GenAI해커톤
1.API 호출 흐름 정리하기
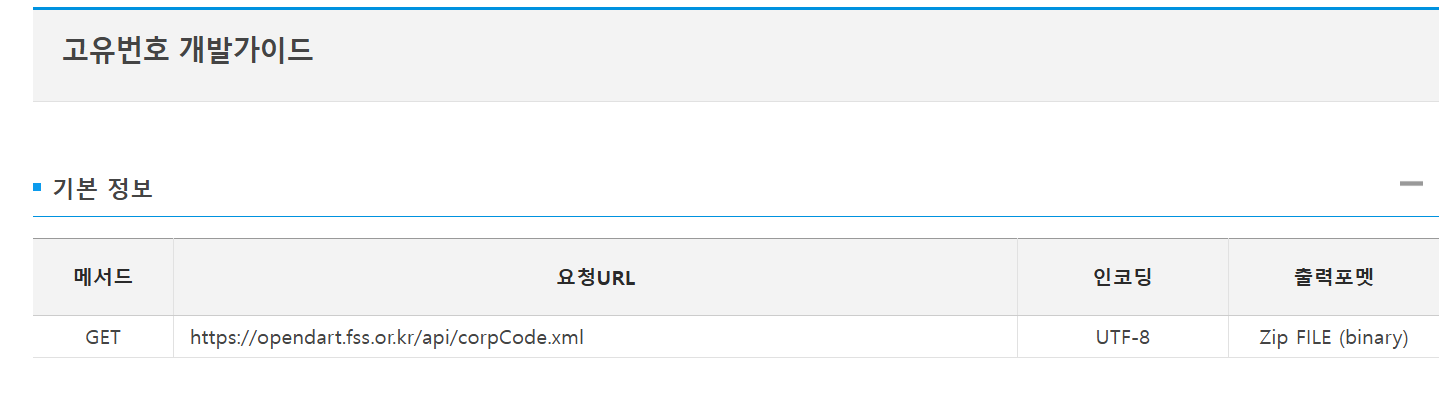
GenAI 해커톤에서 내가 해야 할 일은DART(전자공시사이트)에 있는 상장기업+비상장기업의 재무제표 PDF를 받아오는 일이었다. 이것들을 AWS S3에 올려야 한다.처음에는 간단할 것이라고 생각했지만, 정말 규모가 큰 작업이었다.우선, DART에서는 기업의 재무제표를
2.Unexpected end of file from server, API 호출량 조절하기
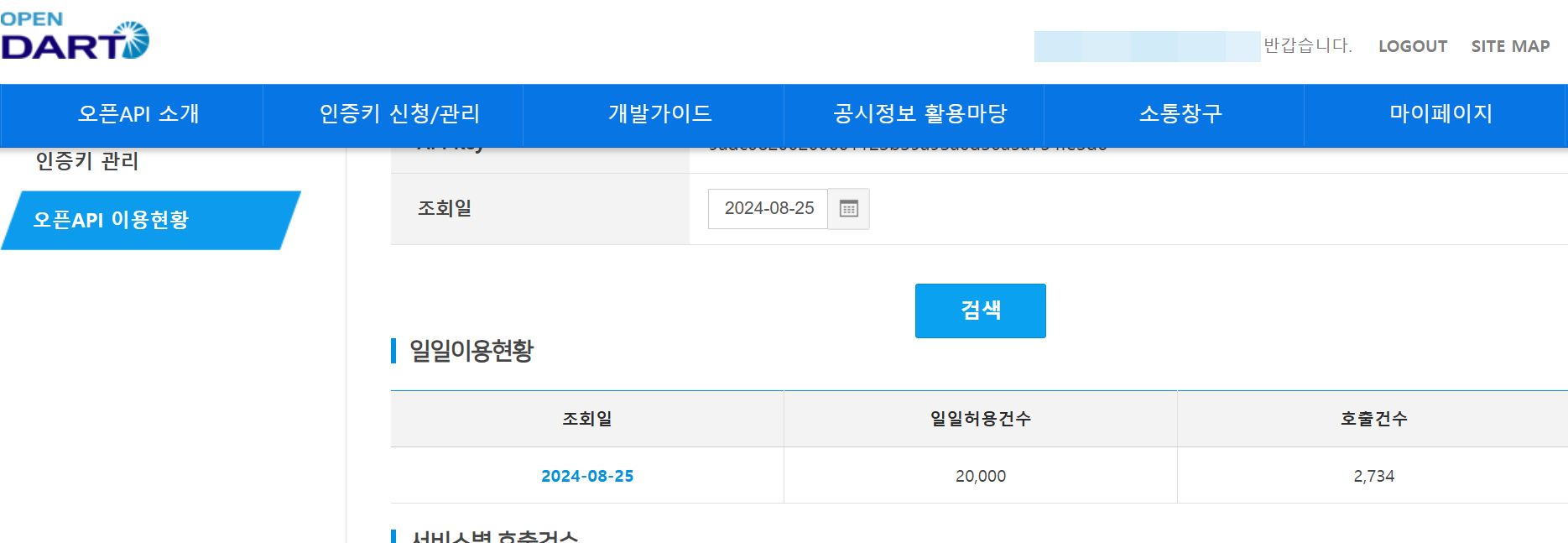
DART에서 API는 하루 2만번씩 호출이 가능하다.그래서, 사실 모든 비상장기업+상장기업의 분기보고서를 가져오는 것이 어렵지 않을 거라고 생각했다.