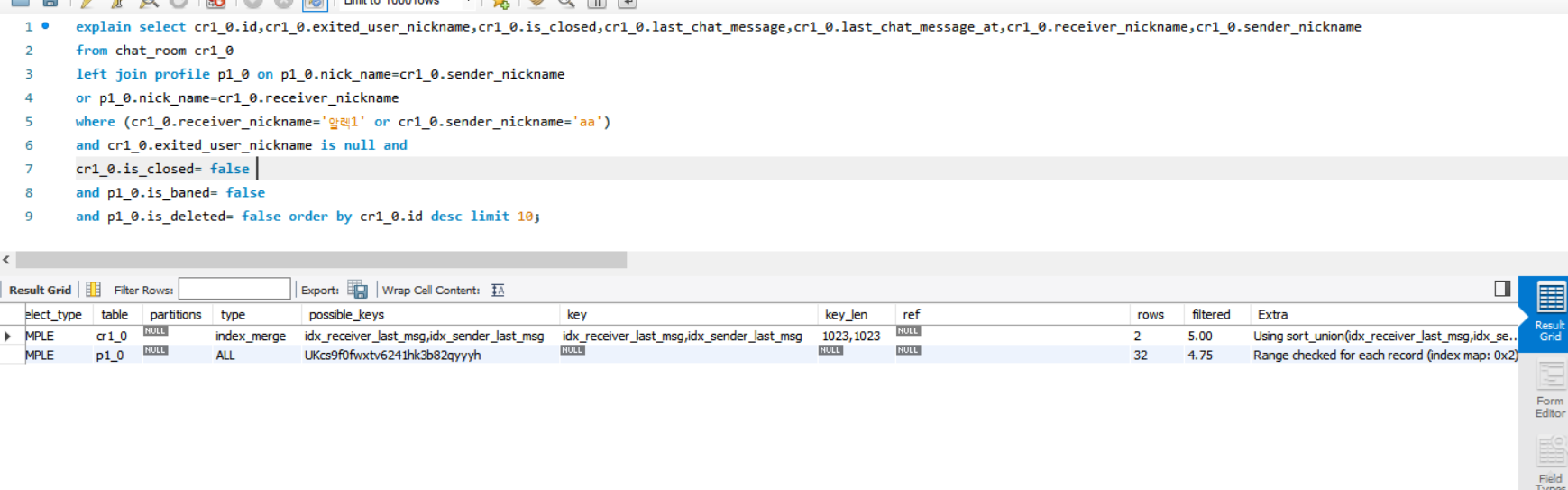
이 쿼리를 봐보자.
모든 레코드를 스캔했다고 돼 있다.
뭔가 성능적으로 좋지는 않아 보인다.
웬만해서는 Join과 or을 같이 쓰지 않는 게 좋다고 한다.
옵티마이저가 인덱스 실행계획을 세우지 못하기 때문에 쿼리 실행 계획 최적화가 안되기 때문
좀더 자세하게 쿼리 실행 계획을 살펴보자.
