1. 스프링 배치와 더티체킹
스프링 배치에서 더티체킹을 사용하는 것은 비효율적일 수 있다.
영속성 컨텍스트에서 엔티티의 스냅샷을 추적하면서 변경 사항을 확인해야 하기 때문이다.
데이터를 조회할 때부터 더티체킹을 포기하는 게 좋다고 한다.
아예 dto로 가져오는 것도 좋은 방법이다.
2. 네트워크 I/O는 최대한 줄이는 게 좋다.
주로 대량의 데이터를 insert, update, delete할 때 단건으로 네트워크를 타고가는 부분에서 퍼포먼스가 저하된다고 한다.
그래서, 벌크 형태로 작업하는 게 좋다.
3.JPA의 saveAll()은 배치를 사용할까?
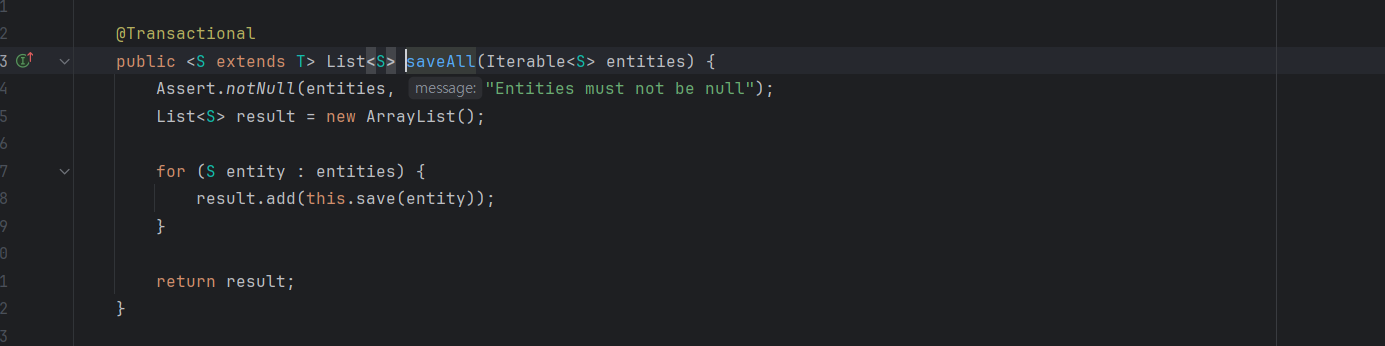
내부 로직을 보면 그냥 for문을 돌려서 엔티티마다 sql을 개별적으로 save하는 방식이다.
Hibernate disables insert batching at the JDBC level transparently if you use an identity identifier generator.
하이버네이트 공식문서를 보면 identity identifier generator를 사용하면, batching insert가 안된다는 내용이 있다.
Why does Hibernate disable INSERT batching when using an IDENTITY identifier generator 여길 보면 좀더 자세한 설명이 나온다.
IDENTITY generator는 굉장히 효율적인 잠금 매커니즈을 사용한다. 이때 트랜잭션이 관여하지 않아서 효율적인 방식이라고 한다.(그래서 롤백을 하면, DB에 영향이 안 가야 함에도 롤백하기 전에 생긴 ID번호들이 날라가는 구조라고 한다)
다만, 단점으로는 실제로 INSERT 쿼리를 실행하기 전까지는 엔티티의 ID를 알 수 없다는 것이다.
이러한 특성이 쓰기 지연을 막는다. 또한, JDBC Batch로 사용하지 못하게 된다.
좀더 쉽게 생각하면
100만개의 데이터를 insert할 때 각각의 id를 모르면 데이터를 넣는 순서도 모르게 된다.
그러니, db에 먼저 insert를 해야 하는 상황인 것이다.
sequence generator를 사용해야 배치를 쓸 수 있다. 하지만, MySQL 과거버전은 Sequnece 전략을 지원하지 않는다.(지금은 어떤지 잘 모르겠다) 대신 테이블 전략을 사용할 수 있지만, 상당히 복잡하다. 시퀀스 방식은, DB로부터 미리 ID 몇개를 받아온 다음에 이걸 애플리케이션단에서 할당하는 방식이다. 테이블 전략을 대신 사용할 수 있지만, Identity보다 성능적으로 안 좋다고 한다.