하지만, 예상과 전혀 달랐다.우선, 공시 정보를 호출하기 위한 API를 불렀을 때 계속 dcmNo(문서번호)가 null로
3.@Retryable으로 재시도 로직 구현하기
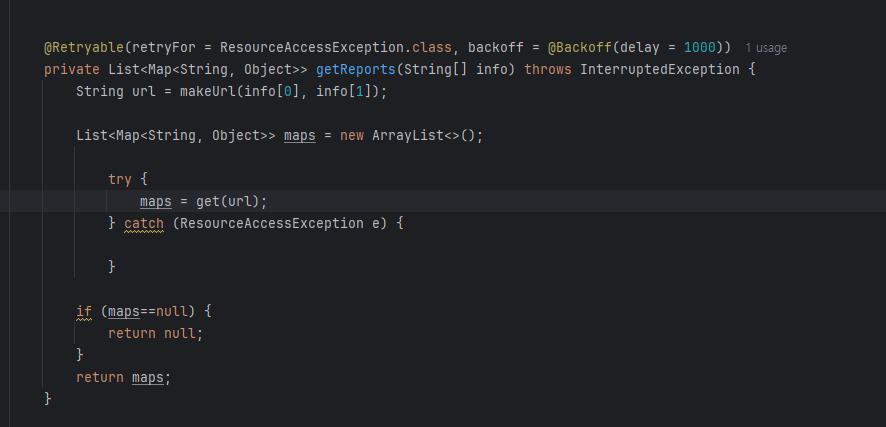
처음에 재시도 로직을 구현하지 않았더니 readtimeout 로그 메시지가 떴다.이러한 타임아웃은 서버로 요청을 보냈지만 일정 시간 동안 답변을 받지 못할 때 발생한다. 이러한 타임아웃이 필요한 이유는 리소스를 절약하기 위해서다. 서버는 여러 클라이언트와 동시에 연결을
4.EC2 네 개로 API 호출하기