'-> Limit: 10 row(s) (cost=10.7 rows=3.04) (actual time=10.1..10.1 rows=0 loops=1)
-> Nested loop inner join (cost=10.7 rows=3.04) (actual time=9.6..9.6 rows=0 loops=1)
-> Sort: cr1_0.id DESC (cost=1.61 rows=2) (actual time=9.6..9.6 rows=0 loops=1)
-> Filter: ((cr1_0.is_closed = false) and ((cr1_0.receiver_nickname = ''알렉1'') or (cr1_0.sender_nickname = ''aa'')) and (cr1_0.exited_user_nickname is null)) (cost=1.61 rows=2) (actual time=8.65..8.65 rows=0 loops=1)
-> Sort-deduplicate by row ID (cost=1.61 rows=2) (actual time=8.65..8.65 rows=0 loops=1)
-> Index range scan on cr1_0 using idx_receiver_last_msg over (receiver_nickname = ''알렉1'') (cost=0.36 rows=1) (actual time=3.8..3.8 rows=0 loops=1)
-> Index range scan on cr1_0 using idx_sender_last_msg over (sender_nickname = ''aa'') (cost=0.36 rows=1) (actual time=0.0486..0.0486 rows=0 loops=1)
-> Filter: ((p1_0.is_deleted = false) and (p1_0.is_baned = false) and ((p1_0.nick_name = cr1_0.sender_nickname) or (p1_0.nick_name = cr1_0.receiver_nickname))) (cost=28.1 rows=1.52) (never executed)
-> Index range scan on p1_0 (re-planned for each iteration) (cost=28.1 rows=32) (never executed)
'-> Filter: ((p1_0.is_deleted = false) and (p1_0.is_baned = false) and ((p1_0.nick_name = cr1_0.sender_nickname) or (p1_0.nick_name = cr1_0.receiver_nickname))) (cost=28.1 rows=1.52) (never executed)
-> Index range scan on p1_0 (re-planned for each iteration) (cost=28.1 rows=32) (never executed)
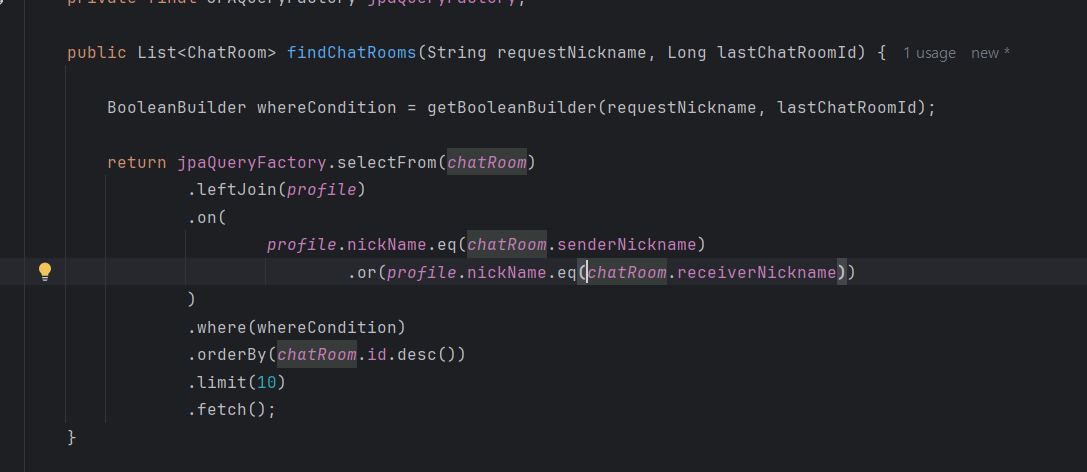
이 코드를 보면 join 조건 절 on에서 or을 사용하기 때문이다.
찾아보니까
참고:MySQL outer join or조건 튜닝
이런 사례들처럼 join에 or 조건을 달면 인덱스를 타지 못하는 사례들이 있는 거 같다.
방식은 join을 두번하거나 union all을 쓰는 두가지가 있다.
두개가 어떤 차이가 있느지는 사실 잘 모르겠다..
union all은 쿼리를 두번 실행해서 결과를 합치는 방식이다.
