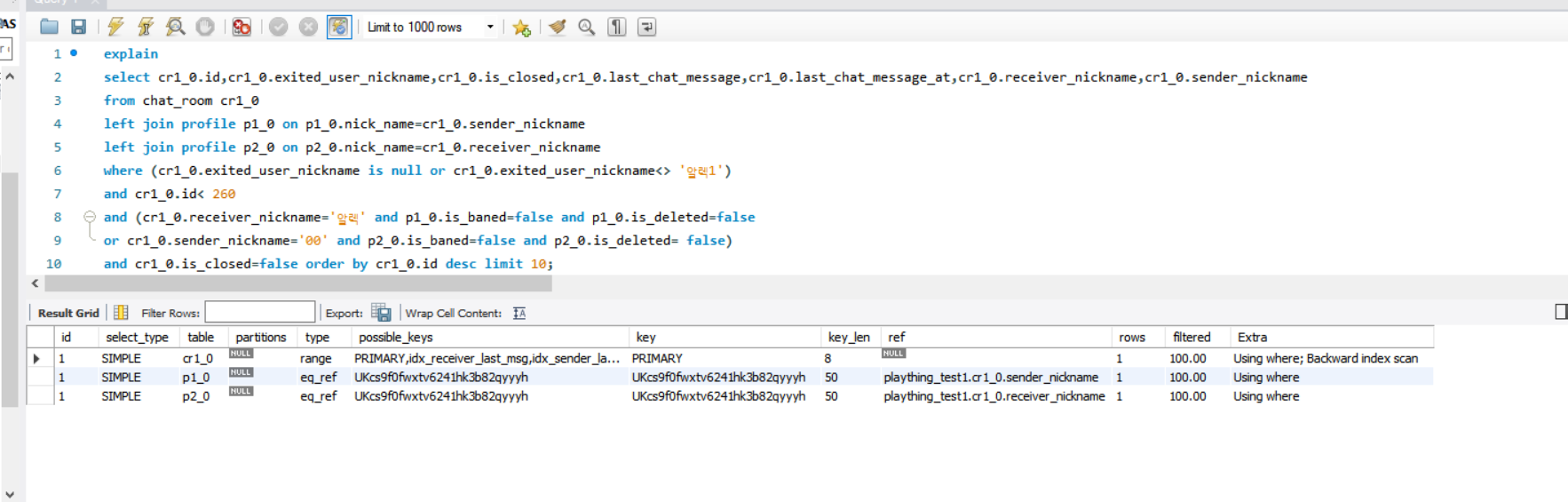
이 사진은 현재 채팅방을 조회하는 최종본의 쿼리다.
인덱스를 다 잘타고 있다.
이 글에서 언급했듯
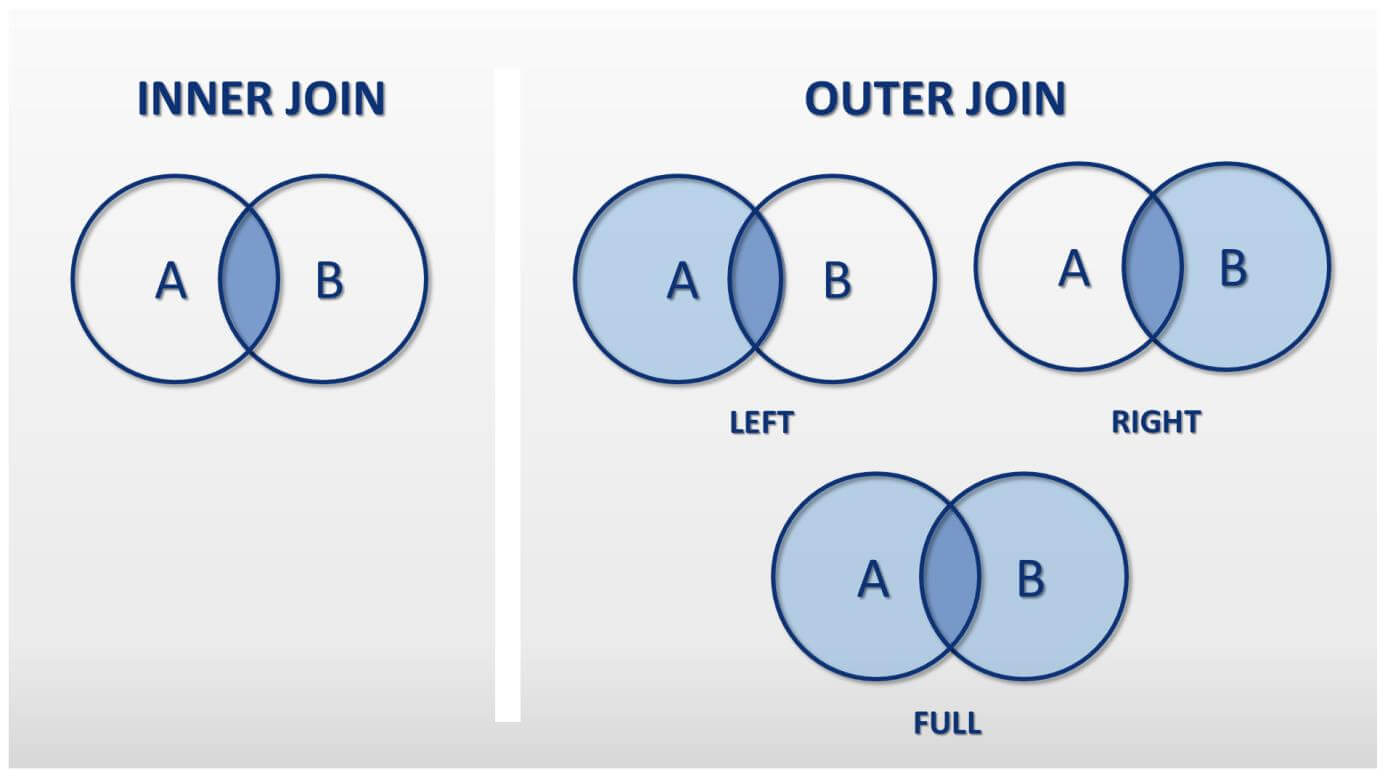
inner join은 교집합을 가져온다.
개념적으로 좀더 정리해보자
Real MySQL2권을 보면서 개념적인 정리를 좀더 해보자.
이너조인은 조인 대상 테이블에 모두 존재하는 레코드만 결과 집합으로 반환한다.

이걸 아우터조인(LEFT JOIN)으로 한다고 해보자.
employee 테이블을 풀스캔하면서, dept_emp 테이블과 departments 테이블을 드리븐 테이블로 사용한다는 것을 알수 있다.
employess 테이블에 존재하는 사원 중에서 dept_emp 테이블에 레코드를 갖지 않는 경우가 있으면 아우터 조인을 써야 한다.
그런 경우는 없으면 굳이 아우터 조인을 사용할 필요가 없다. 테이블의 데이터가 일관되지 않은 경우에만 아우터 조인이 필요하다.
MySQL 옵티마이저는 아우터 조인될 때, left면 left 테이블을 드라이빙 테이블로 선택한다(그값과 중복되는 걸 가져와야 하기 때문인거같다. 오른쪽 테이블을 먼저 읽으면, 왼쪽 테이블에서 중복되는 값이 뭐가 있는지 알 수 없다.). 그 결과 쿼리의 성능이 떨어지는 실행 계획을 수립할 것이다.
이 쿼리에 inner join을 이용했다면, departments 테이블(오른쪽 테이블)에서 부서명이 'Development'인 레코드 1건만 찾아서 조인을 실행하는 실행 계획을 세웠을 것이다.
