 도메인의 IP주소를 갖치 위
28.리버스 프록시란?
ip차단을 계속 해도 끊임없이 차단이 되면서아직 제대로 릴리즈도 안한 서버에서만 약 300개 이상의 ip가 차단됐다.이게 정상인가?.. 싶던 차에 서치를 해보니위와 같은 글이 나왔다.우선, 이렇게 차단이 되는 거를 크게 신경쓸 필요가 없다고 하는데 그 이유는라고 한다.
29.Apach와 Nginx를 비교해보자

아파치는 NGIINX와 마찬가지로 가장 성공적인 오픈소스 웹 서버 중 하나다. 아파치가 성공할 수 있는 핵심 요인은 아키텍처 모델의 간결함이었다고 한다. 당시에는 많은 네트워크 서비스가 inetd라는 마스터 서비스에서 트리거 됐는데, 새로운 네트워크 연결(TCP)가 수
30.커넥션 풀 사이즈는 클수록 좋을까?
JPA-MySQL을 쓰면서 HiKariCP 설정을하게 된다.HiKariCP는 데이터베이스 연결(Connection)을 관리해 주는 라이브러리다.여기서 커넥션 풀의 숫자를 설정할 수 있다.커넥션 풀의 원리는커넥션을 미리 풀에 만들어놓고, 필요할 때마다 가져가서 쓰는 방
31.JWT 토큰을 URL에 넣어도 될까?
이번에 ADMOB을 연결하면서 서버에서 SSV라고 이용자가 실제로 광고를 봤는지 검증을 하는 과정이 필요했다.그래서, 구글에서 제공하는 규격을 따르는 URL 콜백을 만들게 됐는데이때 GET메서드이면서 헤더를 쓸 수 없다는 문제가 생겼다.즉, JWT 토큰을 헤더로 받을
32.CORS란 무엇일까?
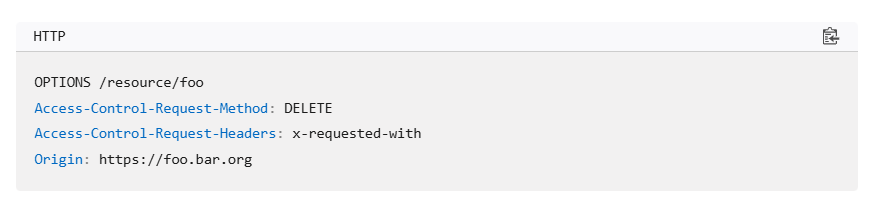
CORS에 대해서 제대로 정리를 해보자.기본적으로 웹사이트 a는 웹사이트 b의 데이터를 가져오지 못한다. 그게 바로 Same-origin-policy라는 규칙이다. 웹 사이트 B가 '웹사이트 A는 내 데이터를 가져갈수 있다'고 허용할 수 있는데, 이걸 CORS(Cros
33.@Mock 테스트에 대해서 정리해보자

