private List<ArticleDto> filter(List<ArticleDtoForSorting> list, String companyName, int count) {
return list.stream()
.filter(i ->
{
String title = i.getTitle();
String companySubstring = companyName.substring(0, Math.min(3, companyName.length()));
return title.contains(companySubstring)
|| title.length() == 2 && title.contains(companyName.substring(0, 2))
|| title.length() > 2 && title.contains(companySubstring);
}).map(i ->
{
try {
String content = getNews(i);
if (content == null) {
return null;
}
return ArticleDto.toDto(i, content);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
)
.filter(Objects::nonNull)
.limit(count)
.toList();
}이 메서드는 네이버 검색 API를 통해서 네이버 기사를 가져온다. API를 한번 호출하고 JSOUP으로 해당 기사의 링크에 들어가서 HTML 파일을 읽고 기사 본문을 가져와서 작업 자체가 상당한 시간이 걸린다.
10개 기사를 가져올 때를 비교해보자.
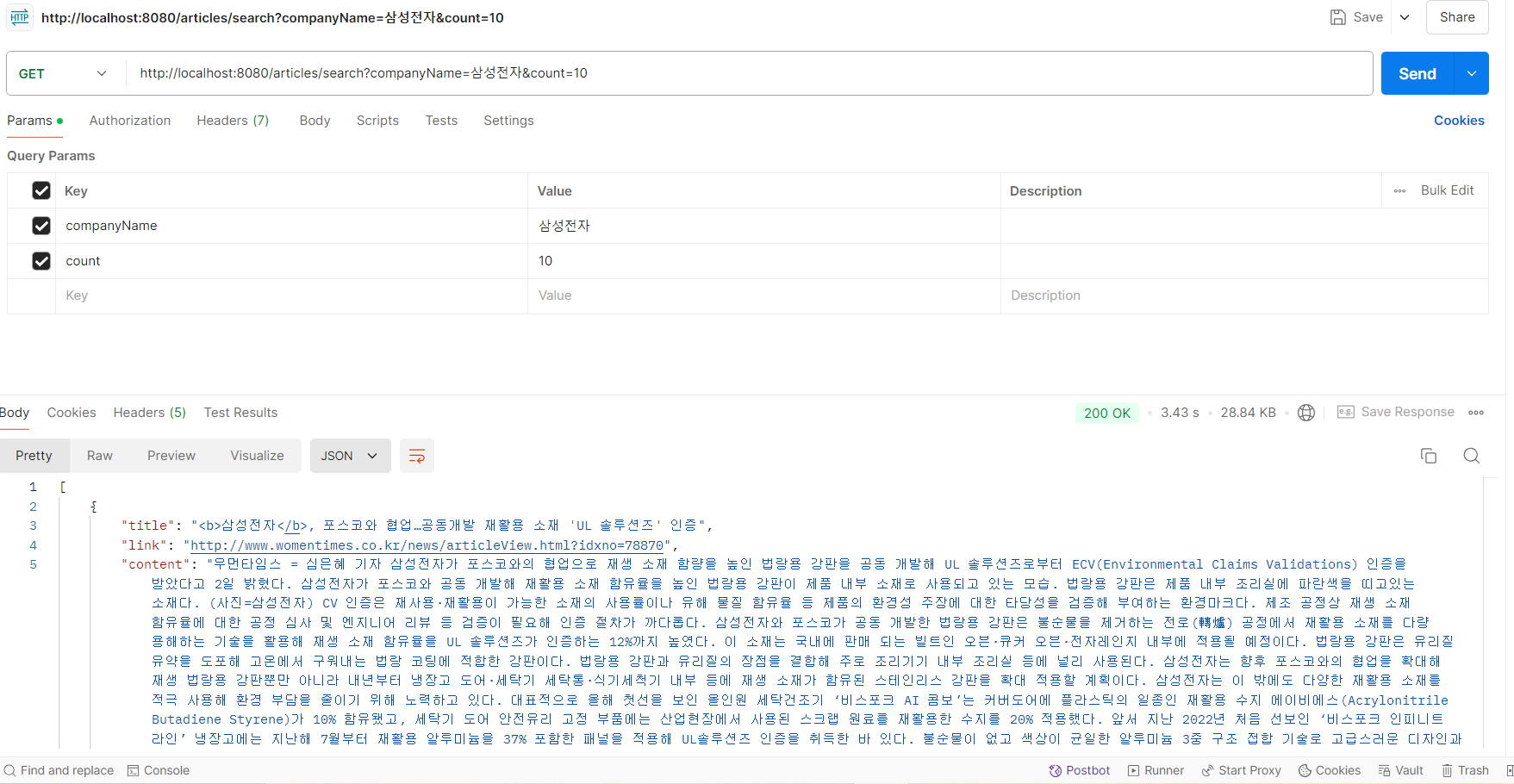
포스트맨 기준으로 3초정도가 걸린다.(일반스트림)
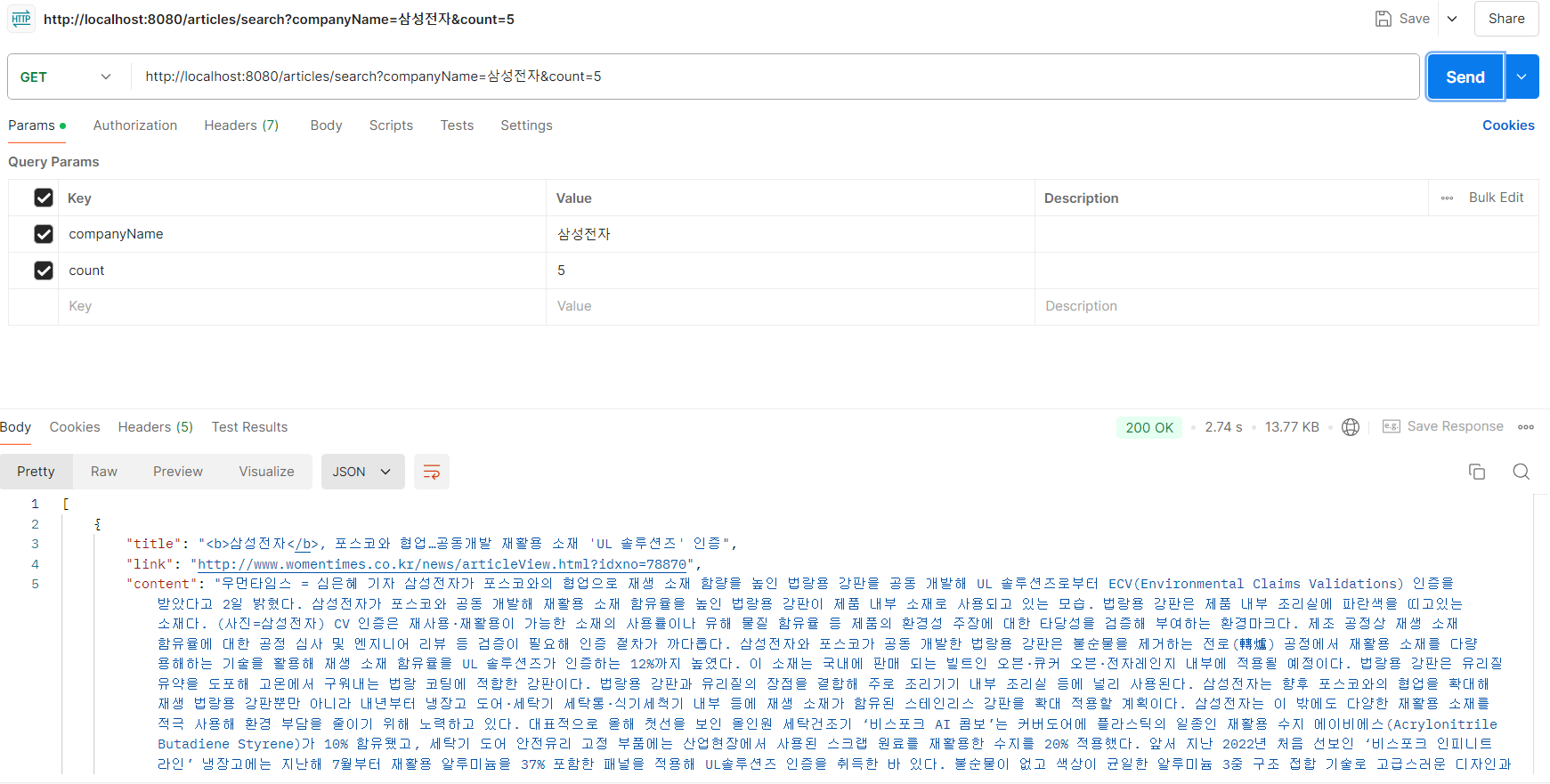
병렬 스트림을 쓰면 시간이 조금 단축돼서 2.7초가 걸린다.