Join 두번으로 쪼개자
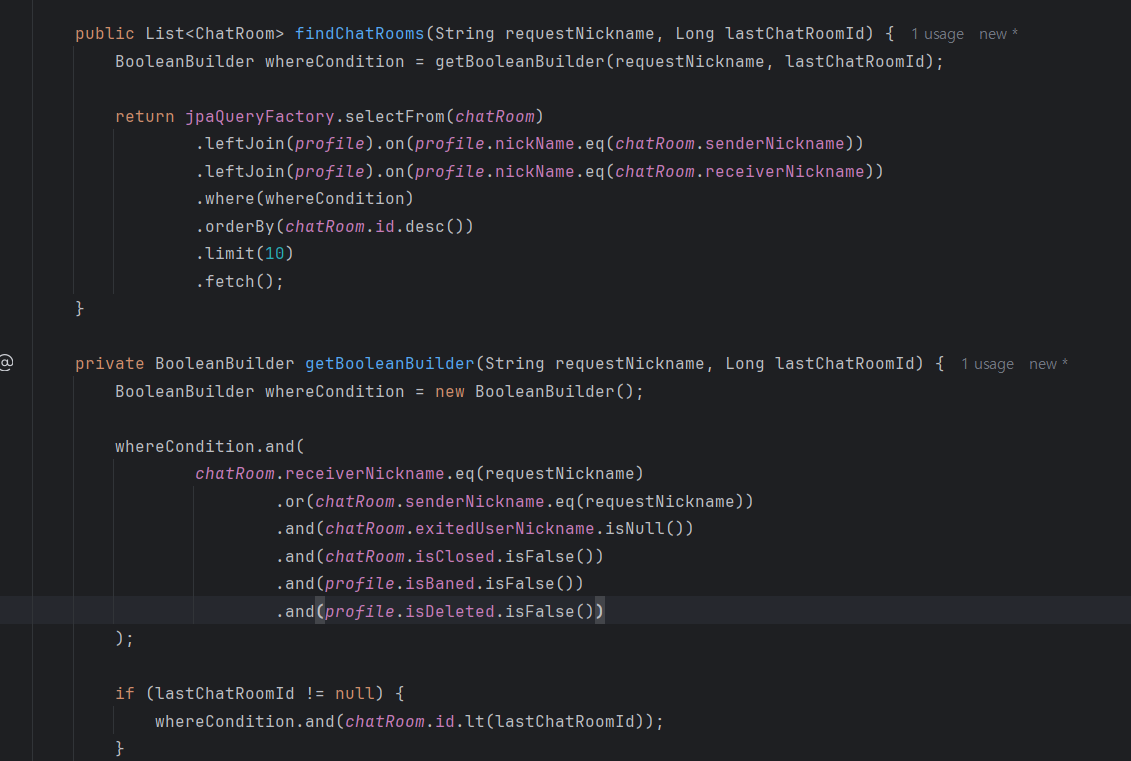
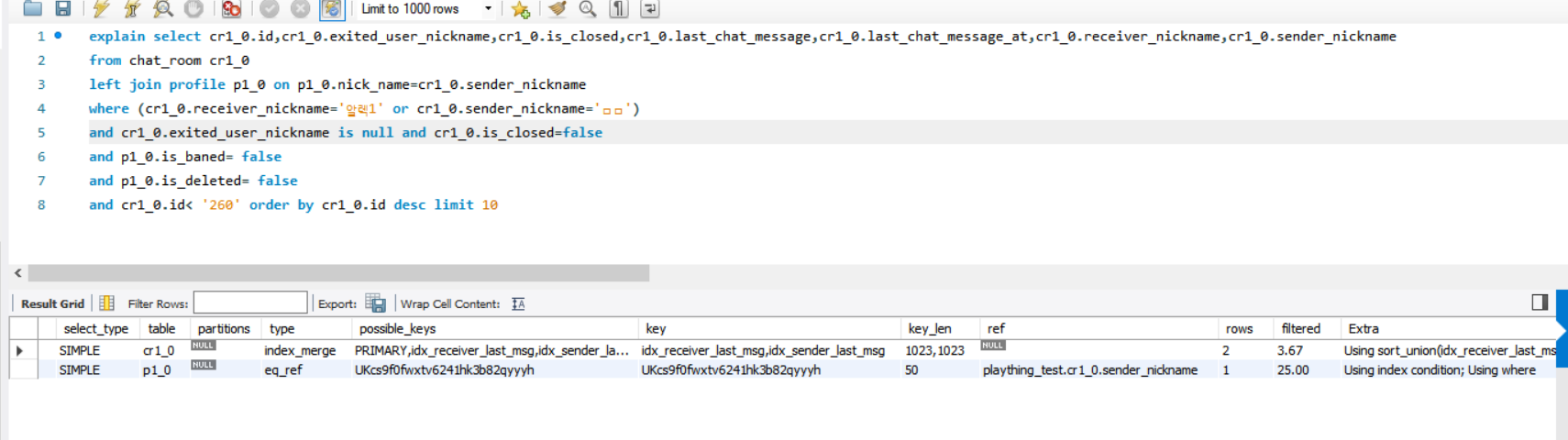
쿼리 실행 계획을 보면 이제는 인덱스를 타는 것으로 나온다.

답을 찾기 위해서 노력하는 사람