현재 10만건의 회사 공시정보를 DART에서 긁어와야 하는데속도가 너무 느렸다. PC하나로는 5시간을 해야 1만건을 돌릴 수 있는 상황.해커톤이라는 특성상 더 빠른 작업이 필요했다.그래서, AWS EC2를 네대로 돌리기로 했다.어차피 AWS t2.micro는 프리티어로
5.Amazon S3 경고 로그 "No content length", "JAXB is unavailable"
Amazon S3를 써보면서 처음 보는 로그들이다. 내용을 보니 메모리 누수가 생길 수 있고, 성능에 악영향을 줄 수 있는 요인들이 있는 듯하다. 배포서버는 메모리가 적으므로 배포하기 전에 해결해야 할 문제로 보인다. No content length specif
6.HTTP 요청 헤더를 확인해서 API로 사용하기
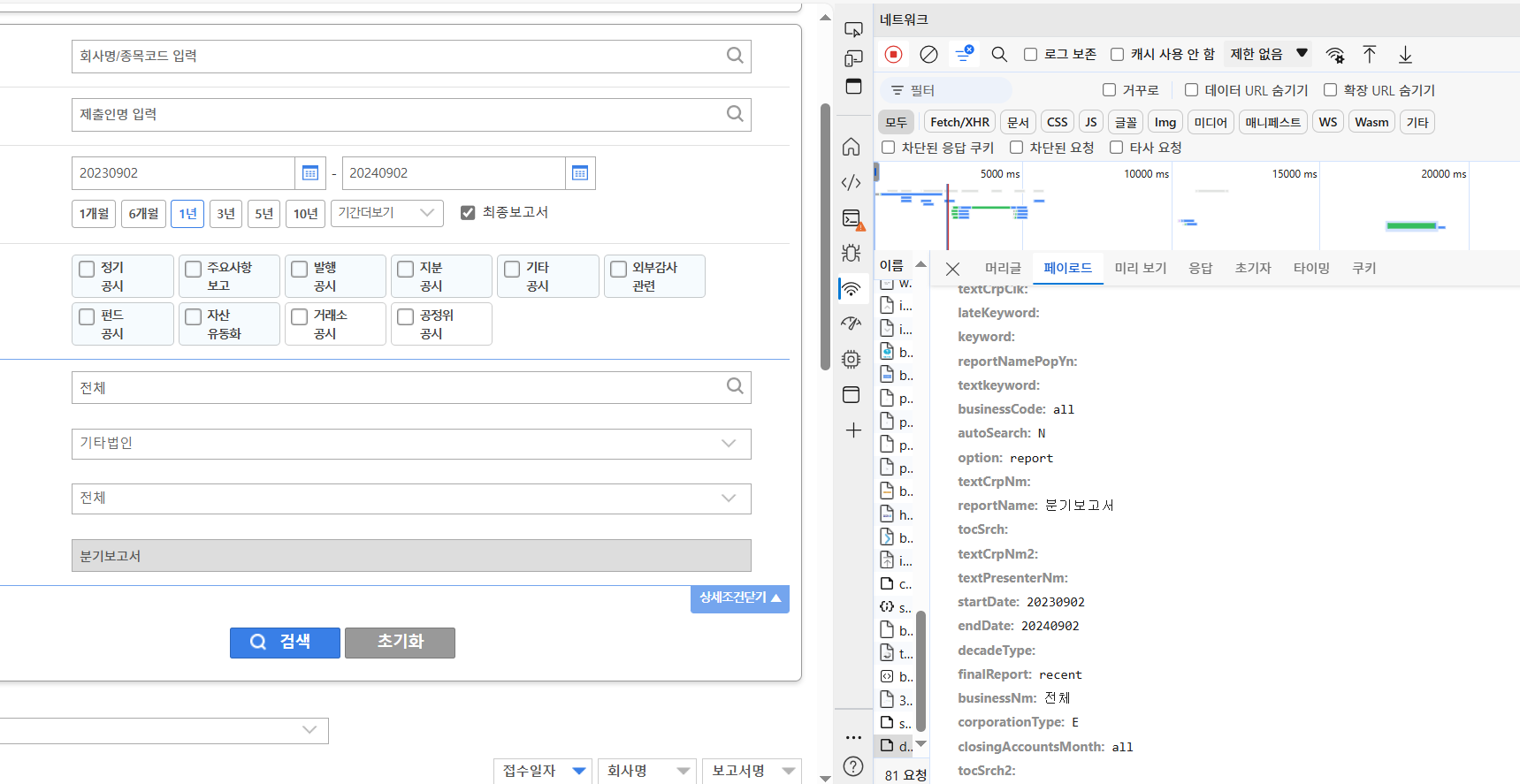
