DB 모델링을 하다보면
연관관계를 맺어서 외래키 제약조건을 활용할지
그냥 식별자만 필드로 갖고있을지 고민이 될 때가 있다.
가령, User1과 그 유저의 '프로필 다시보지 않기' 데이터를 쌓는다고 해보자.
이때 전자의 방식은 연관관계를 설정해 외래키 제약 조건을 설정하는 것이고, 후자의 방식은 User1의 로그인 id(dusgh1)을 필드로 갖게 한 다음 where 절에서 로그인 id 조건으로 찾는 방식이다.
예전에 읽은 sql 안티패턴 책에서는 참조 무결성 제약때문에 연관관계를 맺는 게 좋다는 말이 있었다.
그런데, 유저 입력을 직접 받는 게 아니라 시스템에서 다루는 것이라면
참조 무결성이 꼭 필요할지? 의문이 생겼다. 또한, 지금의 경우는 식별 정보만 필요할뿐 User의 다른 정보들이 필요한 건 아니다. 그래서 식별자 방식만 써도 되지 않을까 싶다.
이에 관련 내용을 좀 정리해보기로 했다.
What's wrong with foreign keys?
1. FK와 NOT FK 간략 정리
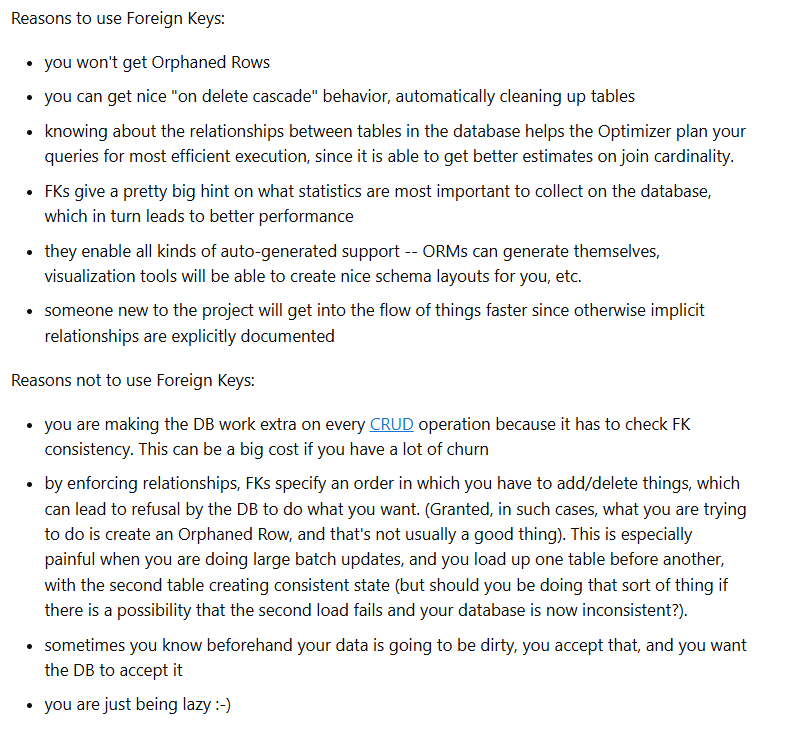
FK를 쓰면
- 고아 데이터를 방지(존재하지 않는 사용자 게시글이 생기는 걸 방지), 자동 삭제 기능
- 쿼리 최적화에 도움(DB가 테이블 간 관계를 알고 있어서 더 효율적인 쿼리 실행이 가능)
- 개발 도구들과의 호환성(JPA같은 ORM나 DB 설계 도구들이 자동으로 관계 인식)
- 문서화 효과(다른 개발자가 DB 구조를 쉽게 파악)할 수 있다.
FK를 쓰지 않으면 좋은 경우는
-
성능이 매우 중요할 때(매번 FK 체크를 하느라 성능 저하가 생길 수 있음, 대량의 데이터를 처리할 때 영향이 커짐)
-
데이터 입력 순서가 복잡할 때(FK 때문에 특정 순서로만 데이터를 넣어야 하는 제약, 대량 데이터 처리시 불편)
FK를 사용하면 데이터 정합성은 좋아지지만 약간의 성능 저하가 발생할 수 있다. 대부분은 FK를 쓰는 게 좋지만, 특수한 상황(대량 처리, 마이그레이션)에서는 FK 없이 가는 것이 나을 수 있다.
대용량 데이터 처리와 관련이 있는 부분이 아니라 FK를 써도 크게 문제는 없을 것 같다.
2. 데이터 정합성의 중요성

