유니크 칼럼은 값의 고유함을 보장함과 동시에 인덱스를 만들어 관리하는 방식이다.
읽기에서는
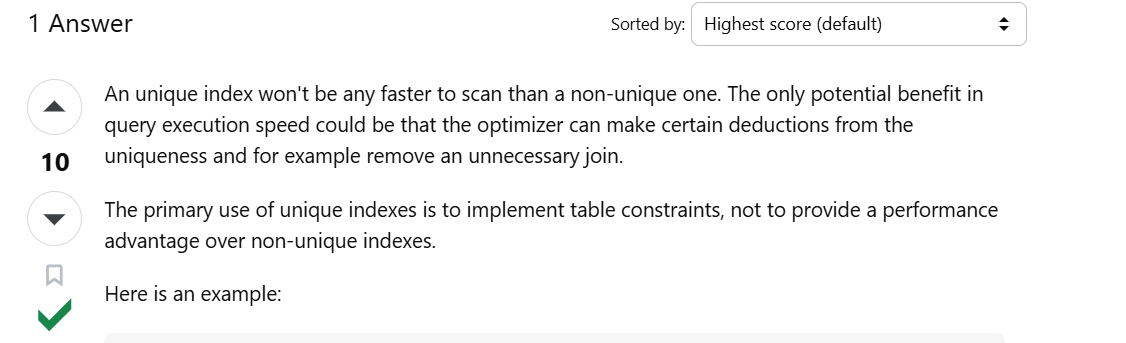
- 유니크 인덱스 자체로 빨라지는 건 아니다.
- 유니크한 특성 때문에 중복 값이 없으므로, 카디널리티가 높아지고 이에 따라 조회가 빨라질 순 있다
쓰기에서는
- 유니크 인덱스는 중복된 값이 있는지 없는지 한번 더 체크를 해야한다.
- MySQL에서는 유니크 인덱스의 중복 값을 체크할 때 읽기 잠금을 상요하고, 쓰기할 때는 쓰기 잠금을 하는데 이 과정에서 데드락이 발생할 수 있다.
- InnoDB 스토리지 엔진에서는 인덱스 키의 저장을 버퍼링하기 위해 체인지 버퍼(Change Buffer)가 사용된다. 인덱스의 저장이나 변경 작업이 상당히 빨리 처리되지만, 유니크 인덱스는 중복 체크를 반드시 해야해서 버퍼링하지 못한다.
- 유니크 인덱스는 일반 세컨더리 인덱스 보다 변경 작업이 느리다.
다만, 쓰기든 업데이트든 유니크체크가 실질적으로 성능에 영향을 주는 건 크지 않다고 한다.
참고로, 인덱스를 만들 땐 단순히 성능만 고려할 게 아니라, 데이터의 유니크함을 보장해야 한다면 성능은 어느정도 포기하는 것도 필요하다고 한다. 어차피 오버헤드가 그렇게 크지 않을 것이기 때문이다.

답을 찾기 위해서 노력하는 사람