이번에 스터디를 하면서 흥미로운 주제들을 발견하게 돼서 이와 관련된 공부를 해보려고 한다.
기본키 없는 설계가 가능할까?
테이블 관점에서, 기본키가 없는 설계는 실제로 가능하다. 실제로 many-to-many 관계에서는, 두개의 외래키만 있고 pk가 없는 경우도 있다.
그렇다면, 기본키는 왜 필요할지에 대해서 한번 고민해보자.
1) 기본키는 데이터의 유일성(unique)함을 보장한다.
INSERT INTO 고객 VALUES ('홍길동', 'hong@example.com', '서울시 강남구');
INSERT INTO 고객 VALUES ('홍길동', 'hong@example.com', '서울시 강남구');이렇게 쿼리를 넣으면, DB에서 중복되는 데이터를 걸러낼 수가 없다.
INSERT INTO 고객 VALUES (1, '홍길동', 'hong@example.com', '서울시 강남구');
INSERT INTO 고객 VALUES (1, '홍길동', 'hong@example.com', '서울시 강남구');이렇게 기본키가 있다면 데이터 중복을 막을 수 있다.
2)성능적인 관점에서도 중요하다.
SELECT * FROM 대용량_데이터 WHERE 데이터_값 = '특정_값';인덱스 없이 위 쿼리를 실행하면 당연히 풀스캔이 발생할 것이다.
PK가 인덱스 역할을 하기 때문에 성능적인 이점을 얻을 수 있다.
특히 PK는 클러스터링 인덱스로, 데이터도 이 인덱스에 맞춰서 물리적으로 정렬된다. 그만큼 조회 시 더 빠르게 조회가 가능하다.
3) 혹시 모를 실수를 예방할 수 있다.
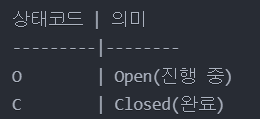
처음에 DB에 이렇게 값을 저장했다고 해보자.

나중에 OutSourced가 추가된다.
이때, O를 기준으로 값을 찾을 때 기존 애플리케이션은 O가 하나일 거라고 예상하지만 조회를 해보니 2개가 된다.

PK가 있다면 ID=1인 "O"는 "Open", ID=3인 "O"는 "Outsourced"로 명확히 구분할 수 있다.
새로운 사람이 DB를 관리하게 되거나, DB 관리자가 추가되면 이런 실수가 발생할 확률이 높아질 수 있다.
4)참조 무결성 조약을 활용할 수 있다.
고객 데이터가 삭제되면, 고객의 주문데이터도 삭제하게끔 해서 효율적으로 DB를 관리할 수 있다. 혹은 참조 대상을 먼저 지우지 않고는 데이터를 못 지우게할 수 있다.
참고자료

테이블 관점에서, 기본키가 없는 설계는 실제로 가능하다. 실제로 many-to-many 관계에서는, 두개의 외래키만 있고 pk가 없는 경우도 있다. https://www.lhiproviderportal.com