이너조인을 사용해도 되는 쿼리를 아우터 조인을 작성하면 MySQL 옵티마이저가 조인 순서를 변경하면서 수행할 수 있는 최적화의 기회를 뺏어버리게 된다.
참고:SQL INNER JOIN 과 LEFT JOIN 성능차이가 나는 이유가 궁금합니다.
이 글을 보면

INNER JOIN은 두개의 테이블에서 일치하는 행만 가져오기 때문에 검색 범위가 줄어든다고 한다.
코드를 변경해보자
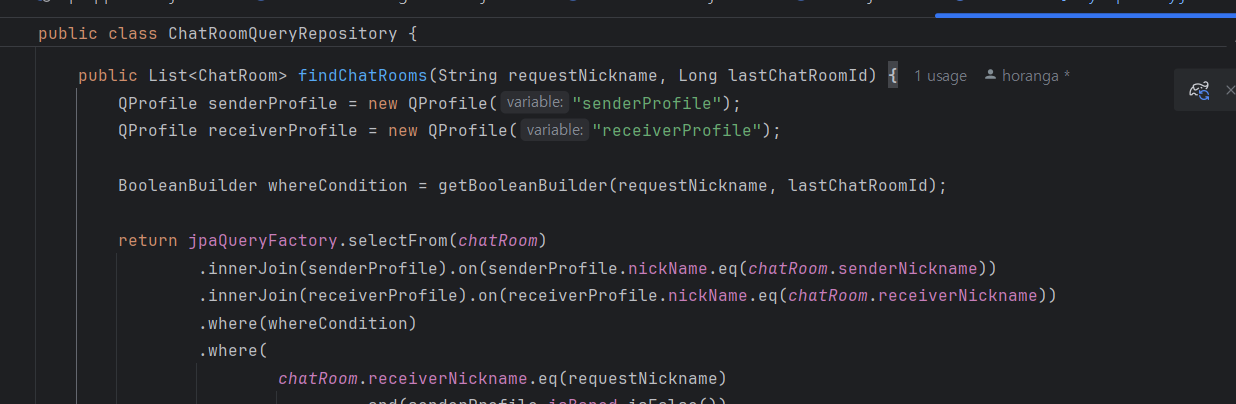
left join을 inner join으로 변경해줬다.
profile이 없는 유저는 어차피 조회되면 안되기 때문에 굳이 outer join을 쓸 필요가 없다.
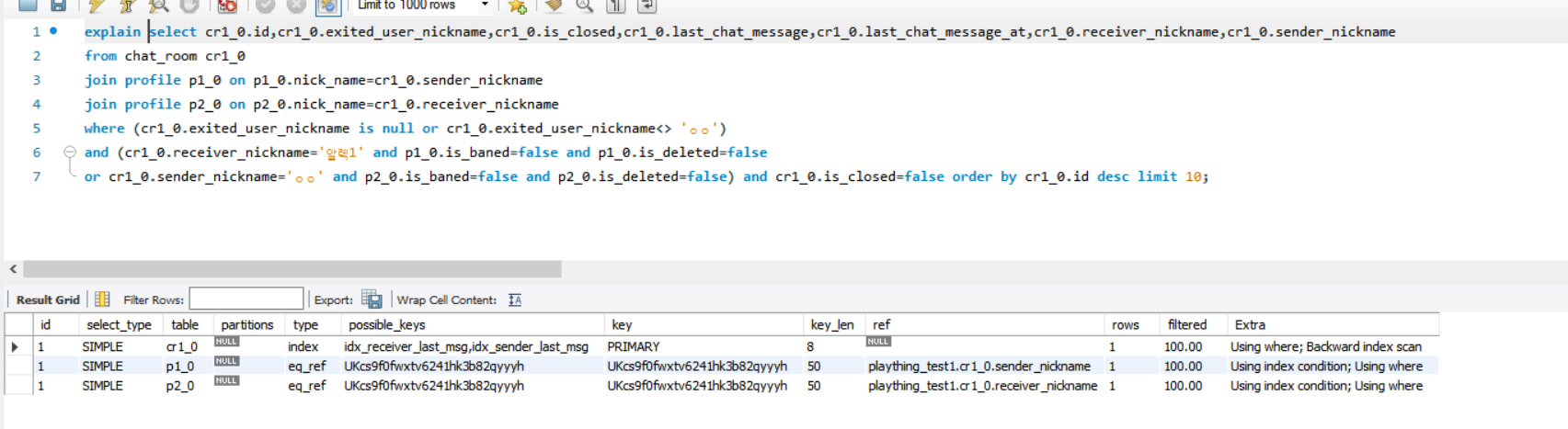
최종적인 쿼리는 위 처럼 나간다.