크롤링 작업을 해보지 않았던 탓에나는 그전에 작업을 굉장히 비효율적으로 했다.DART에서 모든 기업 코드를 받아서, 이 기업 코드로 공시정보를 확인하고나서그걸 기반으로 어떤 보고서가 나오는지 확인한다. 여기서 리포트가 발행된 날짜, 리포트 번호를 다시 크롤링 작업을 통
7.불변 컬렉션을 변경하려고 할 때 터지는 예외
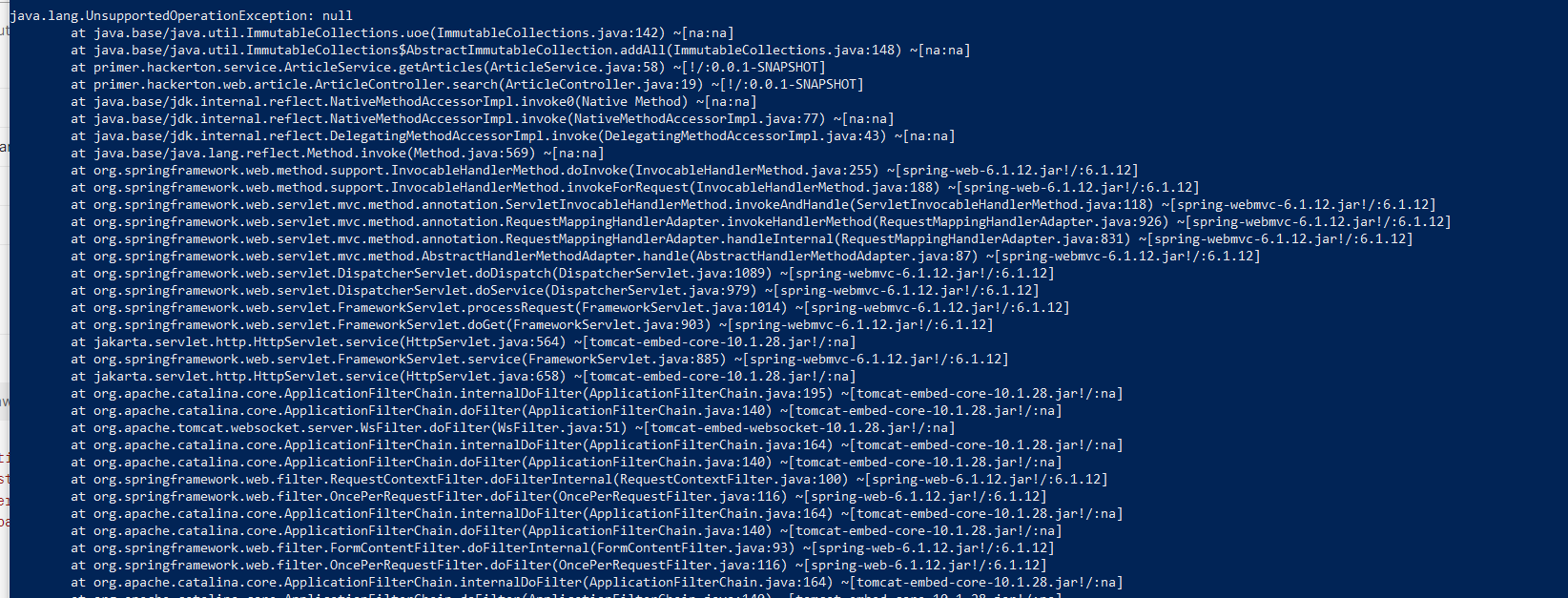
비상장 기업의 기사를 가져오는 API를 배포서버에서 확인했을 때 갑자기이런 예외가 떴다. 에러 로그를 보니 불변컬렉션을 변경하려고 할 때 생기는 문제로 보인다.코드를 보면 toList()는 불변 컬렉션을 반환하는 것을 알 수 있다.이 경우는 두 가지 방법으로 해결할 수