Mock을 만들 때는 세가지 방법을 쓸 수 있다.이 Mockito는 무슨 라이브러리일까?Mockito is a mocking framework for Java. Mockito allows convenient creation of substitutes of real ob
34.해시충돌이란?
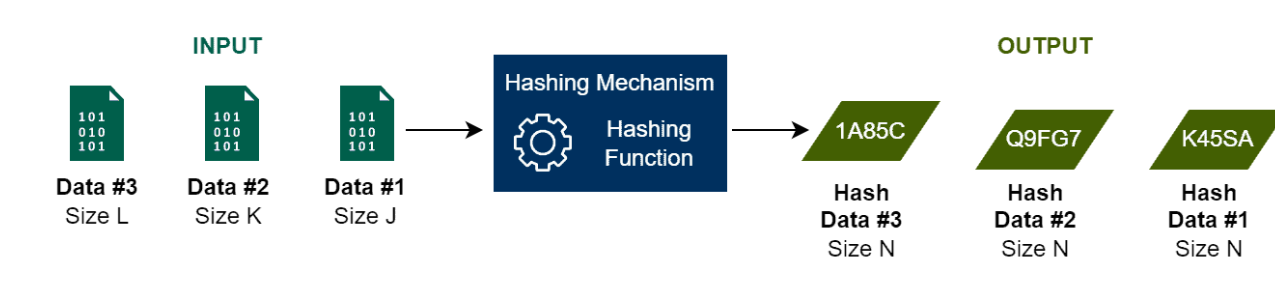
해시 자료구조는 키-값 쌍으로 이루어진 데이터 구조로, 키를 사용해서 O(1) 시간복잡도로 값을 구할 수 있다. 이때 해시 자료구조는 키를 해시 함수에 넣어서 나오는 결과를 기반으로 값을 관리한다.해시충돌은, 다른 키를 사용해서 해시 함수를 돌렸을 때 같은 결과가 나오
35.HTTP/1.1-> HTTP/2.0 -> HTTP/3.0에 대해서 알아보자
HTTP/1.0 HTTP/1.0은 한 개의 요청과 응답마다 TCP 커넥션을 생성하여 사용했다. 이 방식은 매 요청마다 연결을 생성하는 오버헤드가 발생한다. HTTP/1.1 HTTP/1.1은 HTTP/1.0의 여러 불편함을 해결하는 것을 목표로 했다 대표적으로 HTTP/1.0 설계에서 미쳐 고려되지 못한 부분(계층적 프록시, 캐싱, 연결 지속)을 보...
36.grpc는 HTTP/2의 비효율성을 어떻게 해결할까?
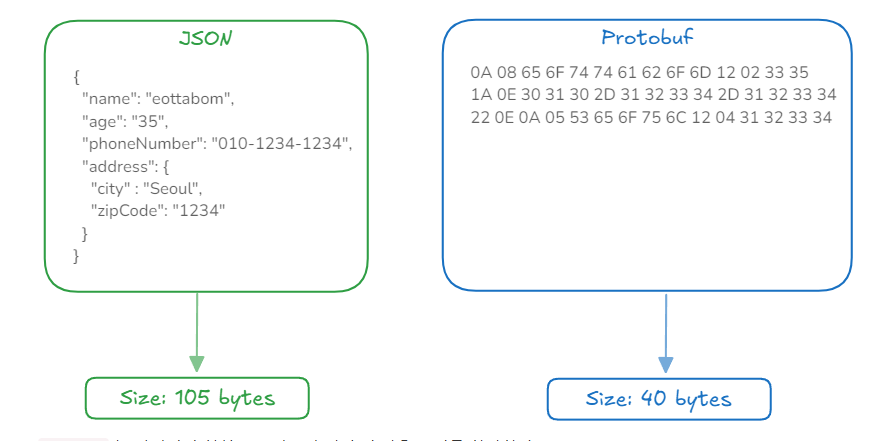
재밌는 내용을 봐서 정리해본다.Monolithic아키텍처에서는 여러 서버간에 네트워크 통신이 필요하지 않다. 서버 하나에서 메서드들을 호출하기만 하면 된다.하지만, MSA는 여러 장비에서 각각의 프로세스가 분리되다 보니 REST 통신을 통해서 각각의 프로세스가 요청-응
37.디스크 접근시간에 대해 알아보자
단일-헤드 디스크 시스템에서는 특정 데이터 블록을 읽거나 쓰려면, 헤드를 데이터가 존재하는 트랙으로 이동시키고+ 원하는 데이터가 저장된 섹터가 헤더 아래도 회전돼 올때까지 기다리는 시간+ 데이터를 전송하는 과정이 필요하다. 이 모든 과정을 수행하는 데 걸리는 시간을 디
38.동기/비동기, 블로킹/논블로킹에 대해서 알아보자
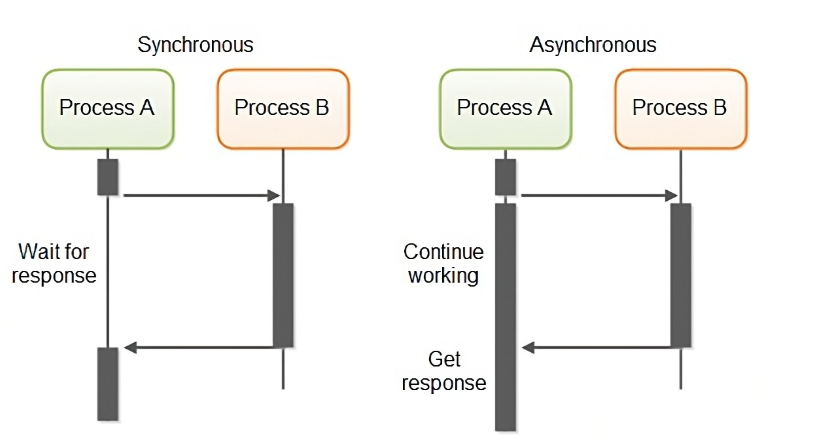
동기와 비동기는 작업의 실행 방식을 말한다. 동기 방식은 한 작업이 끝나야만 다른 작업이 시작되는 순차적인 처리방식이다. 작업의 완료를 기다리는 동안엔 다른 작업을 수행할 수 없다. 동기 방식은 현재 실행 중인 작업이 완료될 때까지 다음 작업이 대기 상태에 있어야 하기
39.트랜잭션은 error에서도 롤백이 될까?
In its default configuration, the Spring Framework’s transaction infrastructure code marks a transaction for rollback only in the case of runtime, unc
40.SQL과 NOSQL의 차이는? (+왜 SQL은 수평적 확장이 어려울까?)

SQL은 구조화 질의 언어(Structured Query Language)로, 관계형 데이터베이스를 관리하고 조작하기 위해 특별히 설계된 표준 프로그래밍 언어다.쿼리, 업데이트, 데이터 구조 관리 등 다양한 작업을 통해 관계형 데이터베이스 관리 시스템(RDBMS)에 저