Join에 대해서 좀더 알아보자
이 글을 보면 join은
- Nested Loops Join
- Hash Join
- Sort Merge Join
이 세가지 알고리즘으로 돌아간다.
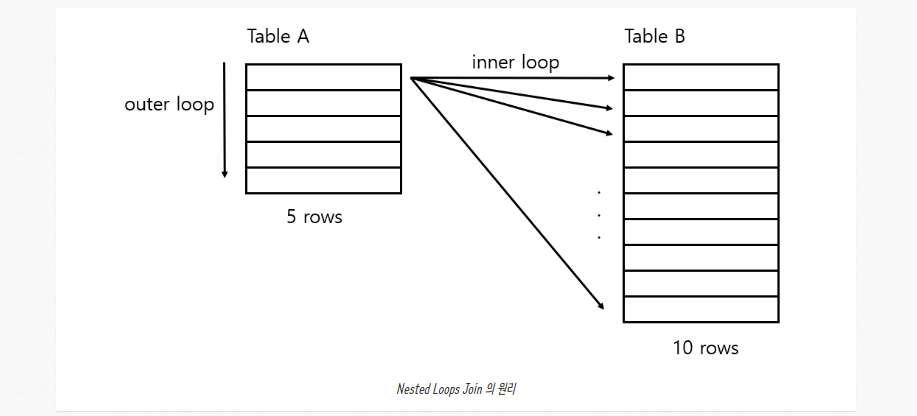
Nested Loops Join은 위 사진처럼 작동한다.
이때 Table A를 구동테이블(드라이빙 테이블)이라고 한다.
설명을 읽어보면 우리가 흔히 사용하는 중첩 for 문의 원리와 같습니다.
테이블 A의 레코드 X 테이블 B의 레코드만큼 레코드수를 접근하게 된다.
성능을 높히기 위해선 R(A) * R(B) 의 값을 낮춰야한다.
"구동테이블(Driving Table)이 작을수록"
&
"내부 테이블(Inner Table)의 결합키 필드에 인덱스가 존재"
일수록 성능을 향상시킬 수 있다.
내부 테이블의 결합키에 인덱스가 존재하게 되면 Driving Table 에서 Inner Table 로 스캔을 하러 갈 때 모든 행에 대해 스캔을 할 필요가 없게 된다.
구동테이블은 어떻게 결정될까?
구동테이블은 옵티마이저가 최적의 실행계획에 따라 결정한다.
구동테이블이 작고 내부테이블 결합키에 인덱스가 존재하는 경우, 조건에 따라 실행 비용을 최소화하는 방향으로 결정한다.
다만, Outer Join 을 실행하면 상황이 달라진다.
Inner Join은 어느 테이블을 먼저 읽어도 결과가 달라지지 않기 때문에 옵티마이저가 조인의 순서를 조절해 다양한 방법으로 최적화를 수행할 수 있다.
하지만 Outer Join 은 반드시 Outer 가 되는 테이블을 먼저 읽어야하기 때문에 옵티마이저가 조인의 순서를 선택할 수 없다.
Left Outer Join 일 땐 왼쪽 테이블이, Right Outer Join 일 땐 오른쪽 테이블이 드라이빙 테이블이 된다.