8.JSOUP 코드
items로 들어오는 기사들을 맵핑해주는 방식1)JSON 파싱 시작->objectMapper.readTree(response)로 JSON 문자열을 파싱하여 트리 구조로 변환한다.2)items" 노드 찾기->rootNode.path("items")로 JSON에서 "ite
9.병렬 스트림을 통한 성능 개선
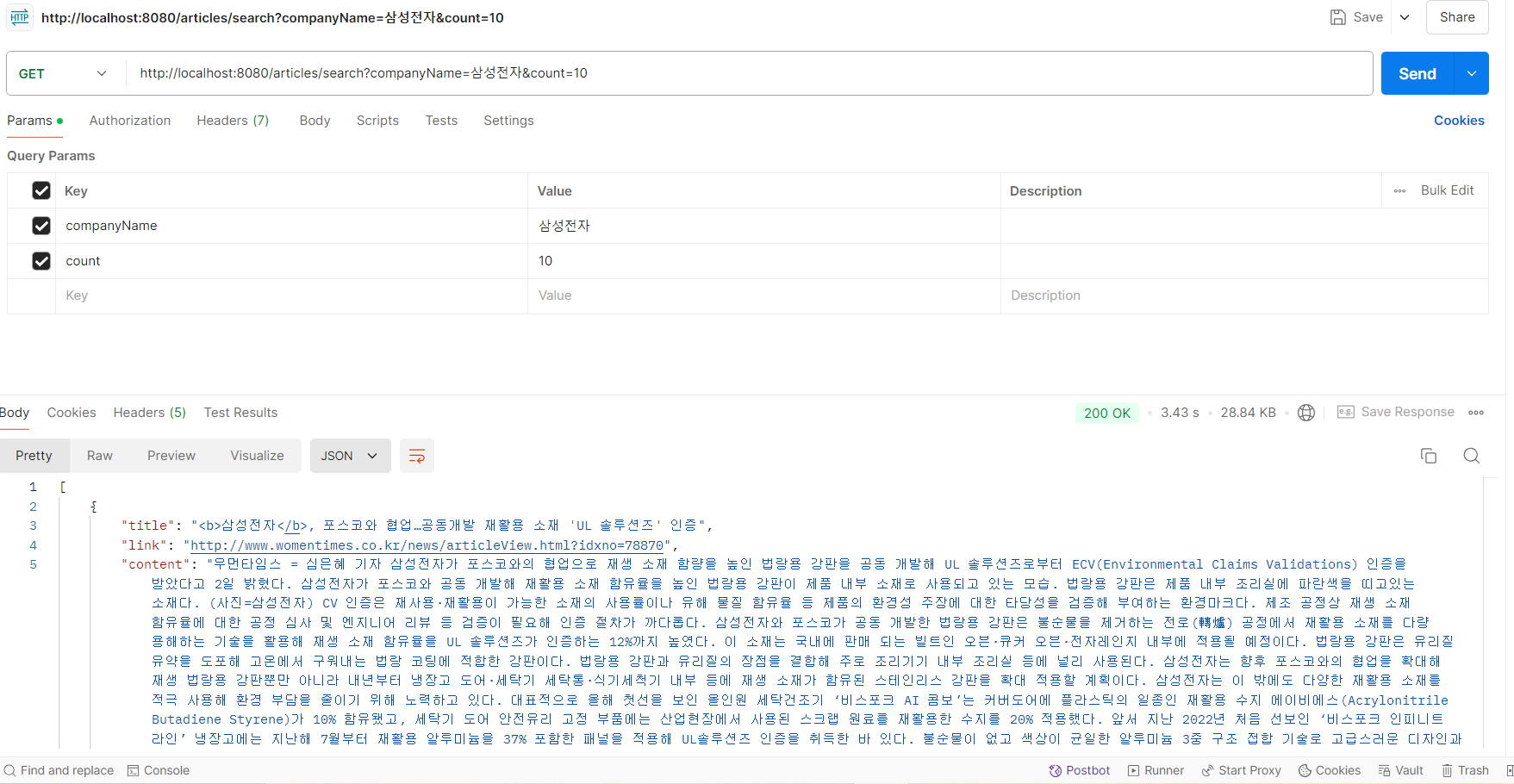
이 메서드는 네이버 검색 API를 통해서 네이버 기사를 가져온다. API를 한번 호출하고 JSOUP으로 해당 기사의 링크에 들어가서 HTML 파일을 읽고 기사 본문을 가져와서 작업 자체가 상당한 시간이 걸린다.10개 기사를 가져올 때를 비교해보자.포스트맨 기준으로 3초