100개를 가져오라고 요청하면 27초 정도가 걸린다.
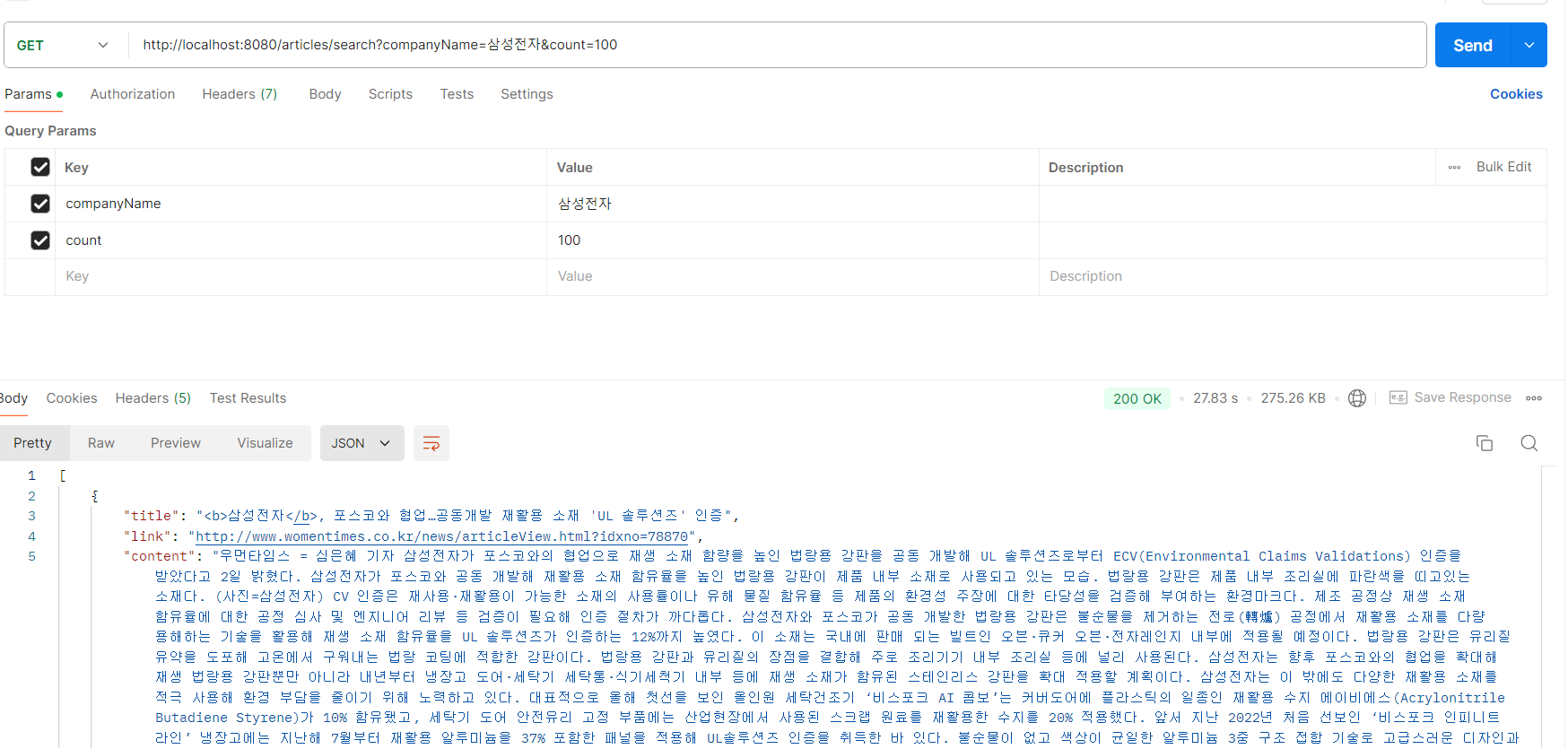
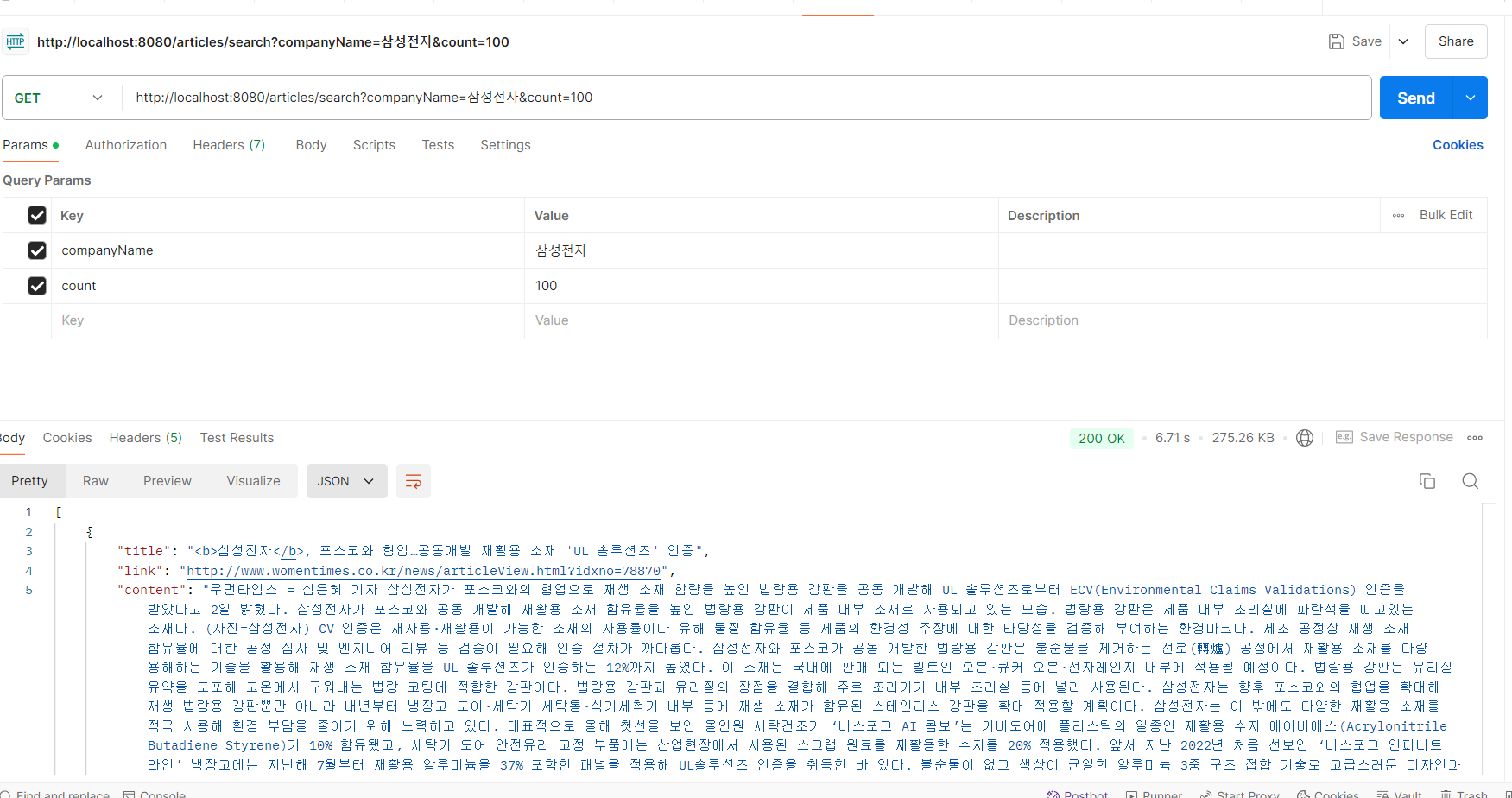
병렬 스트림은 6.5초 정도가 걸렸다. 확실히 크게 차이가 났다. 성능이 3.5배 정도 개선됐다.
배포서버+ 부하테스트
이제 배포서버에서 부하테스트를 해보겠다.
지금 운영 중인 서버말고 새로 EC2를 만들어서 https만 적용하지 않고 배포서버와 동일한 환경에서 부하테스트를 한다.

답을 찾기 위해서 노력하는 사람