기본 테이블 전략을 수정하지 않고도 JDBC Template를 사용하면 Bulkupdat가 가능하다.
JDBC offers support for batching together SQL statements that can be represented as a single PreparedStatement. Implementation wise this generally means that drivers will send the batched operation to the server in one call, which can save on network calls to the database. Hibernate can leverage JDBC batching. The following settings control this behavior.
하이버네이트 공식문서에 따르면
"여러 SQL문을 하나의 PreparedStatement로 합쳐서 사용하는 방식이다. 이를 활용하면 DB로 SQL을 one call만 보낼 수 있다(한번만 쿼리를 날릴 수 있다)"
4.Batch 방식을 쓰면 좋은 이유가 뭐야?
네트워크를 오가는 횟수가 줄어들기도 하지만 DB부하를 줄일 수 있다는 점도 큰 이점이다.
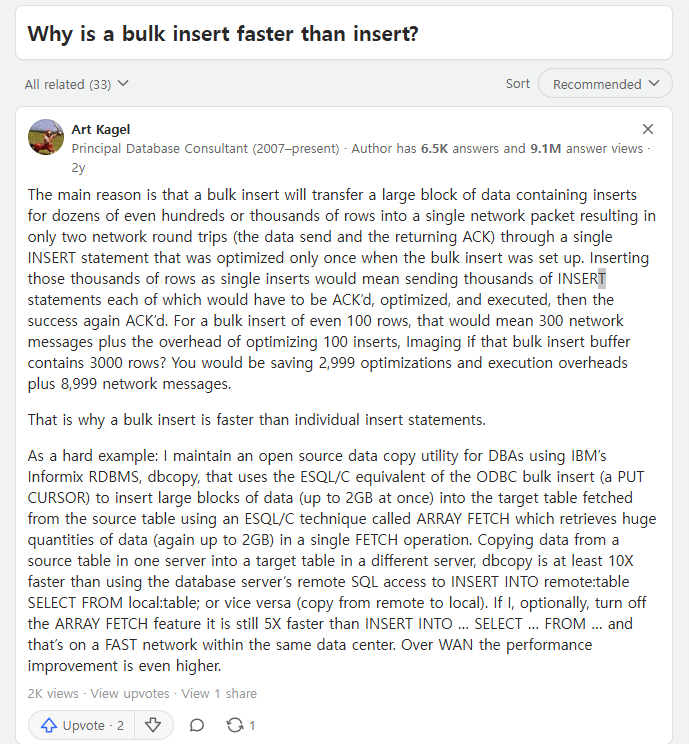
위 내용과 더불어 참고를 통해서 내용을 정리한다.
3000건의 쿼리를 단건으로 보내면 DB에서 쿼리 파싱하고 실행하는 작업을 3000번해야 한다. 쿼리를 1번만 보내면, 이를 1번만에 끝낼 수 있다.
이를 통해서
-
트랜잭션 오버헤드 감소 :쿼리는 트랜잭션 안에서 처리되며, 트랜잭션이 늘어날수록 오버헤드를 증가된다. 3000번을 단건으로 보내면 매번 트랜잭션을 관리해야 하지만, 벌크 쿼리는 트랜잭션 하나로 관리돼서 오버헤드를 줄인다.
-
Locking 오버헤드 감소 : 개별 INSERT 마다 잠금이 필요해서, 여러 사용자가 동시에 작업하려고 하면 Lock 때문에 성능이 느려질 수 있다. 벌크 방식을 쓰면 Lock 사용 횟수가 줄어든다.
-
로그와 인덱싱: 데이터베이스는 일관성을 유지하고 빠르게 검색할 수 있도록 로그와 인덱스를 관리한다. 개별삽입마다 로그와 인덱스 업데이트하면 시간이 많이 걸릴 수 있다. 많은 데이터를 한꺼번에 넣으면, 로그와 인덱스도 한 번에 업데이트된다.