애플리케이션으로 데이터 정합성을 처리하는 게 항상 좋은 아이디어는 아니다. 완벽하게 처리하기도 쉽지 않고, 상당히 번거로울 수 있기 때문이라고 한다.
3. 휴먼 에러 방지
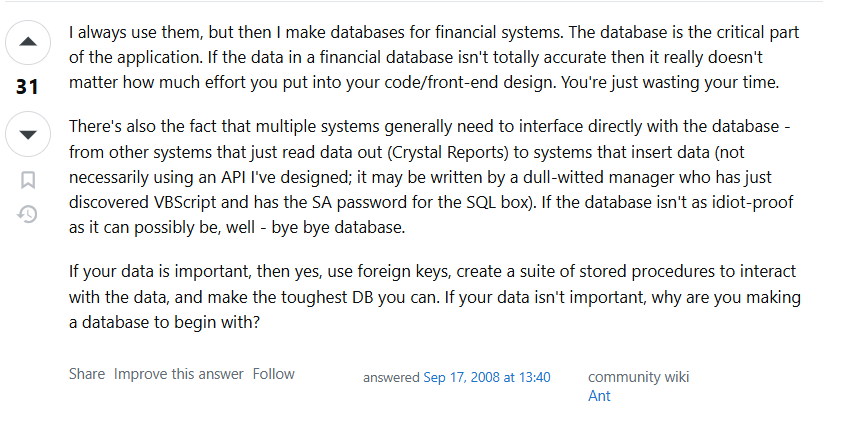
금융권 데이터베이스 같은 경우는 데이터 정합성이 매우 중요하다. 반드시 써야 함.
다양한 시스템에서 DB에서 접근하고, 다른 개발자나 관리자가 직접 데이터를 넣는다면? API만으로 데이터 보호는 불가능하다.
"바보도 실수할 수 없게" 만들어야 함이게 핵심 포인트다.
4. FK를 안 써야 변경이 쉽다

DB가 아닌 애플리케이션에서 처리할때 변경이 더 용이하다. DB는 구조를 변경해야 하기 때문이다. 배포할 때도 훨씬 편하다. DB구조를 변경하면 인덱스 재생성등의 문제가 있지만, 코드만 변경하면 git에만 코드를 올리면 된다. 테스트와 관련된 내용은, fk가 없으면 데이터 세팅을 미리 해두지 않아도 된다는 점이 편리하단 내용이 있었다(해당 로직만 직접 테스트하는 게 가능)
5. 대규모 데이터 처리
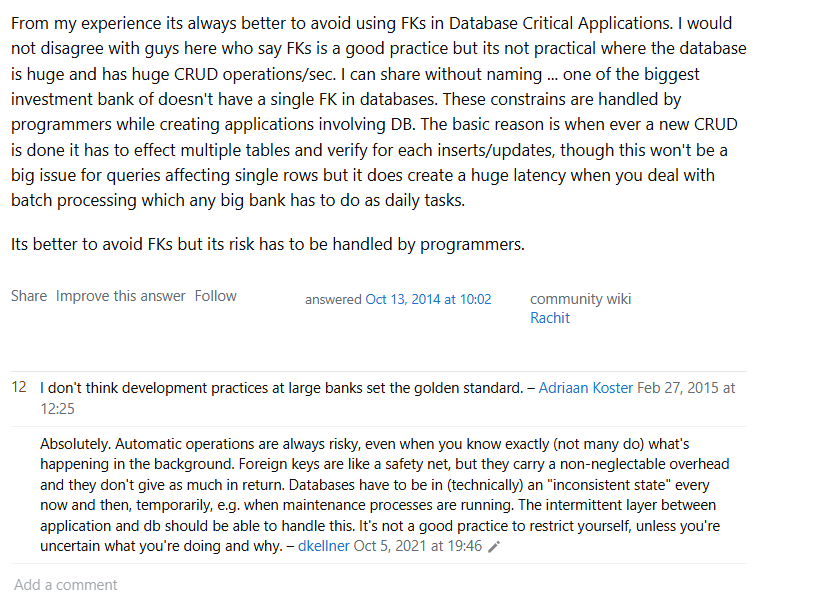
대규모 데이터를 처리할 때 FK가 있으면 매번 정합성 검사를 해야 한다. 여러 테이블에 영향을 미치는 작업에서 지연 발생할 수 있다. 특히 배치 처리에서 큰 성능 저하을 준다.
6. 배치 처리

성능 영향은 주로 배치 처리에서 발생할 수 있는데, 이때 FK를 잠시 비활성화할 수 있다고 한다.
Not using foreign key constraints in real practice. Is it OK?

외부에서 데이터를 넣을 때는 FK를 쓰지 않기도 한다고 한다.
우선 저장하고 나중에 정제하는 것이 효율적이고, 원본 데이터의 참조 무결성이 보장되지 않으며, 대량의 데이터가 빠르게 입력돼야 하는 경우가 많아서 그런 것이다.
결론
내용을 조사해보니 대용량 데이터를 처리하는 게 아닌 이상
FK쓰지 않을 이유가 없어 보인다.
많은 프로그래머들이 데이터 정합성에 대한 얘기를 하는데
이 부분이 정말 중요하다는 걸 이번에 다시 배웠다.
